Recognition: unknown
AVGen-Bench: A Task-Driven Benchmark for Multi-Granular Evaluation of Text-to-Audio-Video Generation
Pith reviewed 2026-05-10 17:10 UTC · model grok-4.3
The pith
A new benchmark reveals that text-to-audio-video generators produce attractive clips but fail at consistent semantic accuracy in text, speech, and physical logic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that existing evaluation methods for text-to-audio-video generation are too coarse or isolated, and a multi-granular framework applied to a new set of realistic prompts exposes a clear separation between strong perceptual quality and weak semantic reliability, with specific breakdowns in text rendering, speech coherence, physical reasoning, and musical pitch control across current systems.
What carries the argument
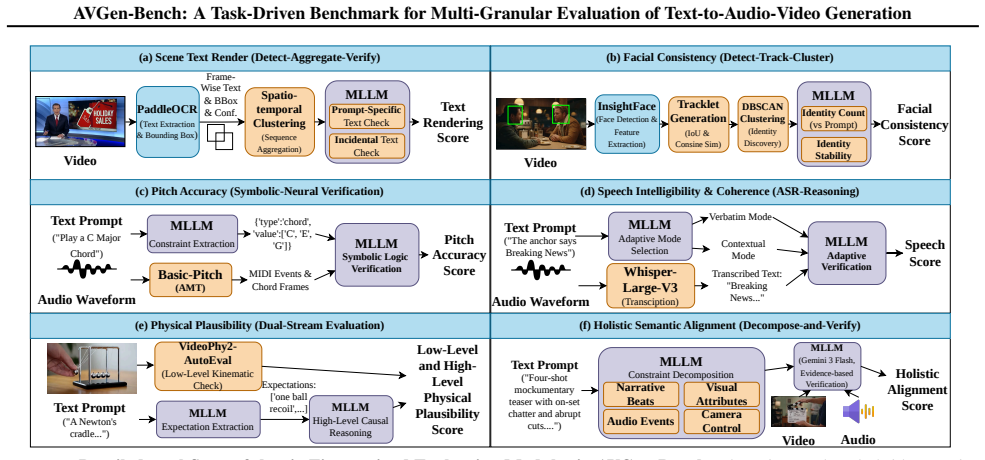
The multi-granular evaluation framework that pairs lightweight specialist models with multimodal large language models to score outputs from basic perceptual quality up to fine-grained semantic controllability across joint audio-video content.
If this is right
- Developers must prioritize reliable text rendering inside generated video frames as a core requirement.
- Speech coherence across audio tracks needs targeted improvements to match visual content.
- Models require better mechanisms for physical reasoning to avoid implausible object or action sequences.
- Musical pitch control must be addressed as a distinct failure mode rather than a side effect of general audio quality.
- Evaluation protocols should move beyond isolated audio or video metrics to joint semantic checks.
Where Pith is reading between the lines
- The benchmark's category-based prompt set could serve as a standard test suite for tracking progress in integrated audio-video models over time.
- Persistent failures suggest that training objectives focused mainly on aesthetic metrics may need explicit semantic alignment terms added.
- If the gap persists in newer models, it may indicate a need to revisit how audio and video streams are jointly conditioned on text prompts during generation.
Load-bearing premise
The multi-granular evaluation framework that combines specialist models with multimodal language models accurately measures fine-grained joint correctness and semantic controllability without introducing its own biases or blind spots.
What would settle it
A controlled study in which human raters score the same set of generated audio-video clips on the benchmark's semantic criteria and the scores diverge substantially from the automated framework's results.
Figures










read the original abstract
Text-to-Audio-Video (T2AV) generation is rapidly becoming a core interface for media creation, yet its evaluation remains fragmented. Existing benchmarks largely assess audio and video in isolation or rely on coarse embedding similarity, failing to capture the fine-grained joint correctness required by realistic prompts. We introduce AVGen-Bench, a task-driven benchmark for T2AV generation featuring high-quality prompts across 11 real-world categories. To support comprehensive assessment, we propose a multi-granular evaluation framework that combines lightweight specialist models with Multimodal Large Language Models (MLLMs), enabling evaluation from perceptual quality to fine-grained semantic controllability. Our evaluation reveals a pronounced gap between strong audio-visual aesthetics and weak semantic reliability, including persistent failures in text rendering, speech coherence, physical reasoning, and a universal breakdown in musical pitch control. Code and benchmark resources are available at http://aka.ms/avgenbench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AVGen-Bench, a task-driven benchmark for text-to-audio-video (T2AV) generation consisting of high-quality prompts across 11 real-world categories. It proposes a multi-granular evaluation framework that combines lightweight specialist models with Multimodal Large Language Models (MLLMs) to assess perceptual quality through fine-grained semantic controllability. The evaluation of existing T2AV models reveals a pronounced gap between strong audio-visual aesthetics and weak semantic reliability, with specific persistent failures in text rendering, speech coherence, physical reasoning, and musical pitch control.
Significance. If the multi-granular framework can be validated as reliable, the benchmark would address a clear gap in T2AV evaluation by moving beyond isolated audio/video metrics or coarse embeddings toward joint semantic correctness. This could help the community track progress on controllability issues that current generators struggle with.
major comments (1)
- [Evaluation Framework and Results] The central claim of a gap between aesthetics and semantic reliability (including failures in pitch control, speech coherence, and physical reasoning) rests on MLLM judgments for fine-grained semantic controllability. However, the manuscript provides no reported validation of these MLLM scores against human experts, objective ground truth, or inter-rater agreement metrics, nor any ablation isolating the MLLM component. This leaves open the possibility that observed failures reflect evaluator limitations rather than generator deficiencies.
minor comments (2)
- [Benchmark Construction] The abstract and high-level description mention 11 categories and the availability of code/resources, but the manuscript should include a table or appendix explicitly listing the categories, prompt counts, and example prompts to allow reproducibility.
- [Evaluation Framework] Clarify the exact division of labor between the lightweight specialist models and the MLLMs (e.g., which metrics each handles) to avoid ambiguity in the multi-granular framework description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on validation of the MLLM component below and will revise the manuscript accordingly to strengthen the evaluation framework.
read point-by-point responses
-
Referee: [Evaluation Framework and Results] The central claim of a gap between aesthetics and semantic reliability (including failures in pitch control, speech coherence, and physical reasoning) rests on MLLM judgments for fine-grained semantic controllability. However, the manuscript provides no reported validation of these MLLM scores against human experts, objective ground truth, or inter-rater agreement metrics, nor any ablation isolating the MLLM component. This leaves open the possibility that observed failures reflect evaluator limitations rather than generator deficiencies.
Authors: We agree that the absence of explicit validation for the MLLM judgments represents a limitation in the current manuscript. While the multi-granular framework combines specialist models for perceptual aspects with MLLMs for semantic controllability, and the MLLM prompts were designed to target specific failure modes identified in preliminary checks, we did not report human agreement or ablation studies. In the revised manuscript, we will add a human evaluation on a representative subset of prompts (e.g., 200 samples across categories), reporting inter-rater agreement metrics and correlation with MLLM scores. We will also include an ablation isolating the MLLM component to demonstrate its contribution to detecting the reported semantic gaps. This will directly address the concern that failures may reflect evaluator limitations. revision: yes
Circularity Check
No circularity: empirical benchmark with independent evaluation framework
full rationale
The paper proposes AVGen-Bench as a new task-driven benchmark and multi-granular evaluation framework combining specialist models with MLLMs. No derivations, equations, fitted parameters, or predictions are present that reduce to prior quantities by construction. The central claim (gap between aesthetics and semantic reliability) is an empirical observation from applying the framework to existing generators, not a self-referential result. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The evaluation methodology is presented as a novel contribution without reducing to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://openai.com/research/ video-generation-models-as-world-simulators . Accessed: 2024-02-15. OpenAI. Sora 2 System Card, 2025. URL https://cdn.openai.com/pdf/ 50d5973c-c4ff-4c2d-986f-c72b5d0ff069/ sora_2_system_card.pdf. Accessed: 2026-01- 22. OpenAI. Introducing gpt-5.2, 2026. URL https:// openai.com/index/introducing-gpt-5-2/ . Accessed: 2026-01...
-
[2]
Google Blog. Accessed: 2026-03-16. Runway. Introducing gen-3 alpha, 2024. URL https://runwayml.com/research/ introducing-gen-3-alpha . Accessed: 2026-01- 23. Seedance, T., Chen, H., Chen, S., Chen, X., Chen, Y ., Chen, Y ., Chen, Z., Cheng, F., Cheng, T., Cheng, X., Chi, X., et al. Seedance 1.5 pro: A native audio- visual joint generation foundation model...
-
[3]
• Rationale:Determining ”which voice sounds more natural” is cognitively easier and more consistent via side-by-side comparison than absolute scoring
Pairwise Comparison for Subjective Quality (Speech & Semantic).For dimensions where quality is often relative or nuanced—such asSpeech QualityandHolistic Semantic Alignment—we utilized aBlind A/B Testingprotocol (Figure 11a). • Rationale:Determining ”which voice sounds more natural” is cognitively easier and more consistent via side-by-side comparison tha...
-
[4]
A pairwise comparison might result in a ”Tie” if both models produce gibberish, failing to capture the absolute failure
Pointwise Scoring for Objective Correctness (Text Rendering).Conversely, text rendering requires an absolute assessment of legibility and spelling correctness. A pairwise comparison might result in a ”Tie” if both models produce gibberish, failing to capture the absolute failure. Therefore, we adopted aPointwise Protocol(Figure 11b). • Rationale:Text qual...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.