Recognition: unknown
Seeing but Not Thinking: Routing Distraction in Multimodal Mixture-of-Experts
Pith reviewed 2026-05-10 16:58 UTC · model grok-4.3
The pith
Multimodal MoE models see images correctly but fail to reason because routing skips domain experts in middle layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Visual inputs trigger routing divergence from text inputs in middle layers of multimodal MoE models, where domain experts concentrate; as a result the routing mechanism under-activates task-relevant reasoning experts even though perception succeeds, producing a seeing-but-not-thinking failure that a routing-guided intervention corrects.
What carries the argument
Layer-wise separation of visual experts from domain experts, which produces routing divergence on image inputs and thereby under-activates reasoning capacity.
If this is right
- Enhancing domain-expert activation via routing guidance yields consistent gains on complex visual reasoning tasks.
- Domain experts identified by the method capture transferable cognitive functions rather than task-specific solutions.
- Cross-modal semantic sharing rules out alignment failure as the sole explanation for the performance gap.
Where Pith is reading between the lines
- The same routing-steering approach could be applied to other MoE vision-language models without full retraining.
- Routing design choices may need explicit separation of perception and reasoning pathways in future multimodal architectures.
- Testing whether forcing text-like routing on visual inputs closes the entire performance gap would directly probe the hypothesis.
Load-bearing premise
The layer-wise separation of visual and domain experts together with the observed routing divergence is the primary driver of the reasoning shortfall rather than training data composition or optimization dynamics.
What would settle it
If the routing-guided intervention produces no accuracy gains on the six benchmarks or if middle-layer routing divergence shows no correlation with reasoning errors, the Routing Distraction hypothesis would be falsified.
Figures






read the original abstract
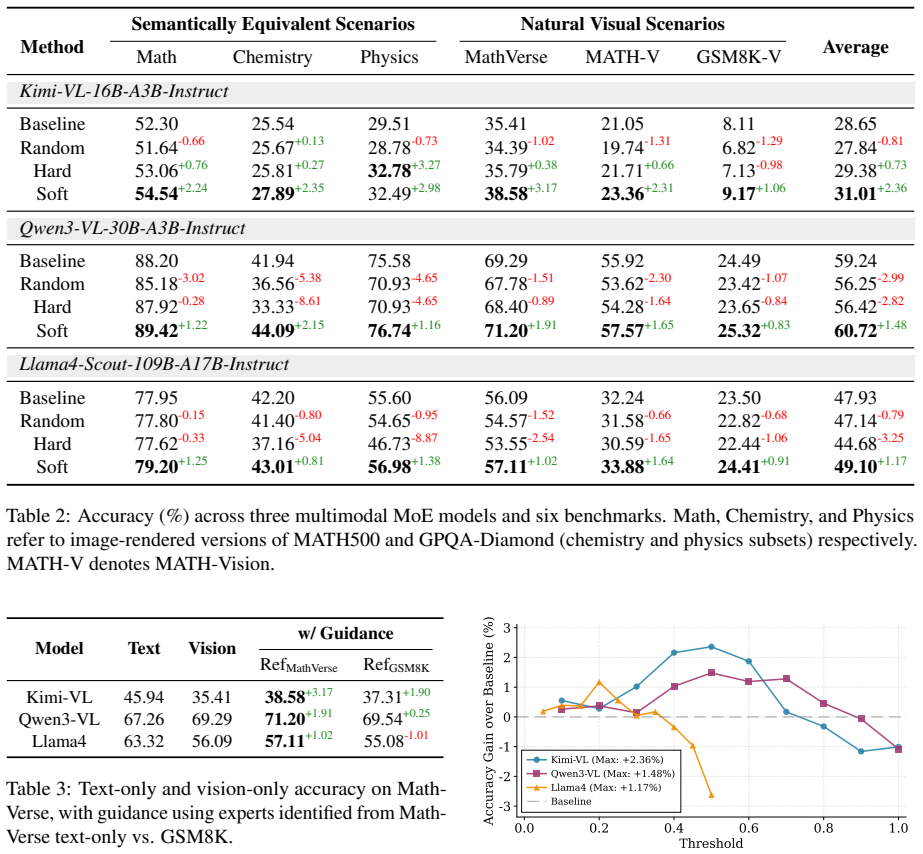
Multimodal Mixture-of-Experts (MoE) models have achieved remarkable performance on vision-language tasks. However, we identify a puzzling phenomenon termed Seeing but Not Thinking: models accurately perceive image content yet fail in subsequent reasoning, while correctly solving identical problems presented as pure text. Through systematic analysis, we first verify that cross-modal semantic sharing exists in MoE architectures, ruling out semantic alignment failure as the sole explanation. We then reveal that visual experts and domain experts exhibit layer-wise separation, with image inputs inducing significant routing divergence from text inputs in middle layers where domain experts concentrate. Based on these findings, we propose the Routing Distraction hypothesis: when processing visual inputs, the routing mechanism fails to adequately activate task-relevant reasoning experts. To validate this hypothesis, we design a routing-guided intervention method that enhances domain expert activation. Experiments on three multimodal MoE models across six benchmarks demonstrate consistent improvements, with gains of up to 3.17% on complex visual reasoning tasks. Our analysis further reveals that domain expert identification locates cognitive functions rather than sample-specific solutions, enabling effective transfer across tasks with different information structures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'Seeing but Not Thinking' phenomenon in multimodal MoE models, where visual inputs are perceived accurately but lead to reasoning failures unlike equivalent text problems. Analysis reveals cross-modal semantic sharing but also layer-wise separation of visual and domain experts, with image inputs causing routing divergence in middle layers. The authors propose the Routing Distraction hypothesis and validate it via a routing-guided intervention that increases domain-expert activation, reporting consistent gains up to 3.17% on complex visual reasoning tasks across three models and six benchmarks. They further claim that identified domain experts capture general cognitive functions transferable across tasks.
Significance. If the causal mechanism holds, the work provides a useful diagnostic for routing behavior in multimodal MoE architectures and a lightweight intervention to improve reasoning performance without retraining. The multi-model, multi-benchmark consistency and the observation that domain-expert identification supports cross-task transfer are notable strengths that could inform future MoE interpretability and design.
major comments (2)
- [§4] §4 (Routing-Guided Intervention): The validation experiments apply a targeted intervention to enhance domain-expert activation but omit control conditions that apply comparable routing perturbations (e.g., forcing an equal number of non-domain or random experts in the same middle layers) while preserving the original visual inputs. Without these controls, the reported gains cannot be unambiguously attributed to reversal of the specific layer-wise separation rather than general rebalancing, increased capacity, or optimization artifacts.
- [§5] §5 (Experimental Results): The performance improvements (up to 3.17%) are presented without statistical significance tests, standard deviations from multiple random seeds, or ablations that isolate the intervention from baseline routing variance. This weakens the claim of consistent, robust gains supporting the hypothesis, especially given that intervention parameters are selected based on the same routing observations used to define the problem.
minor comments (2)
- [Abstract and §3] The abstract and §3 would benefit from explicit quantitative metrics (e.g., KL-divergence or routing probability differences) for the reported layer-wise divergence between text and image inputs.
- [§2 and §3] Notation for expert types (visual vs. domain) and routing scores could be standardized with a single table or equation early in the paper to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the rigor of our experimental validation. We address the major concerns point by point below.
read point-by-point responses
-
Referee: [§4] §4 (Routing-Guided Intervention): The validation experiments apply a targeted intervention to enhance domain-expert activation but omit control conditions that apply comparable routing perturbations (e.g., forcing an equal number of non-domain or random experts in the same middle layers) while preserving the original visual inputs. Without these controls, the reported gains cannot be unambiguously attributed to reversal of the specific layer-wise separation rather than general rebalancing, increased capacity, or optimization artifacts.
Authors: We agree that control experiments are necessary to establish the specificity of the routing-guided intervention. In the revised version of the manuscript, we will add experiments that apply comparable perturbations by forcing activation of non-domain experts or randomly selected experts in the middle layers, while keeping the visual inputs unchanged. These controls will allow us to attribute the performance gains more confidently to the targeted activation of domain experts, addressing potential confounds from general rebalancing or capacity increases. revision: yes
-
Referee: [§5] §5 (Experimental Results): The performance improvements (up to 3.17%) are presented without statistical significance tests, standard deviations from multiple random seeds, or ablations that isolate the intervention from baseline routing variance. This weakens the claim of consistent, robust gains supporting the hypothesis, especially given that intervention parameters are selected based on the same routing observations used to define the problem.
Authors: We acknowledge the importance of statistical rigor and ablations for validating the robustness of our results. We will revise the experimental section to include multiple runs with different random seeds, reporting mean performance with standard deviations. We will also conduct statistical significance tests, such as paired t-tests, to assess the improvements. Furthermore, we will perform additional ablations on the intervention parameters to isolate their effects from baseline routing variance and to demonstrate that the gains are not artifacts of parameter selection based on the routing analysis. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's chain moves from routing measurements and layer-wise expert separation analysis to a proposed Routing Distraction hypothesis, then to a routing-guided intervention tested for performance gains. This uses three distinct models and six external benchmarks for validation, with no equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claim to its own inputs by construction. The intervention is presented as a test of the hypothesis rather than a definitional re-expression of the initial observations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MoE models route tokens to experts via a learned gating function that can be measured per layer and modality.
- domain assumption Semantic content is shared between vision and language pathways in the tested models.
invented entities (1)
-
Routing Distraction
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kimi-vl technical report.arXiv preprint arXiv:2504.07491. Angela van Sprang, Laurens Samson, Ana Lucic, Erman Acar, Sennay Ghebreab, and Yuki M Asano. 2025. Same content, different answers: Cross-modal incon- sistency in mllms.arXiv preprint arXiv:2512.08923. Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li
work page internal anchor Pith review arXiv 2025
-
[2]
Measuring multimodal mathematical reason- ing with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169. Mengru Wang, Xingyu Chen, Yue Wang, Zhiwei He, Jiahao Xu, Tian Liang, Qiuzhi Liu, Yunzhi Yao, Wenxuan Wang, Ruotian Ma, and 1 others. 2025a. Two experts are all you need for steering think- ing: Reinforcing cognitive ef...
-
[3]
Openmoe: An early effort on open mixture-of-experts language models.arXiv preprint arXiv:2402.01739. Fan Yuan, Yuchen Yan, Yifan Jiang, Haoran Zhao, Tao Feng, Jinyan Chen, Yanwei Lou, Wenqi Zhang, Yongliang Shen, Weiming Lu, and 1 others. 2025. Gsm8k-v: Can vision language models solve grade school math word problems in visual contexts.arXiv preprint arXi...
-
[4]
**Text Problem**: `{text_problem}`
-
[5]
A model answered based on the image and produced:
**Correct Text Solution** (guaranteed correct ): `{text_solution}` Now the same problem has been converted into an **equivalent image** (same content, just visual). A model answered based on the image and produced:
-
[6]
**Model Answer (from the image)**: `{model_answer}` This model answer is **wrong**. **Task:** Determine the most likely error type: - **Information Reading Error**: The model misread, overlooked, or failed to extract key information from the image (e.g., missed a condition, misread a number/symbol, ignored part of the diagram/text). - **Reasoning Error**:...
-
[7]
Briefly list the key information that must be extracted from the problem to solve it
-
[8]
Compare the **Model Answer** with the ** Correct Text Solution** and infer whether the model likely failed at reading/extraction or at reasoning
-
[9]
Output **only one label**:`Information Reading Error`or`Reasoning Error`
-
[10]
Acc (OCR first)
Then give a **one-sentence justification**. Dataset Acc Acc (OCR first) Perception Error Reasoning Error MATH500 92.8 - - - MATH500-v1 89.0 87.4 31.8% (7/22) 68.2% (15/22) MATH500-v2 88.2 86.8 26.9% (7/26) 73.1% (19/26) MATH500-v3 87.4 86.8 31.0% (9/29) 69.0% (20/29) Table 6: Accuracy comparison and error analysis on MATH500 and its three image versions. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.