Recognition: 2 theorem links
· Lean TheoremWAND: Windowed Attention and Knowledge Distillation for Efficient Autoregressive Text-to-Speech Models
Pith reviewed 2026-05-15 10:26 UTC · model grok-4.3
The pith
WAND splits attention into global conditioning and local windows on generated tokens to cut KV cache memory by up to 66 percent in autoregressive TTS while keeping quality and constant latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
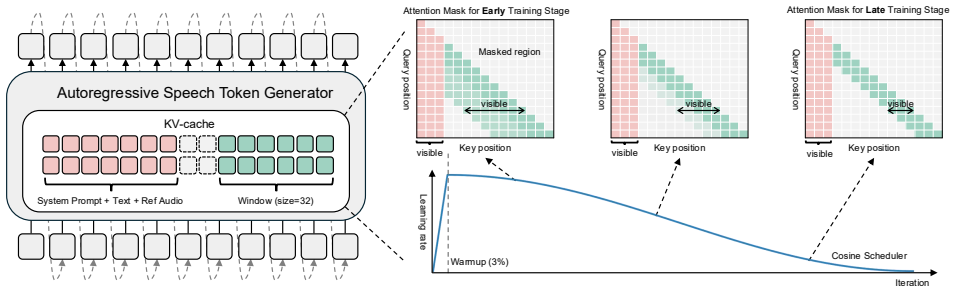
WAND replaces full self-attention in pretrained AR-TTS models with a split mechanism: persistent global attention is retained over the conditioning tokens while a local sliding-window attention is applied only to the generated tokens. Curriculum learning progressively tightens the window size during adaptation, and knowledge distillation from the original full-attention teacher recovers synthesis quality. Across three modern AR-TTS models this yields up to 66.2 percent KV cache memory reduction together with length-invariant near-constant per-step latency, all without measurable loss of audio fidelity.
What carries the argument
The split attention design that keeps persistent global attention on conditioning tokens while restricting generated tokens to local sliding-window attention, stabilized by curriculum learning and knowledge distillation from a full-attention teacher.
If this is right
- KV cache memory drops by up to 66.2 percent.
- Per-step latency becomes nearly constant and independent of output length.
- Original synthesis quality is retained across the tested models.
- The same adaptation works on multiple different pretrained AR-TTS architectures.
- Distillation allows recovery of quality with high data efficiency.
Where Pith is reading between the lines
- The same window-plus-distillation pattern could be tested on other autoregressive generation tasks such as language modeling.
- Mobile or embedded TTS deployments become feasible because memory demand no longer scales with utterance length.
- Local context after the initial conditioning may be sufficient for most speech coherence, suggesting future adaptive window sizes tuned to phonetic or prosodic boundaries.
Load-bearing premise
That global attention on the fixed conditioning tokens plus local sliding-window attention on the generated sequence, when trained with curriculum learning and distillation, captures every long-range dependency required for high-fidelity speech.
What would settle it
A controlled experiment showing clear drops in perceptual quality metrics on long utterances when the sliding window is enforced without the distillation step or when the window size is made too small.
Figures

read the original abstract
Recent decoder-only autoregressive text-to-speech (AR-TTS) models produce high-fidelity speech, but their memory and compute costs scale quadratically with sequence length due to full self-attention. In this paper, we propose WAND, Windowed Attention and Knowledge Distillation, a framework that adapts pretrained AR-TTS models to operate with constant computational and memory complexity. WAND separates the attention mechanism into two: persistent global attention over conditioning tokens and local sliding-window attention over generated tokens. To stabilize fine-tuning, we employ a curriculum learning strategy that progressively tightens the attention window. We further utilize knowledge distillation from a full-attention teacher to recover high-fidelity synthesis quality with high data efficiency. Evaluated on three modern AR-TTS models, WAND preserves the original quality while achieving up to 66.2% KV cache memory reduction and length-invariant, near-constant per-step latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WAND, which adapts pretrained autoregressive TTS models by splitting attention into persistent global attention over fixed conditioning tokens and local sliding-window attention over the growing generated token sequence. Curriculum learning progressively tightens the window during fine-tuning, and knowledge distillation from a full-attention teacher recovers quality. The central empirical claim is that this yields up to 66.2% KV-cache memory reduction and length-invariant near-constant per-step latency while preserving original synthesis quality across three modern AR-TTS models.
Significance. If the quality-preservation claim holds under rigorous metrics, the work would offer a practical, data-efficient route to constant-complexity inference for decoder-only TTS, directly addressing quadratic scaling that currently limits sequence length and deployment. The combination of windowed attention with distillation and curriculum is a concrete engineering contribution that could be adopted by existing AR-TTS pipelines.
major comments (2)
- [Evaluation] Evaluation section: the abstract and results claim quality preservation and a 66.2% KV-cache reduction, yet no concrete metrics (MOS, WER, spectrogram distance), baseline comparisons, statistical significance tests, or ablation on window size versus full attention are reported. This absence directly undermines verification of the central claim.
- [Method] Method (curriculum + distillation subsection): no explicit measurement or diagnostic is given for whether long-range prosodic/phonetic dependencies among generated tokens survive the sliding-window restriction; the paper relies on indirect recovery via distillation without quantifying residual error on long-span phenomena.
minor comments (2)
- [Abstract] Abstract: the 66.2% memory-reduction figure should state the exact model, sequence length, and KV-cache configuration used to obtain it.
- [Method] Notation: the distinction between conditioning-token attention and generated-token window should be given a single consistent symbol or diagram label for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We agree that strengthening the quantitative evaluation and adding explicit diagnostics for long-range dependencies will improve the manuscript. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the abstract and results claim quality preservation and a 66.2% KV-cache reduction, yet no concrete metrics (MOS, WER, spectrogram distance), baseline comparisons, statistical significance tests, or ablation on window size versus full attention are reported. This absence directly undermines verification of the central claim.
Authors: We acknowledge the validity of this observation. Although the abstract summarizes the outcomes, the evaluation section in the current draft does not present the underlying metrics in sufficient detail. In the revised manuscript we will expand the evaluation section to report MOS scores, WER, mel-spectrogram distances, direct comparisons to the original full-attention models, paired statistical significance tests, and ablations across multiple window sizes. These results already exist from our experiments and confirm both quality preservation and the stated KV-cache savings. revision: yes
-
Referee: [Method] Method (curriculum + distillation subsection): no explicit measurement or diagnostic is given for whether long-range prosodic/phonetic dependencies among generated tokens survive the sliding-window restriction; the paper relies on indirect recovery via distillation without quantifying residual error on long-span phenomena.
Authors: We agree that a direct diagnostic would be valuable. The curriculum schedule and distillation objective are intended to preserve long-range structure, yet we did not quantify residual degradation on long-span prosody or phonetics. In the revision we will add a dedicated analysis subsection that measures F0 correlation and phoneme-level accuracy across distant tokens, comparing WAND outputs against the teacher model on long utterances. This will make any remaining gaps explicit. revision: yes
Circularity Check
Empirical adaptation using standard techniques with no self-referential derivations
full rationale
The paper presents WAND as a practical framework that modifies pretrained AR-TTS models by splitting attention into global conditioning and local sliding-window on generated tokens, stabilized via curriculum tightening and distillation from a full-attention teacher. No equations, uniqueness theorems, or central claims reduce by construction to fitted parameters or self-citations defined within the paper. Evaluation metrics (KV cache reduction, latency) are measured externally on three existing models. This matches the default non-circular case for an engineering adaptation paper; the minor score accounts for routine self-citation of prior TTS work that is not load-bearing for the core claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained AR-TTS models can be fine-tuned with modified attention patterns without catastrophic loss of synthesis quality when curriculum learning and knowledge distillation are applied.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WAND separates the attention mechanism into two: persistent global attention over conditioning tokens and local sliding-window attention over generated tokens. ... pθ(yt | y<t, s, x, apr) ≈ pθ(yt | yt−W:t−1, s, x, apr)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Curriculum learning strategy that progressively tightens the attention window ... temperature-controlled soft mask
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Introduction Text-to-Speech (TTS) models leveraging Transformer-based large language model (LLM) backbones have demonstrated the capability to generate near-human-quality speech from short reference audio [1, 2, 3, 4]. By utilizing neural audio codecs [5, 6], these models treat speech as discrete token se- quences, enabling the direct adaptation of text-b...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Method 2.1. Attention Restriction with Sliding Window Decoding We posit that AR-TTS relies on two distinct types of informa- tion:global context, which determines the invariant character- istics of the generation, andlocal context, which governs fine- grained acoustic transitions. By decoupling these, we can re- strict the model’s temporal attention to a ...
-
[3]
Experiments Datasets & Fine-Tuning Configurations.We conduct fine-tuning experiments on thetrain-clean-100subset of LibriTTS [26], which contains approximately 100 hours of transcribed speech(≈1% of the data used to train the base- lines). Notably, we intentionally use only this modest subset rather than the full 580-hour corpus, demonstrating that W AND ...
-
[4]
Analysis 4.1. Target-Language Speech Quality As demonstrated in Table 1, W AND maintains high-fidelity synthesis across all evaluated architectures on the Seed-TTS test-enbenchmark. Notably, the absolute word error rate (WER) either remains within 0.2% of the baseline or exhibits slight improvement, as observed in CosyV oice 2, where the WER decreased fro...
-
[5]
Conclusion In conclusion,W ANDsuccessfully transforms the computa- tional and memory scaling of AR-TTS from linear to constant by bifurcating the attention mechanism into persistentGlobal AttentionandLocal Sliding-Window Attention. Our evaluations across CosyV oice 2, IndexTTS 1.5, and SparkTTS demonstrate that bounded KV caching enables constant per-step...
-
[6]
All scientific content, experimental design, and analysis were con- ducted solely by the authors
Generative AI Use Disclosure Generative AI tools (Claude, Anthropic) were used to assist with grammar correction and polishing of the manuscript. All scientific content, experimental design, and analysis were con- ducted solely by the authors. All authors take full responsibility for the content of this paper
-
[7]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Li, L. He, S. Zhao, and F. Wei, “Neural codec language models are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
X. Wang, M. Gu, W. Liet al., “Spark-tts: An efficient llm- based text-to-speech model with single-stream decoupled speech tokens,”arXiv preprint arXiv:2503.01710, 2025
-
[9]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Duet al., “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Indextts: An industrial-level controllable and efficient zero-shot text-to-speech system,
W. Deng, S. Zhou, J. Shu, J. Wang, and L. Wang, “Indextts: An industrial-level controllable and efficient zero-shot text-to-speech system,”arXiv preprint arXiv:2502.05512, 2025
-
[11]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”Transactions on Machine Learning Research, 2023
work page 2023
-
[12]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2021
work page 2021
-
[13]
Tacotron: Towards end-to-end speech synthesis,
Y . Wang, R. Skerry-Ryan, D. Stanton, Y . Wu, R. J. Weiss, N. Jaitly, Z. Yang, Y . Xiao, Z. Chen, S. Bengioet al., “Tacotron: Towards end-to-end speech synthesis,”Interspeech 2017, p. 4006, 2017
work page 2017
-
[14]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,
J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” inInter- national conference on machine learning. PMLR, 2021, pp. 5530–5540
work page 2021
-
[15]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[16]
Long-form speech generation with spoken lan- guage models,
S. J. Park, J. Salazar, A. Jansen, K. Kinoshita, Y . M. Ro, and R. Skerry-Ryan, “Long-form speech generation with spoken lan- guage models,” inProceedings of the 42nd International Confer- ence on Machine Learning, vol. 267, 2025, pp. 48 245–48 261
work page 2025
-
[17]
The unreasonable ineffectiveness of the deeper lay- ers,
A. Gromov, K. Tirumala, H. Shapourian, P. Glorioso, and D. Roberts, “The unreasonable ineffectiveness of the deeper lay- ers,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[18]
ShortGPT: Layers in large language mod- els are more redundant than you expect,
X. Men, M. Xu, Q. Zhang, Q. Yuan, B. Wang, H. Lin, Y . Lu, X. Han, and W. Chen, “ShortGPT: Layers in large language mod- els are more redundant than you expect,” inFindings of the Asso- ciation for Computational Linguistics: ACL 2025, Jul. 2025, pp. 20 192–20 204
work page 2025
-
[19]
Spade: Structured pruning and adaptive distillation for efficient llm-tts,
T. D. Nguyen, J. Kim, J.-H. Kim, S. Choi, Y . Lim, and J. S. Chung, “Spade: Structured pruning and adaptive distillation for efficient llm-tts,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026
work page 2026
-
[20]
Gated linear attention transformers with hardware-efficient training,
S. Yang, B. Wang, Y . Shen, R. Panda, and Y . Kim, “Gated linear attention transformers with hardware-efficient training,” inPro- ceedings of the 41st International Conference on Machine Learn- ing, ser. ICML’24. JMLR.org, 2024
work page 2024
-
[21]
T. Lemerle, H. Music, N. Obin, and A. Roebel, “Lina-speech: Gated linear attention is a fast and parameter-efficient learner for text-to-speech synthesis,”arXiv preprint arXiv:2410.23320, 2024
-
[22]
T. Dao and A. Gu, “Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality,” in International Conference on Machine Learning (ICML), 2024
work page 2024
-
[23]
X. Jiang, Y . A. Li, A. N. Florea, C. Han, and N. Mesgarani, “Speech slytherin: Examining the performance and efficiency of mamba for speech separation, recognition, and synthesis,” in ICASSP. IEEE, 2025, pp. 1–5
work page 2025
-
[24]
Fast inference from transformers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transformers via speculative decoding,” inInternational Confer- ence on Machine Learning. PMLR, 2023, pp. 19 274–19 286
work page 2023
-
[25]
Accelerating codec-based speech synthesis with multi- token prediction and speculative decoding,
T. D. Nguyen, J.-H. Kim, J. Choi, S. Choi, J. Park, Y . Lee, and J. S. Chung, “Accelerating codec-based speech synthesis with multi- token prediction and speculative decoding,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
work page 2025
-
[26]
Fast and high- quality auto-regressive speech synthesis via speculative decod- ing,
B. Li, H. Wang, S. Zhang, Y . Guo, and K. Yu, “Fast and high- quality auto-regressive speech synthesis via speculative decod- ing,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025
work page 2025
-
[27]
Efficiently scaling transformer inference,
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean, “Efficiently scaling transformer inference,”Proceedings of machine learning and sys- tems, vol. 5, pp. 606–624, 2023
work page 2023
-
[28]
Efficient memory manage- ment for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory manage- ment for large language model serving with pagedattention,” in Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[29]
Efficient streaming language models with attention sinks,
G. Xiao, Y . Tian, B. Chen, S. Han, and M. Lewis, “Efficient streaming language models with attention sinks,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[30]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
DistiLLM: Towards streamlined distillation for large language models,
J. Ko, S. Kim, T. Chen, and S.-Y . Yun, “DistiLLM: Towards streamlined distillation for large language models,” inProceed- ings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235, 2024, pp. 24 872–24 895
work page 2024
-
[32]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech,” inInterspeech 2019, 2019, pp. 1526–1530
work page 2019
-
[33]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Weiet al., “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
P. Anastassiou, J. Chen, J. Chen, Y . Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gaoet al., “Seed-tts: A family of high-quality versatile speech generation models,”arXiv preprint arXiv:2406.02430, 2024
work page internal anchor Pith review arXiv 2024
-
[35]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
work page 2023
-
[36]
Funasr: A fundamental end-to-end speech recog- nition toolkit,
Z. Gaoet al., “Funasr: A fundamental end-to-end speech recog- nition toolkit,” inProc. INTERSPEECH, 2023
work page 2023
-
[37]
Wavlm: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
work page 2022
-
[38]
Utmos: Utokyo-sarulab system for voicemos challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos challenge 2022,”Interspeech 2022, 2022
work page 2022
-
[39]
GQA: Training generalized multi-query trans- former models from multi-head checkpoints,
J. Ainslie, J. Lee-Thorp, M. de Jong, Y . Zemlyanskiy, F. Lebron, and S. Sanghai, “GQA: Training generalized multi-query trans- former models from multi-head checkpoints,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 4895–4901
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.