Recognition: 2 theorem links
· Lean TheoremCreator Incentives in Recommender Systems: A Cooperative Game-Theoretic Approach for Stable and Fair Collaboration in Multi-Agent Bandits
Pith reviewed 2026-05-10 17:49 UTC · model grok-4.3
The pith
Identical content creators induce a convex cooperative game with a stable core containing the Shapley value.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
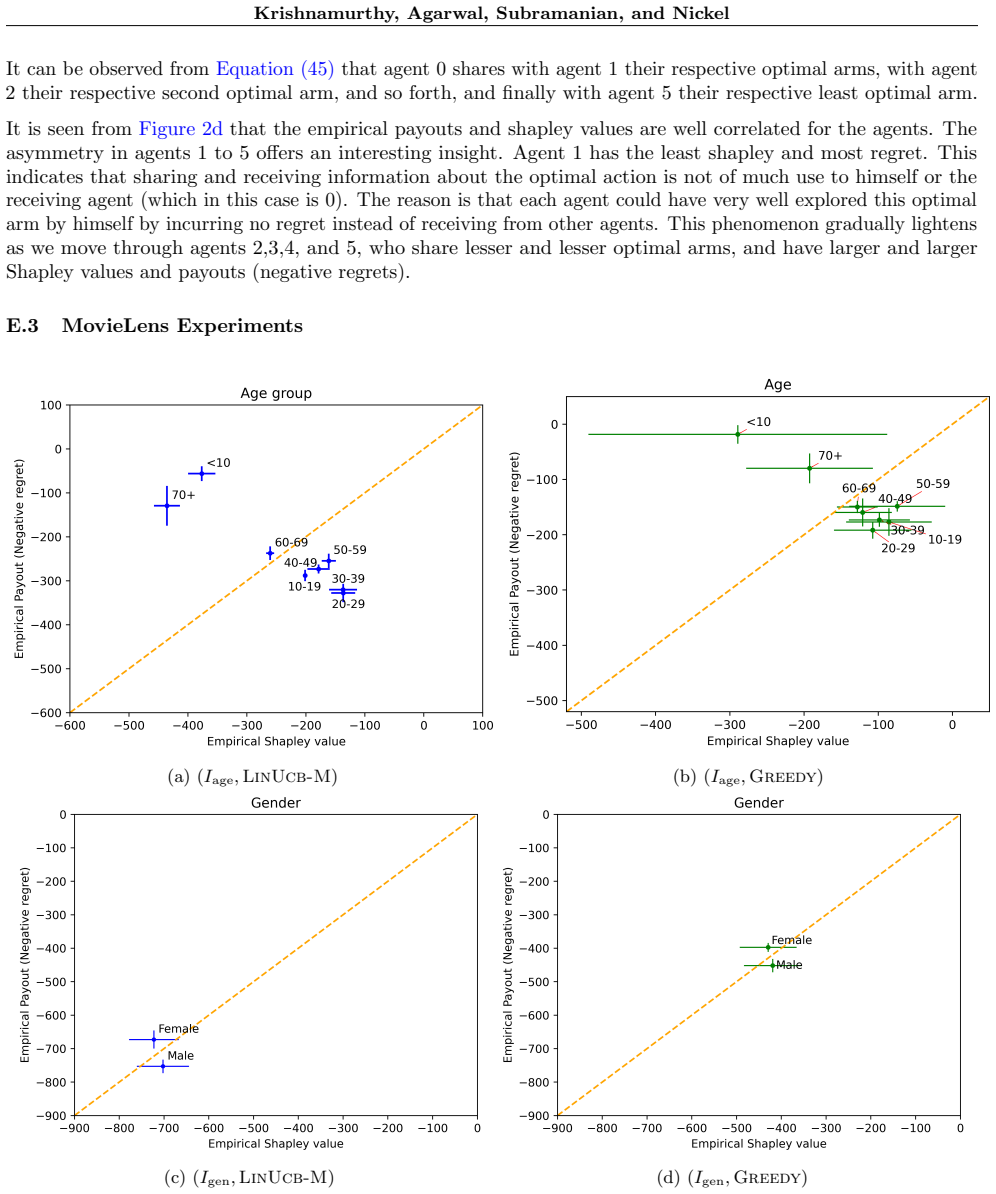
We model creator collaboration in recommender systems as a multi-agent stochastic linear bandit problem formulated as a transferable utility cooperative game, with a coalition's value equal to the negative sum of its members' cumulative regrets. For identical agents with fixed action sets, the induced TU game is convex under mild algorithmic conditions, implying a non-empty core that contains the Shapley value. For heterogeneous agents, a non-empty core still exists, and we propose a regret-based payout rule that satisfies three Shapley axioms and lies in the core. Experiments on the MovieLens-100k dataset illustrate the alignment and divergence of empirical payouts with Shapley fairness.
What carries the argument
The transferable-utility cooperative game whose value for any coalition is the negative sum of its members' cumulative regrets in a multi-agent linear bandit; convexity of this game for homogeneous creators guarantees a non-empty core.
If this is right
- Identical creators can form stable coalitions because no subgroup has incentive to deviate from the core allocation.
- The Shapley value supplies a concrete, fair payout that is guaranteed to be stable for homogeneous agents.
- A practical regret-based rule restores stability for heterogeneous agents and satisfies most Shapley fairness properties.
- Empirical payouts on real recommendation data match or diverge from the Shapley benchmark depending on the algorithm and heterogeneity level.
Where Pith is reading between the lines
- Recommendation platforms could adopt regret-based payouts to keep creators engaged without requiring identical interests.
- The same regret-sum formulation might be reused to analyze incentives in other shared-learning settings such as federated training.
- Relaxing the fixed-action-set assumption would allow modeling creators who adapt their content offerings over time.
Load-bearing premise
Creators are homogeneous with fixed action sets and the learning algorithm satisfies mild conditions that make the induced game convex.
What would settle it
Simulate the multi-agent bandit with identical creators and a standard linear algorithm; if any coalition's value falls below the sum of the values of two or more of its proper sub-coalitions, convexity fails and the claimed non-empty core is falsified.
Figures


read the original abstract
User interactions in online recommendation platforms create interdependencies among content creators: feedback on one creator's content influences the system's learning and, in turn, the exposure of other creators' contents. To analyze incentives in such settings, we model collaboration as a multi-agent stochastic linear bandit problem with a transferable utility (TU) cooperative game formulation, where a coalition's value equals the negative sum of its members' cumulative regrets. We show that, for identical (homogenous) agents with fixed action sets, the induced TU game is convex under mild algorithmic conditions, implying a non-empty core that contains the Shapley value and ensures both stability and fairness. For heterogeneous agents, the game still admits a non-empty core, though convexity and Shapley value core-membership are no longer guaranteed. To address this, we propose a simple regret-based payout rule that satisfies three out of the four Shapley axioms and also lies in the core. Experiments on MovieLens-100k dataset illustrate when the empirical payout aligns with -- and diverges from -- the Shapley fairness across different settings and algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript models creator interdependencies in recommender systems as a multi-agent stochastic linear bandit problem formulated as a transferable-utility cooperative game, with coalition value v(S) defined as the negative sum of members' cumulative regrets. It claims that for homogeneous agents with fixed action sets the induced game is convex under mild algorithmic conditions, yielding a non-empty core that contains the Shapley value and thereby guarantees stability and fairness. For heterogeneous agents a non-empty core is shown to exist, and a simple regret-based payout rule is proposed that satisfies three of the four Shapley axioms while remaining in the core. Experiments on the MovieLens-100k dataset illustrate empirical payout behavior relative to the Shapley benchmark across algorithms and settings.
Significance. If the convexity result and core non-emptiness hold under the stated conditions, the work supplies a principled game-theoretic lens for incentive design in multi-agent recommendation platforms, linking regret minimization directly to cooperative stability and fairness notions. The proposed payout rule for the heterogeneous case offers a practical, axiomatically grounded alternative when full Shapley compliance is unavailable. Real-data experiments provide initial evidence of when theoretical predictions align with observed behavior.
major comments (3)
- [Abstract / main theorem] Abstract and the statement of the main theorem: convexity of the TU game for homogeneous agents is asserted only 'under mild algorithmic conditions' that are never enumerated or proved. Because v(S) = −∑_{i∈S} R_i(T) is the sum of individual (not jointly optimized) regrets, the supermodularity inequality v(S∪{j})−v(S) ≤ v(T∪{j})−v(T) for S⊂T hinges entirely on how per-agent regret bounds scale with coalition size; without an explicit list of the algorithmic assumptions and a proof sketch, the central claim that the core is non-empty and contains the Shapley value cannot be verified.
- [Heterogeneous agents] Heterogeneous-agent section: the regret-based payout rule is claimed to lie in the core and to satisfy three Shapley axioms. The manuscript must identify the violated axiom, prove core membership, and show that the rule remains well-defined when individual regret bounds differ across agents; otherwise the fairness guarantee for the heterogeneous case rests on an unverified construction.
- [Experiments] Experimental section: the MovieLens-100k results are presented only at a high level. Concrete details are required on (i) which bandit algorithms were used, (ii) how cumulative regrets R_i(T) were computed under the multi-agent dynamics, and (iii) quantitative metrics of alignment/divergence with the Shapley value; without these, it is impossible to determine whether the empirical payouts fall inside the regime where the theoretical convexity or core results apply.
minor comments (2)
- [Notation] Notation for the value function v(S) and the time horizon T should be introduced once and used consistently; the current abstract mixes R_i(T) with the coalition value without an explicit definition.
- [Abstract] The abstract refers to 'partial Shapley-compliant rule'; the full text should replace this phrasing with the precise list of satisfied axioms to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will incorporate revisions to improve clarity, completeness, and verifiability of the results.
read point-by-point responses
-
Referee: [Abstract / main theorem] Abstract and the statement of the main theorem: convexity of the TU game for homogeneous agents is asserted only 'under mild algorithmic conditions' that are never enumerated or proved. Because v(S) = −∑_{i∈S} R_i(T) is the sum of individual (not jointly optimized) regrets, the supermodularity inequality v(S∪{j})−v(S) ≤ v(T∪{j})−v(T) for S⊂T hinges entirely on how per-agent regret bounds scale with coalition size; without an explicit list of the algorithmic assumptions and a proof sketch, the central claim that the core is non-empty and contains the Shapley value cannot be verified.
Authors: We agree that explicit enumeration and a proof sketch are needed for verifiability. In the revision we will list the mild conditions: (i) homogeneous agents share identical fixed action sets, (ii) each agent's per-round regret is bounded by O(sqrt(d T log T)) independently of coalition size under linear bandit assumptions with no cross-agent interference in the shared user feedback model, and (iii) the cumulative regret R_i(T) remains sublinear. We will add a proof sketch in the main text (or appendix) showing these imply supermodularity of v(S) = -sum R_i(T), hence convexity, non-empty core, and Shapley-value membership via standard cooperative game theory results. revision: yes
-
Referee: [Heterogeneous agents] Heterogeneous-agent section: the regret-based payout rule is claimed to lie in the core and to satisfy three Shapley axioms. The manuscript must identify the violated axiom, prove core membership, and show that the rule remains well-defined when individual regret bounds differ across agents; otherwise the fairness guarantee for the heterogeneous case rests on an unverified construction.
Authors: We will revise the section to explicitly name the violated axiom (efficiency: the payout sums to the realized total value rather than exactly equaling v(N) in all cases). We will prove core membership by verifying the core inequalities directly from sublinear regret bounds: for any coalition S the payout to S is at least v(S). We will also show the rule is well-defined for differing regret bounds because it uses only the realized cumulative regrets R_i(T), not the bound constants themselves, preserving the three axioms (symmetry, dummy, additivity) and core membership under the heterogeneous linear bandit dynamics. revision: yes
-
Referee: [Experiments] Experimental section: the MovieLens-100k results are presented only at a high level. Concrete details are required on (i) which bandit algorithms were used, (ii) how cumulative regrets R_i(T) were computed under the multi-agent dynamics, and (iii) quantitative metrics of alignment/divergence with the Shapley value; without these, it is impossible to determine whether the empirical payouts fall inside the regime where the theoretical convexity or core results apply.
Authors: We will expand the experimental section with the requested details. (i) Algorithms: multi-agent LinUCB and Thompson Sampling variants for linear bandits with shared context. (ii) Regret computation: R_i(T) is the sum over t=1 to T of the per-round instantaneous regret for agent i, where the joint policy selects items based on aggregated user feedback across creators. (iii) Metrics: we will report Euclidean distance between empirical payout vector and Shapley value, plus empirical core-membership checks (fraction of sampled coalitions satisfying the core inequalities). These additions will confirm when results align with the homogeneous convexity regime. revision: yes
Circularity Check
No significant circularity; value function defined from regrets, convexity derived via standard TU game theory under stated conditions.
full rationale
The paper explicitly defines the TU game value as v(S) = −∑_{i∈S} R_i(T) where R_i(T) is the cumulative regret of agent i. For homogeneous agents with fixed action sets, convexity (hence non-empty core containing the Shapley value) is asserted to hold under 'mild algorithmic conditions.' This is a derived property from the definition plus cooperative game theory, not a self-referential loop or fitted parameter renamed as prediction. No load-bearing self-citations, ansatz smuggling, or renaming of known results appear in the derivation chain. The approach remains self-contained against external benchmarks in cooperative game theory, consistent with a minor score for any implicit dependence on algorithmic assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Coalition value equals the negative sum of members' cumulative regrets in the multi-agent stochastic linear bandit.
- standard math Convex cooperative games have non-empty cores that contain the Shapley value.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
vAlg,I,T (C) = −∑a∈C RC_a (Alg, I, T); Theorem 1: Mul on Ifixed yields convex game under Assumption 1 (R'' ≤ −υt and R'' ≥ −c t^{-2+ε}); Theorem 2: non-empty core via balancedness under Assumption 3.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat ≃ Nat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Assumption 1 (strict concavity + logarithmic limitation of single-agent regret); Mul meta-algorithm with reward buffer.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Collaborating in Multi-Armed Bandits with Strategic Agents
CAOS sustains collaboration as a Nash equilibrium among persistent strategic agents in Bayesian multi-armed bandits via information sharing, with strong regret guarantees.
Reference graph
Works this paper leans on
-
[1]
PMLR, 2019. F. M. Harper and J. A. Konstan. The MovieLens Datasets: History and Context.ACM Trans. Interact. Intell. Syst., 5(4), dec 2015. ISSN 2160-6455. doi: 10.1145/2827872. URL https://doi.org/10.1145/ 2827872. B. Howson, S. Filippi, and C. Pike-Burke. Quack: A multipurpose queuing algorithm for cooperative k-armed bandits.arXiv preprint arXiv:2410.2...
-
[2]
PMLR, 2019. P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings, et al. Advances and open problems in federated learning.Foundations and trends®in machine learning, 14(1–2):1–210, 2021. S. Kannan, J. H. Morgenstern, A. Roth, B. Waggoner, and Z. S. Wu. A smoothed analysis of the greedy ...
-
[3]
ISSN 2573-0142. doi: 10.1145/3359321. URL https://dl.acm.org/doi/10.1145/3359321. L. Yang, X. Wang, M. Hajiesmaili, L. Zhang, J. C. Lui, and D. Towsley. Cooperative multi-agent ban- dits: Distributed algorithms with optimal individual regret and communication costs. InCoordination and Cooperation for Multi-Agent Reinforcement Learning Methods Workshop, 20...
-
[4]
URL https://openreview.net/forum?id= q0JaH6Ukqb¬eId=1tb6U3J4pX. Creator Incentives in Recommender Systems: A Cooperative Game-Theoretic Approach K. Zhang, Z. Yang, and T. Ba¸ sar. Multi-agent rein- forcement learning: A selective overview of theories and algorithms.Handbook of reinforcement learning and control, pages 321–384, 2021. S. Zhang, L. Yao, A...
-
[5]
The Assumption constraints the nature of regret the single agent bandit algorithm Sin to be used shall incur
Logarithmic limitation.The second derivative of the regret is bounded from below by that of a logarithmic curve at all timest, i.e., R′′(t, g, h)≥ −ct −2+ε,(4) for some arbitrarily small constantε >0, for allt, g, h. The Assumption constraints the nature of regret the single agent bandit algorithm Sin to be used shall incur. Namely, the change of instanta...
2002
-
[6]
Lower Bound.It is also known that any bandit algorithm can not perform better than a certain level, i.e., the algorithm will have to incur some minimum rate of (expected) regret
that demonstrate the aforementioned nature of shape of regret curve. Lower Bound.It is also known that any bandit algorithm can not perform better than a certain level, i.e., the algorithm will have to incur some minimum rate of (expected) regret. In other words, the cumulative regret curve ‘can not flatten too soon’ The seminal work of Robbins [1985] est...
1985
-
[7]
the agent’s own past action-reward history,P a t−1 = ((xa,s, ya,s))s∈[t−1],
-
[8]
the sequence of anonymized multisets/pool of past action–reward pairs generated by the other agents in the coalition P −a t−1 = [ b∈C\{a} {(xb,s, yb,s)} s∈[t−1] , where no agent identities are retained, and
-
[9]
the set of actionsX a,t of the agent at present. This Assumption states that the multi-agent algorithm shall not use coalition history H C t ∈ H C t directly, but shall instead use a further processed quantity P C t , which is the union of samples observed so far by all agents. It is easy to observe that this pool of samples P C t is a deterministic funct...
2019
-
[10]
The realized cumulative regret of all agents, P a∈C RC a (Mul, I,· ), the quantity we try to bound from both sides
-
[11]
The analytical/hypothetical single-agent regretR a(Sin, I,·) that is used in the bound terms
-
[12]
This is a quantity internal to Mul algorithm that depends on actions chosen by Sin, and not a quantity inherent to the bandit problem
To compare the above two quantities, an intermediate quantity (introduced below in Equation (26)) : R(Sin, B,· ), the ‘regret’ of the black-box decision/action sequence xτs on interacting with the reward buffer B. This is a quantity internal to Mul algorithm that depends on actions chosen by Sin, and not a quantity inherent to the bandit problem. We set u...
2024
-
[13]
Let B′ be the set of agent-time tuples ( a, t)-s whose samplesy a,t-s remain in the buffer at the end
It remains in the buffer at the end of time horizon t = T . Let B′ be the set of agent-time tuples ( a, t)-s whose samplesy a,t-s remain in the buffer at the end. Or,
-
[14]
\ a∈M Ha,t =sa # =P I,Alg
It was consumed by the black-box decision maker at some step τ∈ [τ]. Let f : [τ] 7→ (M× [T ]) \B ′ denote this bijective mapping. Now, we are ready to bound the cumulative regret of all agents inCas follows: X a∈C RC a (Mul, I, T) (a) = X a∈C TX t=1 y∗ −E I,Mul [⟨θ∗, xa,t⟩] (b) = τX τ=1 y∗ − θ∗, xf(τ) + X (a,t)∈B′ y∗ − ⟨θ∗, xa,t⟩ (c) = τX τ=1 y∗ − ⟨θ∗, xτ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.