Recognition: no theorem link
3D-VCD: Hallucination Mitigation in 3D-LLM Embodied Agents through Visual Contrastive Decoding
Pith reviewed 2026-05-10 17:48 UTC · model grok-4.3
The pith
Contrastive decoding on perturbed 3D scene graphs mitigates hallucinations in embodied agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
3D-VCD constructs a distorted 3D scene graph through category substitutions and coordinate or extent corruptions, then contrasts model predictions under the original and perturbed contexts to suppress tokens insensitive to the grounded 3D evidence and therefore driven by language priors, improving performance on 3D-POPE and HEAL without retraining.
What carries the argument
Visual contrastive decoding applied to structured 3D scene graphs, where the difference between original and semantically or geometrically perturbed representations identifies and downweights ungrounded tokens.
If this is right
- Embodied agents produce fewer unsafe decisions based on invented objects or incorrect spatial relations.
- Existing 3D-LLM agents gain reliability immediately without retraining or new data collection.
- The method targets hallucinations arising specifically from object presence, spatial layout, and geometric grounding.
- Contrastive decoding extends effectively from 2D pixel settings to structured 3D object-centric representations.
Where Pith is reading between the lines
- The same perturbation-plus-contrast pattern could be tested on other structured 3D tasks such as path planning if the core suppression mechanism generalizes.
- Making the perturbations adaptive to real-time sensor noise might extend the approach from static benchmarks to dynamic physical environments.
- Deployment on physical robots would reveal whether the method reduces collision risk when language priors conflict with live 3D observations.
Load-bearing premise
Semantic category substitutions and geometric coordinate or extent corruptions produce a contrast that reliably suppresses only language-prior-driven tokens while preserving tokens grounded in the original 3D evidence.
What would settle it
On the 3D-POPE benchmark, 3D-VCD yields no increase in accuracy for object-presence hallucination detection relative to standard decoding.
Figures



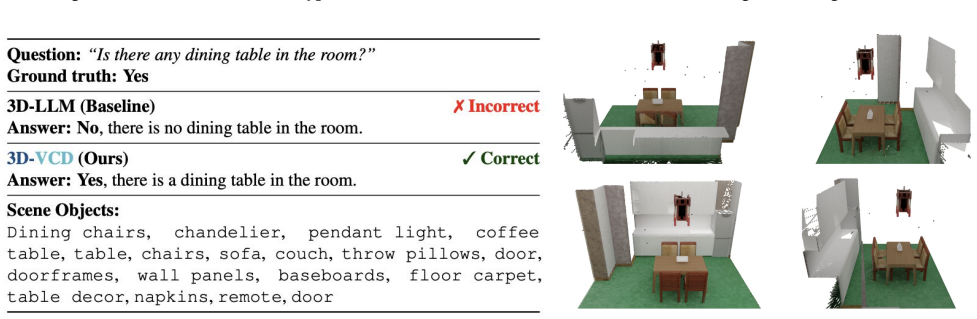





read the original abstract
Large multimodal models are increasingly used as the reasoning core of embodied agents operating in 3D environments, yet they remain prone to hallucinations that can produce unsafe and ungrounded decisions. Existing inference-time hallucination mitigation methods largely target 2D vision-language settings and do not transfer to embodied 3D reasoning, where failures arise from object presence, spatial layout, and geometric grounding rather than pixel-level inconsistencies. We introduce 3D-VCD, the first inference-time visual contrastive decoding framework for hallucination mitigation in 3D embodied agents. 3D-VCD constructs a distorted 3D scene graph by applying semantic and geometric perturbations to object-centric representations, such as category substitutions and coordinate or extent corruption. By contrasting predictions under the original and distorted 3D contexts, our method suppresses tokens that are insensitive to grounded scene evidence and are therefore likely driven by language priors. We evaluate 3D-VCD on the 3D-POPE and HEAL benchmarks and show that it consistently improves grounded reasoning without any retraining, establishing inference-time contrastive decoding over structured 3D representations as an effective and practical route to more reliable embodied intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 3D-VCD, the first inference-time visual contrastive decoding framework for hallucination mitigation in 3D-LLM embodied agents. It constructs a distorted 3D scene graph via semantic category substitutions and geometric perturbations (coordinate or extent corruption) to the object-centric representations, then contrasts model predictions under the original versus distorted 3D contexts to suppress tokens insensitive to grounded scene evidence and thus likely driven by language priors. The method is evaluated on the 3D-POPE and HEAL benchmarks and claimed to consistently improve grounded reasoning without any retraining.
Significance. If the results hold, this provides a practical, training-free approach to improving reliability and safety of embodied agents operating in 3D environments, where hallucinations can lead to unsafe decisions. It extends contrastive decoding techniques from 2D vision-language models to structured 3D scene graphs, addressing a gap in existing inference-time methods. The absence of retraining is a clear strength for real-world deployment in robotics and embodied AI.
major comments (2)
- [§3] §3 (method description): The core assumption that semantic category substitutions and geometric coordinate/extent corruptions isolate language-prior signals while leaving all genuine 3D-grounded evidence intact is load-bearing for the central claim, yet no ablations on perturbation strength, no derivation of the contrast operation, and no analysis of failure modes for partially language-driven tokens (common in spatial reasoning) are provided.
- [§4] §4 (experiments): The abstract states that 3D-VCD improves performance on 3D-POPE and HEAL, but the manuscript provides no quantitative results, baseline comparisons, ablation studies, or details on how perturbations are applied during evaluation, making it impossible to verify whether the central claim is supported by the data.
minor comments (2)
- [§3] The contrast operation could be formalized with an equation to improve precision and reproducibility.
- [Abstract] The abstract would benefit from including the magnitude of reported improvements to better convey the empirical contribution.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight important areas where additional justification and detail will strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§3] §3 (method description): The core assumption that semantic category substitutions and geometric coordinate/extent corruptions isolate language-prior signals while leaving all genuine 3D-grounded evidence intact is load-bearing for the central claim, yet no ablations on perturbation strength, no derivation of the contrast operation, and no analysis of failure modes for partially language-driven tokens (common in spatial reasoning) are provided.
Authors: We agree that the core assumption requires stronger empirical and theoretical support. In the revised manuscript we will add: (1) ablations varying perturbation strength (substitution rate from 0.1–0.5 and geometric noise magnitude), (2) a short derivation of the contrastive term motivated by the difference in conditional token probabilities under grounded versus ungrounded contexts, and (3) a failure-mode analysis that isolates tokens whose predictions remain partially language-driven even after contrast (e.g., in ambiguous spatial relations). These additions will be placed in §3 and a new appendix. revision: yes
-
Referee: [§4] §4 (experiments): The abstract states that 3D-VCD improves performance on 3D-POPE and HEAL, but the manuscript provides no quantitative results, baseline comparisons, ablation studies, or details on how perturbations are applied during evaluation, making it impossible to verify whether the central claim is supported by the data.
Authors: The current draft inadvertently omitted the full experimental section. The revised manuscript will include complete quantitative tables reporting accuracy and hallucination-rate improvements on both 3D-POPE and HEAL, comparisons against standard decoding and existing inference-time baselines, ablation tables for each perturbation type, and explicit parameter settings (e.g., corruption probabilities and coordinate noise variance) used at evaluation time. All numbers and protocols will be described in §4 with corresponding figures. revision: yes
Circularity Check
No circularity: procedural inference-time algorithm with external benchmark evaluation
full rationale
The paper describes 3D-VCD as an inference-time procedure that applies semantic and geometric perturbations to construct a distorted 3D scene graph, then contrasts logits from original versus distorted contexts to suppress language-prior tokens. No equations, fitted parameters, or derivations are presented that reduce the claimed improvement to a self-referential quantity or input by construction. The central claims rest on evaluation against the independent 3D-POPE and HEAL benchmarks rather than any internal fit or self-citation chain. This is a standard non-circular algorithmic contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. InProceedings of the Conference on Neural Information Processing Systems (NeurIPS), 2022. 1
2022
-
[2]
Mitigating object hallucinations in large vision-language models with assembly of global and local attention
Wenbin An, Feng Tian, Sicong Leng, Jiahao Nie, Haonan Lin, QianYing Wang, Ping Chen, Xiaoqin Zhang, and Shijian Lu. Mitigating object hallucinations in large vision-language models with assembly of global and local attention. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2
2025
-
[3]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024. 1, 3
work page internal anchor Pith review arXiv 2024
-
[4]
Do as i can, not as i say: Grounding language in robotic affordances
Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, Ryan Julian, et al. Do as i can, not as i say: Grounding language in robotic affordances. InProceedings of the Annual Conference on Robot Learning (CoRL), 2023. 1
2023
-
[5]
Hallucination detection in foundation models for decision-making: A flexible definition and review of the state of the art.ACM Computing Surveys, 57(7):1–35, 2025
Neeloy Chakraborty, Melkior Ornik, and Katherine Driggs- Campbell. Hallucination detection in foundation models for decision-making: A flexible definition and review of the state of the art.ACM Computing Surveys, 57(7):1–35, 2025. 2
2025
-
[6]
HEAL: an empirical study on hallucinations in embodied agents driven by large language models
Trishna Chakraborty, Udita Ghosh, Xiaopan Zhang, Fahim Faisal Niloy, Yue Dong, Jiachen Li, Amit Roy- Chowdhury, and Chengyu Song. HEAL: an empirical study on hallucinations in embodied agents driven by large language models. InFindings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025. 2, 5
2025
-
[7]
LL3DA: visual interactive instruction tuning for omni-3D understand- ing reasoning and planning
Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. LL3DA: visual interactive instruction tuning for omni-3D understand- ing reasoning and planning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[8]
Palm-e: an embod- ied multimodal language model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: an embod- ied multimodal language model. InProceedings of the In- ternational Conference on Machine Learning (ICML), 2023. 1
2023
-
[9]
Scene-llm: Extending language model for 3d visual understanding and reasoning,
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wen- han Xiong. Scene-llm: Extending language model for 3d visual understanding and reasoning.arXiv preprint arXiv:2403.11401, 2024. 1
-
[10]
Hallusion- bench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language mod- els
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusion- bench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language mod- els. InProceedings of the IEEE/CVF Conference on Com- puter Vis...
2024
-
[11]
3D concept learning and reasoning from multi-view images
Yining Hong, Chunru Lin, Yilun Du, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. 3D concept learning and reasoning from multi-view images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9202–9212, 2023. 2
2023
-
[12]
3D-LLM: inject- ing the 3D world into large language models
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3D-LLM: inject- ing the 3D world into large language models. InProceedings of the Conference on Neural Information Processing Systems (NeurIPS), 2023. 5, 6, 1
2023
-
[13]
Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning
Yingdong Hu, Fanqi Lin, Tong Zhang, Li Yi, and Yang Gao. Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning. InInternational Confer- ence on Robotics and Automation (ICRA)’s Workshop on Vision-Language Models for Navigation and Manipulation,
-
[14]
An embodied generalist agent in 3d world
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baox- iong Jia, and Siyuan Huang. An embodied generalist agent in 3d world. InProceedings of the International Conference on Machine Learning (ICML), 2024. 2, 5, 6
2024
-
[15]
MLLM-for3d: Adapting multimodal large language model for 3d reasoning segmentation
Jiaxin Huang, Runnan Chen, Ziwen Li, Zhengqing Gao, Xiao He, Yandong Guo, Mingming Gong, and Tongliang Liu. MLLM-for3d: Adapting multimodal large language model for 3d reasoning segmentation. InProceedings of the Conference on Neural Information Processing Systems (NeurIPS), 2025. 2
2025
-
[16]
Do robot snakes dream like electric sheep? investigating the effects of architectural inductive biases on hallucination
Jerry Huang, Prasanna Parthasarathi, Mehdi Rezagholizadeh, Boxing Chen, and Sarath Chandar. Do robot snakes dream like electric sheep? investigating the effects of architectural inductive biases on hallucination. InFindings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2025. 2
2025
-
[17]
A survey on hal- lucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Infor- mation Systems, 43(2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hal- lucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Infor- mation Systems, 43(2):1–55, 2025. 1
2025
-
[18]
Vi- sual hallucinations of multi-modal large language models
Wen Huang, Hongbin Liu, Minxin Guo, and Neil Gong. Vi- sual hallucinations of multi-modal large language models. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2024. 1 9
2024
-
[19]
SceneVerse: scaling 3D vision-language learning for grounded scene un- derstanding
Baoxiong Jia, Yixin Chen, Huangyue Yu, Yan Wang, Xuesong Niu, Tengyu Liu, Qing Li, and Siyuan Huang. SceneVerse: scaling 3D vision-language learning for grounded scene un- derstanding. InProceedings of the European Conference on Computer Vision (ECCV), 2024. 2
2024
-
[20]
Retrieval visual contrastive decod- ing to mitigate object hallucinations in large vision-language models
Jihoon Lee and Min Song. Retrieval visual contrastive decod- ing to mitigate object hallucinations in large vision-language models. InFindings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2025. 3
2025
-
[21]
Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR),
-
[22]
BLIP- 2: bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP- 2: bootstrapping language-image pre-training with frozen image encoders and large language models. InProceedings of the International Conference on Machine Learning (ICML),
-
[23]
Embodied agent interface: Bench- marking llms for embodied decision making
Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Yu Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Erran Li Li, Ruohan Zhang, et al. Embodied agent interface: Bench- marking llms for embodied decision making. InProceedings of the Conference on Neural Information Processing Systems (NeurIPS), 2024. 5
2024
-
[24]
Seeground: See and ground for zero-shot open- vocabulary 3d visual grounding
Rong Li, Shijie Li, Lingdong Kong, Xulei Yang, and Jun- wei Liang. Seeground: See and ground for zero-shot open- vocabulary 3d visual grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2
2025
-
[25]
Counterfactual Segmentation Reasoning: Diagnosing and Mitigating Pixel-Grounding Hallucination
Xinzhuo Li, Adheesh Juvekar, Jiaxun Zhang, Xingyou Liu, Muntasir Wahed, Kiet A Nguyen, Yifan Shen, Tianjiao Yu, and Ismini Lourentzou. Counterfactual segmentation reason- ing: Diagnosing and mitigating pixel-grounding hallucination. arXiv preprint arXiv:2506.21546, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Dingning Liu, Xiaoshui Huang, Yuenan Hou, Zhihui Wang, Zhenfei Yin, Yongshun Gong, Peng Gao, and Wanli Ouyang. Uni3D-LLM: unifying point cloud perception, generation and editing with large language models.arXiv preprint arXiv:2402.03327, 2024. 1
-
[27]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InProceedings of the Conference on Neural Information Processing Systems (NeurIPS), 2023. 1
2023
-
[28]
Reducing hallucina- tions in large vision-language models via latent space steering
Sheng Liu, Haotian Ye, and James Zou. Reducing hallucina- tions in large vision-language models via latent space steering. InProceedings of the International Conference on Learning Representations (ICLR), 2025. 2
2025
-
[29]
Visual embodied brain: Let multimodal large language models see, think, and control in spaces
Gen Luo, Ganlin Yang, Ziyang Gong, Guanzhou Chen, Hao- nan Duan, Erfei Cui, Ronglei Tong, Zhi Hou, Tianyi Zhang, Zhe Chen, et al. Visual embodied brain: Let multimodal large language models see, think, and control in spaces.arXiv preprint arXiv:2506.00123, 2025. 1
-
[30]
Openeqa: Embodied question answering in the era of foundation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mc- vay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foundation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 1
2024
-
[31]
Second: Mitigating perceptual hallucination in vision- language models via selective and contrastive decoding
Woohyeon Park, Woojin Kim, Jaeik Kim, and Jaeyoung Do. Second: Mitigating perceptual hallucination in vision- language models via selective and contrastive decoding. In Proceedings of the International Conference on Machine Learning (ICML), 2025. 3
2025
-
[32]
Convis: Contrastive decoding with hallucination visualization for mitigating hallucinations in multimodal large language models
Yeji Park, Deokyeong Lee, Junsuk Choe, and Buru Chang. Convis: Contrastive decoding with hallucination visualization for mitigating hallucinations in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025. 3
2025
-
[33]
Ruiying Peng, Kaiyuan Li, Weichen Zhang, Chen Gao, Xin- lei Chen, and Yong Li. Understanding and evaluating hal- lucinations in 3d visual language models.arXiv preprint arXiv:2502.15888, 2025. 2
-
[34]
How easy is it to fool your multimodal llms? an empirical analy- sis on deceptive prompt
Yusu Qian, Haotian Zhang, Yinfei Yang, and Zhe Gan. How easy is it to fool your multimodal llms? an empirical analy- sis on deceptive prompt. InNeural Information Processing Systems (NeurIPS) Workshop on Safe Generative AI, 2024. 2
2024
-
[35]
Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning
Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou- Chakra, Ian Reid, and Niko S¨underhauf. Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning. InProceedings of the Annual Conference on Robot Learning (CoRL), 2023. 1
2023
-
[36]
A survey of hallucination in large foundation models
Vipula Rawte, Amit Sheth, and Amitava Das. A survey of hallucination in large foundation models.arXiv preprint arXiv:2309.05922, 2023. 2
-
[37]
Object hallucination in image captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018. 1, 5
2018
-
[38]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Am- jad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. LLaMA 2: open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024. 1
2024
-
[40]
Mitigating hallucinations in large vision-language models with instruction contrastive decoding
Xintong Wang, Jingheng Pan, Liang Ding, and Chris Bie- mann. Mitigating hallucinations in large vision-language models with instruction contrastive decoding. InFindings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2024. 3
2024
-
[41]
Yiqi Wang, Wentao Chen, Xiaotian Han, Xudong Lin, Hait- eng Zhao, Yongfei Liu, Bohan Zhai, Jianbo Yuan, Quanzeng You, and Hongxia Yang. Exploring the reasoning abilities of multimodal large language models (MLLMs): a compre- hensive survey on emerging trends in multimodal reasoning. arXiv preprint arXiv:2401.06805, 2024. 1
-
[42]
Vsp: 10 Diagnosing the dual challenges of perception and reason- ing in spatial planning tasks for mllms
Qiucheng Wu, Handong Zhao, Michael Saxon, Trung Bui, William Yang Wang, Yang Zhang, and Shiyu Chang. Vsp: 10 Diagnosing the dual challenges of perception and reason- ing in spatial planning tasks for mllms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 1
2025
-
[43]
3D-GRAND: a million-scale dataset for 3D-LLMs with bet- ter grounding and less hallucination
Jianing Yang, Xuweiyi Chen, Nikhil Madaan, Madhavan Iyengar, Shengyi Qian, David F Fouhey, and Joyce Chai. 3D-GRAND: a million-scale dataset for 3D-LLMs with bet- ter grounding and less hallucination. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 29501–29512, 2025. 2, 5, 1
2025
-
[44]
Uncer- tainty in action: Confidence elicitation in embodied agents
Tianjiao Yu, Vedant Shah, Muntasir Wahed, Kiet A Nguyen, Adheesh Juvekar, Tal August, and Ismini Lourentzou. Uncer- tainty in action: Confidence elicitation in embodied agents. arXiv preprint arXiv:2503.10628, 2025. 1
-
[45]
Analyzing and mitigating object hallucination in large vision- language models
Yiyang Zhou, Chenhang Cui, Jaehong Yoon, Linjun Zhang, Zhun Deng, Chelsea Finn, Mohit Bansal, and Huaxiu Yao. Analyzing and mitigating object hallucination in large vision- language models. InProceedings of the International Confer- ence on Learning Representations (ICLR), 2024. 2
2024
-
[46]
3D-Vista: pre-trained transformer for 3D vision and text alignment
Ziyu Zhu, Xiaojian Ma, Yixin Chen, Zhidong Deng, Siyuan Huang, and Qing Li. 3D-Vista: pre-trained transformer for 3D vision and text alignment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2, 5, 6
2023
-
[47]
RT-2: vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. RT-2: vision-language-action models transfer web knowledge to robotic control. InProceedings of the Annual Conference on Robot Learning (CoRL), 2023. 1 11 3D-VCD: Hallucination Mitigation in 3D-LLM Embodied Agents through Visu...
2023
-
[48]
For HEAL experiments, we apply 3D-VCD to off-the-shelf language-only models (Llama-3-8B-Instruct and Qwen-14B- Instruct) by feeding them scene descriptions in the HEAL text format, requiring no spatial inference modules. Scene graphs are preprocessed once and cached for all runs. B. Additional Ablations Negative Transfer and Query Sensitivity.A critical c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.