Recognition: unknown
QoS-QoE Translation with Large Language Model
Pith reviewed 2026-05-10 16:57 UTC · model grok-4.3
The pith
A literature-extracted dataset enables large language models to perform accurate bidirectional translation between QoS metrics and QoE scores after fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
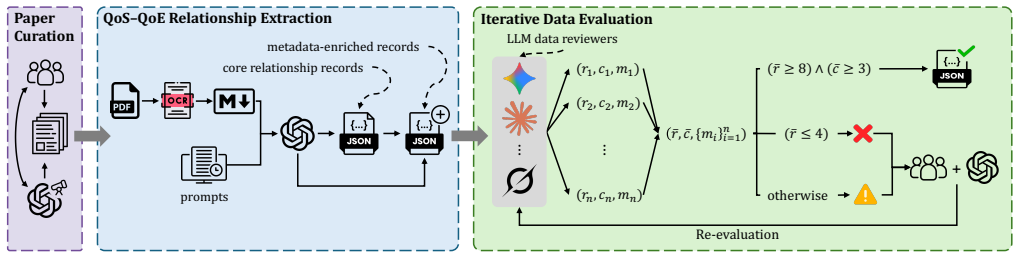
The QoS-QoE Translation dataset, built automatically from multimedia papers, equips large language models to achieve strong performance on continuous-value and discrete-label prediction for both QoS-to-QoE and QoE-to-QoS translation after supervised fine-tuning.
What carries the argument
The QoS-QoE Translation dataset, which stores structured relationships along with parameter definitions, evidence, and metadata, used as training data for LLM fine-tuning on bidirectional translation tasks.
If this is right
- Enables systematic reuse of prior QoS-QoE findings across different experimental setups.
- Supports large-scale analysis and cross-scenario generalization in multimedia quality modeling.
- Provides a benchmark for evaluating LLMs on QoS-QoE and QoE-QoS tasks.
- Facilitates LLM-based reasoning pipelines for multimedia quality prediction and optimization.
Where Pith is reading between the lines
- Real-time streaming systems could use the fine-tuned model to adjust parameters dynamically based on predicted user experience.
- The same extraction-plus-fine-tuning method could be applied to other domains where relationships are scattered across papers.
- Continuous-value outputs might allow finer-grained control loops than discrete labels alone.
Load-bearing premise
The automated pipeline of paper curation, relationship extraction, and iterative evaluation captures valid QoS-QoE relationships from the literature without major extraction errors or selection biases.
What would settle it
Compare the fine-tuned LLM's predicted QoE values or labels against new experimental measurements collected under conditions absent from the original dataset.
Figures


read the original abstract
QoS-QoE translation is a fundamental problem in multimedia systems because it characterizes how measurable system and network conditions affect user-perceived experience. Although many prior studies have examined this relationship, their findings are often developed for specific setups and remain scattered across papers, experimental settings, and reporting formats, limiting systematic reuse, cross-scenario generalization, and large-scale analysis. To address this gap, we first introduce QoS-QoE Translation dataset, a source-grounded dataset of structured QoS-QoE relationships from the multimedia literature, with a focus on video streaming related tasks. We construct the dataset through an automated pipeline that combines paper curation, QoS-QoE relationship extraction, and iterative data evaluation. Each record preserves the extracted relationship together with parameter definitions, supporting evidence, and contextual metadata. We further evaluate the capability of large language models (LLMs) on QoS-QoE translation, both before and after supervised fine-tuning on our dataset, and show strong performance on both continuous-value and discrete-label prediction in bidirectional translation, from QoS-QoE and QoE-QoS. Our dataset provides a foundation for benchmarking LLMs in QoS-QoE translation and for supporting future LLM-based reasoning for multimedia quality prediction and optimization. The complete dataset and code are publicly available at https://yyu6969.github.io/qos-qoe-translation-page/, for full reproducibility and open access.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the QoS-QoE Translation dataset, a structured collection of QoS-QoE relationships extracted from the multimedia literature (with emphasis on video streaming) via an automated pipeline of paper curation, relationship extraction, and iterative evaluation. Each entry includes the relationship, parameter definitions, supporting evidence, and metadata. The authors then evaluate LLMs on bidirectional QoS-to-QoE and QoE-to-QoS translation tasks for both continuous-value regression and discrete-label classification, reporting strong performance both before and after supervised fine-tuning on the new dataset. The dataset and code are released publicly.
Significance. If the extraction pipeline faithfully captures literature relationships and the LLM evaluations are rigorously validated, the work would provide a useful open resource for multimedia quality modeling and could accelerate LLM-based reasoning for QoS-QoE mapping. The public release of data and code is a clear strength that supports reproducibility and follow-on research.
major comments (2)
- [Abstract / Dataset Construction] Abstract and dataset-construction description: the automated pipeline (paper curation + QoS-QoE relationship extraction + iterative evaluation) is load-bearing for all downstream claims, yet no quantitative validation is reported (precision/recall against source papers, human verification sample size, inter-annotator agreement, or error analysis on parameter definitions and evidence spans). Without these, both dataset fidelity and the fine-tuning signal remain unverifiable.
- [LLM Evaluation] LLM evaluation section: the headline claim of 'strong performance' on continuous and discrete bidirectional translation lacks any reported metrics, baselines, data splits, error bars, statistical tests, or ablation on fine-tuning details. This prevents assessment of whether the results exceed trivial baselines or are robust to evaluation choices.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of clarity and rigor that we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / Dataset Construction] Abstract and dataset-construction description: the automated pipeline (paper curation + QoS-QoE relationship extraction + iterative evaluation) is load-bearing for all downstream claims, yet no quantitative validation is reported (precision/recall against source papers, human verification sample size, inter-annotator agreement, or error analysis on parameter definitions and evidence spans). Without these, both dataset fidelity and the fine-tuning signal remain unverifiable.
Authors: We agree that quantitative validation of the automated pipeline is necessary to support claims about dataset quality. The manuscript describes the pipeline steps and notes that iterative evaluation was performed, but we did not report specific metrics such as precision/recall or human verification statistics. In the revised manuscript we will add a dedicated validation subsection that includes: (i) precision and recall computed against a held-out set of manually annotated source papers, (ii) the size of the human verification sample, (iii) inter-annotator agreement (Cohen’s kappa), and (iv) a brief error analysis focused on parameter definitions and evidence spans. revision: yes
-
Referee: [LLM Evaluation] LLM evaluation section: the headline claim of 'strong performance' on continuous and discrete bidirectional translation lacks any reported metrics, baselines, data splits, error bars, statistical tests, or ablation on fine-tuning details. This prevents assessment of whether the results exceed trivial baselines or are robust to evaluation choices.
Authors: We acknowledge that the evaluation section would benefit from greater explicitness. While the manuscript reports performance numbers for both pre-trained and fine-tuned LLMs on the bidirectional tasks, we will expand it to include: (i) all concrete metrics (MAE, RMSE for regression; accuracy, F1 for classification), (ii) explicit baselines (e.g., linear regression for continuous values and majority-class or random baselines for discrete labels), (iii) the exact train/validation/test splits used, (iv) error bars or standard deviations across multiple random seeds, (v) statistical significance tests (paired t-tests or Wilcoxon tests), and (vi) a short ablation table on key fine-tuning hyperparameters. revision: yes
Circularity Check
No circularity: empirical dataset construction and LLM evaluation are self-contained
full rationale
The paper introduces a source-grounded QoS-QoE dataset built via automated curation/extraction/evaluation pipeline and then reports LLM performance (pre- and post-fine-tuning) on continuous/discrete bidirectional translation tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citations invoked as uniqueness theorems appear in the provided text. Performance claims rest on standard held-out evaluation rather than any reduction to inputs by construction. The skeptic concern about missing extraction validation is a correctness/validity issue, not circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Literature papers contain extractable, structured QoS-QoE relationships that can be reliably parsed by an automated pipeline.
Reference graph
Works this paper leans on
-
[1]
Mohammed Alreshoodi and John Woods. 2013. Survey on QoE/QoS Correlation Models for Multimedia Services.International Journal of Distributed and Parallel Systems4, 3 (2013), 53–72. https://doi.org/10.5121/ijdps.2013.4305
-
[2]
Anthropic. 2025. Introducing Claude Haiku 4.5. https://www.anthropic.com/ news/claude-haiku-4-5 Official model announcement. Accessed: 2026-04-01
2025
-
[3]
Athula Balachandran, Vyas Sekar, Aditya Akella, Srinivasan Seshan, Ion Stoica, and Hui Zhang. 2013. Developing a Predictive Model of Quality of Experience for Internet Video.ACM SIGCOMM Computer Communication Review43, 4 (2013), 339–350. https://doi.org/10.1145/2486001.2486025
-
[4]
Alcardo Alex Barakabitze, Nabajeet Barman, Arslan Ahmad, Saman Zadtootaghaj, Lingfen Sun, Maria G. Martini, and Luigi Atzori. 2020. QoE Management of Multimedia Streaming Services in Future Networks: A Tutorial and Survey.IEEE Communications Surveys & Tutorials22, 1 (2020), 526–565. https://doi.org/10. 1109/COMST.2019.2958784
-
[5]
Nabajeet Barman and Maria G. Martini. 2019. QoE Modeling for HTTP Adaptive Video Streaming: A Survey and Open Challenges.IEEE Access7 (2019), 30831– 30859. https://doi.org/10.1109/ACCESS.2019.2901778
-
[6]
doi: 10.1038/s41467-024-45563-x
John Dagdelen, Alexander Dunn, Sanghoon Lee, Nicholas Walker, Andrew S. Rosen, Gerbrand Ceder, Kristin A. Persson, and Anubhav Jain. 2024. Structured information extraction from scientific text with large language models.Nature Communications15, 1 (2024), 1418. https://doi.org/10.1038/s41467-024-45563-x
-
[7]
Florin Dobrian, Vyas Sekar, Asad Awan, Ion Stoica, Dilip Joseph, Aditya Ganjam, Jibin Zhan, and Hui Zhang. 2011. Understanding the Impact of Video Quality on User Engagement.ACM SIGCOMM Computer Communication Review41, 4 (2011), 362–373. https://doi.org/10.1145/2018436.2018478
-
[8]
Zhengfang Duanmu, Abdul Rehman, and Zhou Wang. 2018. A Quality-of- Experience Database for Adaptive Video Streaming.IEEE Transactions on Broad- casting64, 2 (June 2018), 474–487. https://doi.org/10.1109/TBC.2018.2822870
-
[9]
Google. 2025. Gemini 2.5 Flash-Lite. https://ai.google.dev/gemini-api/docs/ models/gemini-2.5-flash-lite Official model documentation. Accessed: 2026-04- 01
2025
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, et al. 2024. The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783(2024). arXiv:2407.21783 https://arxiv.org/abs/ 2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2024. A Survey on LLM-as- a-Judge.arXiv preprint arXiv:2411.15594(2024). https://arxiv.org/abs/2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [12]
-
[13]
2023.Roadmap for QoS and QoE in the ITU-T Study Group 12 Context
ITU-T. 2023.Roadmap for QoS and QoE in the ITU-T Study Group 12 Context. Technical Report GSTR-RQ. International Telecommunication Union. https: //www.itu.int/dms_pub/itu-t/opb/tut/T-TUT-QOS-2023-2-PDF-E.pdf
2023
-
[14]
Shunmuga Krishnan and Ramesh K
S. Shunmuga Krishnan and Ramesh K. Sitaraman. 2012. Video Stream Quality Impacts Viewer Behavior: Inferring Causality Using Quasi-Experimental Designs. InProceedings of the 2012 Internet Measurement Conference (IMC ’12). Association for Computing Machinery, New York, NY, USA, 211–224. https://doi.org/10. 1145/2398776.2398799
- [15]
-
[16]
Yanan Li, Guangqing Deng, Changming Bai, Jingyu Yang, Gang Wang, Hao Zhang, Jin Bai, Haitao Yuan, Mengwei Xu, and Shangguang Wang. 2023. Demystifying the QoS and QoE of Edge-hosted Video Streaming Applications in the Wild with SNESet.Proceedings of the ACM on Management of Data1, 4, Article 236 (2023), 29 pages. https://doi.org/10.1145/3626723
-
[17]
Xiao Liu, Tianjie Zhang, Yu Gu, Iat Long Iong, Yifan Xu, Xixuan Song, Shudan Zhang, Hanyu Lai, Xinyi Liu, Hanlin Zhao, et al . 2024. VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents.arXiv preprint arXiv:2408.06327(2024). arXiv:2408.06327 [cs.CV] https://arxiv.org/abs/2408. 06327
-
[18]
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. 2024. TempCompass: Do Video LLMs Really Understand Videos?. InFindings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics, Bangkok, Thailand, 8731–8772. https: //doi.org/10.18653/v1/2024.findings-acl.517
-
[19]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-Refine: Iterative Refinement with Self- Feedback.arXiv preprint arXiv:2303.17651(2023). ht...
work page internal anchor Pith review arXiv 2023
-
[20]
Hongzi Mao, Ravi Netravali, and Mohammad Alizadeh. 2017. Neural Adaptive Video Streaming with Pensieve. InProceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM ’17). Association for Computing Machinery, New York, NY, USA, 197–210. https://doi.org/10.1145/ 3098822.3098843
-
[21]
OpenAI. 2025. Introducing deep research. https://openai.com/index/introducing- deep-research/ Accessed: 2026-03-26
2025
-
[22]
OpenAI. 2025. Introducing GPT-5.2. https://openai.com/index/introducing-gpt- 5-2/ Accessed: 2026-03-27
2025
-
[23]
Qwen Team. [n. d.]. Qwen3.5-35B-A3B. https://huggingface.co/Qwen/Qwen3.5- 35B-A3B Official model card. Accessed: 2026-03-27
2026
-
[24]
Michael Seufert, Sebastian Egger-Lampl, Martin Slanina, Thomas Zinner, Tobias Hoßfeld, and Phuoc Tran-Gia. 2015. A Survey on Quality of Experience of HTTP Adaptive Streaming.IEEE Communications Surveys & Tutorials17, 1 (2015), 469–492. https://doi.org/10.1109/COMST.2014.2360940
-
[25]
Mahsa Shamsabadi, Jennifer D’Souza, and Sören Auer. 2024. Large Language Models for Scientific Information Extraction: An Empirical Study for Virology. arXiv preprint arXiv:2401.10040(2024). https://doi.org/10.48550/arXiv.2401.10040 arXiv:2401.10040
- [26]
-
[27]
Thinking Machines Lab. 2025. Tinker. https://thinkingmachines.ai/tinker/ Accessed: 2026-04-02
2025
- [28]
-
[29]
Dongsheng Wang, Natraj Raman, Mathieu Sibue, Zhiqiang Ma, Petr Babkin, Simerjot Kaur, Yulong Pei, Armineh Nourbakhsh, and Xiaomo Liu. 2024. Do- cLLM: A Layout-Aware Generative Language Model for Multimodal Document Understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association ...
-
[30]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. 2024. LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding. arXiv preprint arXiv:2407.15754(2024). https://doi.org/10.48550/arXiv.2407.15754 arXiv:2407.15754 [cs.CV]
-
[31]
xAI. [n. d.]. Grok 4.20 0309 Reasoning. https://docs.x.ai/developers/models/grok- 4.20-0309-reasoning Official model documentation. Accessed: 2026-04-01
2026
-
[32]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[33]
Xiaoqi Yin, Abhishek Jindal, Vyas Sekar, and Bruno Sinopoli. 2015. A Control- Theoretic Approach for Dynamic Adaptive Video Streaming over HTTP. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Com- munication (SIGCOMM ’15). Association for Computing Machinery, New York, NY, USA, 325–338. https://doi.org/10.1145/2785956.2787486
-
[34]
Zehao Zhu, Wei Sun, Jun Jia, Wei Wu, Sibin Deng, Kai Li, Ying Chen, Xiongkuo Min, Jia Wang, and Guangtao Zhai. 2024. Subjective and Objec- tive Quality-of-Experience Evaluation Study for Live Video Streaming.arXiv preprint arXiv:2409.17596(2024). https://doi.org/10.48550/arXiv.2409.17596 arXiv:2409.17596 7
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.17596 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.