Recognition: unknown
HiFloat4 Format for Language Model Pre-training on Ascend NPUs
Pith reviewed 2026-05-10 16:45 UTC · model grok-4.3
The pith
HiFloat4 FP4 format enables 4-bit pre-training of dense and MoE language models on Ascend NPUs with relative error within 1% of full precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The HiFloat4 FP4 format, applied to linear and expert GEMM operations entirely in 4-bit precision on Ascend NPU clusters, supports pre-training of dense and mixture-of-experts models when paired with FP4-specific stabilization techniques that limit relative error to within 1% of full-precision baselines.
What carries the argument
HiFloat4 FP4 format together with stabilization techniques that counteract numerical degradation during low-precision training.
Load-bearing premise
The FP4-specific stabilization techniques will prevent numerical degradation across all model scales, architectures, and training durations without additional hyperparameter tuning.
What would settle it
Run full pre-training of a LLaMA-style or MoE model in HiFloat4 on Ascend NPUs and measure final perplexity or downstream accuracy against an identical full-precision run to check whether relative error exceeds 1%.
Figures


read the original abstract
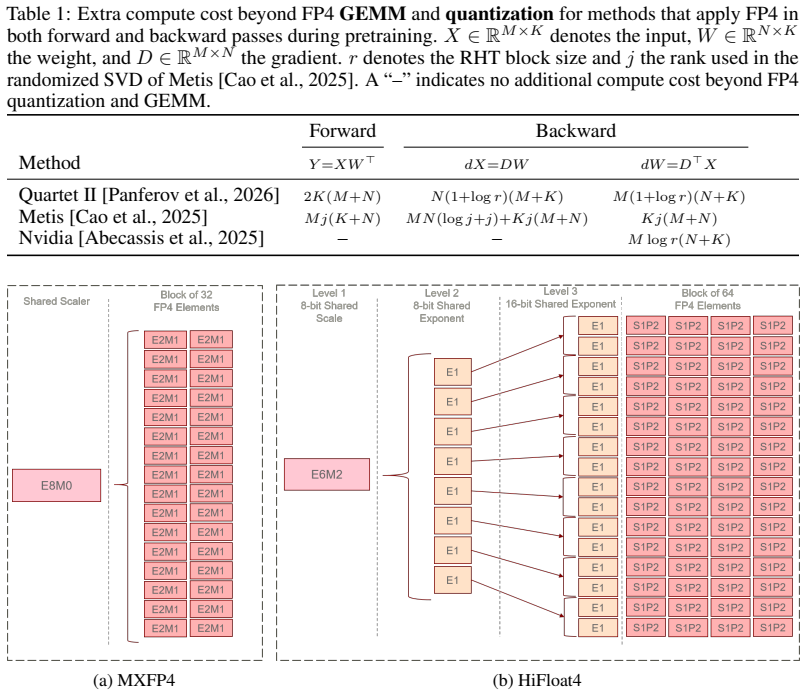
Large foundation models have become central to modern machine learning, with performance scaling predictably with model size and data. However, training and deploying such models incur substantial computational and memory costs, motivating the development of low-precision training techniques. Recent work has demonstrated that 4-bit floating-point (FP4) formats--such as MXFP4 and NVFP4--can be successfully applied to linear GEMM operations in large language models (LLMs), achieving up to 4x improvements in compute throughput and memory efficiency compared to higher-precision baselines. In this work, we investigate the recently proposed HiFloat4 FP4 format for Huawei Ascend NPUs and systematically compare it with MXFP4 in large-scale training settings. All experiments are conducted on Ascend NPU clusters, with linear and expert GEMM operations performed entirely in FP4 precision. We evaluate both dense architectures (e.g., Pangu and LLaMA-style models) and mixture-of-experts (MoE) models, where both standard linear layers and expert-specific GEMMs operate in FP4. Furthermore, we explore stabilization techniques tailored to FP4 training that significantly reduce numerical degradation, maintaining relative error within 1% of full-precision baselines while preserving the efficiency benefits of 4-bit computation. Our results provide a comprehensive empirical study of FP4 training on NPUs and highlight the practical trade-offs between FP4 formats in large-scale dense and MoE models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the HiFloat4 FP4 format, combined with tailored stabilization techniques, enables all linear and expert GEMM operations in dense (Pangu, LLaMA-style) and MoE models to be performed in 4-bit precision on Ascend NPUs while maintaining relative error within 1% of FP32 baselines and retaining efficiency gains; it provides systematic empirical comparisons to MXFP4 under large-scale training settings.
Significance. If the results hold with full experimental details, the work is significant for offering hardware-specific validation of FP4 training on Ascend NPUs, including both dense and MoE architectures with expert GEMMs in FP4. It supplies practical trade-off data between FP4 formats that could inform deployment choices on this platform. The empirical design with direct full-precision baselines is a strength, as is the focus on real NPU clusters rather than simulation.
major comments (2)
- [Abstract] Abstract: The central claim of maintaining relative error within 1% of full-precision baselines is stated without any details on model sizes, training steps, exact error metrics (e.g., loss vs. perplexity), or stabilization implementation; this omission is load-bearing because the soundness of the empirical demonstration cannot be assessed from the provided information.
- [Stabilization techniques] Stabilization techniques section: The assertion that FP4-specific stabilization techniques prevent numerical degradation across model scales, architectures, and training durations without additional hyperparameter tuning rests on an assumption that is not load-bearingly supported by the bounded experimental settings described; a concrete test or ablation on larger scales would be required to substantiate generalization of the 1% bound.
minor comments (1)
- The manuscript would benefit from a summary table listing model configurations, training durations, and precise error metrics to allow quick evaluation of the reported 1% bound.
Simulated Author's Rebuttal
Thank you for reviewing our manuscript on the HiFloat4 FP4 format. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of maintaining relative error within 1% of full-precision baselines is stated without any details on model sizes, training steps, exact error metrics (e.g., loss vs. perplexity), or stabilization implementation; this omission is load-bearing because the soundness of the empirical demonstration cannot be assessed from the provided information.
Authors: We agree that the abstract provides only a high-level overview. In the revised manuscript, we will include additional details in the abstract, such as the specific model sizes (Pangu and LLaMA-style), training steps, and clarify the error metric as relative difference in loss. We will also mention the stabilization techniques section for implementation details. revision: yes
-
Referee: [Stabilization techniques] Stabilization techniques section: The assertion that FP4-specific stabilization techniques prevent numerical degradation across model scales, architectures, and training durations without additional hyperparameter tuning rests on an assumption that is not load-bearingly supported by the bounded experimental settings described; a concrete test or ablation on larger scales would be required to substantiate generalization of the 1% bound.
Authors: Our experiments include systematic evaluations across various model scales, dense and MoE architectures, and different training durations on Ascend NPU clusters, all showing the stabilization techniques maintain performance within 1% relative error without extra tuning. These constitute large-scale settings as per the manuscript. We therefore believe the results support the claim for the tested regimes and do not plan to alter this section. revision: no
Circularity Check
No significant circularity; empirical results self-contained
full rationale
The paper is an empirical study of HiFloat4 FP4 training on Ascend NPUs, reporting direct comparisons of relative error (within 1% of FP32 baselines) for dense and MoE models using stabilization techniques. No equations, derivations, fitted parameters, or self-citations are presented that reduce any claim to a definition or prior input by construction. All load-bearing statements rest on hardware-specific experimental measurements against external full-precision baselines, satisfying the criteria for a self-contained non-circular result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption FP4 arithmetic and GEMM operations behave sufficiently like higher-precision versions when stabilization is applied
Reference graph
Works this paper leans on
-
[1]
doi: 10.1007/978-981-19-2879-6_6
ISBN 978-981-19-2879-6. doi: 10.1007/978-981-19-2879-6_6. URL https://doi.org/10. 1007/978-981-19-2879-6_6. Felix Abecassis, Anjulie Agrusa, Dong Ahn, Jonah Alben, Stefania Alborghetti, Michael Andersch, Sivakumar Arayandi, Alexis Bjorlin, Aaron Blakeman, Evan Briones, et al. Pretraining large language models with nvfp4.arXiv preprint arXiv:2509.25149,
-
[2]
Metis: Training llms with fp4 quantization
Hengjie Cao, Mengyi Chen, Yifeng Yang, Ruijun Huang, Fang Dong, Jixian Zhou, Anrui Chen, Mingzhi Dong, Yujiang Wang, Jinlong Hou, et al. Metis: Training llms with fp4 quantization. arXiv preprint arXiv:2509.00404,
-
[3]
Quartet: Native fp4 training can be optimal for large language models,
10 Roberto L Castro, Andrei Panferov, Soroush Tabesh, Oliver Sieberling, Jiale Chen, Mahdi Nikdan, Saleh Ashkboos, and Dan Alistarh. Quartet: Native fp4 training can be optimal for large language models.arXiv preprint arXiv:2505.14669,
-
[4]
Mengzhao Chen, Meng Wu, Hui Jin, Zhihang Yuan, Jing Liu, Chaoyi Zhang, Yunshui Li, Jie Huang, Jin Ma, Zeyue Xue, et al. Int vs fp: A comprehensive study of fine-grained low-bit quantization formats.arXiv preprint arXiv:2510.25602, 2025a. Yuxiang Chen, Haocheng Xi, Jun Zhu, and Jianfei Chen. Oscillation-reduced mxfp4 training for vision transformers.arXiv ...
-
[5]
arXiv preprint arXiv:2505.19115 , year=
Brian Chmiel, Maxim Fishman, Ron Banner, and Daniel Soudry. Fp4 all the way: Fully quantized training of llms.arXiv preprint arXiv:2505.19115,
-
[6]
Four Over Six: More Accurate NVFP4 Quantization with Adaptive Block Scaling
Jack Cook, Junxian Guo, Guangxuan Xiao, Yujun Lin, and Song Han. Four over six: More accurate nvfp4 quantization with adaptive block scaling.arXiv preprint arXiv:2512.02010,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Elucidating the design space of fp4 training.arXiv preprint arXiv:2509.17791,
Robert Hu, Carlo Luschi, and Paul Balanca. Elucidating the design space of fp4 training.arXiv preprint arXiv:2509.17791,
-
[8]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[9]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
HiFloat4 Format for Language Model Inference.arXiv preprint arXiv:2602.11287, 2026
Yuanyong Luo, Jing Huang, Yu Cheng, Ziwei Yu, Kaihua Zhang, Kehong Hong, Xinda Ma, Xin Wang, Anping Tong, Guipeng Hu, et al. Hifloat4 format for language model inference.arXiv preprint arXiv:2602.11287,
-
[11]
Deepcoder: A fully open-source 14b coder at o3-mini level
Paulius Micikevicius, Dusan Stosic, Neil Burgess, Marius Cornea, Pradeep Dubey, Richard Grisenth- waite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, et al. Fp8 formats for deep learning.arXiv preprint arXiv:2209.05433,
-
[12]
Andrei Panferov, Erik Schultheis, Soroush Tabesh, and Dan Alistarh. Quartet ii: Accurate llm pre-training in nvfp4 by improved unbiased gradient estimation.arXiv preprint arXiv:2601.22813,
-
[13]
arXiv preprint arXiv:2310.10537 , year=
Bita Darvish Rouhani, Nitin Garegrat, Tom Savell, Ankit More, Kyung-Nam Han, Mathew Zhao, Ritchie Hall, Jasmine Klar, Eric Chung, Yuan Yu, Michael Schulte, Ralph Wittig, Ian Bratt, Nigel Stephens, Jelena Milanovic, John Brothers, Pradeep Dubey, Marius Cornea, Alexander Heinecke, Andres Rodriguez, Martin Langhammer, Summer Deng, Maxim Naumov, Paulius Micik...
-
[14]
arXiv preprint arXiv:2501.17116 , year=
Ruizhe Wang, Yeyun Gong, Xiao Liu, Guoshuai Zhao, Ziyue Yang, Baining Guo, Zhengjun Zha, and Peng Cheng. Optimizing large language model training using fp4 quantization.arXiv preprint arXiv:2501.17116,
-
[15]
Scalable training of mixture-of-experts models with megatron core.arXiv preprint arXiv:2603.07685,
URLhttps://arxiv.org/abs/2603.07685. Pengle Zhang, Jia Wei, Jintao Zhang, Jun Zhu, and Jianfei Chen. Accurate int8 training through dynamic block-level fallback.arXiv preprint arXiv:2503.08040,
-
[16]
Practical fp4 training for large-scale moe models on hopper gpus.arXiv preprint arXiv:2603.02731,
Wuyue Zhang, Chongdong Huang, Chunbo You, Cheng Gu, Fengjuan Wang, and Mou Sun. Practical fp4 training for large-scale moe models on hopper gpus.arXiv preprint arXiv:2603.02731,
-
[17]
arXiv preprint arXiv:2502.11458 , year=
Jiecheng Zhou, Ding Tang, Rong Fu, Boni Hu, Haoran Xu, Yi Wang, Zhilin Pei, Zhongling Su, Liang Liu, Xingcheng Zhang, et al. Towards efficient pre-training: Exploring fp4 precision in large language models.arXiv preprint arXiv:2502.11458,
-
[18]
A Training Configuration Table 5: Training configurations for all experiments. Configuration OpenPangu-1B Llama3-8B Qwen3-MoE-30B Model & Data Training Tokens 50B 50B 50B Sequence Length 4K 4K 4K Optimization Optimizer Adam Adam AdamW Start Learning Rate10 −4 10−4 10−4 End Learning Rate10 −5 10−5 10−5 LR Schedule Cosine Decay Cosine Decay Cosine Decay War...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.