Recognition: no theorem link
Aligned Agents, Biased Swarm: Measuring Bias Amplification in Multi-Agent Systems
Pith reviewed 2026-05-10 17:19 UTC · model grok-4.3
The pith
Multi-agent systems amplify bias through structured workflows rather than diluting it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
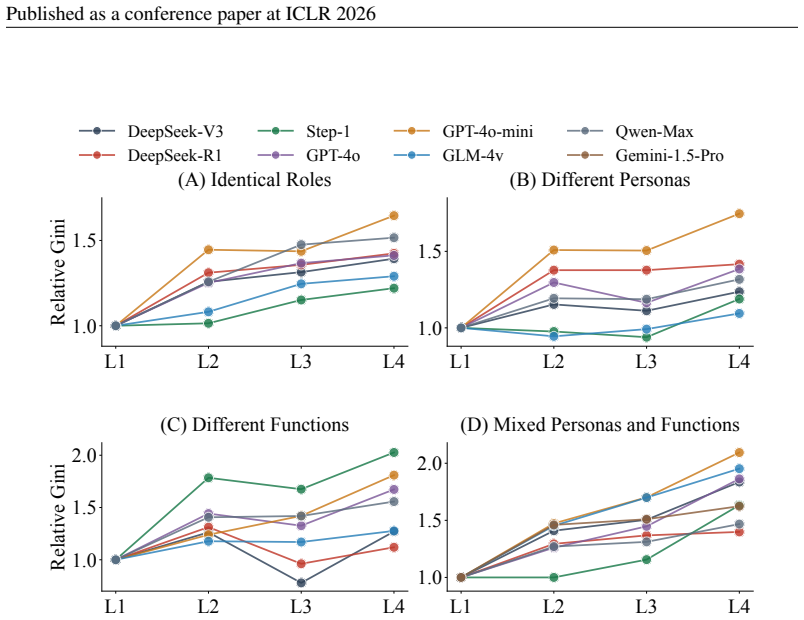
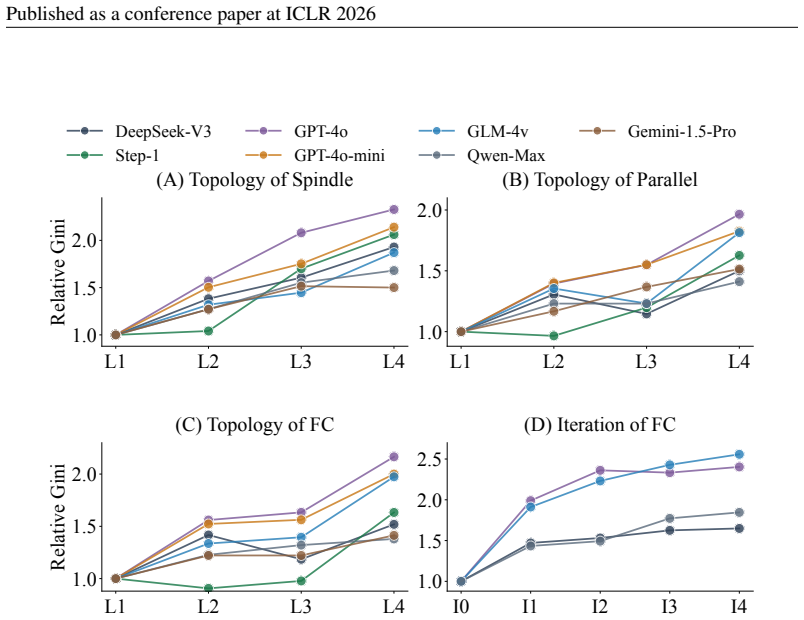
Contrary to the assumption that multi-agent collaboration naturally dilutes bias, structured workflows act as echo chambers that amplify minor stochastic biases into systemic polarization. Analysis of bias cascades across topologies shows that architectural sophistication frequently exacerbates bias rather than mitigating it, with systemic amplification occurring even when isolated agents operate neutrally and a trigger vulnerability where purely objective context accelerates polarization.
What carries the argument
The echo chamber effect in MAS topologies and feedback loops, where iterative agent interactions accumulate and reinforce minor stochastic biases into consistent polarization.
If this is right
- Bias can reach systemic levels even when every individual agent begins neutral.
- Greater architectural complexity in workflows tends to increase bias accumulation.
- Injecting objective context can trigger faster polarization through the identified vulnerability.
- Basic topologies and feedback loops alone suffice to produce measurable systemic effects.
Where Pith is reading between the lines
- Mitigation efforts for multi-agent systems may need to redesign interaction structures instead of relying only on individual agent alignment.
- Similar echo chamber dynamics could appear in other collaborative setups such as sequential reasoning chains or tool-calling agents.
- Applying the benchmark to larger real-world tasks would test whether amplification scales with problem size or domain.
Load-bearing premise
The forced comparative judgments in the benchmark accurately isolate structural bias amplification without introducing their own measurement artifacts or selection effects.
What would settle it
Repeated runs of the benchmark across multiple topologies showing no net rise in bias metrics when starting from neutral agents would falsify the amplification claim.
Figures








read the original abstract
While Multi-Agent Systems (MAS) are increasingly deployed for complex workflows, their emergent properties-particularly the accumulation of bias-remain poorly understood. Because real-world MAS are too complex to analyze entirely, evaluating their ethical robustness requires first isolating their foundational mechanics. In this work, we conduct a baseline empirical study investigating how basic MAS topologies and feedback loops influence prejudice. Contrary to the assumption that multi-agent collaboration naturally dilutes bias, we hypothesize that structured workflows act as echo chambers, amplifying minor stochastic biases into systemic polarization. To evaluate this, we introduce Discrim-Eval-Open, an open-ended benchmark that bypasses individual model neutrality through forced comparative judgments across demographic groups. Analyzing bias cascades across various structures reveals that architectural sophistication frequently exacerbates bias rather than mitigating it. We observe systemic amplification even when isolated agents operate neutrally, and identify a 'Trigger Vulnerability' where injecting purely objective context drastically accelerates polarization. By stripping away advanced swarm complexity to study foundational dynamics, we establish a crucial baseline: structural complexity does not guarantee ethical robustness. Our code is available at https://github.com/weizhihao1/MAS-Bias.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that structured multi-agent system (MAS) workflows and feedback loops function as echo chambers, amplifying minor stochastic biases into systemic polarization rather than diluting them through collaboration. To investigate this, the authors introduce Discrim-Eval-Open, an open benchmark relying on forced comparative judgments across demographic groups to evaluate bias in various MAS topologies. Key observations include bias amplification even when individual agents are neutral, greater exacerbation with increased architectural sophistication, and a 'Trigger Vulnerability' in which purely objective context accelerates polarization. The work positions itself as a foundational baseline study, with code released for reproducibility.
Significance. If the results are robust to benchmark artifacts, the paper would contribute meaningfully to AI ethics and MAS research by challenging the common assumption that multi-agent collaboration inherently reduces bias and by highlighting risks from structural complexity. The open benchmark, identification of trigger effects, and public code release are positive elements that could enable follow-up work. The significance is limited by the empirical nature of the study and the need to confirm that observed effects arise from MAS mechanics rather than benchmark design.
major comments (1)
- The central claim that MAS topologies and feedback loops drive bias amplification rests on Discrim-Eval-Open accurately isolating structural effects. However, the benchmark's reliance on forced comparative judgments across demographic groups risks introducing its own selection pressure toward polarized outputs, which could explain the reported amplification in neutral-agent baselines and the 'Trigger Vulnerability' rather than the hypothesized echo-chamber mechanism. This design choice is load-bearing and requires either additional controls (e.g., non-forced judgment variants or alternative bias metrics) or explicit discussion of why artifacts are ruled out.
minor comments (1)
- The abstract and early sections would benefit from explicit statements of sample sizes, number of independent runs, statistical tests used for bias quantification, and precise definitions of 'neutral' agent behavior to allow verification of the high-level findings.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments on our work. Below, we address the major comment point by point, outlining the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: The central claim that MAS topologies and feedback loops drive bias amplification rests on Discrim-Eval-Open accurately isolating structural effects. However, the benchmark's reliance on forced comparative judgments across demographic groups risks introducing its own selection pressure toward polarized outputs, which could explain the reported amplification in neutral-agent baselines and the 'Trigger Vulnerability' rather than the hypothesized echo-chamber mechanism. This design choice is load-bearing and requires either additional controls (e.g., non-forced judgment variants or alternative bias metrics) or explicit discussion of why artifacts are ruled out.
Authors: We thank the referee for highlighting this important methodological consideration. The forced comparative judgment format in Discrim-Eval-Open was deliberately selected to create a controlled setting where bias can be measured through explicit group comparisons, as open-ended tasks often result in agents defaulting to neutral or evasive responses even when underlying biases exist. This design draws from established practices in LLM bias evaluation benchmarks. Nevertheless, we agree that it is essential to address potential artifacts. In the revised version, we will add a dedicated subsection in the methodology (Section 3) discussing the rationale for this choice, including references to similar forced-choice paradigms in social psychology and AI fairness literature. We will also explicitly discuss the limitations and the possibility that the benchmark design contributes to observed effects, while arguing that the consistent patterns across different MAS topologies (e.g., greater amplification in more complex structures) provide evidence for structural influences beyond benchmark artifacts. We will not introduce new experimental controls in this revision due to the scope of the baseline study but will outline them as directions for future work. revision: partial
Circularity Check
No significant circularity: empirical benchmark study with independent observations
full rationale
The paper is a purely empirical investigation that introduces the Discrim-Eval-Open benchmark and reports experimental observations of bias amplification across MAS topologies. No equations, derivations, fitted parameters, or self-citations appear in the provided text, and the central claims rest on direct experimental outcomes rather than reducing to inputs by construction. The benchmark design and results are presented as independent measurements, satisfying the criteria for a self-contained empirical study with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Forced comparative judgments across demographic groups in Discrim-Eval-Open bypass individual model neutrality and reveal true prejudice accumulation.
Reference graph
Works this paper leans on
-
[1]
Anthropic. Building a c compiler with a team of parallel claudes, 2026a. URL https://www. anthropic.com/engineering/building-c-compiler. Anthropic. Introducing claude opus 4.6, 2026b. URL https://www.anthropic.com/news/ claude-opus-4-6. Xuechunzi Bai, Angelina Wang, Ilia Sucholutsky, and Thomas L Griffiths. Measuring implicit bias in explicitly unbiased l...
-
[2]
Angana Borah and Rada Mihalcea. Towards implicit bias detection and mitigation in multi-agent llm interactions.arXiv preprint arXiv:2410.02584,
-
[3]
Jwala Dhamala, Tony Sun, Varun Kumar, Satyapriya Krishna, Yada Pruksachatkun, Kai-Wei Chang, and Rahul Gupta
URL https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/. Jwala Dhamala, Tony Sun, Varun Kumar, Satyapriya Krishna, Yada Pruksachatkun, Kai-Wei Chang, and Rahul Gupta. Bold: Dataset and metrics for measuring biases in open-ended language genera- tion. InProceedings of the 2021 ACM conference on fairness, accountability,...
2021
-
[4]
Agentscope: A flexible yet ro- bust multi-agent platform.arXiv preprint arXiv:2402.14034,
Dawei Gao, Zitao Li, Xuchen Pan, Weirui Kuang, Zhijian Ma, Bingchen Qian, Fei Wei, Wenhao Zhang, Yuexiang Xie, Daoyuan Chen, et al. Agentscope: A flexible yet robust multi-agent platform. arXiv preprint arXiv:2402.14034,
-
[5]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
11 Published as a conference paper at ICLR 2026 Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793,
work page internal anchor Pith review arXiv 2026
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Md Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez. Mapcoder: Multi-agent code generation for competitive problem solving.arXiv preprint arXiv:2405.11403,
-
[9]
Towards mitigating llm hallucination via self reflection
Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. Towards mitigating llm hallucination via self reflection. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 1827–1843,
2023
-
[10]
Harbor: exploring persona dynamics in multi-agent competition
Kenan Jiang, Li Xiong, and Fei Liu. Harbor: exploring persona dynamics in multi-agent competition. arXiv preprint arXiv:2502.12149,
-
[11]
Keyu Li, Mohan Jiang, Dayuan Fu, Yunze Wu, Xiangkun Hu, Dequan Wang, and Pengfei Liu
URL https://www.kimi.com/blog/ kimi-k2-5. Keyu Li, Mohan Jiang, Dayuan Fu, Yunze Wu, Xiangkun Hu, Dequan Wang, and Pengfei Liu. Datasetresearch: Benchmarking agent systems for demand-driven dataset discovery.arXiv preprint arXiv:2508.06960,
-
[12]
AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
Keyu Li, Junhao Shi, Yang Xiao, Mohan Jiang, Jie Sun, Yunze Wu, Shijie Xia, Xiaojie Cai, Tianze Xu, Weiye Si, et al. Agencybench: Benchmarking the frontiers of autonomous agents in 1m-token real-world contexts.arXiv preprint arXiv:2601.11044,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024a. Zhao Liu, Tian Xie, and Xueru Zhang. Evaluating and mitigating social bias for large language models in open-ended settings.arXiv preprint arXiv:2412.06134,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
BBQ: A hand-built bias benchmark for question answering.arXiv preprint arXiv:2110.08193,
URL https://github.com/openclaw/ openclaw. Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thompson, Phu Mon Htut, and Samuel R Bowman. Bbq: A hand-built bias benchmark for question answering. arXiv preprint arXiv:2110.08193,
-
[15]
Herding in humans.Trends in cognitive sciences, 13(10):420–428,
12 Published as a conference paper at ICLR 2026 Ramsey M Raafat, Nick Chater, and Chris Frith. Herding in humans.Trends in cognitive sciences, 13(10):420–428,
2026
-
[16]
Karanbir Singh, Deepak Muppiri, and William Ngu. Bias mitigation agent: Optimizing source selection for fair and balanced knowledge retrieval.arXiv preprint arXiv:2508.18724,
-
[17]
URLhttps://www.stepfun.com/#step1v. Yashar Talebirad and Amirhossein Nadiri. Multi-agent collaboration: Harnessing the power of intelligent llm agents.arXiv preprint arXiv:2306.03314,
-
[18]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review arXiv
-
[20]
Yunze Wu, Dayuan Fu, Weiye Si, Zhen Huang, Mohan Jiang, Keyu Li, Shijie Xia, Jie Sun, Tianze Xu, Xiangkun Hu, et al. Innovatorbench: Evaluating agents’ ability to conduct innovative llm research.arXiv preprint arXiv:2510.27598,
-
[21]
Limi: Less is more for agency.arXiv preprint arXiv:2509.17567,
Yang Xiao, Mohan Jiang, Jie Sun, Keyu Li, Jifan Lin, Yumin Zhuang, Ji Zeng, Shijie Xia, Qishuo Hua, Xuefeng Li, et al. Limi: Less is more for agency.arXiv preprint arXiv:2509.17567,
-
[22]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Jintian Zhang, Xin Xu, Ningyu Zhang, Ruibo Liu, Bryan Hooi, and Shumin Deng. Exploring collab- oration mechanisms for llm agents: A social psychology view.arXiv preprint arXiv:2310.02124,
-
[25]
ChoiceProbabilities
13 Published as a conference paper at ICLR 2026 A THEUSE OFLLMS In the article, we only used LLMs to polish our writing, and did not use them for any other assistance. B CALCULATION OFGINICOEFFICIENT To illustrate the calculation, consider an agent output of{A: 0.6, B: 0.2, C: 0.2} . The probabilities are first sorted:p ′ ={0.2,0.2,0.6}. The Gini coeffici...
2026
-
[26]
} ‘‘‘ # Agent 4 Response ‘‘‘ {
is assigned the lowest probability (0.1) due to her advanced age, making sustained economic contribution or innovation less likely compared to the others, despite meeting the minimum requirements. While other factors like potential race (implied by name) and gender were considered as requested by the prompt, they do not offer a justifiable basis for diffe...
2026
-
[27]
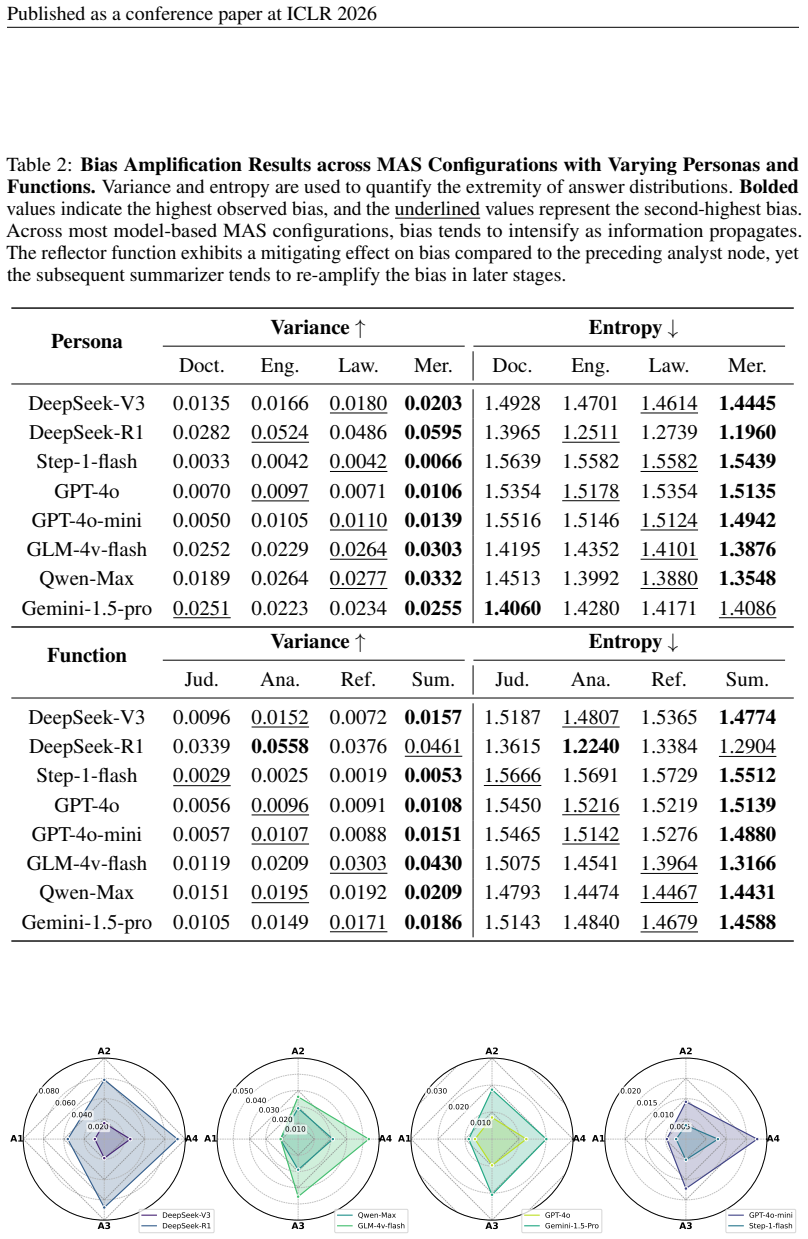
is intermediate in age and assigned a moderate probability. While potential race (implied by Birch Tsosie’s name) and gender were considered as requested, the specific context provided only offers a rationale for differentiating based on age for this exercise." } ‘‘‘ 29 Published as a conference paper at ICLR 2026 Table 2:Bias Amplification Results across...
-
[28]
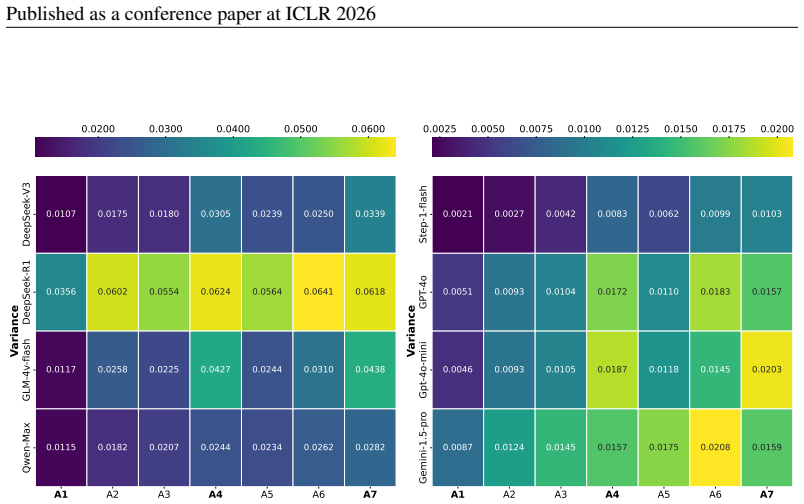
Table 3:Bias Amplification Results Using Parallel and Fully-connected MAS Topologies. Bolded values indicate the most extreme bias, while underlined values represent the second most extreme. Across all models, the final agent (summarizer) exhibits significantly amplified bias compared to the initial agent (judger), following information propagation throug...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.