Recognition: unknown
SiMing-Bench: Evaluating Procedural Correctness from Continuous Interactions in Clinical Skill Videos
Pith reviewed 2026-05-10 17:31 UTC · model grok-4.3
The pith
Multimodal models show weak agreement with physicians on clinical procedure correctness in videos, and global scores hide failures on intermediate steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
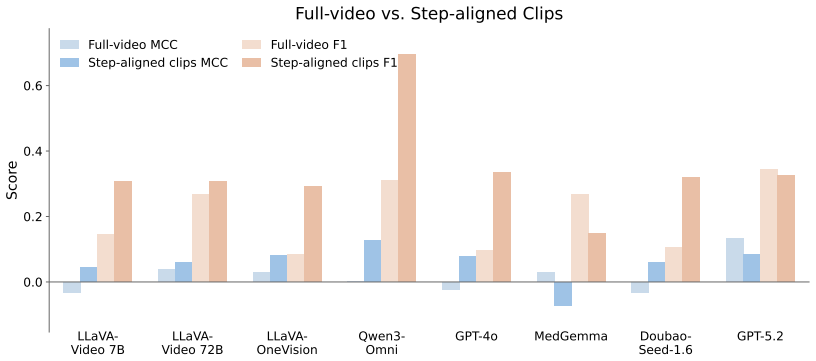
Across diverse open- and closed-source MLLMs, agreement with physician judgments on procedural correctness from clinical skill videos is weak. Weak performance on rubric-defined intermediate steps persists even when overall procedure-level correlation appears acceptable, indicating that coarse global assessment substantially overestimates current models' procedural judgment ability.
What carries the argument
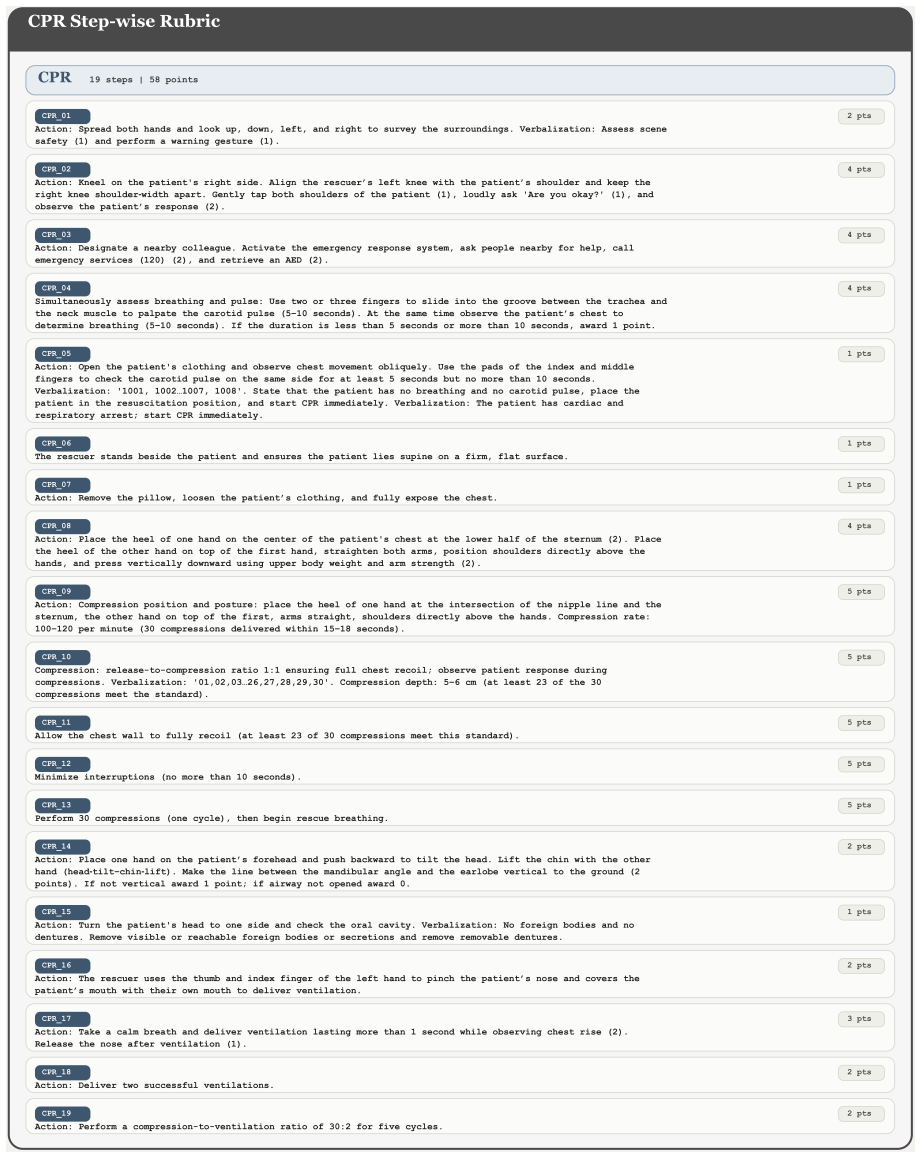
SiMing-Bench instantiated with SiMing-Score, the physician-annotated dataset of full-length clinical skill videos paired with standardized step-wise rubrics and dual-expert labels to assess whether interaction-driven state updates preserve procedural correctness across the workflow.
If this is right
- Coarse global assessment substantially overestimates MLLMs' procedural judgment ability.
- The bottleneck is modeling how continuous interactions update procedural state over time, not merely fine-grained scoring or temporal localization.
- Binary step judgment and step-aligned clips still expose the same limitation, confirming deeper deficits in state tracking.
Where Pith is reading between the lines
- Models may require explicit internal mechanisms to maintain and update procedural state representations from ongoing video interactions.
- The benchmark approach could extend to other procedural domains such as surgical training or industrial processes.
- Targeted training on videos that emphasize step-wise state changes could address the observed gaps.
Load-bearing premise
Dual-expert physician annotations on the selected videos and rubrics provide reliable, unbiased ground truth for procedural correctness across the full workflow.
What would settle it
A newly developed MLLM that achieves high agreement with the dual-expert labels on both overall procedures and individual rubric steps would falsify the reported weak agreement.
Figures






read the original abstract
Current video benchmarks for multimodal large language models (MLLMs) focus on event recognition, temporal ordering, and long-context recall, but overlook a harder capability required for expert procedural judgment: tracking how ongoing interactions update the procedural state and thereby determine the correctness of later actions. We introduce SiMing-Bench, the first benchmark for evaluating this capability from full-length clinical skill videos. It targets rubric-grounded process-level judgment of whether interaction-driven state updates preserve procedural correctness across an entire workflow. SiMing-Bench is instantiated with SiMing-Score, a physician-annotated dataset of real clinical skill examination videos spanning cardiopulmonary resuscitation, automated external defibrillator operation, and bag-mask ventilation, each paired with a standardized step-wise rubric and dual-expert labels. Across diverse open- and closed-source MLLMs, we observe consistently weak agreement with physician judgments. Moreover, weak performance on rubric-defined intermediate steps persists even when overall procedure-level correlation appears acceptable, suggesting that coarse global assessment substantially overestimates current models' procedural judgment ability. Additional analyses with binary step judgment and step-aligned clips indicate that the bottleneck is not merely fine-grained scoring or temporal localization, but modeling how continuous interactions update procedural state over time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SiMing-Bench, the first benchmark for evaluating MLLMs on rubric-grounded procedural correctness in full-length clinical skill videos (CPR, AED operation, bag-mask ventilation). It pairs videos with standardized step-wise rubrics and dual-expert physician labels, then reports consistently weak MLLM agreement with physicians; intermediate-step performance remains weak even when procedure-level correlation appears acceptable, concluding that coarse global assessment substantially overestimates current models' ability to track interaction-driven state updates.
Significance. If the central findings hold after addressing annotation reliability, the work provides a valuable new resource for assessing a previously overlooked capability in video MLLMs—dynamic procedural-state modeling from continuous interactions—which has direct relevance to medical training, simulation, and AI-assisted skill evaluation. The step-aligned analyses and binary-judgment experiments help isolate the bottleneck beyond simple localization or granularity.
major comments (1)
- [dataset construction paragraph / §3] Dataset construction paragraph and §3: The manuscript describes dual-expert physician annotations on rubrics and videos but reports no inter-rater reliability statistics (Cohen’s kappa, percentage agreement, or disagreement-resolution protocol) for the step-wise judgments. Without these metrics, the headline claim that weak model–physician agreement demonstrates a genuine procedural-state-modeling deficit (rather than label noise) cannot be evaluated; moderate inter-expert agreement on intermediate steps would directly undermine the conclusion that coarse global assessment “substantially overestimates” model capabilities.
minor comments (2)
- [Abstract] Abstract: The abstract asserts “consistently weak agreement” and “weak performance on rubric-defined intermediate steps” without any numerical values, dataset size, number of videos, or model names, forcing readers to consult the full text for even basic evidence strength.
- [Results / Experiments] The paper would benefit from an explicit table or figure summarizing inter-model agreement scores, step-level vs. procedure-level correlations, and the exact number of videos/rubrics per procedure to allow direct comparison with future work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The primary concern regarding the lack of inter-rater reliability statistics is addressed point-by-point below. We will revise the manuscript to incorporate the requested metrics and protocol details.
read point-by-point responses
-
Referee: [dataset construction paragraph / §3] Dataset construction paragraph and §3: The manuscript describes dual-expert physician annotations on rubrics and videos but reports no inter-rater reliability statistics (Cohen’s kappa, percentage agreement, or disagreement-resolution protocol) for the step-wise judgments. Without these metrics, the headline claim that weak model–physician agreement demonstrates a genuine procedural-state-modeling deficit (rather than label noise) cannot be evaluated; moderate inter-expert agreement on intermediate steps would directly undermine the conclusion that coarse global assessment “substantially overestimates” model capabilities.
Authors: We agree that reporting inter-rater reliability is essential to substantiate the reliability of the dual-expert labels and to rule out label noise as an explanation for the observed model-physician discrepancies. The original manuscript describes the dual-expert annotation process in §3 but omits the quantitative agreement metrics and resolution protocol. In the revised version, we will add Cohen’s kappa, percentage agreement (both overall and stratified by procedure and step type), and a description of how disagreements were resolved. These statistics will be computed directly from the existing dual annotations and presented in the dataset construction section to allow readers to evaluate label quality, particularly for intermediate steps. This addition will support rather than undermine our central claim. revision: yes
Circularity Check
New benchmark and empirical evaluation with no circular derivation chain
full rationale
The paper introduces SiMing-Bench as a new physician-annotated dataset of clinical skill videos paired with step-wise rubrics and dual-expert labels, then reports direct empirical observations of MLLM agreement with those labels. No mathematical derivations, equations, fitted parameters, or predictions are claimed; the central results (weak agreement, intermediate-step failures despite acceptable global correlation) are observational comparisons against the newly created ground truth rather than reductions to self-referential inputs or prior self-citations. The work is self-contained as a benchmark contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Physician dual-expert annotations constitute reliable ground truth for procedural correctness
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
- [3]
-
[4]
Lauren Chong, Silas Taylor, Matthew Haywood, Barbara-Ann Adelstein, and Boaz Shulruf. 2017. The sights and insights of examiners in objective structured clinical examinations. Journal of educational evaluation for health professions, 14
2017
-
[5]
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, and 1 others. 2026. Molmo2: Open weights and data for vision-language models with video understanding and grounding. arXiv preprint arXiv:2601.10611
-
[6]
Michael D Cusimano, Robert Cohen, William Tucker, John Murnaghan, Ron Kodama, and Richard Reznick. 1994. A comparative analysis of the costs of administration of an osce (objective structured clinical examination). Academic Medicine, 69(7):571--6
1994
-
[7]
Ronald M Epstein and Edward M Hundert. 2002. Defining and assessing professional competence. Jama, 287(2):226--235
2002
-
[8]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, and 1 others. 2025. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 24108--24118
2025
-
[9]
Zhiqi Ge, Hongzhe Huang, Mingze Zhou, Juncheng Li, Guoming Wang, Siliang Tang, and Yueting Zhuang. 2024. Worldgpt: Empowering llm as multimodal world model. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 7346--7355
2024
-
[10]
Google . 2025. A new era of intelligence with gemini 3. https://blog.google/products-and-platforms/products/gemini/gemini-3/. Accessed: 2026-03-15
2025
-
[11]
Ronald M Harden, Mary Stevenson, W Wilson Downie, and GM Wilson. 1975. Assessment of clinical competence using objective structured examination. Br Med J, 1(5955):447--451
1975
-
[12]
David Hope and Helen Cameron. 2015. Examiners are most lenient at the start of a two-day osce. Medical Teacher, 37(1):81--85
2015
-
[13]
Kamran Z Khan, Sankaranarayanan Ramachandran, Kathryn Gaunt, and Piyush Pushkar. 2013. The objective structured clinical examination (osce): Amee guide no. 81. part i: an historical and theoretical perspective. Medical teacher, 35(9):e1437--e1446
2013
-
[14]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and 1 others. 2024 a . Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, and 1 others. 2025 a . Viewspatial-bench: Evaluating multi-perspective spatial localization in vision-language models. arXiv preprint arXiv:2505.21500
-
[16]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, and 1 others. 2024 b . Mvbench: A comprehensive multi-modal video understanding benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195--22206
2024
- [17]
-
[18]
Ye Liu, Zongyang Ma, Zhongang Qi, Yang Wu, Ying Shan, and Chang W Chen. 2024. Et bench: Towards open-ended event-level video-language understanding. Advances in Neural Information Processing Systems, 37:32076--32110
2024
- [19]
- [20]
-
[21]
Kevin McLaughlin, Martha Ainslie, Sylvain Coderre, Bruce Wright, and Claudio Violato. 2009. The effect of differential rater function over time (drift) on objective structured clinical examination ratings. Medical education, 43(10):989--992
2009
-
[22]
George E Miller. 1990. The assessment of clinical skills/competence/performance. Academic medicine, 65(9):S63--7
1990
- [23]
-
[24]
Junzhi Ning, Wei Li, Cheng Tang, Jiashi Lin, Chenglong Ma, Chaoyang Zhang, Jiyao Liu, Ying Chen, Shujian Gao, Lihao Liu, Yuandong Pu, Huihui Xu, Chenhui Gou, Ziyan Huang, Yi Xin, Qi Qin, Zhongying Deng, Diping Song, Bin Fu, and 8 others. 2025. https://arxiv.org/abs/2510.15710 Unimedvl: Unifying medical multimodal understanding and generation through obser...
-
[25]
OpenAI . 2024. Hello gpt-4o. https://openai.com/index/hello-gpt-4o/. Accessed: 2026-03-15
2024
-
[26]
OpenAI . 2025. Introducing gpt-5.2. https://openai.com/index/introducing-gpt-5-2/. Accessed: 2026-03-15
2025
-
[27]
Chiara Plizzari, Alessio Tonioni, Yongqin Xian, Achin Kulshrestha, and Federico Tombari. 2025. Omnia de egotempo: Benchmarking temporal understanding of multi-modal llms in egocentric videos. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 24129--24138
2025
-
[28]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C \' an Hughes, Charles Lau, and 1 others. 2025. Medgemma technical report. arXiv preprint arXiv:2507.05201
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Shiva Sreeram, Tsun-Hsuan Wang, Alaa Maalouf, Guy Rosman, Sertac Karaman, and Daniela Rus. 2025. Probing multimodal llms as world models for driving. IEEE Robotics and Automation Letters
2025
-
[30]
Cees PM Van Der Vleuten and Lambert WT Schuwirth. 2005. Assessing professional competence: from methods to programmes. Medical education, 39(3):309--317
2005
-
[31]
Volcano Engine . 2025. Doubao-seed-1.6-vision. https://www.volcengine.com/docs/82379/1330310. Official model documentation page, Accessed: 2026-03-15
2025
-
[32]
Merrilyn Walton, Helen Woodward, Samantha Van Staalduinen, Claire Lemer, Felix Greaves, Douglas Noble, Benjamin Ellis, Liam Donaldson, Bruce Barraclough, and as Expert Lead for the Sub-Programme Expert Group convened by the World Alliance of Patient Safety. 2011. Republished paper: The who patient safety curriculum guide for medical schools. Postgraduate ...
2011
-
[33]
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, and 1 others. 2025 a . Lvbench: An extreme long video understanding benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958--22967
2025
-
[34]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, and 1 others. 2025 b . Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Yuxuan Wang, Yueqian Wang, Bo Chen, Tong Wu, Dongyan Zhao, and Zilong Zheng. 2025 c . Omnimmi: A comprehensive multi-modal interaction benchmark in streaming video contexts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18925--18935
2025
-
[36]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, and 1 others. 2025. Qwen3-omni technical report. arXiv preprint arXiv:2509.17765
work page internal anchor Pith review arXiv 2025
- [37]
- [38]
- [39]
- [40]
-
[41]
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. 2024. Llava-video: Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713
work page internal anchor Pith review arXiv 2024
-
[42]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[43]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.