Recognition: unknown
Watt Counts: Energy-Aware Benchmark for Sustainable LLM Inference on Heterogeneous GPU Architectures
Pith reviewed 2026-05-10 17:29 UTC · model grok-4.3
The pith
Selecting the right GPU for each LLM and scenario can cut energy use by up to 70 percent in servers with negligible user impact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
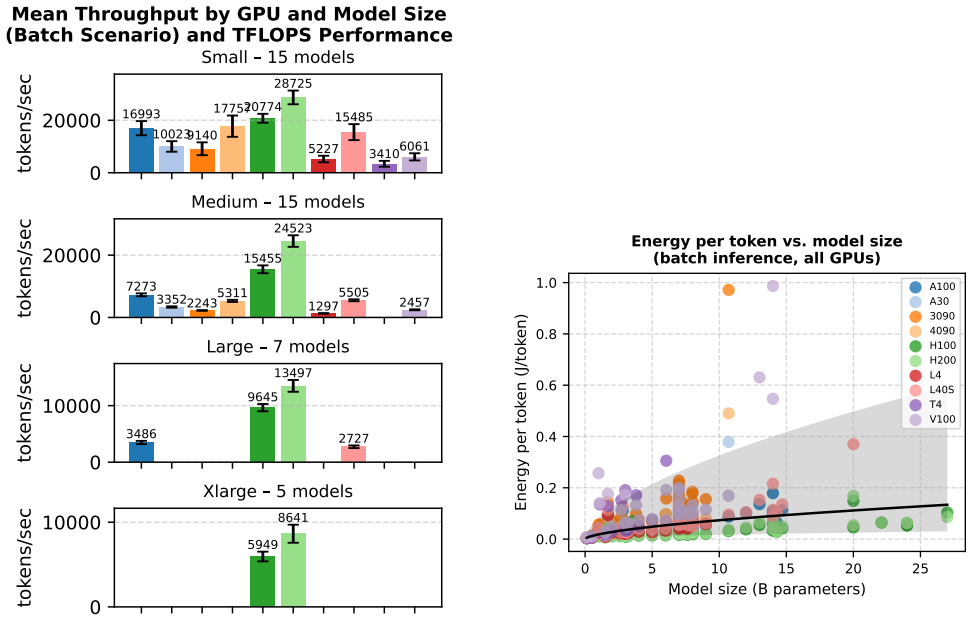
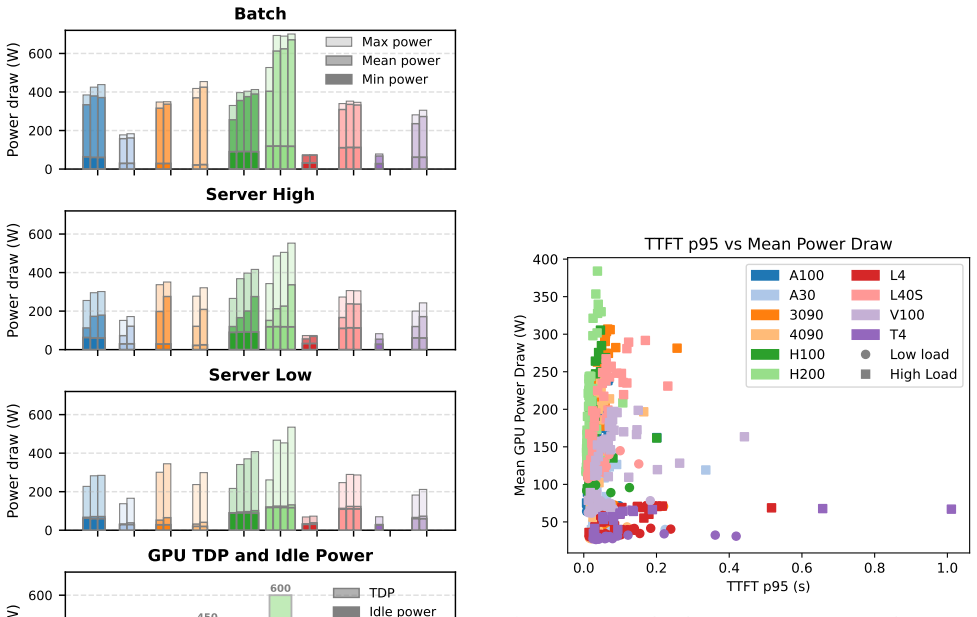
The authors establish that GPU architecture choice dominates energy outcomes for LLM inference, with optimal hardware varying significantly across models and between batch and server scenarios, and that informed selection guided by the new dataset enables energy reductions of up to 70 percent in server deployments and 20 percent in batch deployments while preserving user experience.
What carries the argument
The Watt Counts dataset and accompanying benchmark, which records energy consumption for LLM inference runs across heterogeneous NVIDIA GPUs in both batch and server scenarios.
If this is right
- System operators must treat hardware selection as model- and scenario-specific rather than using one GPU type for everything.
- Energy-aware benchmarks become necessary infrastructure for sustainable LLM deployments.
- Heterogeneous GPU clusters can deliver lower energy use than homogeneous ones when the right mappings are known.
- Open measurement data accelerates identification of energy-efficient configurations across the community.
Where Pith is reading between the lines
- Production systems may eventually need workload-aware schedulers that assign models to the lowest-energy GPU available at request time.
- Extending the measurements to non-NVIDIA accelerators or newer model families would test whether the same selection principle holds outside the current dataset.
- The savings figures could be combined with carbon-intensity data to minimize both energy and emissions rather than energy alone.
- Benchmark results could feed into cost models that trade off hardware purchase price against long-term electricity cost.
Load-bearing premise
The recorded energy numbers and the chosen definition of negligible user-experience impact match what actually happens in varied real-world production workloads.
What would settle it
Running the same models on the same GPUs inside an active production serving system and measuring that the reported energy savings do not appear or that latency, throughput, or satisfaction metrics degrade beyond the stated negligible threshold.
Figures



read the original abstract
While the large energy consumption of Large Language Models (LLMs) is recognized by the community, system operators lack guidance for energy-efficient LLM inference deployments that leverage energy trade-offs of heterogeneous hardware due to a lack of energy-aware benchmarks and data. In this work we address this gap with Watt Counts: the largest open-access dataset of energy consumption of LLMs, with over 5,000 experiments for 50 LLMs across 10 NVIDIA Graphics Processing Units (GPUs) in batch and server scenarios along with a reproducible, open-source benchmark that enables community submissions to expand this dataset. Leveraging this dataset, we conduct a system-level study of LLM inference across heterogeneous GPU architectures and show that GPU selection is crucial for energy efficiency outcomes and that optimal hardware choices vary significantly across models and deployment scenarios, demonstrating the critical importance of hardware-aware deployment in heterogeneous LLM systems. Guided by our data and insights, we show that practitioners can reduce energy consumption by up to 70% in server scenarios with negligible impact on user experience, and by up to 20% in batch scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Watt Counts, an open-access dataset of over 5,000 energy-consumption experiments covering 50 LLMs on 10 NVIDIA GPUs in batch and server scenarios, together with a reproducible open-source benchmark. It performs a system-level analysis showing that GPU selection is critical for energy efficiency, that optimal hardware choices vary across models and scenarios, and that practitioners can achieve up to 70% energy reduction in server mode and 20% in batch mode with negligible impact on user experience.
Significance. If the measurements and UX definitions hold, the work supplies the first large-scale empirical resource for energy-aware LLM deployment on heterogeneous GPUs and demonstrates the practical value of hardware-aware scheduling. The open dataset and benchmark tool constitute a clear community contribution that supports reproducibility and incremental extension.
major comments (3)
- [Abstract] Abstract: the headline claim of 'up to 70% energy reduction in server scenarios with negligible impact on user experience' is load-bearing for the paper's practical contribution, yet the abstract (and the reader's summary) provides no explicit definition or threshold for 'negligible impact' (e.g., latency percentile, throughput bound, or quality metric). Without this definition and supporting validation against tail latency or output-quality drift, the quantitative savings cannot be assessed for robustness.
- [Methods] Methods / experimental protocol (referenced in the abstract's description of the 5,000-experiment dataset): the energy-measurement methodology is not described with sufficient detail to support the reported savings. Key missing elements include whether power is measured at the GPU or full-system level, sampling rate, handling of thermal throttling, and any error analysis or confidence intervals on the 70% and 20% figures. Systematic bias in metering directly affects the central quantitative claims.
- [Dataset and Experiments] Dataset and analysis sections: the representativeness of the tested workloads (model sizes, batch sizes, request patterns) is not justified against production distributions. If the optimal-GPU selections and savings figures are driven primarily by synthetic prompts, the generalization of the 'up to 70%' result to real multi-tenant server deployments is weakened.
minor comments (1)
- [Abstract] Abstract: the phrase 'negligible impact on user experience' should be replaced or immediately qualified with the concrete proxy metric used in the study.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below. Where the concerns identify gaps in clarity or detail, we will revise the manuscript to strengthen the presentation without altering the core claims or data.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 'up to 70% energy reduction in server scenarios with negligible impact on user experience' is load-bearing for the paper's practical contribution, yet the abstract (and the reader's summary) provides no explicit definition or threshold for 'negligible impact' (e.g., latency percentile, throughput bound, or quality metric). Without this definition and supporting validation against tail latency or output-quality drift, the quantitative savings cannot be assessed for robustness.
Authors: We agree that the abstract would benefit from an explicit definition of 'negligible impact on user experience' to make the claim self-contained. In the revised version we will insert a concise parenthetical definition (e.g., 'no more than 5% increase in 99th-percentile latency and no measurable degradation in output quality') and add a forward reference to the evaluation sections where we report the supporting latency and quality measurements across hardware choices. This change improves readability without changing the underlying experimental results. revision: yes
-
Referee: [Methods] Methods / experimental protocol (referenced in the abstract's description of the 5,000-experiment dataset): the energy-measurement methodology is not described with sufficient detail to support the reported savings. Key missing elements include whether power is measured at the GPU or full-system level, sampling rate, handling of thermal throttling, and any error analysis or confidence intervals on the 70% and 20% figures. Systematic bias in metering directly affects the central quantitative claims.
Authors: We accept that the current Methods section is insufficiently detailed for full reproducibility of the quantitative claims. The measurements were taken at the full-system level via an external power meter with GPU power cross-validated through nvidia-smi at 1 Hz; thermal throttling was avoided by enforcing GPU temperatures below 70 °C and repeating runs when throttling was detected. We will expand the Methods section with these specifics, add a short error-analysis subsection reporting standard deviations and 95% confidence intervals on the energy figures (derived from three repeated trials per configuration), and include a brief discussion of potential metering bias. These additions directly address the referee's concern. revision: yes
-
Referee: [Dataset and Experiments] Dataset and analysis sections: the representativeness of the tested workloads (model sizes, batch sizes, request patterns) is not justified against production distributions. If the optimal-GPU selections and savings figures are driven primarily by synthetic prompts, the generalization of the 'up to 70%' result to real multi-tenant server deployments is weakened.
Authors: We acknowledge the value of explicit justification against production distributions. Our current workloads combine synthetic prompts with traces drawn from public conversational datasets (ShareGPT, LMSYS) and cover a range of batch sizes and request rates that align with published inference-server statistics; however, we did not include a dedicated comparison subsection. In revision we will add a short paragraph in the Dataset section that cites representative production characteristics from the literature and discusses the extent to which our synthetic and semi-real traces approximate multi-tenant server behavior. We will also note the limitation that full multi-tenant interference traces were outside the scope of this initial release. This strengthens the paper while preserving the reported findings. revision: partial
Circularity Check
No circularity: purely empirical benchmark and dataset study
full rationale
The paper describes the creation of an open dataset from over 5,000 direct energy measurements of 50 LLMs on 10 GPUs in batch and server scenarios, followed by observational analysis of hardware selection effects. The reported energy reductions (up to 70% server, 20% batch) are presented as outcomes of comparing measured values under different GPU choices, with no equations, fitted parameters, predictive models, or derivations that could reduce to inputs by construction. No self-citations, ansatzes, uniqueness theorems, or renamings of known results appear as load-bearing elements in the provided text. The work is self-contained as data collection and comparison, with no mathematical chain that collapses to tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Energy consumption can be measured accurately and reproducibly with standard GPU power-monitoring tools across the tested hardware and workloads.
Reference graph
Works this paper leans on
-
[1]
Y.Jernite,S.Luccioni,Computeandcompetitioninai:Differentflops for different folks, hugging Face Community Article (Feb. 2026). URLhttps://huggingface.co/blog/sasha/compute-competition
2026
-
[2]
You, How much energy does chatgpt use?, Gradient Updates (Epoch AI newsletter), accessed: 2025-07-31 (Feb
J. You, How much energy does chatgpt use?, Gradient Updates (Epoch AI newsletter), accessed: 2025-07-31 (Feb. 2025). URLhttps://epoch.ai/gradient-updates/ how-much-energy-does-chatgpt-use
2025
-
[3]
G. Yang, C. He, J. Guo, J. Wu, Y. Ding, A. Liu, H. Qin, P. Ji, X. Liu, Llmcbench: Benchmarking large language model compression for efficient deployment, Advances in Neural Information Processing Systems 37 (2024) 87532–87544
2024
-
[4]
Burian, A
V. Burian, A. Stalla-Bourdillon, The increasing energy demand of artificial intelligence and its impact on commodity prices, Economic Bulletin,FocusBox 2/2025, European Central Bank, accessed: 2025-07-31 (May 2025). URLhttps://www.ecb.europa.eu/press/economic-bulletin/focus/ 2025/html/ecb.ebbox202502_03~8eba688e29.en.html
2025
-
[5]
D.Xue,Strategiesformitigatingtheglobalenergyandcarbonimpact of artificial intelligence, United Nations SDGs (2023) 2023–05
2023
-
[6]
M. F. Argerich, M. Patiño-Martínez, Measuring and improving the energy efficiency of large language models inference, IEEE Access (2024)
2024
-
[7]
Theodorou, S
G. Theodorou, S. Karagiorgou, C. Kotronis, On energy-aware and verifiablebenchmarkingofbigdataprocessingtargetingaipipelines, in:2024IEEEInternationalConferenceonBigData(BigData),IEEE, 2024, pp. 3788–3798
2024
-
[8]
V. Liu, Y. Yin, Green ai: exploring carbon footprints, mitigation strategies, and trade offs in large language model training, Discover Artificial Intelligence 4 (1) (2024) 49
2024
-
[9]
Carbon Emissions and Large Neural Network Training
D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, J. Dean, Carbon emissions and large neural network training, arXiv preprint arXiv:2104.10350 (2021)
work page internal anchor Pith review arXiv 2021
- [10]
-
[11]
Samsi, D
S. Samsi, D. Zhao, J. McDonald, B. Li, A. Michaleas, M. Jones, W.Bergeron,J.Kepner,D.Tiwari,V.Gadepally,Fromwordstowatts: Benchmarking the energy costs of large language model inference, in: 2023 IEEE High Performance Extreme Computing Conference (HPEC), IEEE, 2023, pp. 1–9
2023
- [12]
-
[13]
arXiv preprint arXiv:2503.05804 , year=
J. Morrison, C. Na, J. Fernandez, T. Dettmers, E. Strubell, J. Dodge, Holisticallyevaluatingtheenvironmentalimpactofcreatinglanguage models, arXiv preprint arXiv:2503.05804 (2025)
-
[14]
Chang, F
C.-J.Wu,R.Raghavendra,U.Gupta,B.Acun,N.Ardalani,K.Maeng, G. Chang, F. Aga, J. Huang, C. Bai, et al., Sustainable ai: Envi- ronmentalimplications,challengesandopportunities,Proceedingsof Machine Learning and Systems 4 (2022) 795–813
2022
- [15]
- [16]
-
[17]
Tschand, A
A. Tschand, A. T. R. Rajan, S. Idgunji, A. Ghosh, J. Holleman, C. Kiraly, P. Ambalkar, R. Borkar, R. Chukka, T. Cockrell, et al., Mlperfpower:Benchmarkingtheenergyefficiencyofmachinelearn- ing systems from𝜇watts to mwatts for sustainable ai, in: 2025 IEEE International Symposium on High Performance Computer Architec- ture (HPCA), IEEE, 2025, pp. 1201–1216
2025
-
[18]
V. J. Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J. Wu, B. Anderson, M. Breughe, M. Charlebois, W. Chou, R. Chukka, C. Coleman, S. Davis, P. Deng, G. Diamos, J. Duke, D. Fick, J. S. :Preprint submitted to Elsevier Page 11 of 13 Gardner, I. Hubara, S. Idgunji, T. B. Jablin, J. Jiao, T. S. John, P. Kanwar, D. Lee, J. Liao, A. Lokhmotov, F. M...
- [19]
- [20]
-
[21]
A framework for few-shot language model evaluation
V. Schmidt, K. Goyal, A. Joshi, B. Feld, L. Conell, N. Laskaris, D. Blank, J. Wilson, S. Friedler, S. Luccioni, Codecarbon: estimate andtrackcarbonemissionsfrommachinelearningcomputing(2021), DOI: https://doi. org/10.5281/zenodo 4658424 (2021)
-
[22]
You, J.-W
J. You, J.-W. Chung, M. Chowdhury, Zeus: Understanding and op- timizing GPU energy consumption of DNN training, in: USENIX NSDI, 2023
2023
-
[23]
Chung, J
J.-W. Chung, J. J. Ma, R. Wu, J. Liu, O. J. Kweon, Y. Xia, Z.Wu,M.Chowdhury,TheML.ENERGYbenchmark:Towardauto- mated inference energy measurement and optimization, in: NeurIPS Datasets and Benchmarks, 2025
2025
-
[24]
1348–1362
J.Stojkovic,C.Zhang,Í.Goiri,J.Torrellas,E.Choukse,Dynamollm: Designing llm inference clusters for performance and energy effi- ciency,in:2025IEEEInternationalSymposiumonHighPerformance Computer Architecture (HPCA), IEEE, 2025, pp. 1348–1362
2025
-
[25]
Z.Fu,F.Chen,S.Zhou,H.Li,L.Jiang,Llmco2:Advancingaccurate carbon footprint prediction for llm inferences, ACM SIGENERGY Energy Informatics Review 5 (2) (2025) 63–68
2025
-
[26]
A. K. Kakolyris, D. Masouros, P. Vavaroutsos, S. Xydis, D. Soudris, throttll’em:Predictivegputhrottlingforenergyefficientllminference serving, in: 2025 IEEE International Symposium on High Perfor- mance Computer Architecture (HPCA), IEEE, 2025, pp. 1363–1378
2025
-
[27]
Patel, E
P. Patel, E. Choukse, C. Zhang, Í. Goiri, B. Warrier, N. Mahalingam, R. Bianchini, Characterizing power management opportunities for llms in the cloud, in: Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2024, pp. 207–222
2024
-
[28]
Fernandez, C
J. Fernandez, C. Na, V. Tiwari, Y. Bisk, S. Luccioni, E. Strubell, En- ergy considerations of large language model inference and efficiency optimizations, in: Proceedings of the 63rd Annual Meeting of the AssociationforComputationalLinguistics(Volume1:LongPapers), 2025, pp. 32556–32569
2025
-
[29]
G.Wilkins,S.Keshav,R.Mortier,Offlineenergy-optimalllmserving: Workload-based energy models for llm inference on heterogeneous systems,ACMSIGENERGYEnergyInformaticsReview4(5)(2024) 113–119
2024
-
[30]
Agrawal, N
A. Agrawal, N. Kedia, J. Mohan, A. Panwar, N. Kwatra, B. S. Gulavani, R. Ramjee, A. Tumanov, Vidur: A large-scale simulation framework for llm inference, Proceedings of Machine Learning and Systems 6 (2024) 351–366
2024
- [31]
-
[32]
C. Guo, S. Wang, R. Xie, J. Song, Estimating energy consumption of neural networks with joint structure–device encoding, Sustainable Computing: Informatics and Systems 45 (2025) 101062
2025
-
[33]
Luccioni, B
S. Luccioni, B. Gamazaychikov, E. Strubell, S. Hooker, Y. Jernite, M. Mitchell, S. Chamberlin, Ai energy score leaderboard - decem- ber 2025,https://huggingface.co/spaces/AIEnergyScore/Leaderboard (2025)
2025
-
[34]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gon- zalez, H. Zhang, I. Stoica, Efficient memory management for large language model serving with pagedattention, in: Proceedings of the 29thsymposiumonoperatingsystemsprinciples,2023,pp.611–626
2023
-
[35]
L. Stuhlmann, M. F. Argerich, J. Fürst, Bench360: Benchmarking lo- cal llm inference from 360{∖deg}, arXiv preprint arXiv:2511.16682 (2025)
- [36]
- [37]
-
[38]
V. J. Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J. Wu,B.Anderson,M.Breughe,M.Charlebois,W.Chou,etal.,Mlperf inferencebenchmark,in:2020ACM/IEEE47thAnnualInternational SymposiumonComputerArchitecture(ISCA),IEEE,2020,pp.446– 459
2020
-
[39]
G. Colakoglu, G. Solmaz, J. Fürst, Problem solved? information extraction design space for layout-rich documents using LLMs, in: C. Christodoulopoulos, T. Chakraborty, C. Rose, V. Peng (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2025, Association for Computational Linguistics, Suzhou, China, 2025, pp. 17908–17927.doi:10.18653/...
-
[40]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
P. Rajpurkar, J. Zhang, K. Lopyrev, P. Liang, Squad: 100,000+ questions for machine comprehension of text, arXiv preprint arXiv:1606.05250 (2016)
work page internal anchor Pith review arXiv 2016
-
[41]
Z. Yang, K. Adamek, W. Armour, Accurate and convenient energy measurements for gpus: A detailed study of nvidia gpu’s built-in power sensor, in: SC24: International Conference for High Perfor- mance Computing, Networking, Storage and Analysis, IEEE, 2024, pp. 1–17
2024
- [42]
- [43]
-
[44]
Deber, R
J. Deber, R. Jota, C. Forlines, D. Wigdor, How much faster is fast enough?userperceptionoflatency&latencyimprovementsindirect andindirecttouch,in:Proceedingsofthe33rdannualacmconference on human factors in computing systems, 2015, pp. 1827–1836
2015
-
[45]
S. Kim, D. Kim, C. Park, W. Lee, W. Song, Y. Kim, H. Kim, Y. Kim, H. Lee, J. Kim, et al., Solar 10.7 b: Scaling large language models withsimpleyeteffectivedepthup-scaling,in:Proceedingsofthe2024 Conference of the North American Chapter of the Association for ComputationalLinguistics:HumanLanguageTechnologies(Volume 6: Industry Track), 2024, pp. 23–35. A....
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.