Recognition: no theorem link
DeepGuard: Secure Code Generation via Multi-Layer Semantic Aggregation
Pith reviewed 2026-05-10 17:56 UTC · model grok-4.3
The pith
Aggregating security signals from multiple intermediate transformer layers raises the rate of secure and correct code generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Vulnerability-discriminative cues are most detectable in intermediate-to-upper layers of code LLMs and attenuate toward the final layer; an attention-based aggregation of multiple upper-layer representations can be combined with a multi-objective training objective to improve the secure-and-correct generation rate while preserving next-token prediction quality and supporting inference-time steering.
What carries the argument
An attention-based aggregation module that combines hidden states from several upper transformer layers to drive a separate security analyzer inside a multi-objective loss function.
If this is right
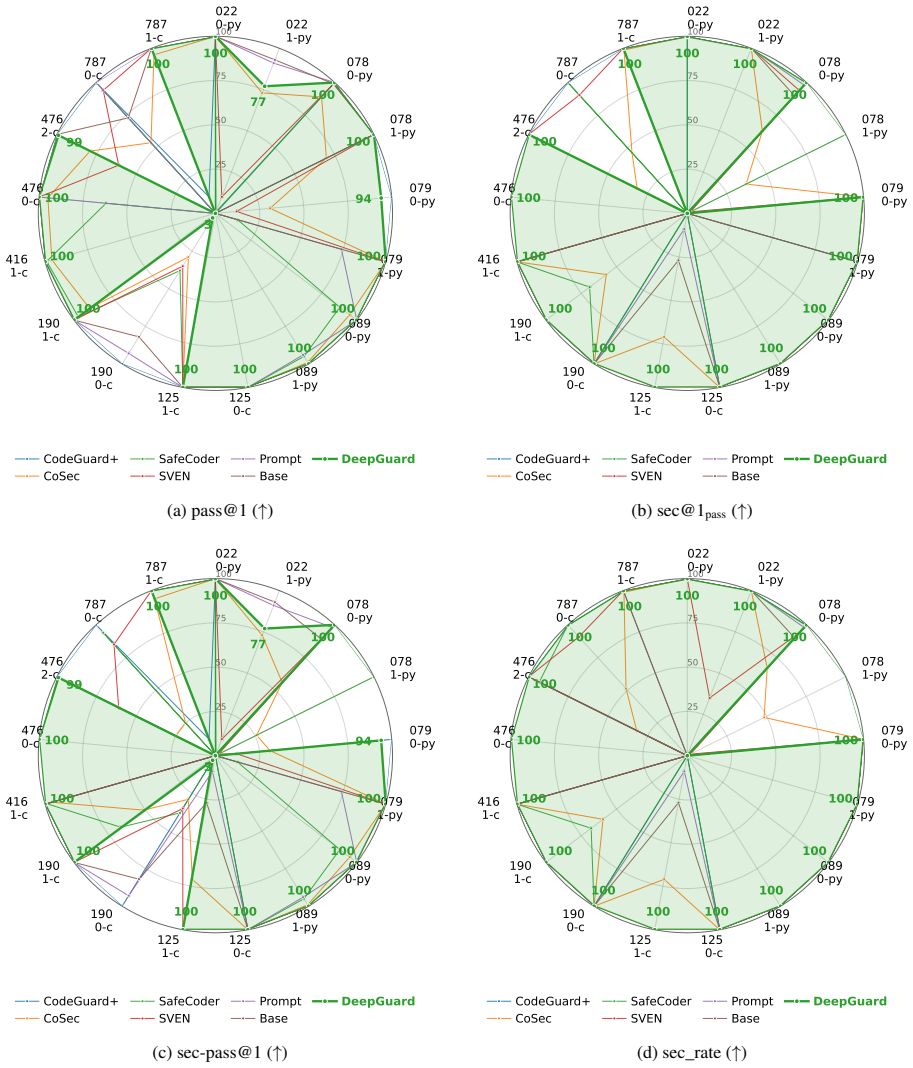
- The secure-and-correct generation rate rises by an average of 11.9 percent over baselines such as SVEN.
- Functional correctness of the generated code stays at the same level as the original model.
- The approach generalizes to vulnerability types held out from training.
- A lightweight inference-time steering strategy becomes available without retraining.
- The gains appear consistently across five different code-generation LLMs.
Where Pith is reading between the lines
- The same layer-probing approach could locate useful internal signals for other quality or safety properties beyond security.
- If aggregation adds little compute, production code generators might adopt it as a default safeguard.
- The finding that final layers optimize for prediction at the expense of other signals may apply to non-code generation tasks.
Load-bearing premise
Vulnerability signals remain distributed and readable enough in the selected layers that the aggregation step can combine them without creating new errors or weakening the model's ability to generate correct code.
What would settle it
A controlled experiment in which the same models are fine-tuned with final-layer supervision only and the secure-and-correct generation rate matches or exceeds the multi-layer version would falsify the need for aggregation.
Figures










read the original abstract
Large Language Models (LLMs) for code generation can replicate insecure patterns from their training data. To mitigate this, a common strategy for security hardening is to fine-tune models using supervision derived from the final transformer layer. However, this design may suffer from a final-layer bottleneck: vulnerability-discriminative cues can be distributed across layers and become less detectable near the output representations optimized for next-token prediction. To diagnose this issue, we perform layer-wise linear probing. We observe that vulnerability-related signals are most detectable in a band of intermediate-to-upper layers yet attenuate toward the final layers. Motivated by this observation, we introduce DeepGuard, a framework that leverages distributed security-relevant cues by aggregating representations from multiple upper layers via an attention-based module. The aggregated signal powers a dedicated security analyzer within a multi-objective training objective that balances security enhancement and functional correctness, and further supports a lightweight inference-time steering strategy. Extensive experiments across five code LLMs demonstrate that DeepGuard improves the secure-and-correct generation rate by an average of 11.9% over strong baselines such as SVEN. It also preserves functional correctness while exhibiting generalization to held-out vulnerability types. Our code is public at https://github.com/unknownhl/DeepGuard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DeepGuard, a framework for secure code generation in LLMs. It diagnoses a final-layer bottleneck via layer-wise linear probing showing stronger vulnerability signals in intermediate-to-upper layers, aggregates representations from multiple layers via an attention-based module to power a dedicated security analyzer, and trains under a multi-objective loss balancing security and functional correctness (with an optional inference-time steering strategy). Experiments across five code LLMs report an average 11.9% improvement in secure-and-correct generation rate over baselines such as SVEN, while preserving functional correctness and generalizing to held-out vulnerability types. Code is released publicly.
Significance. If the multi-layer aggregation is shown to be responsible for the gains, the work would meaningfully advance secure code generation by addressing potential attenuation of security cues in final-layer representations. The experiments on multiple models and public code release are clear strengths that support reproducibility and broader impact.
major comments (1)
- [§3 and §4] §3 (Method) and §4 (Experiments): The central claim attributes the 11.9% improvement in secure-and-correct generation to the attention-based multi-layer aggregation, motivated by the layer-wise probing observation. However, no ablation is reported that compares DeepGuard against an otherwise identical security analyzer and multi-objective objective that receives only the final-layer hidden state. Because the probing analysis is strictly linear, it does not establish that non-linear combinations at the final layer would be insufficient; without this control, the load-bearing contribution of the multi-layer design remains unverified.
minor comments (2)
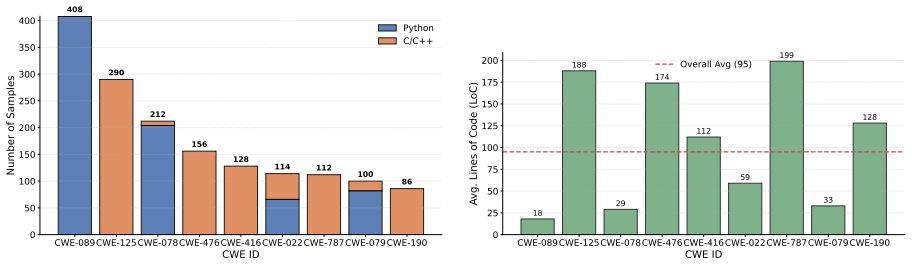
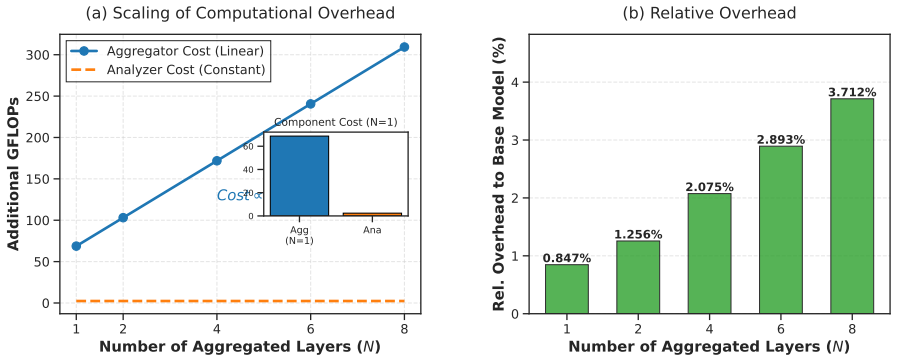
- [Abstract and §4] Abstract and §4: Average gains are reported without error bars, statistical significance tests, or details on exact baseline re-implementations and the selection criteria for held-out vulnerabilities.
- [§3] §3: The multi-objective loss formulation and attention aggregation module would benefit from explicit equations or pseudocode to clarify the layer band selection and loss weighting.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The observation regarding the need for a targeted ablation to isolate the contribution of multi-layer aggregation is well-taken and directly strengthens the central claim of the work. We address the major comment below and will revise the manuscript to incorporate the suggested control experiment.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Method) and §4 (Experiments): The central claim attributes the 11.9% improvement in secure-and-correct generation to the attention-based multi-layer aggregation, motivated by the layer-wise probing observation. However, no ablation is reported that compares DeepGuard against an otherwise identical security analyzer and multi-objective objective that receives only the final-layer hidden state. Because the probing analysis is strictly linear, it does not establish that non-linear combinations at the final layer would be insufficient; without this control, the load-bearing contribution of the multi-layer design remains unverified.
Authors: We agree that the current experiments leave the specific contribution of the multi-layer aggregation partially unverified. The layer-wise linear probing establishes that vulnerability signals are stronger in intermediate-to-upper layers and attenuate toward the final layer, but as the referee correctly notes, this does not preclude a sufficiently expressive non-linear model from recovering comparable information from the final-layer representation alone. To address this directly, we will add a new ablation in the revised manuscript: an otherwise identical DeepGuard variant in which the security analyzer receives only the final-layer hidden state (with the same multi-objective loss, training procedure, and inference-time steering). We will report the secure-and-correct generation rates for this final-layer-only baseline across all five evaluated LLMs and compare them quantitatively to the full multi-layer DeepGuard results. This control will clarify whether the attention-based aggregation is responsible for the observed 11.9% average improvement. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical workflow: layer-wise linear probing on existing LLMs to observe vulnerability signal distribution, followed by design of an attention-based multi-layer aggregator and a multi-objective loss for fine-tuning. No equations, parameters, or predictions are defined such that the output reduces to the input by construction. The central performance claims rest on experimental comparisons rather than self-referential definitions, fitted quantities renamed as predictions, or load-bearing self-citations. The derivation chain is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes smuggled via prior author work.
Axiom & Free-Parameter Ledger
free parameters (2)
- layer band for aggregation
- multi-objective loss weight
axioms (2)
- domain assumption Vulnerability-related signals are linearly probeable and distributed across transformer layers
- domain assumption Attention aggregation preserves functional next-token information while enhancing security cues
Reference graph
Works this paper leans on
-
[1]
InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–11
A user-centered security evaluation of copilot. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–11. Enna Basic and Alberto Giaretta. 2024. Large language models and code security: A systematic literature review.arXiv preprint arXiv:2412.15004. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De ...
-
[2]
Enhanced automated code vulnerability repair using large language models.Engineering Applica- tions of Artificial Intelligence, 138:109291. Thomas Dohmke. 2023. Github copilot x: The ai-powered developer experience. https://github.blog/news-insights/product- news/github-copilot-x-the-ai-powered-developer- experience/. The GitHub Blog, March 22, 2023. Moha...
-
[3]
Constrained decoding for secure code genera- tion.arXiv preprint arXiv:2405.00218. GitHub. 2023. Codeql. https://codeql.github.com. GitHub CodeQL Official Website. Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, and 1 others. 2024. Deepseek- coder: When the large language model meets programming–...
-
[4]
Qwen2.5-Coder Technical Report
IEEE Computer Society. Li Huang, Meng Yan, Tao Yin, Weifeng Sun, Zhongxin Liu, Hongyu Zhang, and David Lo. 2026. Steer your model: Secure code generation with contrastive de- coding.IEEE Transactions on Software Engineering. Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, and 1 others. ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Sarker, Leandros Maglaras, and Naeem Janjua
Unveiling code pre-trained models: Investi- gating syntax and semantics capacities.ACM Trans- actions on Software Engineering and Methodology, 33(7):1–29. Vahid Majdinasab, Michael Joshua Bishop, Shawn Rasheed, Arghavan Moradidakhel, Amjed Tahir, and Foutse Khomh. 2024. Assessing the security of github copilot’s generated code-a targeted replica- tion stu...
-
[6]
CWE-476 0-c
The network consists of three hidden layers with non-linear activation and normalization, de- Table 8: Summary of hyperparameters used for training and evaluating DEEPGUARD. Hyperparameter Value Training Dynamics Epochs 5 Learning Rate2×10 −5 Batch Size (Effective) 16 Per-Device Batch Size 8 Gradient Accumulation 2 steps Max Gradient Norm 1.0 Optimizer (A...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.