Recognition: no theorem link
High-dimensional Adaptive MCMC with Reduced Computational Complexity
Pith reviewed 2026-05-10 16:39 UTC · model grok-4.3
The pith
Adaptive MCMC learns a dense preconditioner parametrized sparsely via online PCA and reflection matrices for O(m squared d) per-step cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that a preconditioner built as the product of a diagonal matrix and a short sequence of reflection matrices, with the reflection angles obtained from online principal component analysis of the MCMC trajectory, can be adapted on the fly while preserving the O(m squared d) cost scaling. This construction supplies the correlation structure needed for efficient sampling on non-diagonal targets without incurring the quadratic cost of storing or multiplying by a full dense matrix at every step.
What carries the argument
A linear preconditioner formed as a diagonal matrix times a product of reflection matrices, whose parameters are updated from online principal component analysis of the chain samples.
If this is right
- The method supplies correlation information at far lower per-step cost than any full dense adaptive preconditioner.
- It delivers higher absolute sampling efficiency than diagonal preconditioning on targets where correlations matter.
- Time-normalized performance exceeds both traditional dense preconditioners and multiple diagonal-plus-low-rank alternatives on the reported test problems.
- The reflection-matrix form keeps the adaptation stable while still allowing off-diagonal elements to be learned.
Where Pith is reading between the lines
- The same reflection-based parametrization could be tried in other adaptive Monte Carlo settings that currently rely on dense matrix updates.
- Choosing small m relative to dimension d would let the method scale to targets where full-matrix adaptation becomes prohibitive.
- If the online PCA step can be made robust to non-stationarity, the approach might extend to sequential Monte Carlo or other online inference tasks.
Load-bearing premise
Online principal component analysis run on the MCMC chain itself yields accurate enough estimates of the target covariance eigenstructure that the resulting reflection matrices produce a useful preconditioner without introducing bias or instability.
What would settle it
A high-dimensional target with strong correlations on which the online PCA estimates remain too inaccurate or noisy, so that the new method shows no gain or actually worse effective sample size per unit time than ordinary diagonal preconditioning.
Figures
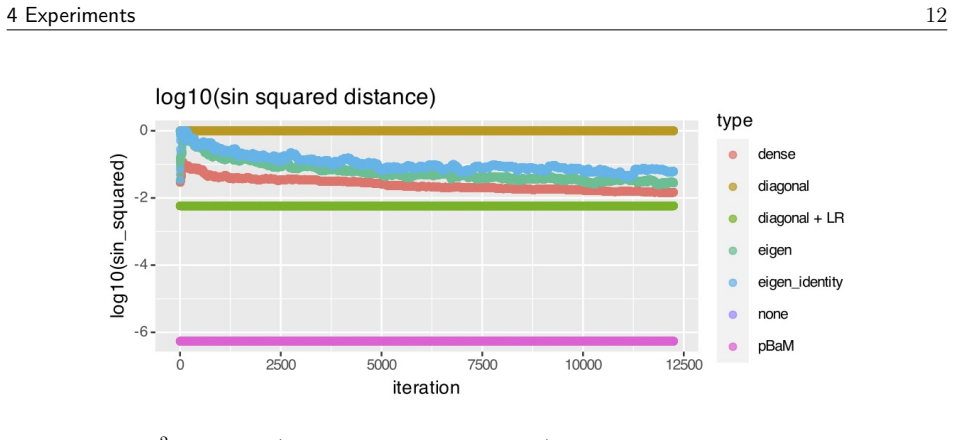
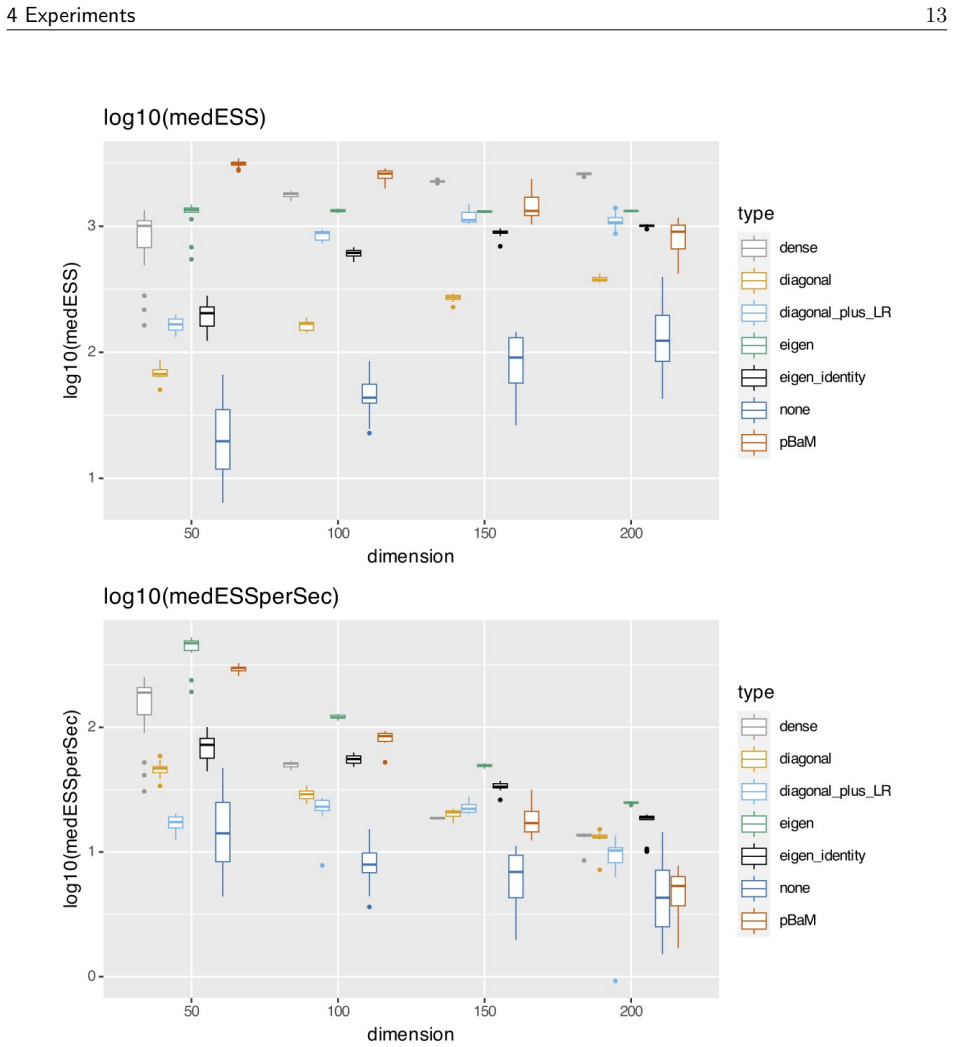
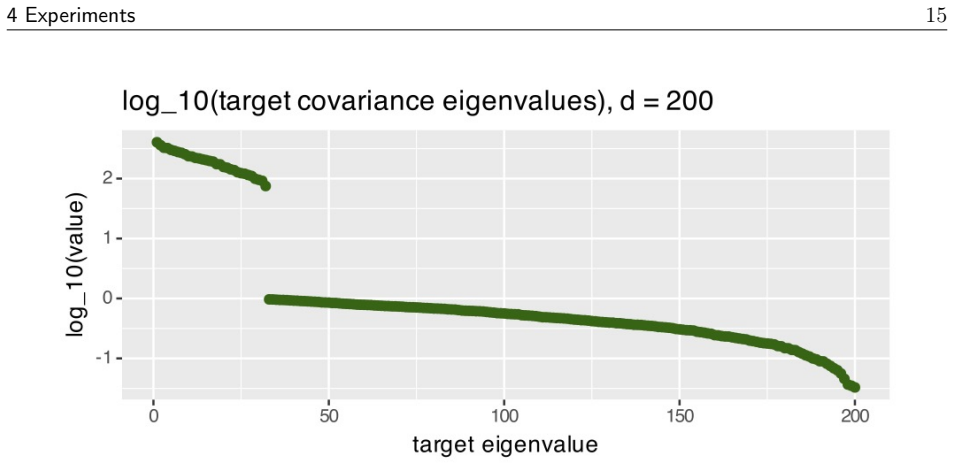




read the original abstract
We propose an adaptive MCMC method that learns a linear preconditioner which is dense in its off-diagonal elements but sparse in its parametrisation. Due to this sparsity, we achieve a per-iteration computational complexity of $O(m^2d)$ for a user-determined parameter $m$, compared with the $O(d^2)$ complexity of existing adaptive strategies that can capture correlation information from the target. Diagonal preconditioning has an $O(d)$ per-iteration complexity, but is known to fail in the case that the target distribution is highly correlated, see \citet[Section 3.5]{hird2025a}. Our preconditioner is constructed using eigeninformation from the target covariance which we infer using online principal components analysis on the MCMC chain. It is composed of a diagonal matrix and a product of carefully chosen reflection matrices. On various numerical tests we show that it outperforms diagonal preconditioning in terms of absolute performance, and that it outperforms traditional dense preconditioning and multiple diagonal plus low-rank alternatives in terms of time-normalised performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an adaptive MCMC algorithm that constructs a linear preconditioner for the proposal covariance. The preconditioner is dense in its off-diagonal elements but sparsely parametrized as the product of a diagonal matrix and a small number of reflection matrices, with the required eigeninformation obtained via online PCA applied to the running chain. This yields per-iteration cost O(m²d) for a user parameter m, in contrast to the O(d²) cost of full dense adaptation. Numerical experiments on several target distributions are reported to show superior absolute performance relative to diagonal preconditioning and superior time-normalized performance relative to both full dense and diagonal-plus-low-rank alternatives.
Significance. If the empirical results are reproducible and the online adaptation remains stable, the method offers a practical compromise between the inability of diagonal preconditioners to capture strong correlations and the prohibitive cost of maintaining a full dense covariance estimate. The reflection-matrix parametrization is a novel way to achieve dense structure at reduced parameter count, and the time-normalized gains could be useful in moderately high-dimensional settings where full adaptation is infeasible.
major comments (2)
- [Section on adaptation mechanism and numerical experiments] The central empirical claim rests on the online PCA supplying sufficiently accurate eigen-directions without violating diminishing-adaptation conditions. The manuscript should explicitly verify (in the experimental section) that the adaptation schedule satisfies the standard requirements of Roberts & Rosenthal (2007) or equivalent ergodicity theorems; otherwise the reported performance gains cannot be guaranteed to persist as d grows.
- [Section describing the preconditioner parametrization] The reflection-matrix construction is claimed to preserve necessary correlation structure, yet no quantitative bound is given on the approximation error relative to the full eigen-decomposition of the estimated covariance. A short derivation or numerical diagnostic showing the Frobenius or operator-norm error as a function of m would strengthen the complexity claim.
minor comments (2)
- The abstract cites hird2025a Section 3.5; ensure the bibliography entry is complete and the section number is correct in the final version.
- Clarify the precise initialization and forgetting factor used in the online PCA update; these details affect reproducibility of the reported timings.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation and constructive suggestions. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: The central empirical claim rests on the online PCA supplying sufficiently accurate eigen-directions without violating diminishing-adaptation conditions. The manuscript should explicitly verify (in the experimental section) that the adaptation schedule satisfies the standard requirements of Roberts & Rosenthal (2007) or equivalent ergodicity theorems; otherwise the reported performance gains cannot be guaranteed to persist as d grows.
Authors: We agree that explicit verification strengthens the claims. Our adaptation employs a standard diminishing step-size schedule for the online PCA updates (with step sizes satisfying the usual summability conditions). In the revised manuscript we will add a short subsection in the numerical experiments section that confirms compliance with the Roberts & Rosenthal (2007) conditions, including the required decay rates on the adaptation steps, thereby ensuring the ergodicity guarantees extend to the reported high-dimensional regimes. revision: yes
-
Referee: The reflection-matrix construction is claimed to preserve necessary correlation structure, yet no quantitative bound is given on the approximation error relative to the full eigen-decomposition of the estimated covariance. A short derivation or numerical diagnostic showing the Frobenius or operator-norm error as a function of m would strengthen the complexity claim.
Authors: The referee is correct that we have not supplied a quantitative error analysis. The product of m reflection matrices exactly recovers the full orthogonal transformation when m equals the number of retained components, but for smaller m it yields an approximation. In the revision we will add a numerical diagnostic (in the preconditioner section or an appendix) that plots the Frobenius-norm error between the m-reflection preconditioner and the full eigen-decomposition, evaluated on the covariance structures arising in our experiments. This will quantify the accuracy-complexity trade-off and support the choice of m. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes a novel adaptive MCMC preconditioner parametrized via a diagonal matrix and reflection matrices, with eigeninformation obtained from online PCA on the running chain, and validates its performance claims through direct numerical comparisons on test distributions. No derivation chain reduces any result to its own inputs by construction, no fitted quantities are relabeled as independent predictions, and the single self-citation (to prior work on diagonal preconditioner limitations) serves only as background motivation rather than load-bearing justification for the central empirical result. The method is self-contained against external benchmarks via the reported experiments.
Axiom & Free-Parameter Ledger
free parameters (1)
- m
axioms (1)
- domain assumption The target distribution admits a covariance structure that can be approximated online from MCMC samples without destabilizing the chain.
Forward citations
Cited by 1 Pith paper
-
Adaptive Riemannian Manifold Hamiltonian Monte Carlo with Hierarchical Metric
An adaptive hierarchical RMHMC sampler with closed-form leapfrog integrator and automatic mass matrix tuning for efficient MCMC in high-dimensional Bayesian problems.
Reference graph
Works this paper leans on
-
[1]
Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng
Mart \'i n Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow : A system for ...
2016
-
[2]
Agliari and C
A. Agliari and C. Calvi Parisetti. A-g Reference Informative Prior : A Note on Zellner 's g Prior . Journal of the Royal Statistical Society. Series D (The Statistician), 37 0 (3): 0 271--275, 1988
1988
-
[3]
A tutorial on adaptive MCMC
Christophe Andrieu and Johannes Thoms. A tutorial on adaptive MCMC . Statistics and Computing, 18 0 (4): 0 343--373, December 2008. ISSN 1573-1375
2008
-
[4]
Christophe Andrieu, Anthony Lee, Sam Power, and Andi Q. Wang. Explicit convergence bounds for Metropolis Markov chains: Isoperimetry , spectral gaps and profiles. The Annals of Applied Probability, 34 0 (4): 0 4022--4071, August 2024
2024
-
[5]
Optimal tuning of the hybrid Monte Carlo algorithm
Alexandros Beskos, Natesh Pillai, Gareth Roberts, Jesus-Maria Sanz-Serna , and Andrew Stuart. Optimal tuning of the hybrid Monte Carlo algorithm. Bernoulli, 19 0 (5A): 0 1501--1534, 2013
2013
-
[6]
Online Principal Component Analysis in High Dimension : Which Algorithm to Choose ? International Statistical Review, 86 0 (1): 0 29--50, 2018
Herv \'e Cardot and David Degras. Online Principal Component Analysis in High Dimension : Which Algorithm to Choose ? International Statistical Review, 86 0 (1): 0 29--50, 2018. ISSN 1751-5823
2018
-
[7]
Hoffman, Daniel Lee, Ben Goodrich, Michael Betancourt, Marcus Brubaker, Jiqiang Guo, Peter Li, and Allen Riddell
Bob Carpenter, Andrew Gelman, Matthew D. Hoffman, Daniel Lee, Ben Goodrich, Michael Betancourt, Marcus Brubaker, Jiqiang Guo, Peter Li, and Allen Riddell. Stan: A Probabilistic Programming Language . Journal of Statistical Software, 76: 0 1--32, January 2017. ISSN 1548-7660
2017
-
[8]
Dimensionality Reduction for Stationary Time Series via Stochastic Nonconvex Optimization , October 2018
Minshuo Chen, Lin Yang, Mengdi Wang, and Tuo Zhao. Dimensionality Reduction for Stationary Time Series via Stochastic Nonconvex Optimization , October 2018
2018
-
[9]
An Adaptive Metropolis Algorithm
Heikki Haario, Eero Saksman, and Johanna Tamminen. An Adaptive Metropolis Algorithm . Bernoulli, 7 0 (2): 0 223--242, 2001. ISSN 1350-7265
2001
-
[10]
Quantifying the Effectiveness of Linear Preconditioning in Markov Chain Monte Carlo
Max Hird and Samuel Livingstone. Quantifying the Effectiveness of Linear Preconditioning in Markov Chain Monte Carlo . Journal of Machine Learning Research, 26 0 (119): 0 1--51, 2025
2025
-
[11]
Critical behavior of mean-field XY and related models, November 2016
Kay Kirkpatrick and Tayyab Nawaz. Critical behavior of mean-field XY and related models, November 2016
2016
-
[12]
Streaming PCA for Markovian Data , June 2023
Syamantak Kumar and Purnamrita Sarkar. Streaming PCA for Markovian Data , June 2023
2023
-
[13]
The Barker proposal: Combining robustness and efficiency in gradient-based MCMC
Samuel Livingstone and Giacomo Zanella. The Barker proposal: Combining robustness and efficiency in gradient-based MCMC . Journal of the Royal Statistical Society Series B: Statistical Methodology, 84 0 (2): 0 496--523, 2022
2022
-
[14]
Chirag Modi, Diana Cai, and Lawrence K. Saul. Batch, match, and patch: Low-rank approximations for score-based variational inference. In Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , pages 4510--4518. PMLR, April 2025
2025
-
[15]
Subspace methods of pattern recognition
Erkki Oja. Subspace methods of pattern recognition. In Signal Processing , volume 7, page 79, September 1984
1984
-
[16]
A. M. Ostrowski. A quantitative formulation of sylvester's law of inertia*. Proceedings of the National Academy of Sciences, 45 0 (5): 0 740--744, May 1959
1959
-
[17]
Coda: Output Analysis and Diagnostics for MCMC , 2024
Martyn Plummer, Nicky Best, Kate Cowles, Karen Vines, Deepayan Sarkar, Douglas Bates, Russell Almond, and Arni Magnusson coda author details . Coda: Output Analysis and Diagnostics for MCMC , 2024
2024
-
[18]
Adaptive Tuning for Metropolis Adjusted Langevin Trajectories
Lionel Riou-Durand , Pavel Sountsov, Jure Vogrinc, Charles Margossian, and Sam Power. Adaptive Tuning for Metropolis Adjusted Langevin Trajectories . In Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , pages 8102--8116. PMLR, April 2023
2023
-
[19]
G. O. Roberts, A. Gelman, and W. R. Gilks. Weak Convergence and Optimal Scaling of Random Walk Metropolis Algorithms . The Annals of Applied Probability, 7 0 (1): 0 110--120, 1997
1997
-
[20]
Roberts and Richard L
Gareth O. Roberts and Richard L. Tweedie. Exponential convergence of Langevin distributions and their discrete approximations. Bernoulli, 2 0 (4): 0 341--363, December 1996. ISSN 1350-7265
1996
-
[21]
Optimal proposal distributions and adaptive MCMC
Jeffrey S Rosenthal et al. Optimal proposal distributions and adaptive MCMC . Handbook of Markov Chain Monte Carlo, 4, 2011
2011
-
[22]
Optimal Preconditioning and Fisher Adaptive Langevin Sampling
Michalis Titsias. Optimal Preconditioning and Fisher Adaptive Langevin Sampling . Advances in Neural Information Processing Systems, 36: 0 29449--29460, December 2023
2023
-
[23]
Tuning diagonal scale matrices for HMC
Jimmy Huy Tran and Tore Selland Kleppe. Tuning diagonal scale matrices for HMC . Statistics and Computing, 34 0 (6): 0 196, October 2024. ISSN 1573-1375
2024
-
[24]
A Fast Algorithm for Incremental Principal Component Analysis
Juyang Weng, Yilu Zhang, and Wey-Shiuan Hwang. A Fast Algorithm for Incremental Principal Component Analysis . In Jiming Liu, Yiu-ming Cheung, and Hujun Yin, editors, Intelligent Data Engineering and Automated Learning , pages 876--881. Springer, 2003
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.