Recognition: unknown
Case-Grounded Evidence Verification: A Framework for Constructing Evidence-Sensitive Supervision
Pith reviewed 2026-05-10 17:09 UTC · model grok-4.3
The pith
A supervision construction method automatically creates support and non-support examples so that verifiers must depend on whether evidence backs a claim for a given case.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
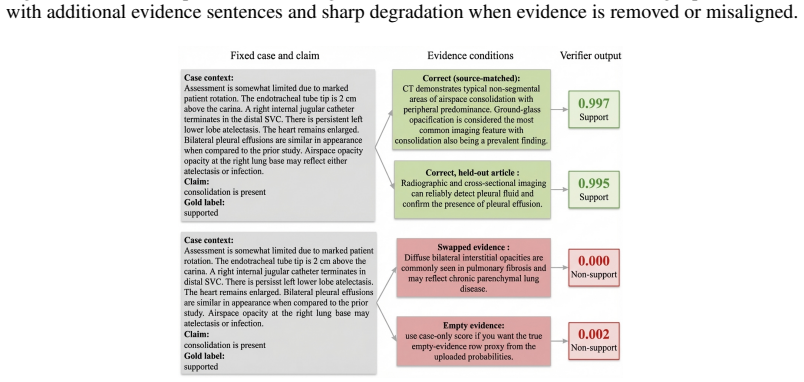
The supervision construction procedure generates explicit support examples together with semantically controlled non-support examples, including counterfactual wrong-state and topic-related negatives, without manual evidence annotation. Training a verifier on the resulting task produces models that substantially outperform case-only and evidence-only baselines, remain strong when evidence is correct, and collapse when evidence is removed or swapped, showing genuine dependence on whether the evidence supports the claim for the case.
What carries the argument
The supervision construction procedure that pairs case context with evidence and claims, then automatically produces support instances plus counterfactual wrong-state and topic-related negative instances to encode evidence dependence.
If this is right
- Verifiers can be trained to exhibit genuine evidence dependence for case-specific decisions without requiring manual support labels.
- The same construction procedure scales to produce large supervision sets for evidence-grounded reasoning in domains such as radiology.
- Trained models transfer their evidence-checking behavior to unseen evidence articles and external case distributions.
- Performance remains sensitive to shifts in the source of evidence and to the choice of underlying model backbone.
Where Pith is reading between the lines
- The same automatic negative generation approach could be applied to build supervision for evidence verification in legal or scientific reasoning tasks.
- Combining this verifier with retrieval systems might create end-to-end pipelines that both fetch and check evidence.
- The sharp drop under evidence swap offers a practical test for whether other models have truly learned to ground predictions in supplied evidence.
Load-bearing premise
The automatically generated counterfactual wrong-state and topic-related negative examples accurately represent real cases of evidence non-support without introducing exploitable artifacts or semantic mismatches that a model could learn instead of true verification.
What would settle it
Run the trained verifier on a new test set of human-annotated radiology cases that include known unsupported evidence and measure whether accuracy falls to near-chance levels comparable to the synthetic negative conditions.
Figures


read the original abstract
Evidence-grounded reasoning requires more than attaching retrieved text to a prediction: a model should make decisions that depend on whether the provided evidence supports the target claim. In practice, this often fails because supervision is weak, evidence is only loosely tied to the claim, and evaluation does not test evidence dependence directly. We introduce case-grounded evidence verification, a general framework in which a model receives a local case context, external evidence, and a structured claim, and must decide whether the evidence supports the claim for that case. Our key contribution is a supervision construction procedure that generates explicit support examples together with semantically controlled non-support examples, including counterfactual wrong-state and topic-related negatives, without manual evidence annotation. We instantiate the framework in radiology and train a standard verifier on the resulting support task. The learned verifier substantially outperforms both case-only and evidence-only baselines, remains strong under correct evidence, and collapses when evidence is removed or swapped, indicating genuine evidence dependence. This behavior transfers across unseen evidence articles and an external case distribution, though performance degrades under evidence-source shift and remains sensitive to backbone choice. Overall, the results suggest that a major bottleneck in evidence grounding is not only model capacity, but the lack of supervision that encodes the causal role of evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces case-grounded evidence verification, a framework where a model receives local case context, external evidence, and a structured claim, and decides if the evidence supports the claim. The key contribution is an automatic supervision construction procedure that generates explicit support examples along with semantically controlled non-support examples (counterfactual wrong-state and topic-related negatives) without manual annotation. Instantiated in radiology, the trained verifier outperforms case-only and evidence-only baselines, remains strong with correct evidence, and collapses under evidence removal or swap, which the authors interpret as genuine evidence dependence; this transfers across unseen articles but degrades under source shift and is backbone-sensitive.
Significance. If the synthetic non-support examples faithfully isolate the causal support relation without artifacts, the work offers a scalable route to evidence-sensitive supervision that directly addresses a core bottleneck in evidence-grounded reasoning. The explicit tests of dependence via evidence removal and swap constitute a falsifiable empirical strength that goes beyond standard accuracy metrics. The approach could improve reliability in high-stakes domains such as medical reasoning, provided the supervision quality holds.
major comments (3)
- [§3] §3 (Supervision Construction): The operational details for defining and generating 'counterfactual wrong-state' negatives in the radiology domain—specifically how wrong-states are identified while preserving case context and avoiding semantic drift—are not provided. This is load-bearing for the central claim, as the observed outperformance and collapse behavior could reflect exploitation of generation artifacts rather than learned verification logic.
- [§4] §4 (Experiments): No dataset sizes, statistical significance tests for the reported performance gains over baselines, or exact implementation details for the case-only and evidence-only baselines are supplied. Without these, it is impossible to assess whether the gains are robust or potentially confounded by differences in training data volume or baseline construction.
- [§4.3] §4.3 (Evidence Sensitivity): The claim of genuine evidence dependence rests on the collapse when evidence is removed or swapped, yet no additional controls (e.g., human validation of negatives or detection of systematic patterns in the synthetic examples) are described to rule out the model learning spurious cues from the negative generation process instead of the support relation.
minor comments (2)
- [§3] The notation for the verifier input tuple (case context, evidence, claim) could be formalized more clearly, perhaps with an explicit equation, to aid reproducibility.
- [§4] Figure captions and axis labels in the evidence-sensitivity plots would benefit from explicit mention of the exact swap and removal conditions tested.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas for improving clarity in the supervision construction and experimental reporting, which we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (Supervision Construction): The operational details for defining and generating 'counterfactual wrong-state' negatives in the radiology domain—specifically how wrong-states are identified while preserving case context and avoiding semantic drift—are not provided. This is load-bearing for the central claim, as the observed outperformance and collapse behavior could reflect exploitation of generation artifacts rather than learned verification logic.
Authors: We agree that expanding the operational details in §3 is necessary for transparency. In the revised manuscript, we will add a dedicated subsection describing the counterfactual wrong-state generation: wrong-states are derived from a predefined set of radiology-specific state transitions (e.g., presence/absence of findings like effusion or consolidation, drawn from clinical literature on common diagnostic alternatives) applied only to the claim-relevant portions of the case. Case context is preserved by leaving all unrelated findings and history unchanged, and semantic drift is controlled via template-based edits followed by automatic consistency checks against the original case text. These additions will clarify that the negatives isolate the support relation without introducing exploitable artifacts. revision: yes
-
Referee: [§4] §4 (Experiments): No dataset sizes, statistical significance tests for the reported performance gains over baselines, or exact implementation details for the case-only and evidence-only baselines are supplied. Without these, it is impossible to assess whether the gains are robust or potentially confounded by differences in training data volume or baseline construction.
Authors: We accept that these details are required for reproducibility and robustness assessment. The revised version will report exact dataset sizes (e.g., counts of support examples and each negative type in train/dev/test splits), include statistical significance tests (paired bootstrap or McNemar's test with p-values for gains over baselines), and specify baseline implementations: case-only receives the structured claim plus full case context; evidence-only receives the claim plus evidence text; both use identical training regimes, data volumes, and hyperparameters as the full model. revision: yes
-
Referee: [§4.3] §4.3 (Evidence Sensitivity): The claim of genuine evidence dependence rests on the collapse when evidence is removed or swapped, yet no additional controls (e.g., human validation of negatives or detection of systematic patterns in the synthetic examples) are described to rule out the model learning spurious cues from the negative generation process instead of the support relation.
Authors: The referee correctly notes that the dependence tests would be strengthened by ruling out generation artifacts. We will add to §4.3 a human validation experiment on a random sample of 200 synthetic negatives (with inter-annotator agreement) confirming they do not support the claims, plus an analysis checking for systematic lexical or structural cues in the negatives. The existing removal/swap results already provide falsifiable evidence of dependence, but these controls will further address the concern. This constitutes a partial revision as the core experiments remain unchanged. revision: partial
Circularity Check
No significant circularity in empirical supervision framework
full rationale
The paper presents a data-construction procedure for generating support and non-support examples (including counterfactual wrong-state and topic-related negatives) for training an evidence verifier, followed by empirical training and evaluation against baselines plus ablation tests on evidence removal/swap. No equations, fitted parameters, or derivations are described that reduce any claimed prediction or result to the inputs by construction. The central claims rest on measurable performance differences in held-out testing and transfer settings, which are independent of any self-referential definitions or self-citation chains. The method is self-contained and externally falsifiable via the described generation rules and model behavior.
Axiom & Free-Parameter Ledger
free parameters (1)
- verifier model hyperparameters
axioms (1)
- domain assumption Generated counterfactual and topic-related negatives faithfully represent evidence non-support without introducing model-exploitable shortcuts.
Reference graph
Works this paper leans on
-
[1]
A diagnostic study of explainability techniques for text classification
Pepa Atanasova, Jakob Grue Simonsen, Christina Lioma, and Isabelle Augenstein. A diagnostic study of explainability techniques for text classification. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3256–3274, 2020. URL https://aclanthology.org/2020.emnlp-main.263/
2020
-
[2]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[3]
Bowman, Gabor Angeli, Christopher Potts, and Christopher D
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. A large an- notated corpus for learning natural language inference. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 632–642, September 2015. URL https: //aclanthology.org/D15-1075/
2015
-
[4]
Kay Henning Brodersen, Cheng Soon Ong, Klaas Enno Stephan, and Joachim M. Buhmann. The balanced accuracy and its posterior distribution. In2010 20th International Conference on Pattern Recognition, pages 3121–3124, 2010. doi: 10.1109/ICPR.2010.764
-
[5]
From large language models to multimodal ai: a scoping review on the potential of generative ai in medicine
Lukas Buess, Matthias Keicher, Nassir Navab, Andreas Maier, and Soroosh Tayebi Arasteh. From large language models to multimodal ai: a scoping review on the potential of generative ai in medicine. Biomedical Engineering Letters, 15(5):845–863, 2025
2025
-
[6]
e-snli: natural language inference with natural language explanations
Oana-Maria Camburu, Tim Rocktäschel, Thomas Lukasiewicz, and Phil Blunsom. e-snli: natural language inference with natural language explanations. InProceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, page 9560–9572, Red Hook, NY , USA, 2018
2018
-
[7]
Pierre Chambon, Jean-Benoit Delbrouck, Thomas Sounack, Shih-Cheng Huang, Zhihong Chen, Maya Varma, Steven QH Truong, Chu The Chuong, and Curtis P Langlotz. Chexpert plus: Augmenting a large chest x-ray dataset with text radiology reports, patient demographics and additional image formats.arXiv preprint arXiv:2405.19538, 2024
-
[8]
Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tai, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
2024
-
[9]
ELECTRA: Pre-training text encoders as discriminators rather than generators
Kevin Clark, Minh-Thang Luong, Quoc V Le, and Christopher D Manning. Electra: Pre-training text encoders as discriminators rather than generators.arXiv preprint arXiv:2003.10555, 2020
-
[10]
arXiv preprint arXiv:2205.09712 , year=
Antonia Creswell, Murray Shanahan, and Irina Higgins. Selection-inference: Exploiting large language models for interpretable logical reasoning.arXiv preprint arXiv:2205.09712, 2022
-
[11]
The pascal recognising textual entailment challenge
Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. InMachine learning challenges workshop, pages 177–190. Springer, 2005
2005
-
[12]
The relationship between precision-recall and ROC curves,
Jesse Davis and Mark Goadrich. The relationship between precision-recall and roc curves. InProceedings of the 23rd International Conference on Machine Learning, page 233–240, New York, NY , USA, 2006. Association for Computing Machinery. URLhttps://doi.org/10.1145/1143844.1143874
-
[13]
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C. Wallace. ERASER: A benchmark to evaluate rationalized NLP models. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4443–4458, 2020. URL https://aclanthology.org/2020.acl-main.408/
2020
-
[14]
Bootstrap methods: another look at the jackknife
Bradley Efron. Bootstrap methods: another look at the jackknife. InBreakthroughs in statistics: Methodol- ogy and distribution, pages 569–593. Springer, 1992
1992
-
[15]
Chapman and Hall/CRC, 1994
Bradley Efron and Robert J Tibshirani.An introduction to the bootstrap. Chapman and Hall/CRC, 1994
1994
-
[16]
On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(53):1605–1641, 2010
Ran El-Yaniv and Yair Wiener. On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(53):1605–1641, 2010. URL http://jmlr.org/papers/v11/el-yaniv10a. html
2010
-
[17]
Mina Farajiamiri, Jeta Sopa, Saba Afza, Lisa Adams, Felix Barajas Ordonez, Tri-Thien Nguyen, Mahshad Lotfinia, Sebastian Wind, Keno Bressem, Sven Nebelung, Daniel Truhn, and Soroosh Tayebi Arasteh. Agentic retrieval-augmented reasoning reshapes collective reliability under model variability in radiology question answering, 2026. URLhttps://arxiv.org/abs/2...
-
[18]
Radiopaedia: building an online radiology resource
F Gaillard et al. Radiopaedia: building an online radiology resource. European Congress of Radiology- RANZCR ASM 2011, 2011
2011
-
[19]
Liu, Phoebe Mulcaire, Qiang Ning, Sameer Singh, Noah A
Matt Gardner, Yoav Artzi, Victoria Basmov, Jonathan Berant, Ben Bogin, Sihao Chen, Pradeep Dasigi, Dheeru Dua, Yanai Elazar, Ananth Gottumukkala, Nitish Gupta, Hannaneh Hajishirzi, Gabriel Ilharco, Daniel Khashabi, Kevin Lin, Jiangming Liu, Nelson F. Liu, Phoebe Mulcaire, Qiang Ning, Sameer Singh, Noah A. Smith, Sanjay Subramanian, Reut Tsarfaty, Eric Wal...
2020
-
[20]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. NIPS’17, page 4885–4894, Red Hook, NY , USA, 2017. Curran Associates Inc
2017
-
[21]
Verification of forecasts expressed in terms of probability.Monthly weather review, 78(1):1–3, 1950
W Brier Glenn et al. Verification of forecasts expressed in terms of probability.Monthly weather review, 78(1):1–3, 1950
1950
-
[22]
Strictly proper scoring rules, prediction, and estimation.Journal of the American statistical Association, 102(477):359–378, 2007
Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation.Journal of the American statistical Association, 102(477):359–378, 2007
2007
-
[23]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InProceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, page 1321–1330, 2017
2017
-
[24]
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel Bowman, and Noah A. Smith. Annotation artifacts in natural language inference data. In Marilyn Walker, Heng Ji, and Amanda Stent, editors,Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volu...
2018
-
[25]
Retrieval augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. InInternational conference on machine learning, pages 3929–3938. PMLR, 2020
2020
-
[26]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[27]
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, Jayne Seekins, David A. Mong, Safwan S. Halabi, Jesse K. Sandberg, Ricky Jones, David B. Larson, Curtis P. Langlotz, Bhavik N. Patel, Matthew P. Lungren, and Andrew Y . Ng. Chexpert: a large chest radiogr...
-
[28]
Leveraging passage retrieval with generative models for open domain question answering
Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880, 2021. URL https://aclanthology.org/ 2021.eacl-main.74/
2021
-
[29]
Alon Jacovi and Yoav Goldberg. Towards faithfully interpretable nlp systems: How should we define and evaluate faithfulness? InProceedings of the 58th annual meeting of the association for computational linguistics, pages 4198–4205, 2020
2020
-
[30]
Sarthak Jain and Byron C. Wallace. Attention is not Explanation. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3543–3556, Minneapolis, Minnesota, 2019. Association for Computational Linguistics. URLhttps://aclantholog...
2019
-
[31]
Sarthak Jain, Sarah Wiegreffe, Yuval Pinter, and Byron C. Wallace. Learning to faithfully rationalize by construction. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4459–4473, Online, 2020. URLhttps://aclanthology.org/2020.acl-main.409/
2020
-
[32]
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019. 11
2019
-
[33]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781,
2020
-
[34]
URLhttps://aclanthology.org/2020.emnlp-main.550/
2020
-
[35]
Divyansh Kaushik, Eduard Hovy, and Zachary C Lipton. Learning the difference that makes a difference with counterfactually-augmented data.arXiv preprint arXiv:1909.12434, 2019
-
[36]
Rationalizing neural predictions
Tao Lei, Regina Barzilay, and Tommi Jaakkola. Rationalizing neural predictions. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 107–117. Association for Computational Linguistics, 2016. URLhttps://aclanthology.org/D16-1011/
2016
-
[37]
Retrieval- augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval- augmented generation for knowledge-intensive nlp tasks. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’2...
2020
-
[38]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[39]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[40]
Thomas McCoy, Ellie Pavlick, and Tal Linzen
R. Thomas McCoy, Ellie Pavlick, and Tal Linzen. Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference. In Anna Korhonen, David Traum, and Lluís Màrquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3428– 3448, Florence, Italy, 2019. URLhttps://aclanthology.org/...
2019
-
[41]
Distant supervision for relation extraction without labeled data
Mike Mintz, Steven Bills, Rion Snow, and Daniel Jurafsky. Distant supervision for relation extraction without labeled data. In Keh-Yih Su, Jian Su, Janyce Wiebe, and Haizhou Li, editors,Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, pages 100...
2009
-
[42]
Differential privacy for medical deep learning: methods, tradeoffs, and deployment implications.npj Digital Medicine, 9:93, 2026
Marziyeh Mohammadi, Mohsen Vejdanihemmat, Mahshad Lotfinia, Mirabela Rusu, Daniel Truhn, Andreas Maier, and Soroosh Tayebi Arasteh. Differential privacy for medical deep learning: methods, tradeoffs, and deployment implications.npj Digital Medicine, 9:93, 2026
2026
-
[43]
Longllada: Unlocking long context capabilities in diffusion llms
Yixin Nie, Haonan Chen, and Mohit Bansal. Combining fact extraction and verification with neural semantic matching networks. InProceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence,...
-
[44]
A corpus with multi-level annotations of patients, interventions and outcomes to support language processing for medical literature
Benjamin Nye, Junyi Jessy Li, Roma Patel, Yinfei Yang, Iain Marshall, Ani Nenkova, and Byron Wallace. A corpus with multi-level annotations of patients, interventions and outcomes to support language processing for medical literature. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1...
2018
-
[45]
Cambridge University Press, USA, 2nd edition,
Judea Pearl.Causality: Models, Reasoning and Inference. Cambridge University Press, USA, 2nd edition,
-
[46]
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.Advances in large margin classifiers, 10(3):61–74, 1999
John Platt et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.Advances in large margin classifiers, 10(3):61–74, 1999
1999
-
[47]
RocketQA: An optimized training approach to dense passage retrieval for open- domain question answering
Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu, and Haifeng Wang. RocketQA: An optimized training approach to dense passage retrieval for open- domain question answering. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo...
2021
-
[48]
Data programming: creating large training sets, quickly
Alexander Ratner, Christopher De Sa, Sen Wu, Daniel Selsam, and Christopher Ré. Data programming: creating large training sets, quickly. InProceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, page 3574–3582, Red Hook, NY , USA, 2016. Curran Associates Inc. ISBN 9781510838819. 12
2016
-
[49]
Available: http://dx.doi.org/10.14778/3157794.3157797
Alexander Ratner, Stephen H. Bach, Henry Ehrenberg, Jason Fries, Sen Wu, and Christopher Ré. Snorkel: rapid training data creation with weak supervision.Proc. VLDB Endow., 11(3):269–282, November 2017. ISSN 2150-8097. URLhttps://doi.org/10.14778/3157794.3157797
-
[50]
The precision-recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets.PloS one, 10(3):e0118432, 2015
Takaya Saito and Marc Rehmsmeier. The precision-recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets.PloS one, 10(3):e0118432, 2015
2015
-
[51]
Sofia Serrano and Noah A. Smith. Is attention interpretable? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2931–2951. Association for Computational Linguistics, 2019. URLhttps://aclanthology.org/P19-1282/
2019
-
[52]
Toward expert-level medical question answering with large language models.Nature medicine, 31(3):943–950, 2025
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al. Toward expert-level medical question answering with large language models.Nature medicine, 31(3):943–950, 2025
2025
-
[53]
Measuring the accuracy of diagnostic systems.Science, 240(4857):1285–1293, 1988
John A Swets. Measuring the accuracy of diagnostic systems.Science, 240(4857):1285–1293, 1988
1988
-
[54]
Large language models streamline automated machine learning for clinical studies.Nature Communications, 15(1):1603, 2024
Soroosh Tayebi Arasteh, Tianyu Han, Mahshad Lotfinia, Christiane Kuhl, Jakob Nikolas Kather, Daniel Truhn, and Sven Nebelung. Large language models streamline automated machine learning for clinical studies.Nature Communications, 15(1):1603, 2024
2024
-
[55]
The treasure trove hidden in plain sight: The utility of gpt-4 in chest radiograph evaluation.Radiology, 313(2):e233441, 2024
Soroosh Tayebi Arasteh, Robert Siepmann, Marc Huppertz, Mahshad Lotfinia, Behrus Puladi, Christiane Kuhl, Daniel Truhn, and Sven Nebelung. The treasure trove hidden in plain sight: The utility of gpt-4 in chest radiograph evaluation.Radiology, 313(2):e233441, 2024
2024
-
[56]
Preserving fairness and diagnostic accuracy in private large-scale ai models for medical imaging.Communications Medicine, 4(1):46, 2024
Soroosh Tayebi Arasteh, Alexander Ziller, Christiane Kuhl, Marcus Makowski, Sven Nebelung, Rickmer Braren, Daniel Rueckert, Daniel Truhn, and Georgios Kaissis. Preserving fairness and diagnostic accuracy in private large-scale ai models for medical imaging.Communications Medicine, 4(1):46, 2024
2024
-
[57]
Radiorag: online retrieval– augmented generation for radiology question answering.Radiology: Artificial Intelligence, 7(4):e240476, 2025
Soroosh Tayebi Arasteh, Mahshad Lotfinia, Keno Bressem, Robert Siepmann, Lisa Adams, Dyke Ferber, Christiane Kuhl, Jakob Nikolas Kather, Sven Nebelung, and Daniel Truhn. Radiorag: online retrieval– augmented generation for radiology question answering.Radiology: Artificial Intelligence, 7(4):e240476, 2025
2025
-
[58]
FEVER: a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for fact extraction and VERification. In Marilyn Walker, Heng Ji, and Amanda Stent, editors,Pro- ceedings of the 2018 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, Volume 1 (...
2018
-
[59]
URLhttps://aclanthology.org/N18-1074/
Association for Computational Linguistics. URLhttps://aclanthology.org/N18-1074/
-
[60]
An introduction to the bootstrap.Monographs on statistics and applied probability, 57(1):1–436, 1993
Robert J Tibshirani and Bradley Efron. An introduction to the bootstrap.Monographs on statistics and applied probability, 57(1):1–436, 1993
1993
-
[61]
Fact or fiction: Verifying scientific claims
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. Fact or fiction: Verifying scientific claims. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7534–7550, 2020. URL https: //aclanthology.org/2020.emnlp-main.609/
2020
-
[62]
Irgan: A minimax game for unifying generative and discriminative information retrieval models
Jun Wang, Lantao Yu, Weinan Zhang, Yu Gong, Yinghui Xu, Benyou Wang, Peng Zhang, and Dell Zhang. Irgan: A minimax game for unifying generative and discriminative information retrieval models. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’17, page 515–524, New York, NY , USA, 2017...
-
[63]
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Griffin Thomas Adams, Jeremy Howard, and Iacopo Poli. Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. InProceedi...
-
[64]
Attention is not not explanation
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 11–20. Association for Computational Linguistics,
2019
-
[65]
URLhttps://aclanthology.org/D19-1002/. 13
-
[66]
A broad-coverage challenge corpus for sentence understanding through inference
Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122. Association for Computational Linguistic...
2018
-
[67]
Multi-step retrieval and reasoning improves radiology question answering with large language models.npj Digital Medicine, 8:790, 2025
Sebastian Wind, Jeta Sopa, Daniel Truhn, Mahshad Lotfinia, Tri-Thien Nguyen, Keno Bressem, Lisa Adams, Mirabela Rusu, Harald Köstler, Gerhard Wellein, et al. Multi-step retrieval and reasoning improves radiology question answering with large language models.npj Digital Medicine, 8:790, 2025
2025
-
[68]
End-to-end neural ad- hoc ranking with kernel pooling
Chenyan Xiong, Zhuyun Dai, Jamie Callan, Zhiyuan Liu, and Russell Power. End-to-end neural ad- hoc ranking with kernel pooling. InProceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’17, page 55–64, New York, NY , USA, 2017. Association for Computing Machinery. ISBN 9781450350228. URL http...
-
[69]
Index for rating diagnostic tests.Cancer, 3(1):32–35, 1950
William J Youden. Index for rating diagnostic tests.Cancer, 3(1):32–35, 1950
1950
-
[70]
Transforming classifier scores into accurate multiclass probability estimates
Bianca Zadrozny and Charles Elkan. Transforming classifier scores into accurate multiclass probability estimates. InProceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 694–699, 2002
2002
-
[71]
Cyril Zakka, Rohan Shad, Akash Chaurasia, Alex R. Dalal, Jennifer L. Kim, Michael Moor, Robyn Fong, Curran Phillips, Kevin Alexander, Euan Ashley, Jack Boyd, Kathleen Boyd, Karen Hirsch, Curt Langlotz, Rita Lee, Joanna Melia, Joanna Nelson, Karim Sallam, Stacey Tullis, Melissa Ann V ogelsong, John Patrick Cunningham, and William Hiesinger. Almanac — retri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.