Recognition: no theorem link
Characterizing Performance-Energy Trade-offs of Large Language Models in Multi-Request Workflows
Pith reviewed 2026-05-15 12:25 UTC · model grok-4.3
The pith
Batch size is the strongest lever for trading off latency and energy in multi-request LLM workflows, but only when the workload shares large prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
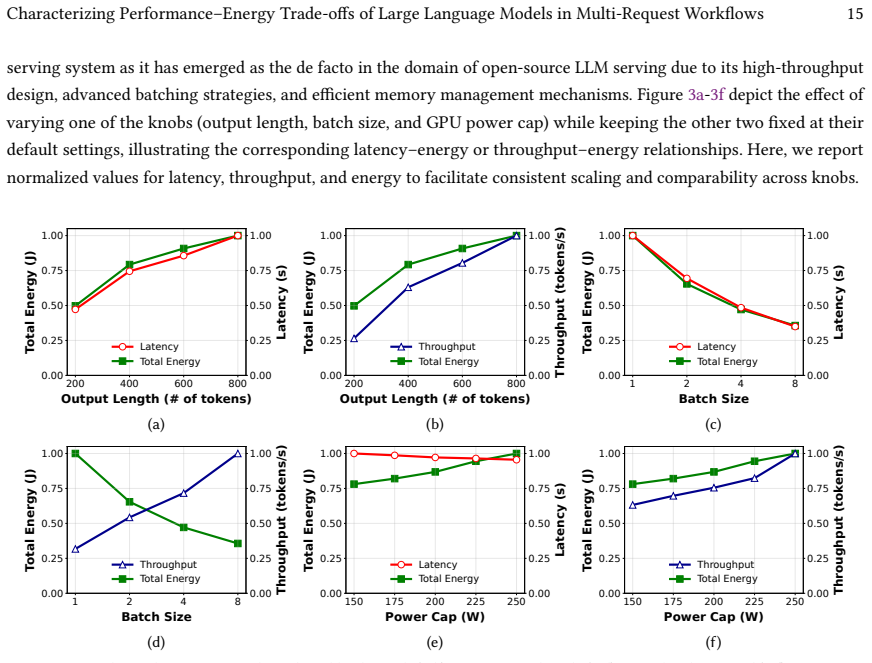
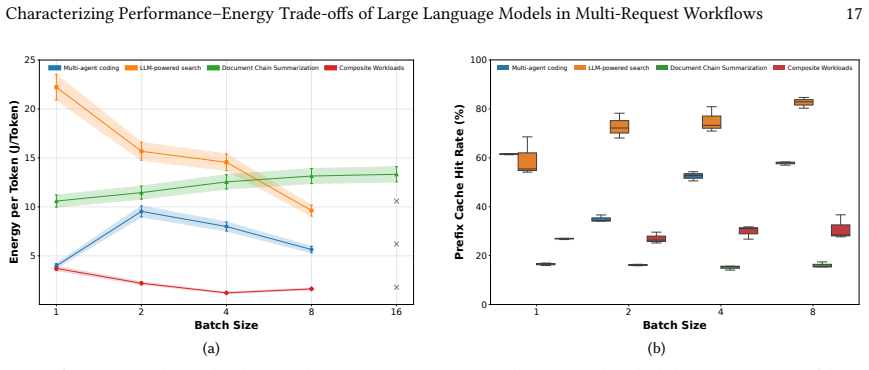
We present the first systematic characterization of performance-energy trade-offs in multi-request LLM inference. Four workloads capture sequential, interactive, agentic, and composite patterns. On an NVIDIA A100 with vLLM and Parrot, batch size emerges as the dominant knob, yet its benefits are workload-dependent: it improves efficiency for tasks with large shared prompts, shows no gain for sequential summarization, and gives only partial improvement for multi-agent coding. GPU power capping delivers modest but consistent savings, output length produces linear energy growth with little efficiency upside, vLLM sustains higher utilization on decode-heavy work, and Parrot's workflow-aware调度trt
What carries the argument
Four representative workloads together with the three energy-control knobs (batch size, GPU power cap, output length) measured across vLLM and Parrot serving engines.
If this is right
- Workloads whose requests share long common prefixes can cut both energy and latency by raising batch size without extra hardware.
- Sequential summarization pipelines gain almost nothing from batch-size tuning and must rely on other levers such as power capping.
- GPU power capping gives modest, predictable energy reductions that scale across all four workload types.
- vLLM-style continuous batching keeps GPU utilization high when decode phases dominate, improving energy per token.
- Parrot-style workflow-aware scheduling lowers total energy when the system is forced to run under a tight power budget.
Where Pith is reading between the lines
- Production serving systems could add lightweight prompt-sharing detectors so they can raise batch size only when the workload will actually benefit.
- Similar characterization studies on other accelerators or at the edge would reveal whether the same workload-dependent pattern holds outside the A100 and vLLM/Parrot pair.
- Workflow schedulers that already track request dependencies could be extended to choose serving engines or power caps on a per-workflow basis rather than globally.
Load-bearing premise
The four chosen workloads are representative of the sequential, interactive, agentic, and composite patterns that actually occur in production multi-request LLM deployments.
What would settle it
Re-running the exact same measurement suite on a fresh set of workloads whose prompt-sharing statistics or interaction structure differ markedly from the original four and finding that batch size no longer produces the largest changes in energy or latency.
Figures




read the original abstract
Large language models (LLMs) are increasingly used in applications forming multi-request workflows like document summarization, search-based copilots, and multi-agent programming. While these workflows unlock richer functionality, they also amplify latency and energy demand during inference. Existing measurement and benchmarking efforts either focus on assessing LLM inference systems or consider single-request evaluations, overlooking workflow dependencies and cross-request interactions unique to multi-request workflows. Moreover, the energy usage of such interdependent LLM calls remains underexplored. To address these gaps, this paper presents the first systematic characterization of performance-energy trade-offs in multi-request LLM inference. We develop four representative workloads capturing sequential, interactive, agentic, and composite patterns common in modern deployments. Using an NVIDIA A100 testbed with state-of-the-art serving systems (vLLM and Parrot), we analyze how key energy knobs affect latency, throughput, and component-level energy use. Our findings reveal batch size as the most impactful lever, though benefits are workload dependent. While optimal batching benefits workloads with large shared prompts, it is ineffective for sequential summarization and only partially effective for multi-agent coding. GPU power capping provides modest but predictable savings, while output length induces linear energy scaling with limited efficiency gains. We further show that engine-level optimizations in vLLM maintain higher GPU utilization and efficiency, especially for decode-heavy workloads, while Parrot's workflow-aware scheduling achieves lower energy consumption under strict power constraints. These findings offer actionable guidelines for developers and system operators designing performance- and energy-aware LLM serving systems in emerging multi-request workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systematic empirical characterization of performance-energy trade-offs in multi-request LLM inference workflows. It introduces four synthetic workloads (sequential summarization, interactive, agentic coding, and composite) evaluated on an NVIDIA A100 testbed with vLLM and Parrot serving systems, reporting that batch size is the dominant optimization lever with workload-dependent benefits, GPU power capping yields modest predictable savings, output length drives linear energy scaling, and engine-specific optimizations affect utilization and efficiency differently under power constraints.
Significance. If the workload representativeness and measurement rigor hold, the work is significant for filling the gap between single-request LLM benchmarks and real multi-request deployments; the concrete identification of batch size as the primary lever and the engine comparisons provide actionable guidelines for energy-aware serving system design in applications like multi-agent systems.
major comments (2)
- [Workload Definition] Workload Definition: The four workloads are asserted to capture 'sequential, interactive, agentic, and composite patterns common in modern deployments,' yet the manuscript supplies no quantitative validation (e.g., prompt-sharing statistics, request-graph metrics, or output-length distributions) against production traces. This assumption is load-bearing for the headline claim that 'optimal batching benefits workloads with large shared prompts' while being 'ineffective for sequential summarization' and 'only partially effective for multi-agent coding.'
- [Results and Evaluation] Results and Evaluation: Directional findings on batch-size impact and workload dependence are reported without error bars, number of repetitions, statistical significance tests, or raw-data release. The absence of these elements makes it impossible to assess whether observed differences (e.g., 'ineffective for sequential summarization') exceed measurement noise, weakening the reliability of the performance-energy trade-off conclusions.
minor comments (1)
- [Abstract] The abstract and introduction could more precisely define the energy measurement methodology (e.g., which GPU components are instrumented and the sampling interval) to allow readers to judge the component-level claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps improve the clarity and rigor of our work. We address each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Workload Definition] Workload Definition: The four workloads are asserted to capture 'sequential, interactive, agentic, and composite patterns common in modern deployments,' yet the manuscript supplies no quantitative validation (e.g., prompt-sharing statistics, request-graph metrics, or output-length distributions) against production traces. This assumption is load-bearing for the headline claim that 'optimal batching benefits workloads with large shared prompts' while being 'ineffective for sequential summarization' and 'only partially effective for multi-agent coding.'
Authors: We acknowledge that the workloads are synthetic and that we lack access to proprietary production traces for direct quantitative validation. The workload parameters were derived from patterns and statistics reported in the open literature on multi-agent LLM systems and serving workloads. In the revised manuscript, we will expand Section 3 to include explicit citations to these sources, provide a table comparing our chosen parameters (e.g., prompt-sharing ratios, output-length distributions) to published values, and add a limitations paragraph stating that the results illustrate trade-offs under representative conditions rather than claiming exact replication of any specific production deployment. This addresses the concern while preserving the core contribution. revision: partial
-
Referee: [Results and Evaluation] Results and Evaluation: Directional findings on batch-size impact and workload dependence are reported without error bars, number of repetitions, statistical significance tests, or raw-data release. The absence of these elements makes it impossible to assess whether observed differences (e.g., 'ineffective for sequential summarization') exceed measurement noise, weakening the reliability of the performance-energy trade-off conclusions.
Authors: We agree that statistical rigor should be strengthened. Each configuration was executed five times; we will report this number, add error bars (standard deviation) to all figures, include t-test results for the key workload-dependent differences highlighted in the text, and release the raw measurement data via a public repository (with a DOI link added to the camera-ready version). These changes will allow readers to evaluate whether the reported differences exceed measurement variability. revision: yes
Circularity Check
No significant circularity: pure empirical measurement study
full rationale
The paper is a characterization study that defines four workloads explicitly as representative examples of sequential, interactive, agentic, and composite patterns, then reports direct measurements of latency, throughput, and energy on an NVIDIA A100 testbed using vLLM and Parrot. No equations, fitted parameters, predictions, or derivations appear that reduce by construction to quantities defined inside the paper. Workload definitions and findings are presented as constructed test cases and observed results rather than self-referential outputs. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present. The central claims rest on external hardware measurements and are therefore self-contained against the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four workloads are representative of common multi-request patterns in modern deployments
Reference graph
Works this paper leans on
- [1]
-
[2]
https://github.com/langchain-ai/langchain, 2025
Langchain. https://github.com/langchain-ai/langchain, 2025
work page 2025
-
[3]
https://www.llamaindex.ai/, 2025
Llamaindex - build knowledge assistants over your enterprise data. https://www.llamaindex.ai/, 2025
work page 2025
-
[4]
On evaluating performance of llm inference serving systems.arXiv preprint arXiv:2507.09019, 2025
Amey Agrawal, Nitin Kedia, Anmol Agarwal, Jayashree Mohan, Nipun Kwatra, Souvik Kundu, Ramachandran Ramjee, and Alexey Tumanov. On evaluating performance of llm inference serving systems.arXiv preprint arXiv:2507.09019, 2025
-
[5]
Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 117–134, 2024
work page 2024
-
[6]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints.arXiv preprint arXiv:2305.13245, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Llm in a flash: Efficient large language model inference with limited memory
Keivan Alizadeh, Seyed Iman Mirzadeh, Dmitry Belenko, S Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, and Mehrdad Farajtabar. Llm in a flash: Efficient large language model inference with limited memory. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12562–12584, 2024
work page 2024
- [8]
-
[9]
Mauricio Fadel Argerich and Marta Patiño-Martínez. Measuring and improving the energy efficiency of large language models inference.IEEE Access, 12:80194–80207, 2024
work page 2024
-
[10]
A programming framework for agentic ai, 2025
AutoGen. A programming framework for agentic ai, 2025
work page 2025
-
[11]
Hao Bai, Yifei Zhou, Jiayi Pan, Mert Cemri, Alane Suhr, Sergey Levine, and Aviral Kumar. Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning.Advances in Neural Information Processing Systems, 37:12461–12495, 2024
work page 2024
-
[12]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[14]
Gohar Irfan Chaudhry, Esha Choukse, Haoran Qiu, Íñigo Goiri, Rodrigo Fonseca, Adam Belay, and Ricardo Bianchini. Murakkab: Resource-efficient agentic workflow orchestration in cloud platforms.arXiv preprint arXiv:2508.18298, 2025
-
[15]
Jinyuan Chen, Jiuchen Shi, Quan Chen, and Minyi Guo. Kairos: Low-latency multi-agent serving with shared llms and excessive loads in the public cloud.arXiv preprint arXiv:2508.06948, 2025
-
[16]
Lingjiao Chen, Jared Quincy Davis, Boris Hanin, Peter Bailis, Ion Stoica, Matei A Zaharia, and James Y Zou. Are more llm calls all you need? towards the scaling properties of compound ai systems.Advances in Neural Information Processing Systems, 37:45767–45790, 2024
work page 2024
-
[17]
Llm-inference-bench: Inference benchmarking of large language models on ai accelerators
Krishna Teja Chitty-Venkata, Siddhisanket Raskar, Bharat Kale, Farah Ferdaus, Aditya Tanikanti, Ken Raffenetti, Valerie Taylor, Murali Emani, and Venkatram Vishwanath. Llm-inference-bench: Inference benchmarking of large language models on ai accelerators. InSC24-W: Workshops of the International Conference for High Performance Computing, Networking, Stor...
work page 2024
-
[18]
Nvidia a100 tensor core gpu: Performance and innovation
Jack Choquette, Wishwesh Gandhi, Olivier Giroux, Nick Stam, and Ronny Krashinsky. Nvidia a100 tensor core gpu: Performance and innovation. IEEE Micro, 41(2):29–35, 2021
work page 2021
-
[19]
de Araújo, JPW, and MinervaBooks
Benoit Courty, Victor Schmidt, Sasha Luccioni, Goyal-Kamal, MarionCoutarel, Boris Feld, Jérémy Lecourt, LiamConnell, Amine Saboni, Inimaz, supatomic, Mathilde Léval, Luis Blanche, Alexis Cruveiller, ouminasara, Franklin Zhao, Aditya Joshi, Alexis Bogroff, Hugues de Lavoreille, Niko Characterizing Performance–Energy Trade-offs of Large Language Models in M...
work page 2024
-
[20]
Flashattention: Fast and memory-efficient exact attention with io-awareness
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems, 35:16344–16359, 2022
work page 2022
-
[21]
Rapl: Memory power estimation and capping
Howard David, Eugene Gorbatov, Ulf R Hanebutte, Rahul Khanna, and Christian Le. Rapl: Memory power estimation and capping. InProceedings of the 16th ACM/IEEE international symposium on Low power electronics and design, pages 189–194, 2010
work page 2010
-
[22]
Energy considerations of large language model inference and efficiency optimizations
Jared Fernandez, Clara Na, Vashisth Tiwari, Yonatan Bisk, Sasha Luccioni, and Emma Strubell. Energy considerations of large language model inference and efficiency optimizations. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V...
work page 2025
-
[23]
Eva García-Martín, Crefeda Faviola Rodrigues, Graham Riley, and Håkan Grahn. Estimation of energy consumption in machine learning.Journal of Parallel and Distributed Computing, 134:75–88, 2019
work page 2019
-
[24]
Stefanos Georgiou, Maria Kechagia, Tushar Sharma, Federica Sarro, and Ying Zou. Green ai: Do deep learning frameworks have different costs? In Proceedings of the 44th International Conference on Software Engineering, pages 1082–1094, 2022
work page 2022
-
[25]
ggml-org/llama.cpp: Llm inference in c/c++, 2025
ggml-org. ggml-org/llama.cpp: Llm inference in c/c++, 2025
work page 2025
- [26]
-
[27]
Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Reza Yazdani Aminabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, et al. Deepspeed-fastgen: High-throughput text generation for llms via mii and deepspeed-inference.arXiv preprint arXiv:2401.08671, 2024
-
[28]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[29]
Hongzhen Huang, Kunming Zhang, Hanlong Liao, Kui Wu, and Guoming Tang. Wattsonai: Measuring, analyzing, and visualizing energy and carbon footprint of ai workloads.arXiv preprint arXiv:2506.20535, 2025
-
[30]
huggingface/text-generation-inference: Large language model text generation inference, 2025
huggingface. huggingface/text-generation-inference: Large language model text generation inference, 2025
work page 2025
- [31]
-
[32]
International Energy Agency (IEA). Energy efficiency 2024, 2024. Licence: CC BY 4.0
work page 2024
-
[33]
International Energy Agency (IEA). Energy efficiency 2025, 2025
work page 2025
-
[34]
ml-energy/zeus: Measure and optimize the energy consumption of your ai applications!, 2025
Jie You and Jae-Won Chung and Mosharaf Chowdhury. ml-energy/zeus: Measure and optimize the energy consumption of your ai applications!, 2025
work page 2025
-
[35]
Andreas Kosmas Kakolyris, Dimosthenis Masouros, Sotirios Xydis, and Dimitrios Soudris. Slo-aware gpu dvfs for energy-efficient llm inference serving.IEEE Computer Architecture Letters, 23(2):150–153, 2024
work page 2024
-
[36]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[37]
Energy consumption of neural networks on nvidia edge boards: an empirical model
Seyyidahmed Lahmer, Aria Khoshsirat, Michele Rossi, and Andrea Zanella. Energy consumption of neural networks on nvidia edge boards: an empirical model. In2022 20th international symposium on modeling and optimization in mobile, ad hoc, and wireless networks (WiOpt), pages 365–371. IEEE, 2022
work page 2022
-
[38]
Llm inference serving: Survey of recent advances and opportunities
Baolin Li, Yankai Jiang, Vijay Gadepally, and Devesh Tiwari. Llm inference serving: Survey of recent advances and opportunities. In2024 IEEE High Performance Extreme Computing Conference (HPEC), pages 1–8. IEEE, 2024
work page 2024
-
[39]
Yucheng Li. Unlocking context constraints of llms: Enhancing context efficiency of llms with self-information-based content filtering.arXiv preprint arXiv:2304.12102, 2023
-
[40]
{AlpaServe}: Statistical multiplexing with model parallelism for deep learning serving
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E Gonzalez, et al. {AlpaServe}: Statistical multiplexing with model parallelism for deep learning serving. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23), pages 663–679, 2023
work page 2023
-
[41]
Parrot: Efficient serving of {LLM-based} applications with semantic variable
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. Parrot: Efficient serving of {LLM-based} applications with semantic variable. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 929–945, 2024
work page 2024
-
[42]
Zejia Lin, Hongxin Xu, Guanyi Chen, Xianwei Zhang, and Yutong Lu. Bullet: Boosting gpu utilization for llm serving via dynamic spatial-temporal orchestration.arXiv preprint arXiv:2504.19516, 2025
-
[43]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.arXiv preprint arXiv:2307.03172, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Michael Luo, Xiaoxiang Shi, Colin Cai, Tianjun Zhang, Justin Wong, Yichuan Wang, Chi Wang, Yanping Huang, Zhifeng Chen, Joseph E Gonzalez, et al. Autellix: An efficient serving engine for llm agents as general programs.arXiv preprint arXiv:2502.13965, 2025
-
[45]
Paul Joe Maliakel, Shashikant Ilager, and Ivona Brandic. Investigating energy efficiency and performance trade-offs in llm inference across tasks and dvfs settings.arXiv preprint arXiv:2501.08219, 2025
-
[46]
The multi-agent framework, 2025
MetaGPT. The multi-agent framework, 2025. 24 Md. Monzurul Amin Ifath and Israat Haque
work page 2025
- [47]
-
[48]
Microsoft. microsoft/parrotserve: [osdi’24] serving llm-based applications efficiently with semantic variable, 2025
work page 2025
-
[49]
Large Language Models: A Survey
Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. Large language models: A survey.arXiv preprint arXiv:2402.06196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
System management interface smi, 2025
NVIDIA Developer. System management interface smi, 2025
work page 2025
-
[51]
Get up and running with openai gpt-oss, deepseek-r1, gemma 3 and other models., 2025
Ollama. Get up and running with openai gpt-oss, deepseek-r1, gemma 3 and other models., 2025
work page 2025
-
[52]
Open Collective. vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for llms, 2025
work page 2025
- [53]
-
[54]
Characterizing power management opportunities for llms in the cloud
Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Brijesh Warrier, Nithish Mahalingam, and Ricardo Bianchini. Characterizing power management opportunities for llms in the cloud. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, pages 207–222, 2024
work page 2024
-
[55]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 118–132. IEEE, 2024
work page 2024
-
[56]
Tu (r) ning ai green: Exploring energy efficiency cascading with orthogonal optimizations
Saurabhsingh Rajput, Mootez Saad, and Tushar Sharma. Tu (r) ning ai green: Exploring energy efficiency cascading with orthogonal optimizations. arXiv preprint arXiv:2506.18289, 2025
-
[57]
Saurabhsingh Rajput, Tim Widmayer, Ziyuan Shang, Maria Kechagia, Federica Sarro, and Tushar Sharma. Enhancing energy-awareness in deep learning through fine-grained energy measurement.ACM Transactions on Software Engineering and Methodology, 33(8):1–34, 2024
work page 2024
-
[58]
From words to watts: Benchmarking the energy costs of large language model inference
Siddharth Samsi, Dan Zhao, Joseph McDonald, Baolin Li, Adam Michaleas, Michael Jones, William Bergeron, Jeremy Kepner, Devesh Tiwari, and Vijay Gadepally. From words to watts: Benchmarking the energy costs of large language model inference. In2023 IEEE High Performance Extreme Computing Conference (HPEC), pages 1–9. IEEE, 2023
work page 2023
-
[59]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36:68539–68551, 2023
work page 2023
-
[60]
sglang.ai. sgl-project/sglang: Sglang is a fast serving framework for large language models and vision language models., 2025
work page 2025
- [61]
-
[62]
The sparsely-gated mixture-of-experts layer.Outrageously large neural networks, 2, 2017
N Shazeer, A Mirhoseini, K Maziarz, A Davis, Q Le, G Hinton, and J Dean. The sparsely-gated mixture-of-experts layer.Outrageously large neural networks, 2, 2017
work page 2017
-
[63]
On the sustainability of ai inferences in the edge.arXiv preprint arXiv:2507.23093, 2025
Ghazal Sobhani, Md Monzurul Amin Ifath, Tushar Sharma, and Israat Haque. On the sustainability of ai inferences in the edge.arXiv preprint arXiv:2507.23093, 2025
-
[64]
Towards greener llms: Bringing energy-efficiency to the forefront of llm inference
Jovan Stojkovic, Esha Choukse, Chaojie Zhang, Íñigo Goiri, and Josep Torrellas. Towards greener llms: Bringing energy-efficiency to the forefront of llm inference. InEMC2 at ASPLOS, April 2024
work page 2024
-
[65]
Dynamollm: Designing llm inference clusters for performance and energy efficiency
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. Dynamollm: Designing llm inference clusters for performance and energy efficiency. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1348–1362. IEEE, 2025
work page 2025
-
[66]
Zhaoyuan Su, Tingfeng Lan, Zirui Wang, Juncheng Yang, and Yue Cheng. Efficient and workload-aware llm serving via runtime layer swapping and kv cache resizing.arXiv preprint arXiv:2506.02006, 2025
-
[67]
Llumnix: Dynamic scheduling for large language model serving
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. Llumnix: Dynamic scheduling for large language model serving. In18th USENIX symposium on operating systems design and implementation (OSDI 24), pages 173–191, 2024
work page 2024
-
[68]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
Xiaolong Tu, Anik Mallik, Dawei Chen, Kyungtae Han, Onur Altintas, Haoxin Wang, and Jiang Xie. Unveiling energy efficiency in deep learning: Measurement, prediction, and scoring across edge devices. InProceedings of the Eighth ACM/IEEE Symposium on Edge Computing, pages 80–93, 2023
work page 2023
-
[70]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[71]
Grant Wilkins, Srinivasan Keshav, and Richard Mortier. Offline energy-optimal llm serving: Workload-based energy models for llm inference on heterogeneous systems.ACM SIGENERGY Energy Informatics Review, 4(5):113–119, 2024
work page 2024
-
[72]
Carole-Jean Wu, Ramya Raghavendra, Udit Gupta, Bilge Acun, Newsha Ardalani, Kiwan Maeng, Gloria Chang, Fiona Aga, Jinshi Huang, Charles Bai, et al. Sustainable ai: Environmental implications, challenges and opportunities.Proceedings of machine learning and systems, 4:795–813, 2022
work page 2022
-
[73]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation framework.arXiv preprint arXiv:2308.08155, 3(4), 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[74]
Zeus: Understanding and optimizing {GPU } energy consumption of {DNN} training
Jie You, Jae-Won Chung, and Mosharaf Chowdhury. Zeus: Understanding and optimizing {GPU } energy consumption of {DNN} training. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 119–139, 2023
work page 2023
-
[75]
Orca: A distributed serving system for{Transformer-Based} generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for{Transformer-Based} generative models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538, 2022
work page 2022
-
[76]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
work page 2023
-
[77]
Llm-enhanced data management.arXiv preprint arXiv:2402.02643, 2024
Xuanhe Zhou, Xinyang Zhao, and Guoliang Li. Llm-enhanced data management.arXiv preprint arXiv:2402.02643, 2024. Characterizing Performance–Energy Trade-offs of Large Language Models in Multi-Request Workflows 25
-
[78]
Language agents as optimizable graphs.arXiv preprint arXiv:2402.16823, 2024
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Language agents as optimizable graphs.arXiv preprint arXiv:2402.16823, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.