Recognition: 1 theorem link
· Lean TheoremIdentity-Aware U-Net: Fine-grained Cell Segmentation via Identity-Aware Representation Learning
Pith reviewed 2026-05-10 19:10 UTC · model grok-4.3
The pith
Identity-Aware U-Net adds an auxiliary embedding branch to learn identity representations that distinguish visually similar cells during mask prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
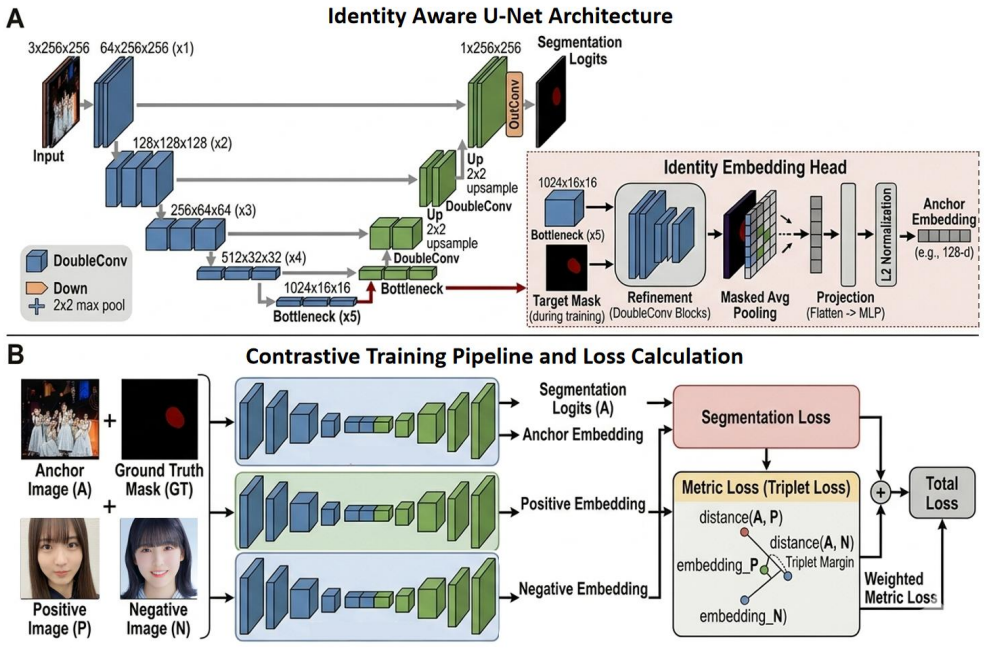
The Identity-Aware U-Net jointly models spatial localization and instance discrimination by augmenting the segmentation backbone with an auxiliary embedding branch that learns discriminative identity representations from high-level features, with triplet-based metric learning used to pull target-consistent embeddings together and separate them from hard negatives that share similar morphology.
What carries the argument
Auxiliary embedding branch trained with triplet loss on high-level features to produce identity representations that separate near-identical instances.
If this is right
- The model produces more accurate instance-level masks in scenes with overlapping cells or ambiguous boundaries.
- Segmentation moves from category-level region detection to discrimination among visually similar objects.
- The same architecture can be applied to other dense prediction tasks that contain morphologically close instances.
- Training remains end-to-end and uses the existing mask annotations plus only the triplet supervision derived from them.
Where Pith is reading between the lines
- The approach may reduce the need for separate post-processing steps such as watershed or clustering to split touching objects.
- Similar auxiliary branches could be tested on non-biological images that contain repeated similar shapes, such as crowd or particle scenes.
- If the embedding space proves stable, the learned identities might support downstream tasks like tracking the same cell across frames without extra models.
Load-bearing premise
The auxiliary embedding branch will reliably separate instances with near-identical contours or textures without degrading the primary mask prediction or requiring large amounts of additional identity annotations.
What would settle it
Training and evaluating on a cell dataset where all instances have deliberately matched contours and textures, then checking whether average precision or boundary F1 scores rise above a plain U-Net baseline; no improvement would falsify the central claim.
Figures

read the original abstract
Precise segmentation of objects with highly similar shapes remains a challenging problem in dense prediction, especially in scenarios with ambiguous boundaries, overlapping instances, and weak inter-instance visual differences. While conventional segmentation models are effective at localizing object regions, they often lack the discriminative capacity required to reliably distinguish a target object from morphologically similar distractors. In this work, we study fine-grained object segmentation from an identity-aware perspective and propose Identity-Aware U-Net (IAU-Net), a unified framework that jointly models spatial localization and instance discrimination. Built upon a U-Net-style encoder-decoder architecture, our method augments the segmentation backbone with an auxiliary embedding branch that learns discriminative identity representations from high-level features, while the main branch predicts pixel-accurate masks. To enhance robustness in distinguishing objects with near-identical contours or textures, we further incorporate triplet-based metric learning, which pulls target-consistent embeddings together and separates them from hard negatives with similar morphology. This design enables the model to move beyond category-level segmentation and acquire a stronger capability for precise discrimination among visually similar objects. Experiments on benchmarks including cell segmentation demonstrate promising results, particularly in challenging cases involving similar contours, dense layouts, and ambiguous boundaries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Identity-Aware U-Net (IAU-Net), a U-Net-style encoder-decoder augmented with an auxiliary embedding branch. The branch applies triplet loss to high-level encoder features to learn identity-discriminative representations, with the goal of improving fine-grained instance segmentation for cells that have near-identical contours, textures, and ambiguous boundaries.
Significance. If the auxiliary branch reliably improves instance separation without degrading mask accuracy, the work would offer a practical way to move standard segmentation models beyond category-level predictions in dense, low-contrast scenes such as cell microscopy. The integration of metric learning into a segmentation backbone is a straightforward idea that could be adopted in biomedical imaging pipelines.
major comments (2)
- [Abstract and §3] Abstract and §3 (method description): the central claim that triplet loss on high-level features 'enhances robustness in distinguishing objects with near-identical contours or textures' and transfers to better boundary decisions rests on three unverified assumptions—(1) reliable positive/negative triplets can be mined from ordinary instance masks without extra identity labels, (2) the metric-learning gradient does not interfere with the primary segmentation loss in the shared encoder, and (3) high-level features retain enough spatial detail for contour-level discrimination. None of these are supported by ablation results or gradient analysis in the manuscript.
- [Experiments] Experiments section: the abstract asserts 'promising results' on cell segmentation benchmarks yet reports no quantitative metrics (Dice, IoU, boundary F-score), no baseline comparisons, and no ablation isolating the embedding branch. Without these numbers the load-bearing claim that the identity-aware design acquires 'stronger capability for precise discrimination' cannot be evaluated.
minor comments (2)
- [Abstract] The abstract would be strengthened by including one or two key quantitative results (e.g., Dice improvement on a named dataset) to substantiate the 'promising results' statement.
- [§3] Notation for the embedding branch output dimension, margin of the triplet loss, and the exact form of the combined loss (segmentation + triplet) should be defined explicitly, preferably with an equation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [Abstract and §3] The central claim that triplet loss on high-level features enhances robustness rests on three unverified assumptions: (1) reliable positive/negative triplets can be mined from ordinary instance masks without extra identity labels, (2) the metric-learning gradient does not interfere with the primary segmentation loss, and (3) high-level features retain enough spatial detail. None are supported by ablation results or gradient analysis.
Authors: We agree that the manuscript does not contain explicit ablations or gradient-flow analysis to verify these three points. Triplet construction relies on the provided instance masks to designate same-instance pixels as positives and different-instance pixels as negatives, which is feasible without additional identity annotations. The joint training objective is intended to balance the two losses, but we have not demonstrated this balance empirically. In the revised manuscript we will add (a) an ablation that isolates the triplet term, (b) quantitative comparison of segmentation metrics with and without the auxiliary branch, and (c) a brief analysis of feature discriminability (e.g., embedding distances for morphologically similar cells). revision: yes
-
Referee: [Experiments] The abstract asserts 'promising results' on cell segmentation benchmarks yet reports no quantitative metrics (Dice, IoU, boundary F-score), no baseline comparisons, and no ablation isolating the embedding branch. The load-bearing claim cannot be evaluated.
Authors: We acknowledge that the current experiments section is incomplete and does not supply the requested quantitative evidence. The phrase 'promising results' is not backed by tables or figures in the submitted version. In the revision we will include: Dice, IoU, and boundary F-score on the cited cell benchmarks; direct comparisons against a standard U-Net and at least one additional baseline; and an ablation that removes the identity-aware branch while keeping all other components fixed. These additions will allow readers to assess the contribution of the proposed design. revision: yes
Circularity Check
No circularity: standard multi-task U-Net with auxiliary triplet loss
full rationale
The paper presents IAU-Net as a U-Net backbone augmented by an auxiliary embedding branch trained with triplet loss on high-level features, using conventional supervised segmentation and metric-learning objectives. No derivation chain reduces a claimed prediction or uniqueness result to its own fitted inputs by construction, no load-bearing self-citations are invoked for theorems or ansatzes, and no known empirical pattern is merely renamed. The approach is self-contained as a standard architecture choice with empirical results, not circular. Score 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption High-level features from a U-Net encoder contain identity-discriminative information separable by triplet loss
- domain assumption Triplet loss will improve instance discrimination without harming pixel-level mask quality
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
augments the segmentation backbone with an auxiliary embedding branch that learns discriminative identity representations from high-level features... triplet-based metric learning, which pulls target-consistent embeddings together and separates them from hard negatives
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Signature verification using a “Siamese” time delay neural network
Jane Bromley, Isabelle Guyon, Yann LeCun, Eduard S¨ackinger, and Roopak Shah. Signature verification using a “Siamese” time delay neural network. InAdvances in Neural Information Processing Systems (NeurIPS), volume 6, 1993
work page 1993
-
[2]
Caicedo, Allen Goodman, Kyle W
Juan C. Caicedo, Allen Goodman, Kyle W. Karhohs, Beth A. Cimini, Jeanelle Ackerman, Marzieh Haghighi, et al. Nu- cleus segmentation across imaging experiments: the 2018 data science bowl.Nature Methods, 16(12):1247–1253, 2019
work page 2018
-
[3]
Hao Chen, Xiaojuan Qi, Lequan Yu, Qi Dou, Jing Qin, and Pheng-Ann Heng. Dcan: Deep contour-aware networks for accurate gland segmentation.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2487–2496, 2016
work page 2016
-
[4]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vi- sion (ECCV), pages 801–818, 2018
work page 2018
-
[5]
Ahmed Raza, Ayesha Azam, Yee Wah Tsang, Jin Tae Kwak, and Nasir Rajpoot
Simon Graham, Quoc Dang Vu, Shan E. Ahmed Raza, Ayesha Azam, Yee Wah Tsang, Jin Tae Kwak, and Nasir Rajpoot. Hover-net: Simultaneous segmentation and classi- fication of nuclei in multi-tissue histology images.Medical Image Analysis, 58:101563, 2019
work page 2019
-
[6]
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask r-cnn. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2961–2969, 2017
work page 2017
-
[7]
In Defense of the Triplet Loss for Person Re-Identification
Alexander Hermans, Lucas Beyer, and Bastian Leibe. In de- fense of the triplet loss for person re-identification.arXiv preprint arXiv:1703.07737, 2017
work page Pith review arXiv 2017
-
[8]
Supervised contrastive learning
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. InAd- vances in Neural Information Processing Systems (NeurIPS), volume 33, pages 18661–18673, 2020. 6
work page 2020
-
[9]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, 2023
work page 2023
-
[10]
A multi-organ nucleus segmentation challenge
Neeraj Kumar, Ruchika Verma, Deepak Anand, Yanning Zhou, et al. A multi-organ nucleus segmentation challenge. IEEE Transactions on Medical Imaging, 39(5):1380–1391, 2020
work page 2020
-
[11]
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks
Dong-Hyun Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. InICML Workshop on Challenges in Representation Learn- ing (WREPL), 2013
work page 2013
-
[12]
Hyeonsoo Lee and Won-Ki Jeong. Scribble2label: Scribble- supervised cell segmentation via self-generating pseudo- labels with consistency. InMedical Image Computing and Computer-Assisted Intervention (MICCAI), pages 14– 23, 2020
work page 2020
-
[13]
Geert Litjens, Thijs Kooi, Babak Ehteshami Bejnordi, Ar- naud Arindra Adiyoso Setio, Francesco Ciompi, Mohsen Ghafoorian, Jeroen A. W. M. van der Laak, Bram van Gin- neken, and Clara I. S ´anchez. A survey on deep learning in medical image analysis.Medical Image Analysis, 42:60–88, 2017
work page 2017
-
[14]
Fully convolutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3431–3440, 2015
work page 2015
-
[15]
Splinedist: Automated cell segmentation with spline curves
Krishnendu Mandal, Virginie Uhlmann, and Timo Ropinski. Splinedist: Automated cell segmentation with spline curves. InMedical Image Computing and Computer-Assisted Inter- vention (MICCAI), pages 108–118, 2020
work page 2020
-
[16]
Peter Naylor, Marie La ´e, Fabien Reyal, and Thomas Walter. Segmentation of nuclei in histopathology images by deep re- gression of the distance map.IEEE Transactions on Medical Imaging, 38(2):448–459, 2019
work page 2019
-
[17]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Inter- vention (MICCAI), pages 234–241, 2015
work page 2015
-
[18]
Carsten Rother, Vladimir Kolmogorov, and Andrew Blake. Grabcut: Interactive foreground extraction using iterated graph cuts.ACM Transactions on Graphics, 23(3):309–314, 2004
work page 2004
-
[19]
Cell detection with star-convex polygons
Uwe Schmidt, Martin Weigert, Coleman Broaddus, and Gene Myers. Cell detection with star-convex polygons. In Medical Image Computing and Computer-Assisted Interven- tion (MICCAI), pages 265–273, 2018
work page 2018
-
[20]
Facenet: A unified embedding for face recognition and clus- tering
Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clus- tering. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 815– 823, 2015
work page 2015
-
[21]
Cellpose: a generalist algorithm for cellular segmentation.Nature Methods, 18(1):100–106, 2021
Carsen Stringer, Tim Wang, Michalis Michaelos, and Mar- ius Pachitariu. Cellpose: a generalist algorithm for cellular segmentation.Nature Methods, 18(1):100–106, 2021
work page 2021
-
[22]
On reg- ularized losses for weakly-supervised cnn segmentation
Meng Tang, Federico Perazzi, Abdelaziz Djelouah, Ismail Ben Ayed, Christopher Schroers, and Yuri Boykov. On reg- ularized losses for weakly-supervised cnn segmentation. In Proceedings of the European Conference on Computer Vi- sion (ECCV), pages 507–522, 2018. 7
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.