Recognition: 1 theorem link
· Lean TheoremHead-wise Modality Specialization within MLLMs for Robust Fake News Detection under Missing Modality
Pith reviewed 2026-05-10 18:14 UTC · model grok-4.3
The pith
Specializing attention heads in MLLMs to individual modalities preserves verification ability when one input type is missing in fake news detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
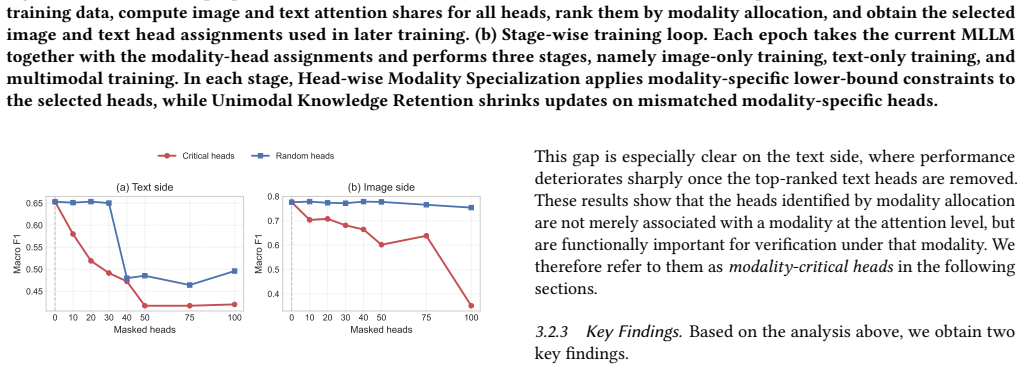
Systematic examination shows that modality-critical attention heads function as the primary carriers of unimodal verification ability due to their specialization. Explicitly assigning these heads to separate modalities and enforcing lower-bound attention constraints maintains their focus, while a unimodal knowledge retention step stops them from drifting away from the limited single-modality supervision. The resulting head-wise specialization improves detection robustness under missing-modality conditions while leaving performance unchanged when both modalities are available.
What carries the argument
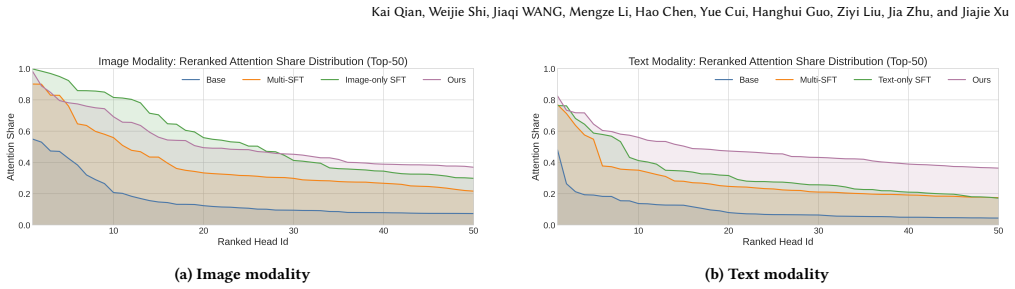
The head-wise modality specialization mechanism that identifies modality-critical attention heads, allocates them to distinct modalities via lower-bound attention constraints, and applies unimodal knowledge retention to preserve their verification capacity.
If this is right
- Detection performance on complete multimodal inputs stays comparable to baseline MLLMs.
- Accuracy rises specifically when either the text or the visual evidence is unavailable.
- The retention step allows more effective use of scarce unimodal annotations without harming joint training.
- The same allocation logic can be applied at inference time without retraining the entire model.
Where Pith is reading between the lines
- The head-allocation technique could be tested on other multimodal tasks that routinely encounter incomplete inputs, such as visual question answering with missing image regions.
- Treating attention heads as modular, modality-locked units suggests a broader way to make large models more tolerant of data loss or corruption.
- One could measure whether the specialized heads identified in one MLLM transfer their benefits when the same constraints are applied to a different architecture.
Load-bearing premise
The premise that the heads flagged as modality-critical in the systematic study genuinely hold unimodal verification ability and that the attention constraints plus retention step will keep that ability active for the low-contribution modality when the other input is absent.
What would settle it
Disable the allocated heads during inference and check whether the accuracy drop is substantially larger in missing-modality test cases than in full-input cases; a clear difference would support their role as carriers of the preserved ability.
Figures





read the original abstract
Multimodal fake news detection (MFND) aims to verify news credibility by jointly exploiting textual and visual evidence. However, real-world news dissemination frequently suffers from missing modality due to deleted images, corrupted screenshots, and similar issues. Thus, robust detection in this scenario requires preserving strong verification ability for each modality, which is challenging in MFND due to insufficient learning of the low-contribution modality and scarce unimodal annotations. To address this issue, we propose Head-wise Modality Specialization within Multimodal Large Language Models (MLLMs) for robust MFND under missing modality. Specifically, we first systematically study attention heads in MLLMs and their relationship with performance under missing modality, showing that modality-critical heads serve as key carriers of unimodal verification ability through their modality specialization. Based on this observation, to better preserve verification ability for the low-contribution modality, we introduce a head-wise specialization mechanism that explicitly allocates these heads to different modalities and preserves their specialization through lower-bound attention constraints. Furthermore, to better exploit scarce unimodal annotations, we propose a Unimodal Knowledge Retention strategy that prevents these heads from drifting away from the unimodal knowledge learned from limited supervision. Experiments show that our method improves robustness under missing modality while preserving performance with full multimodal input.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that attention heads in MLLMs exhibit modality specialization, with certain heads acting as key carriers of unimodal verification ability for fake news detection. Based on a systematic masking study, the authors propose allocating these modality-critical heads to specific modalities via lower-bound attention constraints and a Unimodal Knowledge Retention strategy to handle scarce unimodal annotations. This is intended to improve robustness under missing modalities while maintaining performance on complete multimodal inputs.
Significance. If the results hold and the head identification is causally linked to unimodal abilities, the approach could provide a lightweight, model-internal way to address missing-modality issues in real-world MFND without heavy reliance on data augmentation or external supervision. It extends observations of head specialization in transformers to a practical robustness setting.
major comments (2)
- [§3] §3 (systematic study of attention heads): The masking-based identification of modality-critical heads risks confounding modality-specific verification with general attention capacity or cross-modal fusion effects. Performance drops under missing-modality masking could arise from disrupting overall model flow rather than losing specialized unimodal pathways, which would undermine the justification for the subsequent lower-bound constraints and allocation mechanism.
- [§4] §4 (experiments): The central robustness claim depends on showing that the specialization preserves unimodal ability specifically for the low-contribution modality; without ablations isolating the confound (e.g., comparing against random head allocation or capacity-matched controls), the reported gains may not be attributable to the proposed mechanism.
minor comments (2)
- [Abstract] Abstract: Lacks any quantitative metrics, baseline comparisons, or dataset names, which makes the strength of the experimental claims difficult to gauge from the summary alone.
- [§3.3] Notation: The terms 'lower-bound attention constraints' and 'Unimodal Knowledge Retention' are introduced without an equation or pseudocode in the provided description, leaving the precise implementation unclear.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight valid concerns about potential confounds in the head identification study and the need for stronger experimental controls to attribute gains to the proposed mechanism. We address each point below, providing clarifications from the manuscript and outlining targeted revisions to strengthen the claims.
read point-by-point responses
-
Referee: §3 (systematic study of attention heads): The masking-based identification of modality-critical heads risks confounding modality-specific verification with general attention capacity or cross-modal fusion effects. Performance drops under missing-modality masking could arise from disrupting overall model flow rather than losing specialized unimodal pathways, which would undermine the justification for the subsequent lower-bound constraints and allocation mechanism.
Authors: We appreciate this concern about possible confounds in the masking study. The study systematically masks individual heads and measures degradation specifically under missing-modality inputs (while the other modality remains available), identifying heads whose removal disproportionately affects unimodal verification for the low-contribution modality. To address the risk that drops reflect general attention capacity or fusion disruption rather than specialized pathways, we will add in the revision a direct comparison of attention activation patterns and modality-specific scores between the identified critical heads and randomly selected heads of similar capacity. This analysis will show stronger modality specialization in the critical heads, providing better justification for the lower-bound constraints and allocation. revision: partial
-
Referee: §4 (experiments): The central robustness claim depends on showing that the specialization preserves unimodal ability specifically for the low-contribution modality; without ablations isolating the confound (e.g., comparing against random head allocation or capacity-matched controls), the reported gains may not be attributable to the proposed mechanism.
Authors: We agree that isolating the contribution of modality-specific head allocation is essential for causal attribution. Our current experiments compare against full multimodal training and existing robustness baselines, but do not include random allocation controls. In the revised manuscript we will add ablations with (i) random head allocation under the same lower-bound constraints and (ii) capacity-matched controls that constrain an equal number of heads without modality-specific assignment. These will demonstrate that gains under missing modalities arise from preserving the identified critical heads rather than from general capacity retention or constraint effects alone. revision: yes
Circularity Check
No circularity: method follows from empirical head-masking observations
full rationale
The paper's central chain begins with a systematic masking study of attention heads in MLLMs, observes performance drops under missing-modality settings, and then proposes head allocation plus lower-bound constraints and unimodal retention based on those observations. No equations, fitted parameters, or self-citations are shown that reduce the specialization mechanism or robustness claims to the inputs by construction. The derivation remains self-contained because the proposed interventions are motivated by, but not definitionally equivalent to, the reported empirical patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Certain attention heads in MLLMs specialize in individual modalities and carry unimodal verification ability.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We quantify head-level modality allocation by measuring how each attention head distributes attention across token groups... L_lb_img = 1/|H_img| Σ max(0, τ - m_img(X))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Jing Bi, Junjia Guo, Yunlong Tang, Lianggong Bruce Wen, Zhang Liu, Bingjie Wang, and Chenliang Xu. 2025. Unveiling visual perception in language models: An attention head analysis approach. InProceedings of the Computer Vision and Pattern Recognition Conference. 4135–4144
2025
-
[3]
Yixuan Chen, Dongsheng Li, Peng Zhang, Jie Sui, Qin Lv, Lu Tun, and Li Shang
-
[4]
In Proceedings of the ACM web conference 2022
Cross-modal ambiguity learning for multimodal fake news detection. In Proceedings of the ACM web conference 2022. 2897–2905
2022
-
[5]
Yi-Ting Chen, Jinghao Shi, Zelin Ye, Christoph Mertz, Deva Ramanan, and Shu Kong. 2022. Multimodal object detection via probabilistic ensembling. InEuro- pean Conference on Computer Vision. Springer, 139–158
2022
-
[6]
Marco L Della Vedova, Eugenio Tacchini, Stefano Moret, Gabriele Ballarin, Mas- simo DiPierro, and Luca De Alfaro. 2018. Automatic online fake news detection combining content and social signals. In2018 22nd conference of open innovations association (FRUCT). IEEE, 272–279
2018
-
[7]
Marc Fisher, John Woodrow Cox, and Peter Hermann. 2016. Pizzagate: From rumor, to hashtag, to gunfire in DC.Washington Post6 (2016), 8410–8415
2016
-
[8]
Lifang Fu and Shuai Liu. 2023. Multimodal fake news detection incorporating external knowledge and user interaction feature.Advances in Multimedia2023, 1 (2023), 8836476
2023
-
[9]
Chongjian Ge, Junsong Chen, Enze Xie, Zhongdao Wang, Lanqing Hong, Huchuan Lu, Zhenguo Li, and Ping Luo. 2023. Metabev: Solving sensor fail- ures for 3d detection and map segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8721–8731
2023
-
[10]
Hao Guo, Zihan Ma, Zhi Zeng, Minnan Luo, Weixin Zeng, Jiuyang Tang, and Xiang Zhao. 2025. Each fake news is fake in its own way: An attribution multi- granularity benchmark for multimodal fake news detection. InProceedings of the AAAI conference on artificial intelligence, Vol. 39. 228–236
2025
-
[11]
Ying Guo, Hong Ge, and Jinhong Li. 2023. A two-branch multimodal fake news detection model based on multimodal bilinear pooling and attention mechanism. Frontiers in Computer Science5 (2023), 1159063
2023
-
[12]
Judy Hoffman, Saurabh Gupta, and Trevor Darrell. 2016. Learning with side information through modality hallucination. InProceedings of the IEEE conference on computer vision and pattern recognition. 826–834
2016
-
[13]
Jiaheng Hua, Xiaodong Cui, Xianghua Li, Keke Tang, and Peican Zhu. 2023. Multimodal fake news detection through data augmentation-based contrastive learning.Applied Soft Computing136 (2023), 110125
2023
-
[14]
Ruihan Jin, Ruibo Fu, Zhengqi Wen, Shuai Zhang, Yukun Liu, and Jianhua Tao
- [15]
-
[16]
Zhiwei Jin, Juan Cao, Han Guo, Yongdong Zhang, and Jiebo Luo. 2017. Multi- modal fusion with recurrent neural networks for rumor detection on microblogs. InProceedings of the 25th ACM international conference on Multimedia. 795–816
2017
-
[17]
Guanzhou Ke, Shengfeng He, Xiaoli Wang, Bo Wang, Guoqing Chao, Yuanyang Zhang, Yi Xie, and Hexing Su. 2025. Knowledge bridger: Towards training-free missing modality completion. InProceedings of the Computer Vision and Pattern Recognition Conference. 25864–25873
2025
-
[18]
Kwanhyung Lee, Soojeong Lee, Sangchul Hahn, Heejung Hyun, Edward Choi, Byungeun Ahn, and Joohyung Lee. 2023. Learning missing modal electronic health records with unified multi-modal data embedding and modality-aware attention. InMachine Learning for Healthcare Conference. PMLR, 423–442
2023
-
[19]
Guoyi Li, Die Hu, Xiaomeng Fu, Qirui Tang, Yulei Wu, Xiaodan Zhang, and Honglei Lyu. 2025. Entity Graph Alignment and Visual Reasoning for Multimodal Fake News Detection. InProceedings of the 33rd ACM International Conference on Multimedia. 2486–2495
2025
-
[20]
Zhiyuan Li, Yafei Zhang, Huafeng Li, Yi Chai, and Yushi Yang. 2024. Deformation- aware and reconstruction-driven multimodal representation learning for brain tumor segmentation with missing modalities.Biomedical Signal Processing and Control91 (2024), 106012
2024
-
[21]
Paul Pu Liang, Zhun Liu, Yao-Hung Hubert Tsai, Qibin Zhao, Ruslan Salakhutdi- nov, and Louis-Philippe Morency. 2019. Learning representations from imperfect time series data via tensor rank regularization. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 1569–1576
2019
-
[22]
Marion Meyers, Gerhard Weiss, and Gerasimos Spanakis. 2020. Fake news detec- tion on twitter using propagation structures. InMultidisciplinary International Symposium on Disinformation in Open Online Media. Springer, 138–158
2020
-
[23]
Salman Bin Naeem and Rubina Bhatti. 2020. The Covid-19 ‘infodemic’: a new front for information professionals.Health Information & Libraries Journal37, 3 (2020), 233–239
2020
-
[24]
Verónica Pérez-Rosas, Bennett Kleinberg, Alexandra Lefevre, and Rada Mihalcea
-
[25]
InProceedings of the 27th international conference on computational linguistics
Automatic detection of fake news. InProceedings of the 27th international conference on computational linguistics. 3391–3401
-
[26]
Feng Qian, Chengyue Gong, Karishma Sharma, and Yan Liu. 2018. Neural user response generator: Fake news detection with collective user intelligence.. In IJCAI, Vol. 18. 3834–3840
2018
-
[27]
Isabel Segura-Bedmar and Santiago Alonso-Bartolome. 2022. Multimodal fake news detection.Information13, 6 (2022), 284
2022
-
[28]
Wenqian Shang, Kang Song, Jialing Ji, Tong Yi, Jiajun Cai, and Xianxian Li. 2025. Semantic space aligned multimodal fake news detection.Information Fusion (2025), 103469
2025
-
[29]
Rui Shao, Tianxing Wu, and Ziwei Liu. 2023. Detecting and grounding multi- modal media manipulation. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. 6904–6913
2023
-
[30]
Shivangi Singhal, Rajiv Ratn Shah, Tanmoy Chakraborty, Ponnurangam Ku- maraguru, and Shin’ichi Satoh. 2019. Spotfake: A multi-modal framework for fake news detection. In2019 IEEE fifth international conference on multimedia big data (BigMM). IEEE, 39–47
2019
-
[31]
Jiahao Sun, Chen Chen, Chunyan Hou, Yike Wu, and Xiaojie Yuan. 2025. Multi- modal Taylor Series Network for Misinformation Detection. InProceedings of the ACM on Web Conference 2025. 2540–2548
2025
-
[32]
Damian Tambini. 2017. Fake news: public policy responses. (2017)
2017
-
[33]
Nguyen Manh Duc Tuan and Pham Quang Nhat Minh. 2021. Multimodal fusion with BERT and attention mechanism for fake news detection. In2021 RIVF international conference on computing and communication technologies (RIVF). IEEE, 1–6
2021
-
[34]
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. InProceedings of the 57th annual meeting of the association for computational linguistics. 5797–5808
2019
-
[35]
Longzheng Wang, Chuang Zhang, Hongbo Xu, Yongxiu Xu, Xiaohan Xu, and Siqi Wang. 2023. Cross-modal contrastive learning for multimodal fake news detection. InProceedings of the 31st ACM international conference on multimedia. 5696–5704
2023
-
[36]
Qianqian Wang, Huanhuan Lian, Gan Sun, Quanxue Gao, and Licheng Jiao. 2020. iCmSC: Incomplete cross-modal subspace clustering.IEEE Transactions on Image Processing30 (2020), 305–317
2020
-
[37]
Shu Wang, Zhe Qu, Yuan Liu, Shichao Kan, Yixiong Liang, and Jianxin Wang. 2024. Fedmmr: Multi-modal federated learning via missing modality reconstruction. In2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1–6
2024
-
[38]
Yuanzhi Wang, Zhen Cui, and Yong Li. 2023. Distribution-consistent modal recovering for incomplete multimodal learning. InProceedings of the IEEE/CVF International Conference on Computer Vision. 22025–22034
2023
- [39]
-
[40]
Yang Wu, Pengwei Zhan, Yunjian Zhang, Liming Wang, and Zhen Xu. 2021. Mul- timodal fusion with co-attention networks for fake news detection. InFindings of the association for computational linguistics: ACL-IJCNLP 2021. 2560–2569
2021
-
[41]
Wenxin Xu, Hexin Jiang, and Xuefeng Liang. 2024. Leveraging knowledge of modality experts for incomplete multimodal learning. InProceedings of the 32nd ACM International Conference on Multimedia. 438–446
2024
-
[42]
Junxiao Xue, Yabo Wang, Yichen Tian, Yafei Li, Lei Shi, and Lin Wei. 2021. De- tecting fake news by exploring the consistency of multimodal data.Information Processing & Management58, 5 (2021), 102610
2021
-
[43]
Zihui Xue and Radu Marculescu. 2023. Dynamic multimodal fusion. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2575–2584
2023
-
[44]
Long Ying, Hui Yu, Jinguang Wang, Yongze Ji, and Shengsheng Qian. 2021. Multi- level multi-modal cross-attention network for fake news detection.Ieee Access9 (2021), 132363–132373
2021
-
[45]
Zhilin Zeng, Zelin Peng, Xiaokang Yang, and Wei Shen. 2024. Missing as masking: arbitrary cross-modal feature reconstruction for incomplete multimodal brain tumor segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 424–433
2024
-
[46]
Zhi Zeng, Jiaying Wu, Minnan Luo, Herun Wan, Xiangzheng Kong, Zihan Ma, Guang Dai, and Qinghua Zheng. 2025. Imol: Incomplete-modality-tolerant learning for multi-domain fake news video detection. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 30921–30933
2025
-
[47]
Yifan Zhan, Rui Yang, Junxian You, Mengjie Huang, Weibo Liu, and Xiaohui Liu. 2025. A systematic literature review on incomplete multimodal learning: techniques and challenges.Systems Science & Control Engineering13, 1 (2025), 2467083
2025
-
[48]
Hengyuan Zhang, Zhihao Zhang, Mingyang Wang, Zunhai Su, Yiwei Wang, Qianli Wang, Shuzhou Yuan, Ercong Nie, Xufeng Duan, Qibo Xue, et al. 2026. Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Inter- pretability in Large Language Models.arXiv preprint arXiv:2601.14004(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
HaoChen Zhu. 2025. AdaptiveViTBERT: A Multimodal Fake News Detection Model Integrating Dynamic Gating and Missing Modality Compensation. In 2025 6th International Conference on Machine Learning and Computer Application (ICMLCA). IEEE, 1082–1088. Head-wise Modality Specialization within MLLMs for Robust Fake News Detection under Missing Modality Received 2...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.