Recognition: 2 theorem links
· Lean TheoremLAST: Leveraging Tools as Hints to Enhance Spatial Reasoning for Multimodal Large Language Models
Pith reviewed 2026-05-10 19:22 UTC · model grok-4.3
The pith
LAST framework turns vision tool outputs into hints that boost MLLM spatial reasoning by around 20 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
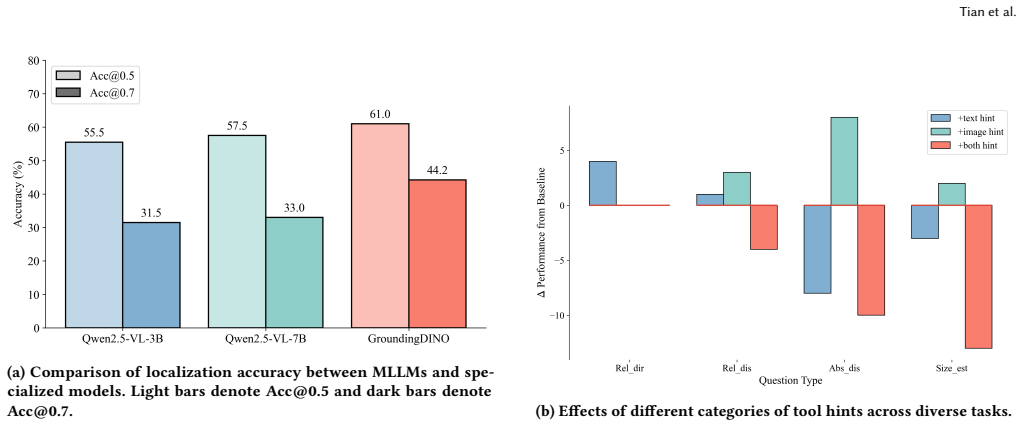
LAST-Box abstracts diverse vision tool calls into atomic instructions and reusable spatial skills that return multimodal hints directly usable by LLMs. A three-stage progressive training strategy then moves models from basic understanding of those hints to proficient and adaptive tool invocation. On four datasets, the resulting LAST-7B model records approximately 20 percent gains over its backbone and exceeds the performance of several strong proprietary closed-source LLMs on complex spatial reasoning.
What carries the argument
LAST-Box, an extensible interactive sandbox that converts heterogeneous tool invocations into atomic instructions and reusable spatial skills while returning multimodal hints for direct LLM consumption.
If this is right
- LAST-7B records around 20 percent performance improvement over its backbone model on spatial reasoning benchmarks.
- The three-stage training enables models to progress from interpreting tool outputs to adaptive and proficient tool use.
- Multimodal hints from abstracted tools allow smaller open models to outperform certain closed-source LLMs on complex geometric tasks.
- The framework provides an alternative to data scaling when internalizing structured geometric priors and spatial constraints.
Where Pith is reading between the lines
- The same hint-abstraction pattern could be applied to other multimodal domains such as temporal or causal reasoning.
- Reusable spatial skills created inside LAST-Box might be shared across different models and tasks as modular components.
- In practice this method could reduce the amount of task-specific fine-tuning data needed for reliable physical-world interaction.
- Integrating additional tool types beyond vision, such as simulation engines, would be a direct next extension.
Load-bearing premise
The multimodal hints produced by LAST-Box can be fed directly to LLMs and used for high-level spatial reasoning without adding new hallucinations or losing critical information.
What would settle it
A test that runs LAST-7B on the same four datasets but supplies it with no hints or with deliberately noisy hints from LAST-Box and checks whether the reported 20 percent gain vanishes.
Figures





read the original abstract
Spatial reasoning is a cornerstone capability for intelligent systems to perceive and interact with the physical world. However, multimodal large language models (MLLMs) frequently suffer from hallucinations and imprecision when parsing complex geometric layouts. As data-driven scaling struggles to internalize structured geometric priors and spatial constraints, integrating mature, specialized vision models presents a compelling alternative. Despite its promise, applying this paradigm to spatial reasoning is hindered by two key challenges: The difficulty of invoking heterogeneous, parameter-rich tools, as well as the challenge of understanding and effectively leveraging their diverse low-level outputs (e.g., segmentation masks, depth maps) in high-level reasoning. To address these challenges, we propose LAST, a unified framework for tool-augmented spatial reasoning. LAST features an extensible interactive sandbox, termed LAST-Box, which abstracts heterogeneous tool invocations into atomic instructions and reusable spatial skills, returning multimodal hints (e.g., annotated images and textual descriptions) that can be directly consumed by LLMs. We further design a three-stage progressive training strategy that guides models from understanding tool outputs to proficient and adaptive tool invocation. Experiments on four datasets show that LAST-7B achieves around 20\% performance gains over its backbone and outperforms strong proprietary closed-source LLMs, substantially enhancing reasoning on complex spatial tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LAST, a framework for tool-augmented spatial reasoning in multimodal LLMs. It introduces LAST-Box, an extensible sandbox that abstracts heterogeneous vision-tool calls (e.g., segmentation, depth) into atomic instructions and returns multimodal hints (annotated images plus textual descriptions) directly consumable by the LLM. A three-stage progressive training strategy is used to move the model from understanding tool outputs to adaptive invocation. On four datasets, LAST-7B is reported to deliver ~20% gains over its backbone and to outperform several closed-source models on complex spatial tasks.
Significance. If the reported gains prove robust, the work offers a concrete, extensible route for grounding MLLMs in mature vision tools without requiring the LLM itself to internalize low-level geometric priors. The abstraction of tool outputs into reusable multimodal hints and the staged training curriculum are practical contributions that could generalize beyond the evaluated tasks. The manuscript does not mention open-sourced code or parameter-free derivations, so reproducibility will depend on the experimental details supplied in revision.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the central performance claim (~20% gains and outperformance of closed models) is stated without any mention of the precise baselines, number of runs, error bars, dataset splits, or ablation controls. Because the entire significance rests on these empirical numbers, the absence of this information makes the claim impossible to evaluate at present.
- [Method (LAST-Box)] Method section (LAST-Box description): no quantitative metric is supplied that measures information preservation or hallucination rate when low-level tool outputs (masks, depth maps) are converted into the multimodal hints. The weakest assumption—that these hints can be reliably consumed without introducing new geometric errors or hallucinations—is therefore untested, yet it is load-bearing for the claim that tool augmentation improves spatial reasoning.
- [Method (three-stage training)] Training-strategy subsection: the three-stage progressive curriculum is presented as essential, but no ablation removing individual stages is reported. Without such controls it is unclear whether the observed gains are attributable to the staged training, to the hints themselves, or to other factors.
minor comments (2)
- [Method] Notation for the atomic instructions and reusable spatial skills inside LAST-Box should be defined once in a table or figure caption rather than scattered across prose.
- [Figures] Figure captions for the annotated-image examples should explicitly state which vision tool produced each annotation so readers can trace the hint-generation pipeline.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We provide detailed responses to each major comment below and commit to revising the paper to address the raised issues.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central performance claim (~20% gains and outperformance of closed models) is stated without any mention of the precise baselines, number of runs, error bars, dataset splits, or ablation controls. Because the entire significance rests on these empirical numbers, the absence of this information makes the claim impossible to evaluate at present.
Authors: We agree that the current presentation lacks sufficient detail for rigorous evaluation of the performance claims. In the revised version, we will clearly specify the baselines used in comparisons, indicate the number of experimental runs performed (with error bars or standard deviations if multiple runs were conducted), detail the dataset splits, and ensure ablation studies are comprehensively described. We will also update the abstract to better contextualize these results. revision: yes
-
Referee: [Method (LAST-Box)] Method section (LAST-Box description): no quantitative metric is supplied that measures information preservation or hallucination rate when low-level tool outputs (masks, depth maps) are converted into the multimodal hints. The weakest assumption—that these hints can be reliably consumed without introducing new geometric errors or hallucinations—is therefore untested, yet it is load-bearing for the claim that tool augmentation improves spatial reasoning.
Authors: We acknowledge this limitation in the current manuscript. Although the overall performance gains on spatial reasoning tasks provide indirect evidence of the hints' utility, we will add a quantitative evaluation of the hint generation process in the revision. This may include metrics such as the fidelity of mask annotations or depth information preservation, and an assessment of potential hallucinations in the textual descriptions accompanying the hints. revision: yes
-
Referee: [Method (three-stage training)] Training-strategy subsection: the three-stage progressive curriculum is presented as essential, but no ablation removing individual stages is reported. Without such controls it is unclear whether the observed gains are attributable to the staged training, to the hints themselves, or to other factors.
Authors: This is an important point for validating the training strategy. We will conduct and report additional ablation experiments in the revised manuscript, where we train models omitting one or more stages of the curriculum and compare their performance to the full three-stage approach. This will help attribute the gains specifically to the progressive training. revision: yes
Circularity Check
No circularity: empirical framework with independent experimental validation
full rationale
The paper describes a tool-augmented framework (LAST with LAST-Box sandbox and three-stage training) for enhancing MLLM spatial reasoning via multimodal hints, followed by empirical evaluation on four datasets. No equations, parameter fittings, self-citations, or derivations are present that reduce any claim to its own inputs by construction. Performance gains are reported from direct experiments rather than statistical forcing or renamed patterns, rendering the central results self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Specialized vision models produce accurate low-level outputs (segmentation masks, depth maps) that can be turned into useful high-level hints for LLMs.
invented entities (2)
-
LAST-Box
no independent evidence
-
Three-stage progressive training strategy
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LAST-Box abstracts heterogeneous tool invocations into atomic instructions and reusable spatial skills, returning multimodal hints (e.g., annotated images and textual descriptions)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage progressive training strategy that guides models from understanding tool outputs to proficient and adaptive tool invocation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
SpatialForge: Bootstrapping 3D-Aware Spatial Reasoning from Open-World 2D Images
SpatialForge synthesizes 10 million spatial QA pairs from in-the-wild 2D images to train VLMs for better depth ordering, layout, and viewpoint-dependent reasoning.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. 14455–14465
2024
-
[3]
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. 2024. End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Machine Intelligence(2024)
2024
- [4]
- [5]
-
[6]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24185–24198
2024
-
[7]
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. 2024. Spatialrgpt: Grounded spatial reasoning in vision-language models.Advances in Neural Information Processing Systems37 (2024), 135062–135093
2024
-
[8]
Mengfei Du, Binhao Wu, Zejun Li, Xuan-Jing Huang, and Zhongyu Wei. 2024. Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 346–355
2024
-
[9]
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. 2024. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision. Springer, 148–166
2024
-
[10]
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Pal: Program-aided language models. InProceedings of the 40th International Conference on Machine Learning. 10764– 10799
2023
-
[11]
Tanmay Gupta and Aniruddha Kembhavi. 2023. Visual programming: Com- positional visual reasoning without training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14953–14962
2023
- [12]
-
[13]
Yicong Hong, Qi Wu, Yuankai Qi, Cristian Rodriguez-Opazo, and Stephen Gould
-
[14]
InPro- ceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition
Vln bert: A recurrent vision-and-language bert for navigation. InPro- ceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. 1643–1653
-
[15]
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. 2024. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.Advances in Neural Information Processing Systems37 (2024), 139348–139379
2024
-
[16]
Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. 2023. Segment Anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 4015–4026
2023
-
[17]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [18]
- [19]
- [20]
- [21]
-
[22]
Fangyu Liu, Guy Emerson, and Nigel Collier. 2023. Visual spatial reasoning. Transactions of the Association for Computational Linguistics11 (2023), 635–651
2023
- [23]
-
[24]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. 2024. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision. Springer, 38–55
2024
-
[25]
Yang Liu, Weixing Chen, Yongjie Bai, Xiaodan Liang, Guanbin Li, Wen Gao, and Liang Lin. 2025. Aligning cyber space with physical world: A comprehensive survey on embodied ai.IEEE/ASME Transactions on Mechatronics(2025)
2025
-
[26]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al
-
[27]
Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [28]
-
[29]
Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xuanhe Zhou, Yufei Huang, Chaojun Xiao, et al. 2024. Tool learning with foundation models.Comput. Surveys57, 4 (2024), 1–40
2024
-
[30]
Ziqiao Shang, Lingyue Ge, Yang Chen, Shi-Yu Tian, Zhenyu Huang, Wenbo Fu, Yu-Feng Li, and Lan-Zhe Guo. 2026. MapTab: Can MLLMs Master Constrained Route Planning?arXiv preprint arXiv:2602.18600(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Shiyu Tian, Hongxin Wei, Yiqun Wang, and Lei Feng. 2024. Crosel: Cross selection of confident pseudo labels for partial-label learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19479–19488
2024
-
[33]
Shi-Yu Tian, Zhi Zhou, Wei Dong, Kun-Yang Yu, Ming Yang, Zi-Jian Cheng, Lan- Zhe Guo, and Yu-Feng Li. 2025. TabularMath: Understanding Math Reasoning over Tables with Large Language Models.arXiv preprint arXiv:2505.19563(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Shi-Yu Tian, Zhi Zhou, Kun-Yang Yu, Ming Yang, Lin-Han Jia, Lan-Zhe Guo, and Yu-Feng Li. 2025. VCSearch: Bridging the Gap Between Well-Defined and Ill-Defined Problems in Mathematical Reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 12721–12742
2025
-
[35]
Peter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Jairam Veda- giri IYER, Sai Charitha Akula, Shusheng Yang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. 2024. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems37 (2024), 87310–87356
2024
-
[36]
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rup- precht, and David Novotny. 2025. VGGT: Visual Geometry Grounded Trans- former. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5294–5306
2025
- [37]
- [38]
-
[39]
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. 2024. Pointllm: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision. Springer, 131–147
2024
-
[40]
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. 2025. Thinking in space: How multimodal large language models see, 9 Tian et al. remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference. 10632–10643
2025
-
[41]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth Anything V2. arXiv:2406.09414 [cs.CV]
work page internal anchor Pith review arXiv 2024
- [42]
- [43]
-
[44]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InProceedings of the 11th International Conference on Learning Represen- tations
2023
- [45]
- [46]
-
[47]
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. 2024. LLaVA-NeXT: A Strong Zero-shot Video Understanding Model
2024
-
[48]
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. 2025. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630(2025)
work page internal anchor Pith review arXiv 2025
-
[49]
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, et al . 2025. Swift: a scalable lightweight infrastructure for fine-tuning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 29733–29735
2025
-
[50]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. 2025. DeepEyes: Incentivizing" Thinking with Images" via Reinforcement Learning.arXiv preprint arXiv:2505.14362(2025)
work page internal anchor Pith review arXiv 2025
- [51]
- [52]
-
[53]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. 2025. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479(2025). 10 LAST: Leveraging Tools as Hints to Enhance Spatial Reasoning for Multimodal Large Languag...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.