Recognition: 2 theorem links
· Lean TheoremSpatialForge: Bootstrapping 3D-Aware Spatial Reasoning from Open-World 2D Images
Pith reviewed 2026-05-13 01:22 UTC · model grok-4.3
The pith
A scalable pipeline turns ordinary 2D web images into 10 million spatial QA pairs that improve VLMs on depth ordering and layout tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
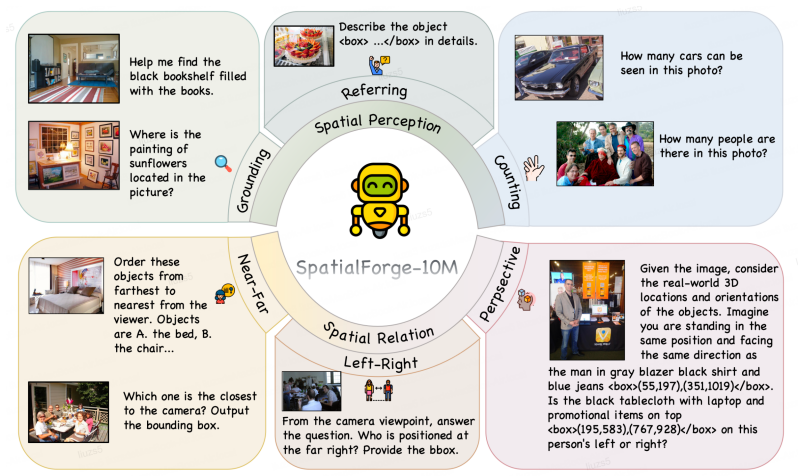
SpatialForge is a synthesis pipeline that decomposes spatial reasoning into perception and relation, then produces structured supervision covering depth, layout, and viewpoint-dependent reasoning from in-the-wild 2D images, together with automatic verification. The pipeline yields SpatialForge-10M containing 10 million spatial QA pairs. Training standard VLMs on this collection significantly raises their accuracy on spatial reasoning benchmarks.
What carries the argument
The decomposition of spatial reasoning into perception and relation, which lets the pipeline extract and verify depth, layout, and viewpoint signals directly from single 2D images.
If this is right
- VLMs trained on SpatialForge-10M perform better on concrete tasks such as depth ordering and precise coordinate grounding.
- The approach removes the scene-count bottleneck that limits existing scene-centric datasets.
- Training data volume and diversity can now approach the scale of ordinary web image collections.
- The same decomposition and verification steps can be reused to generate further spatial data without new 3D captures.
Where Pith is reading between the lines
- If the method works, similar automatic pipelines could extract structured supervision from 2D data for other reasoning skills where 3D ground truth is expensive.
- Models trained this way may acquire implicit geometry knowledge that transfers to open-world images never seen during synthesis.
- Larger versions of the dataset could be generated cheaply to test whether spatial gains continue to scale with data volume.
Load-bearing premise
The automatic verification step produces labels that match real-world 3D geometry without systematic errors introduced by the 2D-to-3D breakdown.
What would settle it
Compare the synthesized QA pairs against human-annotated or LiDAR ground-truth spatial labels on a held-out set of diverse images; low agreement rates would show the pipeline does not deliver faithful supervision.
Figures





read the original abstract
Recent advancements in Large Vision-Language Models (VLMs) have demonstrated exceptional semantic understanding, yet these models consistently struggle with spatial reasoning, often failing at fundamental geometric tasks such as depth ordering and precise coordinate grounding. Recent efforts introduce spatial supervision from scene-centric datasets (e.g., multi-view scans or indoor video), but are constrained by the limited number of underlying scenes. As a result, the scale and diversity of such data remain significantly smaller than those of web-scale 2D image collections. To address this limitation, we propose SpatialForge, a scalable data synthesis pipeline that transforms in-the-wild 2D images into spatial reasoning supervision. Our approach decomposes spatial reasoning into perception and relation, and constructs structured supervision signals covering depth, layout, and viewpoint-dependent reasoning, with automatic verification to ensure data quality. Based on this pipeline, we build SpatialForge-10M, a large-scale dataset containing 10 million spatial QA pairs. Extensive experiments across multiple spatial reasoning benchmarks demonstrate that training on SpatialForge-10M significantly improves the spatial reasoning ability of standard VLMs, highlighting the effectiveness of scaling 2D data for 3D-aware spatial reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SpatialForge, a data synthesis pipeline that decomposes open-world 2D images into perception (depth, layout) and relation signals to generate 10 million spatial QA pairs with automatic verification. It claims that fine-tuning standard VLMs on the resulting SpatialForge-10M dataset produces substantial gains on spatial reasoning benchmarks, showing that scaling 2D-derived supervision can bootstrap 3D-aware capabilities.
Significance. If the reported gains prove robust and attributable to genuine geometric supervision rather than shared estimator biases, the work would offer a practical route to web-scale spatial data that bypasses the scene-count limits of multi-view or indoor datasets. This could meaningfully advance VLM spatial reasoning without requiring new 3D capture infrastructure.
major comments (2)
- [§3.2] §3.2 (Automatic Verification): The verification module re-uses the same monocular depth and layout estimators employed in the initial decomposition. This internal loop risks confirming rather than detecting systematic biases such as depth-scale ambiguity or Manhattan-world assumptions; the manuscript provides no external validation (e.g., agreement with human-annotated 3D ground truth or multi-view consistency checks) on a held-out subset of the generated QA pairs.
- [§5] §5 (Experiments): While benchmark improvements are reported, the section lacks component ablations that isolate the contribution of the perception versus relation signals and contains no error analysis of cases where the automatic verifier may have accepted geometrically inconsistent labels. These omissions make it difficult to rule out that gains arise from data volume or estimator priors rather than veridical 3D reasoning.
minor comments (2)
- [Abstract] Abstract: The claim of 'significant' benchmark gains is stated without any numerical deltas, baselines, or dataset sizes; a one-sentence quantitative summary would improve readability.
- [Figure 3] Figure 3: The example QA pairs would benefit from an accompanying column showing the original image and the decomposed depth/layout maps to allow readers to assess label fidelity directly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the verification pipeline and experimental analysis. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Automatic Verification): The verification module re-uses the same monocular depth and layout estimators employed in the initial decomposition. This internal loop risks confirming rather than detecting systematic biases such as depth-scale ambiguity or Manhattan-world assumptions; the manuscript provides no external validation (e.g., agreement with human-annotated 3D ground truth or multi-view consistency checks) on a held-out subset of the generated QA pairs.
Authors: We agree that reusing the same estimators creates a risk of internal bias confirmation rather than independent validation. While §3.2 applies cross-consistency checks across depth, layout, and relation signals to filter inconsistent pairs, this does not fully address estimator-specific issues like scale ambiguity. In the revised manuscript we will add external validation via a human study on a held-out subset of 500 QA pairs, where annotators assess geometric accuracy against the source images and report agreement statistics along with remaining failure modes. revision: yes
-
Referee: [§5] §5 (Experiments): While benchmark improvements are reported, the section lacks component ablations that isolate the contribution of the perception versus relation signals and contains no error analysis of cases where the automatic verifier may have accepted geometrically inconsistent labels. These omissions make it difficult to rule out that gains arise from data volume or estimator priors rather than veridical 3D reasoning.
Authors: We acknowledge that the current experiments do not fully isolate the contributions of perception versus relation signals or analyze verifier errors. In the revised §5 we will add component ablations (perception-only, relation-only, and combined training) and an error analysis section that samples verifier-accepted pairs with potential inconsistencies, quantifies their frequency, and measures their effect on benchmark scores. These additions will help attribute gains more precisely to the spatial supervision. revision: yes
Circularity Check
No circularity: empirical gains from generated dataset are measured on external benchmarks
full rationale
The paper describes a data-synthesis pipeline that decomposes 2D images into perception/relation signals, applies automatic verification, produces SpatialForge-10M QA pairs, and then reports measured improvements when VLMs are trained on this data and evaluated on separate spatial-reasoning benchmarks. No equations, fitted parameters, or self-citations are shown to reduce the reported performance gains to a tautology or to the pipeline's own inputs by construction. The verification step is an internal quality filter whose correctness is an empirical assumption, not a definitional identity that forces the downstream benchmark scores. The central claim therefore remains externally falsifiable and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Spatial reasoning decomposes into independent perception and relation components that can be supervised separately from 2D images
- domain assumption Automatic verification produces labels whose quality is comparable to human annotation for training purposes
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach decomposes spatial reasoning into perception and relation, and constructs structured supervision signals covering depth, layout, and viewpoint-dependent reasoning, with automatic verification to ensure data quality.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we employ a monocular depth estimator to predict a dense depth map D
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[2]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9568–9578, 2024
work page 2024
-
[5]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
work page 2025
-
[6]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
work page 2023
-
[7]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Keshigeyan Chandrasegaran, Agrim Gupta, Lea M Hadzic, Taran Kota, Jimming He, Cristóbal Eyzaguirre, Zane Durante, Manling Li, Jiajun Wu, and Li Fei-Fei. Hourvideo: 1-hour video- language understanding.Advances in Neural Information Processing Systems, 37:53168–53197, 2024
work page 2024
-
[9]
arXiv preprint arXiv:2505.23747 (2025)
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025
-
[10]
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progressive training for spatial reasoning in vision-language models.arXiv preprint arXiv:2510.08531, 2025
-
[11]
arXiv preprint arXiv:2503.22976 (2025)
Jiahui Zhang, Yurui Chen, Yanpeng Zhou, Yueming Xu, Ze Huang, Jilin Mei, Junhui Chen, Yu- Jie Yuan, Xinyue Cai, Guowei Huang, et al. From flatland to space: Teaching vision-language models to perceive and reason in 3d.arXiv preprint arXiv:2503.22976, 2025
-
[12]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9490–9498. IEEE, 2025
work page 2025
-
[13]
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494, 2023
work page 2023
-
[14]
Shapellm: Universal 3d object understanding for embodied interaction
Zekun Qi, Runpei Dong, Shaochen Zhang, Haoran Geng, Chunrui Han, Zheng Ge, Li Yi, and Kaisheng Ma. Shapellm: Universal 3d object understanding for embodied interaction. In European Conference on Computer Vision, pages 214–238. Springer, 2024
work page 2024
-
[15]
Llava-3d: A simple yet effective pathway to empowering lmms with 3d-awareness, 2025
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. Llava-3d: A simple yet effective pathway to empowering lmms with 3d-awareness, 2025
work page 2025
-
[16]
Nianchen Deng, Lixin Gu, Shenglong Ye, Yinan He, Zhe Chen, Songze Li, Haomin Wang, Xingguang Wei, Tianshuo Yang, Min Dou, et al. Internspatial: A comprehensive dataset for spatial reasoning in vision-language models.arXiv preprint arXiv:2506.18385, 2025. 10
-
[17]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
work page 2017
-
[18]
Scannet++: A high- fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high- fidelity dataset of 3d indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
work page 2023
-
[19]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
work page 2024
-
[20]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021
work page 2021
-
[21]
Ling Fu, Zhebin Kuang, Jiajun Song, Mingxin Huang, Biao Yang, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, et al. Ocrbench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning.arXiv preprint arXiv:2501.00321, 2024
-
[22]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
work page 2024
-
[23]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models.arXiv preprint arXiv:2506.03135, 2025
-
[26]
Spatial mental modeling from limited views
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, et al. Spatial mental modeling from limited views. InStructural Priors for Vision Workshop at ICCV’25, 2025
work page 2025
-
[27]
Pointllm: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision, pages 131–147. Springer, 2024
work page 2024
-
[28]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems, 37:135062–135093, 2024
work page 2024
-
[29]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
work page 2024
-
[30]
arXiv preprint arXiv:2504.01805 (2025)
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
-
[31]
Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhanguang Zhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, et al. Spatialcot: Advancing spatial reasoning through coordinate alignment and chain-of-thought for embodied task planning.arXiv preprint arXiv:2501.10074, 2025. 11
-
[32]
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vuli ´c, and Furu Wei. Imagine while reasoning in space: Multimodal visualization-of-thought.arXiv preprint arXiv:2501.07542, 2025
-
[33]
LAST: Leveraging Tools as Hints to Enhance Spatial Reasoning for Multimodal Large Language Models
Shi-Yu Tian, Zhi Zhou, Kun-Yang Yu, Ming Yang, Yang Chen, Ziqiao Shang, Lan-Zhe Guo, and Yu-Feng Li. Last: Leveraging tools as hints to enhance spatial reasoning for multimodal large language models.arXiv preprint arXiv:2604.09712, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF international conference on computer vision, pages 11888–11898, 2023
work page 2023
-
[35]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Haotian Zhang, Haoxuan You, Philipp Dufter, Bowen Zhang, Chen Chen, Hong-You Chen, Tsu- Jui Fu, William Yang Wang, Shih-Fu Chang, Zhe Gan, et al. Ferret-v2: An improved baseline for referring and grounding with large language models.arXiv preprint arXiv:2404.07973, 2024
-
[37]
Learning to localize objects improves spatial reasoning in visual-llms
Kanchana Ranasinghe, Satya Narayan Shukla, Omid Poursaeed, Michael S Ryoo, and Tsung-Yu Lin. Learning to localize objects improves spatial reasoning in visual-llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12977–12987, 2024
work page 2024
-
[38]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Is a picture worth a thousand words? delving into spatial reasoning for vision language models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Yixuan Li, and Neel Joshi. Is a picture worth a thousand words? delving into spatial reasoning for vision language models. Advances in Neural Information Processing Systems, 37:75392–75421, 2024
work page 2024
-
[40]
Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15768– 15780, 2025
work page 2025
-
[41]
Jianing Li, Xi Nan, Ming Lu, Li Du, and Shanghang Zhang. Proximity qa: Unleashing the power of multi-modal large language models for spatial proximity analysis.arXiv preprint arXiv:2401.17862, 2024
-
[42]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[43]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024
work page 2024
-
[44]
Depth anything v2.Advances in Neural Information Processing Systems, 37:21875– 21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37:21875– 21911, 2024
work page 2024
-
[45]
Objects365: A large-scale, high-quality dataset for object detection
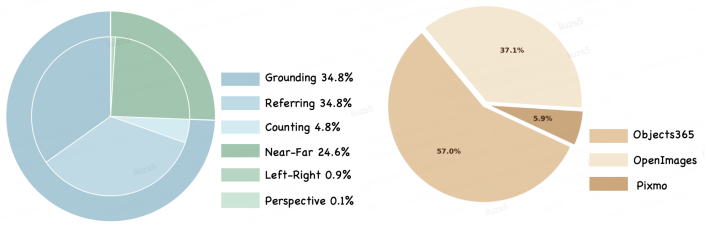
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 8430–8439, 2019. 12
work page 2019
-
[46]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.International journal of computer vision, 128(7):1956–1981, 2020
work page 1956
-
[47]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 91–104, 2025
work page 2025
-
[48]
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai C Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
work page 2024
-
[49]
Ziyang Gong, Wenhao Li, Olivera Martínez Ma, Songyuan Li, Jiayi Ji, Xue Yang, Gen Luo, Junchi Yan, and Rongrong Ji. Space-10: A comprehensive benchmark for multimodal large language models in compositional spatial intelligence.ArXiv, abs/2506.07966, 2025
-
[50]
The claude 3 model family: Opus, sonnet, haiku
Anthropic. The claude 3 model family: Opus, sonnet, haiku. Model card, Anthropic, 2024
work page 2024
-
[51]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[52]
Mantis: Interleaved multi-image instruction tuning
Dongfu Jiang, Xuan He, Huaye Zeng, Con Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning.arXiv preprint arXiv:2405.01483, 2024. 13 6 Task Taxonomy In this section, we provide a detailed breakdown of the spatial task taxonomy used in our dataset. We organize spatial reasoning into multiple capability levels and defin...
-
[53]
Gender or age group, such as man, woman, elderly man, young girl, or boy
-
[55]
Facing direction, such as facing camera, facing left, back to camera, or profile view
-
[56]
Upper body clothing, including color and garment type, such as white shirt, red hoodie, or blue suit jacket
-
[57]
Lower body clothing if visible, such as black jeans or grey skirt
-
[58]
Woman facing camera wearing red blouse and blue jeans, sunglasses in the foreground
One prominent accessory or feature if notable, such as hat, glasses, backpack, or long hair. Example outputs: “Woman facing camera wearing red blouse and blue jeans, sunglasses in the foreground” “Elderly man back to camera in grey coat and dark trousers, on the left” “Young boy in the background, in yellow t-shirt, facing left” Object Region: If the obje...
-
[59]
Object name, using the provided object hint
-
[60]
Position in the image, using spatial terms such as left, right, center, front, back, top, bottom, foreground, or background
-
[61]
Dominant color or visible pattern
-
[62]
Material, such as metal, wood, plastic, fabric, glass, or ceramic, when distinguishable
-
[63]
Shape, size, or quantity if notable, such as long, round, small, or a pair of
-
[64]
Red plastic bottle with white screw cap, cylindrical, located on the right side
One distinctive feature or state, such as open, broken, stacked, or worn. Example outputs: “Red plastic bottle with white screw cap, cylindrical, located on the right side” “Wooden chair with blue fabric cushion, four legs, positioned in the center foreground” “Silver metal fork, long thin handle, placed on the left side of the image” “Stack of white cera...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.