Recognition: unknown
Agentic Compilation: Mitigating the LLM Rerun Crisis for Minimized-Inference-Cost Web Automation
Pith reviewed 2026-05-10 17:39 UTC · model grok-4.3
The pith
A single LLM call on sanitized browser state can compile web tasks into reusable JSON blueprints that a lightweight runtime executes without further model queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
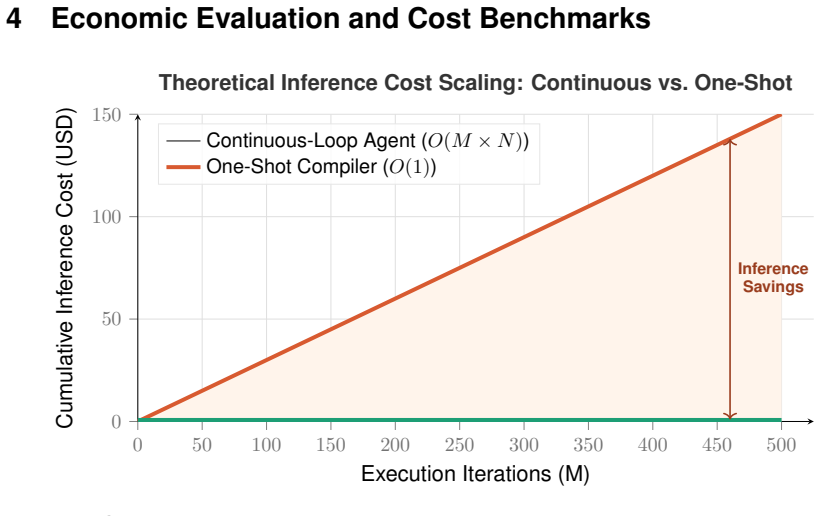
The central claim is that LLM-driven web agents can be restructured as a compile-and-execute system in which a one-shot model invocation on a sanitized DOM representation emits a deterministic JSON workflow blueprint; a lightweight runtime then executes that blueprint across arbitrary numbers of iterations without additional model calls, reducing per-workflow inference cost to under 0.10 USD and formalizing the improvement as a move from O(M x N) to amortized O(1) scaling.
What carries the argument
The Compile-and-Execute architecture, which uses one LLM call on a token-efficient semantic representation from the DOM Sanitization Module to emit a deterministic JSON workflow blueprint that a model-free runtime executes repeatedly.
Load-bearing premise
A single LLM call on the sanitized DOM representation will reliably emit a correct and deterministic JSON workflow blueprint that the runtime can execute without any further model intervention.
What would settle it
Execute the compiled JSON blueprint for several hundred iterations on target sites and measure whether every step completes correctly without triggering additional LLM queries or errors.
Figures



read the original abstract
LLM-driven web agents operating through continuous inference loops -- repeatedly querying a model to evaluate browser state and select actions -- exhibit a fundamental scalability constraint for repetitive tasks. We characterize this as the Rerun Crisis: the linear growth of token expenditure and API latency relative to execution frequency. For a 5-step workflow over 500 iterations, a continuous agent incurs approximately 150.00 USD in inference costs; even with aggressive caching, this remains near 15.00 USD. We propose a Compile-and-Execute architecture that decouples LLM reasoning from browser execution, reducing per-workflow inference cost to under 0.10 USD. A one-shot LLM invocation processes a token-efficient semantic representation from a DOM Sanitization Module (DSM) and emits a deterministic JSON workflow blueprint. A lightweight runtime then drives the browser without further model queries. We formalize this cost reduction from O(M x N) to amortized O(1) inference scaling, where M is the number of reruns and N is the sequential actions. Empirical evaluation across data extraction, form filling, and fingerprinting tasks yields zero-shot compilation success rates of 80-94%. Crucially, the modularity of the JSON intermediate representation allows minimal Human-in-the-Loop (HITL) patching to elevate execution reliability to near-100%. At per-compilation costs between 0.002 USD and 0.092 USD across five frontier models, these results establish deterministic compilation as a paradigm enabling economically viable automation at scales previously infeasible under continuous architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript characterizes the 'Rerun Crisis' in continuous LLM web agents, where per-action inference causes linear cost growth (O(M × N)) for repetitive workflows. It proposes a Compile-and-Execute architecture with a DOM Sanitization Module (DSM) that feeds a token-efficient representation to a single LLM call, producing a deterministic JSON workflow blueprint executed by a lightweight runtime with no further model queries. This is claimed to reduce per-workflow inference cost to under 0.10 USD and amortize to O(1) scaling. Empirical results across data extraction, form filling, and fingerprinting tasks report 80-94% zero-shot compilation success, with modularity enabling minimal HITL patching to reach near-100% reliability; per-compilation costs range from 0.002-0.092 USD across five frontier models.
Significance. If the central claims hold under detailed validation, the work would offer a meaningful contribution to scalable LLM agent deployment by decoupling reasoning from execution via a reusable intermediate representation. The formal cost scaling argument and the explicit support for lightweight patching are constructive elements that could influence practical system design for repetitive web tasks.
major comments (3)
- [Abstract] Abstract: The 80-94% zero-shot success rates and associated cost figures (under 0.10 USD per workflow) are reported without any description of experimental setup, task definitions, number of trials, baselines (e.g., continuous agents or caching variants), or statistical measures such as error bars or variance. This is load-bearing for the central claims because the amortized O(1) scaling and economic viability assertions rest directly on these results being representative.
- [Cost formalization] Cost formalization (throughout the architecture and evaluation discussion): The reduction from O(M × N) to amortized O(1) is asserted without a quantitative model or bounds on recompilation frequency. The 6-20% failure rate already implies that some fraction of workflows will require re-inference or patching; absent analysis of how often dynamic site changes, anti-bot measures, or unmodeled branches trigger this, the amortized claim cannot be secured for long-running repetitive workloads.
- [Architecture description] Architecture description: The weakest assumption—that a single LLM call on the DSM output will reliably emit a correct, deterministic JSON blueprint executable without further intervention—is supported only by the aggregate success rates. No breakdown is provided by task type, site dynamism, or failure modes (e.g., JavaScript-heavy pages or state-dependent branches), leaving the determinism claim unverified at the level required for the no-further-model-calls guarantee.
minor comments (2)
- [Abstract] The abstract states costs 'between 0.002 USD and 0.092 USD across five frontier models' but does not name the models or the exact prompt/DOM sizes used; adding this would improve reproducibility without altering the core argument.
- Notation for the scaling (O(M × N) vs. amortized O(1)) is introduced without an accompanying equation or small example that shows how M (reruns) and N (actions) map to the compiled case; a short illustrative calculation would clarify the formalization.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas for strengthening the presentation of our empirical results and formal arguments. We respond to each major comment below and commit to revisions that address the concerns while preserving the core contributions of the Compile-and-Execute architecture.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 80-94% zero-shot success rates and associated cost figures (under 0.10 USD per workflow) are reported without any description of experimental setup, task definitions, number of trials, baselines (e.g., continuous agents or caching variants), or statistical measures such as error bars or variance. This is load-bearing for the central claims because the amortized O(1) scaling and economic viability assertions rest directly on these results being representative.
Authors: We agree that the abstract should be more self-contained to support the reported figures. In the revised manuscript, we will expand the abstract with a concise description of the task categories (data extraction, form filling, fingerprinting), the zero-shot compilation protocol, the number of trials per task, and a cross-reference to the full experimental setup, baselines (including continuous-agent and caching comparisons), and variance measures in Section 4. This will make the load-bearing results more transparent without exceeding typical abstract length limits. revision: yes
-
Referee: [Cost formalization] Cost formalization (throughout the architecture and evaluation discussion): The reduction from O(M × N) to amortized O(1) is asserted without a quantitative model or bounds on recompilation frequency. The 6-20% failure rate already implies that some fraction of workflows will require re-inference or patching; absent analysis of how often dynamic site changes, anti-bot measures, or unmodeled branches trigger this, the amortized claim cannot be secured for long-running repetitive workloads.
Authors: The referee correctly notes that the amortized O(1) claim requires explicit bounds and analysis of recompilation frequency. While the manuscript formalizes the one-time compilation versus per-action inference, it does not quantify expected recompilation triggers for long-running workloads. We will add a new subsection with an empirical model of recompilation rates drawn from our experiments, sensitivity analysis under varying failure rates (including site dynamism and anti-bot effects), and projected amortized costs for 100+ iterations. This will rigorously secure the scaling argument. revision: yes
-
Referee: [Architecture description] Architecture description: The weakest assumption—that a single LLM call on the DSM output will reliably emit a correct, deterministic JSON blueprint executable without further intervention—is supported only by the aggregate success rates. No breakdown is provided by task type, site dynamism, or failure modes (e.g., JavaScript-heavy pages or state-dependent branches), leaving the determinism claim unverified at the level required for the no-further-model-calls guarantee.
Authors: We acknowledge that aggregate success rates alone are insufficient to fully verify the determinism guarantee. The JSON blueprint is executed deterministically by the runtime with no further LLM calls once compilation succeeds; the 80-94% figure reflects zero-shot compilation reliability. We will revise the architecture and evaluation sections to include a per-task-type breakdown (e.g., success on static vs. JS-heavy pages), categorization of observed failure modes (including state-dependent branches), and explicit discussion of how the DSM and modular JSON representation enable the no-further-model-calls property. This will provide the required granular verification. revision: yes
Circularity Check
No circularity: cost scaling follows directly from proposed architecture
full rationale
The paper presents a Compile-and-Execute design that uses one LLM call to produce a JSON blueprint, after which a lightweight runtime executes without further model queries. The O(M×N) to amortized O(1) formalization is a direct consequence of this decoupling, not a fitted parameter or self-referential equation. Empirical zero-shot success rates (80-94%) and per-compilation costs are reported as measurements, not predictions derived from the same inputs. No self-citations, uniqueness theorems, or ansatzes appear in the load-bearing steps. The architecture is self-contained as a new proposal validated against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can reliably translate a token-efficient semantic DOM representation into a correct deterministic JSON workflow blueprint in a single forward pass.
- domain assumption A lightweight runtime can execute the emitted JSON blueprint on a live browser without additional LLM queries or state feedback loops.
invented entities (2)
-
DOM Sanitization Module (DSM)
no independent evidence
-
JSON workflow blueprint
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chen, M., T worek, J., Jun, H., Y uan, Q., Pinto, H. P . d. O., Kaplan, J., et al. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [2]
-
[3]
V ., & Zhou, D
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F ., Chi, E., Le, Q. V ., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837
2022
- [4]
-
[5]
Y ao, S., Zhao, J., Y u, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y . (2022). ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [6]
-
[7]
Zheng, Y ., et al. (2024). Agent Workflow Memory .arXiv preprint arXiv:2409.07429. 12
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.