Recognition: unknown
Toward Explanatory Equilibrium: Verifiable Reasoning as a Coordination Mechanism under Asymmetric Information
Pith reviewed 2026-05-10 15:46 UTC · model grok-4.3
The pith
Structured reasoning artifacts let LLM agents coordinate under asymmetric information without welfare collapse from silence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
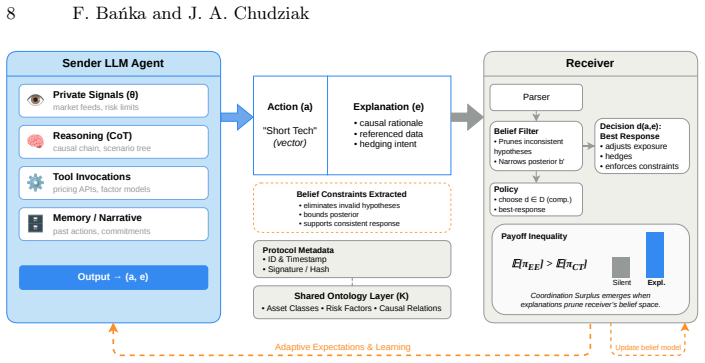
Explanatory Equilibrium is a design principle for explanation-aware multi-agent systems in which agents exchange structured reasoning artifacts consisting of auditable claims paired with concise text, while receivers apply bounded verification through probabilistic audits under explicit resource constraints. This mechanism links audit intensity, misreporting incentives, and reasoning costs. In a finance-inspired LLM setting with a Trader and a Risk Manager, auditable artifacts prevent the cost of silence driven by conservative validation under asymmetric information, unlocking coordination while maintaining consistently low bad-approval rates across audit intensities, audit budgets, and thep
What carries the argument
Explanatory Equilibrium: a coordination mechanism in which agents externalize reasoning as auditable claims with concise text, verified by receivers through probabilistic audits under explicit resource constraints.
If this is right
- Structured reasoning unlocks coordination in ambiguous proposals while keeping bad-approval rates low.
- Without structured claims, approval and welfare collapse under conservative validation.
- Low bad-approval rates hold across audit intensities, budgets, and incentive regimes.
- Scalable, safety-preserving coordination depends on externalizing reasoning into partially verifiable artifacts.
Where Pith is reading between the lines
- The approach could extend beyond finance to other domains with uncertain multi-agent decisions.
- Systems may need built-in incentives to ensure agents produce high-quality structured artifacts.
- Combining this with automated verification could further lower audit resource costs.
Load-bearing premise
Agents will reliably produce and exchange structured reasoning artifacts rather than defaulting to silence or unverified text, and receivers can apply bounded probabilistic audits effectively without the audits becoming prohibitively expensive or ineffective.
What would settle it
In the Trader-Risk Manager LLM simulation, compare approval rates and welfare when structured reasoning artifacts are required versus when they are absent, and check whether approvals and welfare collapse in the absent case while bad-approval rates remain controlled when artifacts are present.
Figures



read the original abstract
LLM-based agents increasingly coordinate decisions in multi-agent systems, often attaching natural-language reasoning to actions. However, reasoning is neither free nor automatically reliable: it incurs computational cost and, without verification, may degenerate into persuasive cheap talk. We introduce Explanatory Equilibrium as a design principle for explanation-aware multi-agent systems and study a regime in which agents exchange structured reasoning artifacts-auditable claims paired with concise text-while receivers apply bounded verification through probabilistic audits under explicit resource constraints. We contribute (i) a minimal mechanism-level exchange-audit model linking audit intensity, misreporting incentives, and reasoning costs, and (ii) empirical evidence from a finance-inspired LLM setting involving a Trader and a Risk Manager. In ambiguous, borderline proposals, auditable artifacts prevent the cost of silence driven by conservative validation under asymmetric information: without structured claims, approval and welfare collapse. By contrast, structured reasoning unlocks coordination while maintaining consistently low bad-approval rates across audit intensities, audit budgets, and incentive regimes. Our results suggest that scalable, safety-preserving coordination in LLM-based multi-agent systems depends not only on audit strength, but more fundamentally on disciplined externalization of reasoning into partially verifiable artifacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Explanatory Equilibrium as a design principle for LLM-based multi-agent systems. Agents exchange structured reasoning artifacts (auditable claims paired with concise text) while receivers perform bounded probabilistic audits under explicit resource constraints. It contributes a minimal exchange-audit model that links audit intensity to misreporting incentives and reasoning costs, plus empirical evidence from a finance-inspired Trader-Risk Manager scenario. The central result is that, in ambiguous borderline proposals, these artifacts prevent welfare collapse from conservative validation under asymmetric information, whereas unstructured approaches lead to approval and welfare collapse; structured reasoning maintains consistently low bad-approval rates across audit intensities, budgets, and incentive regimes.
Significance. If the model and results hold, the work is significant for multi-agent systems research because it shifts focus from audit strength alone to the externalization of reasoning into partially verifiable artifacts as a coordination mechanism. The minimal model provides a clean mechanism-level link between incentives and verification costs, and the empirical demonstration of robustness across regimes offers a concrete, falsifiable prediction for LLM coordination. Credit is due for the disciplined framing of the problem and the attempt to ground the claims in a finance-inspired simulation rather than purely theoretical analysis.
major comments (2)
- [§3] §3 (exchange-audit model): the audit success probability on structured claims is never given an explicit functional form, calibration against LLM generation noise, or sensitivity analysis; because the central claim of consistently low bad-approval rates across regimes rests on this quantity, the reported coordination benefit cannot be evaluated for robustness.
- [§4] §4 (empirical evaluation): no parameter values, number of trials, statistical tests, or measurement protocol for bad-approval rates are reported, leaving open whether the low rates are an artifact of the simulation assumptions rather than a general property of the mechanism.
minor comments (2)
- Notation for the audit intensity and reasoning cost parameters is introduced without a consolidated table of symbols, which would aid readability.
- [Abstract and §3] The abstract's claim of 'parameter-free' aspects of the model is not repeated or justified in the main text; clarify whether any quantities are derived without fitting.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important gaps in model specification and empirical reporting that we will address in revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [§3] §3 (exchange-audit model): the audit success probability on structured claims is never given an explicit functional form, calibration against LLM generation noise, or sensitivity analysis; because the central claim of consistently low bad-approval rates across regimes rests on this quantity, the reported coordination benefit cannot be evaluated for robustness.
Authors: We agree that an explicit functional form for audit success probability is required to substantiate robustness claims. In the revised §3 we will introduce p(success | claim, noise) = 1 - (1 - precision) * exp(-budget / cost) calibrated to published LLM error rates on factual claims, and we will add a sensitivity analysis sweeping noise levels from 0.05 to 0.30 while holding other parameters fixed. This will directly test whether the reported coordination benefit persists under varying verification reliability. revision: yes
-
Referee: [§4] §4 (empirical evaluation): no parameter values, number of trials, statistical tests, or measurement protocol for bad-approval rates are reported, leaving open whether the low rates are an artifact of the simulation assumptions rather than a general property of the mechanism.
Authors: The referee is correct that the current §4 omits these details. We will expand the section to report: all parameter values (audit intensity grid, reasoning cost coefficients, incentive multipliers), number of Monte Carlo trials per condition (1000), statistical tests (two-sided t-tests with Bonferroni correction for welfare and approval-rate differences), and the exact measurement protocol (bad-approval defined as approval of a proposal whose expected value is negative under full information, computed from ground-truth labels). We will also include 95% confidence intervals and additional robustness sweeps over simulation seeds. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines a minimal exchange-audit model linking audit intensity, misreporting incentives, and reasoning costs, then reports empirical outcomes from an LLM-based Trader-Risk Manager simulation. No equations, predictions, or central claims reduce by construction to fitted parameters, self-definitions, or unverified self-citations. The coordination benefits and low bad-approval rates are presented as simulation results under varying regimes rather than tautological outputs. The model assumptions (e.g., agents producing structured artifacts) are explicit and not derived from the target results themselves.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reasoning incurs computational cost and is not automatically reliable without verification.
- domain assumption Receivers apply bounded verification through probabilistic audits under explicit resource constraints.
invented entities (1)
-
Explanatory Equilibrium
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Quarterly Journal of Economics84(3), 488–500 (1970)
Akerlof, G.A.: The market for “lemons”: Quality uncertainty and the market mech- anism. The Quarterly Journal of Economics84(3), 488–500 (1970)
1970
-
[2]
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J., Mané, D.: Concrete problems in ai safety (2016)
2016
-
[3]
Arrow, K.J.: The Limits of Organization. W.W. Norton & Company (1974)
1974
-
[4]
In: Recent Challenges in Intelligent Information and Database Systems
Bańka, F., Chudziak, J.A.: Options pricing platform with neural networks, llms and reinforcement learning. In: Recent Challenges in Intelligent Information and Database Systems. pp. 202–216. Springer Nature Singapore (2025)
2025
-
[5]
Information fusion58, 82–115 (2020), https://doi.org/10.1016/j.inffus.2019.12.012
Barredo Arrieta, A., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., García, S., Gil-López, S., Molina, D., Benjamins, R., Chatila, R., Herrera, F.: Explainable artificial intelligence (XAI): Concepts, taxonomies, op- portunities and challenges toward responsible AI. Information Fusion58, 82–115 (2020),https://doi.org/10.1016/j.inff...
-
[6]
In: PACIS 2025 Proceedings
Bańka, F., Chudziak, J.A.: Deltahedge: A multi-agent framework for portfolio options optimization. In: PACIS 2025 Proceedings. No. 25 (2025)
2025
-
[7]
Econometrica: Journal of the Econometric Society pp
Crawford, V.P., Sobel, J.: Strategic information transmission. Econometrica: Journal of the Econometric Society pp. 1431–1451 (1982)
1982
-
[8]
Danilevsky, M., Qian, K., Aharonov, R., Katsis, Y., Kawas, B., Sen, P.: A survey of the state of explainable AI for natural language processing (2020)
2020
-
[9]
Business & Information Systems Engineering61(5), 637–643 (2019),https://doi.org/10
Dellermann, D., Ebel, P., Söllner, M., Leimeister, J.M.: Hybrid intelligence. Business & Information Systems Engineering61(5), 637–643 (2019),https://doi.org/10. 1007/s12599-019-00595-2
2019
-
[10]
Doshi-Velez, F., Kim, B.: Towards a rigorous science of interpretable machine learning (2017)
2017
-
[11]
MIT Press (1991)
Fudenberg, D., Tirole, J.: Game theory. MIT Press (1991)
1991
-
[12]
MIT Sloan Working Paper (2020)
Gensler, G., Bailey, L.: Deep learning and financial stability. MIT Sloan Working Paper (2020)
2020
-
[13]
The Journal of Law and Economics24(3), 461–483 (1981)
Grossman, S.J.: The informational role of warranties and private disclosure about product quality. The Journal of Law and Economics24(3), 461–483 (1981)
1981
-
[14]
ACM Computing Surveys 51(5), 1–42 (2018)
Guidotti, R., Monreale, A., Ruggieri, S., Turini, F., Pedreschi, D., Giannotti, F.: A survey of methods for explaining black box models. ACM Computing Surveys 51(5), 1–42 (2018)
2018
-
[15]
Hagendorff, T.: Machine psychology: Investigating emergent capabilities and behav- ior in large language models using psychological methods (2023)
2023
-
[16]
Bańka and J
Hendrycks, D., Carlini, N., Schulman, J., Steinhardt, J.: Unsolved problems in ml safety (2021) 18 F. Bańka and J. A. Chudziak
2021
-
[17]
American Economic Review 101(6), 2590–2615 (2011)
Kamenica, E., Gentzkow, M.: Bayesian persuasion. American Economic Review 101(6), 2590–2615 (2011)
2011
-
[18]
Kostka, A., Chudziak, J.A.: Towards cognitive synergy in llm-based multi-agent systems: Integrating theory of mind and critical evaluation (2025)
2025
-
[19]
Artificial Intel- ligence94(1), 79–97 (1997),https://doi.org/10.1016/S0004-3702(97)00025-8
Kraus, S.: Negotiation and cooperation in multi-agent environments. Artificial Intel- ligence94(1), 79–97 (1997),https://doi.org/10.1016/S0004-3702(97)00025-8
-
[20]
Journal of Eco- nomic Theory27(2), 253–279 (1982)
Kreps, D.M., Wilson, R.: Reputation and imperfect information. Journal of Eco- nomic Theory27(2), 253–279 (1982)
1982
-
[21]
Queue16(3), 31–57 (2018)
Lipton, Z.C.: The mythos of model interpretability. Queue16(3), 31–57 (2018)
2018
-
[22]
Artificial Intelligence267, 1–38 (2019)
Miller, T.: Explanation in artificial intelligence: Insights from the social sciences. Artificial Intelligence267, 1–38 (2019)
2019
-
[23]
Journal of Economic Perspectives31(2), 87–106 (2017)
Mullainathan, S., Spiess, J.: Machine learning: An applied econometric approach. Journal of Economic Perspectives31(2), 87–106 (2017)
2017
-
[24]
Cam- bridge University Press (1990)
North, D.C.: Institutions, Institutional Change and Economic Performance. Cam- bridge University Press (1990)
1990
-
[25]
Cambridge University Press (1990)
Ostrom, E.: Governing the Commons: The Evolution of Institutions for Collective Action. Cambridge University Press (1990)
1990
-
[26]
In: Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology
Park, J.S., O’Brien, J.C., Cai, C.J., Morris, M.R., Liang, P., Bernstein, M.S.: Generative agents: Interactive simulacra of human behavior. In: Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. pp. 1–22. ACM (2023)
2023
-
[27]
Viking (2019)
Russell, S.: Human Compatible: Artificial Intelligence and the Problem of Control. Viking (2019)
2019
-
[28]
In: Proceedings of the 34th ACM International Conference on Information and Knowledge Management
Sadowski, A., Chudziak, J.A.: On verifiable legal reasoning: A multi-agent framework with formalized knowledge representations. In: Proceedings of the 34th ACM International Conference on Information and Knowledge Management. p. 2535–2545. CIKM ’25, Association for Computing Machinery, New York, NY, USA (2025). https://doi.org/10.1145/3746252.3761057
-
[29]
(eds.): Explain- able AI: Interpreting, Explaining and Visualizing Deep Learning, Lecture Notes in Computer Science, vol
Samek, W., Montavon, G., Vedalli, A., Hansen, L.K., Müller, K.R. (eds.): Explain- able AI: Interpreting, Explaining and Visualizing Deep Learning, Lecture Notes in Computer Science, vol. 11700. Springer (2019)
2019
-
[30]
Cambridge University Press (2008)
Shoham, Y., Leyton-Brown, K.: Multiagent systems: Algorithmic, game-theoretic, and logical foundations. Cambridge University Press (2008)
2008
-
[31]
2009.Argumentation in Artificial Intelligence
Simari, G., Rahwan, I.: Argumentation in Artificial Intelligence. Springer Science & Business Media (2009),https://doi.org/10.1007/978-0-387-98197-0
-
[32]
The Quarterly Journal of Economics69(1), 99–118 (1955)
Simon, H.A.: A behavioral model of rational choice. The Quarterly Journal of Economics69(1), 99–118 (1955)
1955
-
[33]
The Quarterly Journal of Economics87(3), 355–374 (1973)
Spence, M.: Job market signaling. The Quarterly Journal of Economics87(3), 355–374 (1973)
1973
-
[34]
A Survey on Large Language Model based Autonomous Agents
Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., Chen, Z., Tang, J., Chen, X., Lin, Y., Zhao, W.X., Wei, Z., Wen, J.R.: A survey on large language model based autonomous agents. arXiv preprint arXiv:2308.11432 (2023)
work page internal anchor Pith review arXiv 2023
-
[35]
Xiao, Y., Sun, E., Luo, D., Wang, W.: Tradingagents: Multi-agents llm financial trading framework (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.