Recognition: 2 theorem links
· Lean TheoremYUV20K: A Complexity-Driven Benchmark and Trajectory-Aware Alignment Model for Video Camouflaged Object Detection
Pith reviewed 2026-05-10 16:40 UTC · model grok-4.3
The pith
A new 24K-frame benchmark and two-module framework improve video camouflaged object detection under erratic motion and camera movement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that Motion Feature Stabilization via frame-agnostic Semantic Basis Primitives combined with Trajectory-Aware Alignment via trajectory-guided deformable sampling resolves Motion-Induced Appearance Instability and Temporal Feature Misalignment, yielding higher accuracy than prior methods on both legacy VCOD benchmarks and the new YUV20K dataset while improving generalization across domains.
What carries the argument
Motion Feature Stabilization (MFS) module using frame-agnostic Semantic Basis Primitives and Trajectory-Aware Alignment (TAA) module using trajectory-guided deformable sampling, which together stabilize features against erratic motion and enforce precise temporal correspondence.
Load-bearing premise
The assumption that the internal designs of the Motion Feature Stabilization and Trajectory-Aware Alignment modules actually eliminate the stated motion and alignment problems rather than merely fitting the chosen test sets.
What would settle it
A controlled experiment in which the proposed model is run on YUV20K sequences containing only the targeted large-displacement and camera-motion cases and fails to exceed the best prior method's F-measure or mean absolute error by a statistically significant margin.
Figures





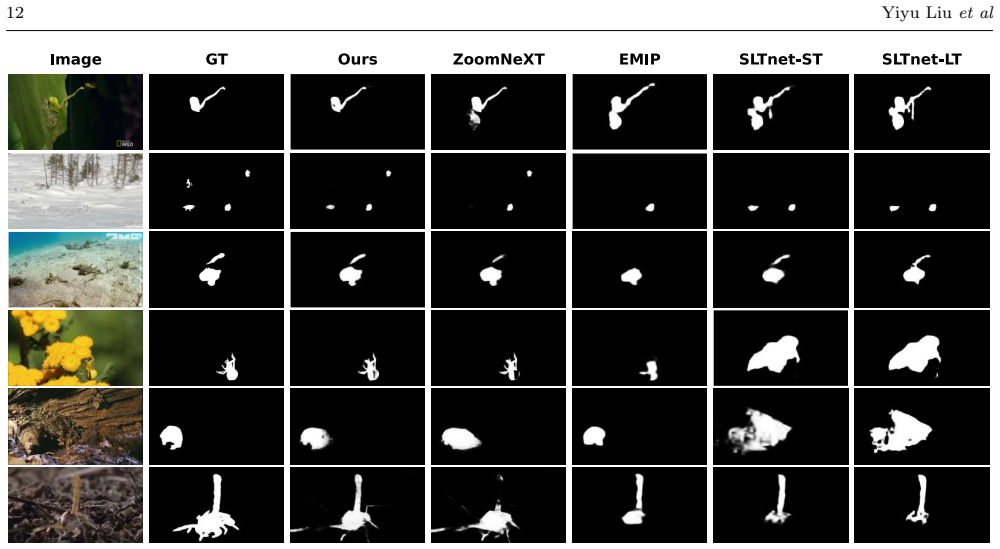


read the original abstract
Video Camouflaged Object Detection (VCOD) is currently constrained by the scarcity of challenging benchmarks and the limited robustness of models against erratic motion dynamics. Existing methods often struggle with Motion-Induced Appearance Instability and Temporal Feature Misalignment caused by complex motion scenarios. To address the data bottleneck, we present YUV20K, a pixel-level annoated complexity-driven VCOD benchmark. Comprising 24,295 annotated frames across 91 scenes and 47 kinds of species, it specifically targets challenging scenarios like large-displacement motion, camera motion and other 4 types scenarios. On the methodological front, we propose a novel framework featuring two key modules: Motion Feature Stabilization (MFS) and Trajectory-Aware Alignment (TAA). The MFS module utilizes frame-agnostic Semantic Basis Primitives to stablize features, while the TAA module leverages trajectory-guided deformable sampling to ensure precise temporal alignment. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art competitors on existing datasets and establishes a new baseline on the challenging YUV20K. Notably, our framework exhibits superior cross-domain generalization and robustness when confronting complex spatiotemporal scenarios. Our code and dataset will be available at https://github.com/K1NSA/YUV20K
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces YUV20K, a pixel-level annotated complexity-driven benchmark for Video Camouflaged Object Detection (VCOD) with 24,295 frames across 91 scenes and 47 species, targeting challenging scenarios such as large-displacement motion and camera motion. It proposes a framework consisting of a Motion Feature Stabilization (MFS) module that uses frame-agnostic Semantic Basis Primitives and a Trajectory-Aware Alignment (TAA) module that employs trajectory-guided deformable sampling to address Motion-Induced Appearance Instability and Temporal Feature Misalignment. The authors claim that the method significantly outperforms state-of-the-art competitors on existing datasets, establishes a new baseline on YUV20K, and exhibits superior cross-domain generalization and robustness in complex spatiotemporal scenarios, with code and dataset to be released.
Significance. If the performance claims hold under rigorous evaluation, the work would provide a valuable new benchmark that exposes limitations of current VCOD methods in complex motion regimes and a model architecture potentially improving robustness to erratic dynamics. The public release of the dataset and code would be a strength for reproducibility and further research in the field.
major comments (3)
- [Abstract] Abstract: The central claims of significant outperformance on existing datasets and a new baseline on YUV20K are asserted without any quantitative results, metrics (such as mIoU or F-measure), listed baselines, error analysis, or experimental setup details, which are load-bearing for evaluating the empirical contributions.
- [Method] Method section: The MFS module (frame-agnostic Semantic Basis Primitives for stabilization) and TAA module (trajectory-guided deformable sampling for alignment) are described at a high level with no equations, derivations, pseudocode, or comparison to standard techniques such as deformable convolutions or optical-flow warping; this prevents assessment of novelty and internal efficacy.
- [Experiments] Experiments section: No ablation studies, component-wise contributions, or failure-mode analysis are provided to isolate whether the MFS and TAA modules actually resolve Motion-Induced Appearance Instability and Temporal Feature Misalignment, undermining the attribution of reported gains to the proposed architecture rather than dataset curation or training protocol.
minor comments (2)
- [Abstract] Abstract: Typo 'stablize' should be 'stabilize'; typo 'annoated' should be 'annotated'.
- The manuscript states that code and dataset will be available at a GitHub link but provides no details on license, exact release timeline, or data split protocols.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, agreeing on the need for enhancements where the manuscript is currently high-level, and outlining specific revisions to improve clarity, rigor, and attribution of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of significant outperformance on existing datasets and a new baseline on YUV20K are asserted without any quantitative results, metrics (such as mIoU or F-measure), listed baselines, error analysis, or experimental setup details, which are load-bearing for evaluating the empirical contributions.
Authors: We agree that the abstract would benefit from including key quantitative highlights to make the empirical claims more concrete and accessible. The full manuscript contains detailed results with metrics such as mIoU and F-measure, baseline comparisons, and experimental setups. In revision, we will update the abstract to incorporate specific performance numbers (e.g., mIoU gains on existing datasets and the new YUV20K baseline), mention the primary metrics, and briefly note the evaluation protocol. revision: yes
-
Referee: [Method] Method section: The MFS module (frame-agnostic Semantic Basis Primitives for stabilization) and TAA module (trajectory-guided deformable sampling for alignment) are described at a high level with no equations, derivations, pseudocode, or comparison to standard techniques such as deformable convolutions or optical-flow warping; this prevents assessment of novelty and internal efficacy.
Authors: We acknowledge that the current method descriptions remain at an overview level, limiting precise evaluation of novelty. The revised manuscript will add formal equations and derivations for the frame-agnostic Semantic Basis Primitives in MFS and the trajectory-guided deformable sampling in TAA. We will also include pseudocode for both modules and explicit comparisons to deformable convolutions and optical-flow warping to highlight distinctions and demonstrate internal efficacy. revision: yes
-
Referee: [Experiments] Experiments section: No ablation studies, component-wise contributions, or failure-mode analysis are provided to isolate whether the MFS and TAA modules actually resolve Motion-Induced Appearance Instability and Temporal Feature Misalignment, undermining the attribution of reported gains to the proposed architecture rather than dataset curation or training protocol.
Authors: We agree that ablation studies and targeted failure-mode analysis are necessary to rigorously attribute gains to the MFS and TAA modules. While the manuscript reports overall outperformance and generalization, the revised version will add component-wise ablations quantifying the contribution of each module individually and in combination. We will also include failure-mode analysis on complex motion scenarios to show how MFS and TAA specifically mitigate Motion-Induced Appearance Instability and Temporal Feature Misalignment, separate from dataset or training effects. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks and new dataset without self-referential reduction.
full rationale
The paper introduces YUV20K as a new benchmark and proposes MFS/TAA modules whose efficacy is asserted via performance comparisons on existing datasets plus the new one. No equations, derivations, or parameter-fitting steps are described in the provided text that would reduce a claimed result to its own inputs by construction. Claims of outperformance and generalization are presented as experimental outcomes rather than tautological or self-cited necessities. This is the standard non-circular pattern for benchmark-plus-architecture papers.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Motion Feature Stabilization (MFS) module
no independent evidence
-
Trajectory-Aware Alignment (TAA) module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The MFS module utilizes frame-agnostic Semantic Basis Primitives to stabilize features... The TAA module leverages trajectory-guided deformable sampling to ensure precise temporal alignment.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Extensive experiments demonstrate that our method significantly outperforms state-of-the-art competitors on existing datasets and establishes a new baseline on the challenging YUV20K.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Concealed object detection.IEEE transactions on pattern analysis and machine intelligence, 44(10):6024– 6042, 2021
Deng-Ping Fan, Ge-Peng Ji, Ming-Ming Cheng, and Ling Shao. Concealed object detection.IEEE transactions on pattern analysis and machine intelligence, 44(10):6024– 6042, 2021
2021
-
[2]
Pranet: Paral- lel reverse attention network for polyp segmentation
Deng-Ping Fan, Ge-Peng Ji, Tao Zhou, Geng Chen, Huazhu Fu, Jianbing Shen, and Ling Shao. Pranet: Paral- lel reverse attention network for polyp segmentation. In International conference on medical image computing and computer-assisted intervention, pages 263–273. Springer, 2020
2020
-
[3]
Inf- net: Automatic covid-19 lung infection segmentation from ct images.IEEE transactions on medical imaging, 39(8):2626–2637, 2020
Deng-Ping Fan, Tao Zhou, Ge-Peng Ji, Yi Zhou, Geng Chen, Huazhu Fu, Jianbing Shen, and Ling Shao. Inf- net: Automatic covid-19 lung infection segmentation from ct images.IEEE transactions on medical imaging, 39(8):2626–2637, 2020
2020
-
[4]
Application of an image and environmental sensor network for au- tomated greenhouse insect pest monitoring.Journal of Asia-Pacific Entomology, 23(1):17–28, 2020
Dan Jeric Arcega Rustia, Chien Erh Lin, Jui-Yung Chung, Yi-Ji Zhuang, Ju-Chun Hsu, and Ta-Te Lin. Application of an image and environmental sensor network for au- tomated greenhouse insect pest monitoring.Journal of Asia-Pacific Entomology, 23(1):17–28, 2020
2020
-
[5]
Betrayed by motion: Camouflaged object discovery via motion segmentation
Hala Lamdouar, Charig Yang, Weidi Xie, and Andrew Zisserman. Betrayed by motion: Camouflaged object discovery via motion segmentation. InProceedings of the Asian conference on computer vision, 2020. 16 Yiyu Liuet al
2020
-
[6]
Self-supervised video object seg- mentation by motion grouping
Charig Yang, Hala Lamdouar, Erika Lu, Andrew Zisser- man, and Weidi Xie. Self-supervised video object seg- mentation by motion grouping. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 7177–7188, 2021
2021
-
[7]
A benchmark dataset and evaluation methodol- ogy for video object segmentation
Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine- Hornung. A benchmark dataset and evaluation methodol- ogy for video object segmentation. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 724–732, 2016
2016
-
[8]
Uncertainty-guided trans- former reasoning for camouflaged object detection
Fan Yang, Qiang Zhai, Xin Li, Rui Huang, Ao Luo, Hong Cheng, and Deng-Ping Fan. Uncertainty-guided trans- former reasoning for camouflaged object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4146–4155, 2021
2021
-
[9]
Edvr: Video restoration with enhanced deformable convolutional networks
Xintao Wang, Kelvin CK Chan, Ke Yu, Chao Dong, and Chen Change Loy. Edvr: Video restoration with enhanced deformable convolutional networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 0–0, 2019
2019
-
[10]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable trans- formers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020
work page internal anchor Pith review arXiv 2010
-
[11]
Internimage: Exploring large-scale vision foundation models with deformable convolutions
Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, et al. Internimage: Exploring large-scale vision foundation models with deformable convolutions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14408–14419, 2023
2023
-
[12]
It’s moving! a prob- abilistic model for causal motion segmentation in moving camera videos
Pia Bideau and Erik Learned-Miller. It’s moving! a prob- abilistic model for causal motion segmentation in moving camera videos. InEuropean Conference on Computer Vision, pages 433–449. Springer, 2016
2016
-
[13]
Implicit motion handling for video camouflaged object de- tection
Xuelian Cheng, Huan Xiong, Deng-Ping Fan, Yiran Zhong, Mehrtash Harandi, Tom Drummond, and Zongyuan Ge. Implicit motion handling for video camouflaged object de- tection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13864– 13873, 2022
2022
-
[14]
A survey of camouflaged object detection and beyond.arXiv preprint arXiv:2408.14562, 2024
Fengyang Xiao, Sujie Hu, Yuqi Shen, Chengyu Fang, Jinfa Huang, Chunming He, Longxiang Tang, Ziyun Yang, and Xiu Li. A survey of camouflaged object detection and beyond.arXiv preprint arXiv:2408.14562, 2024
-
[15]
Camouflage, detection and identification of moving targets.Pro- ceedings of the Royal Society B: Biological Sciences, 280(1758):20130064, 2013
Joanna R Hall, Innes C Cuthill, Roland Baddeley, Adam J Shohet, and Nicholas E Scott-Samuel. Camouflage, detection and identification of moving targets.Pro- ceedings of the Royal Society B: Biological Sciences, 280(1758):20130064, 2013
2013
-
[16]
Camouflaged object detection
Deng-Ping Fan, Ge-Peng Ji, Guolei Sun, Ming-Ming Cheng, Jianbing Shen, and Ling Shao. Camouflaged object detection. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2777–2787, 2020
2020
-
[17]
Frequency perception network for camouflaged object detection
Runmin Cong, Mengyao Sun, Sanyi Zhang, Xiaofei Zhou, Wei Zhang, and Yao Zhao. Frequency perception network for camouflaged object detection. InProceedings of the 31st ACM international conference on multimedia, pages 1179–1189, 2023
2023
-
[18]
Frequency-spatial entanglement learning for camouflaged object detection
Yanguang Sun, Chunyan Xu, Jian Yang, Hanyu Xuan, and Lei Luo. Frequency-spatial entanglement learning for camouflaged object detection. InEuropean Conference on Computer Vision, pages 343–360. Springer, 2024
2024
-
[19]
Mutual graph learning for camouflaged object detection
Qiang Zhai, Xin Li, Fan Yang, Chenglizhao Chen, Hong Cheng, and Deng-Ping Fan. Mutual graph learning for camouflaged object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12997–13007, 2021
2021
-
[20]
Zoom in and out: A mixed-scale triplet network for camouflaged object detection
Youwei Pang, Xiaoqi Zhao, Tian-Zhu Xiang, Lihe Zhang, and Huchuan Lu. Zoom in and out: A mixed-scale triplet network for camouflaged object detection. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 2160–2170, 2022
2022
-
[21]
Feature shrink- age pyramid for camouflaged object detection with trans- formers
Zhou Huang, Hang Dai, Tian-Zhu Xiang, Shuo Wang, Huai-Xin Chen, Jie Qin, and Huan Xiong. Feature shrink- age pyramid for camouflaged object detection with trans- formers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5557–5566, 2023
2023
-
[22]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on computer vision, pages 402–419. Springer, 2020
2020
-
[23]
Explicit motion handling and interactive prompting for video camouflaged object detection.IEEE Transactions on Image Processing, 2025
Xin Zhang, Tao Xiao, Ge-Peng Ji, Xuan Wu, Keren Fu, and Qijun Zhao. Explicit motion handling and interactive prompting for video camouflaged object detection.IEEE Transactions on Image Processing, 2025
2025
-
[24]
Endow sam with keen eyes: Temporal-spatial prompt learning for video camouflaged object detection
Wenjun Hui, Zhenfeng Zhu, Shuai Zheng, and Yao Zhao. Endow sam with keen eyes: Temporal-spatial prompt learning for video camouflaged object detection. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19058–19067, 2024
2024
-
[25]
Zoomnext: A unified collaborative pyramid network for camouflaged object detection.IEEE transactions on pattern analysis and machine intelligence, 46(12):9205–9220, 2024
Youwei Pang, Xiaoqi Zhao, Tian-Zhu Xiang, Lihe Zhang, and Huchuan Lu. Zoomnext: A unified collaborative pyramid network for camouflaged object detection.IEEE transactions on pattern analysis and machine intelligence, 46(12):9205–9220, 2024
2024
-
[26]
Sam-pm: Enhancing video camouflaged object de- tection using spatio-temporal attention
Muhammad Nawfal Meeran, Bhanu Pratyush Mantha, et al. Sam-pm: Enhancing video camouflaged object de- tection using spatio-temporal attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1857–1866, 2024
2024
-
[27]
Anabranch network for camouflaged object segmentation.Computer vision and image understanding, 184:45–56, 2019
Trung-Nghia Le, Tam V Nguyen, Zhongliang Nie, Minh- Triet Tran, and Akihiro Sugimoto. Anabranch network for camouflaged object segmentation.Computer vision and image understanding, 184:45–56, 2019
2019
-
[28]
Animal camouflage analysis: Chameleon database.Unpublished manuscript, 2(6):7, 2018
Przemys law Skurowski, Hassan Abdulameer, Jakub B laszczyk, Tomasz Depta, Adam Kornacki, and Prze- mys law Kozie l. Animal camouflage analysis: Chameleon database.Unpublished manuscript, 2(6):7, 2018
2018
-
[29]
Simultaneously localize, segment and rank the camouflaged objects
Yunqiu Lyu, Jing Zhang, Yuchao Dai, Aixuan Li, Bowen Liu, Nick Barnes, and Deng-Ping Fan. Simultaneously localize, segment and rank the camouflaged objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[30]
Advanced auto labeling solution with added features
Wei Wang. Advanced auto labeling solution with added features. https://github.com/CVHub520/X-AnyLabeling, 2023
2023
-
[31]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨ adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review arXiv 2024
-
[33]
Pvt v2: Improved baselines with pyramid vision transformer
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pvt v2: Improved baselines with pyramid vision transformer. Computational visual media, 8(3):415–424, 2022
2022
-
[34]
Concept embedding models: Beyond the accuracy-explainability trade-off
Mateo Espinosa Zarlenga, Pietro Barbiero, Gabriele Ciravegna, Giuseppe Marra, Francesco Giannini, YUV20K 17 Michelangelo Diligenti, Zohreh Shams, Frederic Precioso, Stefano Melacci, Adrian Weller, et al. Concept embedding models: Beyond the accuracy-explainability trade-off. Advances in neural information processing systems, 35:21400–21413, 2022
2022
-
[35]
Concept bottleneck models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInternational conference on machine learning, pages 5338–5348. PMLR, 2020
2020
-
[36]
IKA2: Internal Knowledge Adap- tive Activation for Robust Recognition in Complex Sce- narios.Machine Intelligence Research, 23(2):429–443, April 2026
Shuo Ye, Lixin Chen, Qiaoqi Li, Jiayu Zhang, Chaomeng Chen, and Shutao Xia. IKA2: Internal Knowledge Adap- tive Activation for Robust Recognition in Complex Sce- narios.Machine Intelligence Research, 23(2):429–443, April 2026
2026
-
[37]
Searching central difference convolutional networks for face anti-spoofing
Zitong Yu, Chenxu Zhao, Zezheng Wang, Yunxiao Qin, Zhuo Su, Xiaobai Li, Feng Zhou, and Guoying Zhao. Searching central difference convolutional networks for face anti-spoofing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5295–5305, 2020
2020
-
[38]
Dual-cross central difference network for face anti-spoofing.arXiv preprint arXiv:2105.01290, 2021
Zitong Yu, Yunxiao Qin, Hengshuang Zhao, Xiaobai Li, and Guoying Zhao. Dual-cross central difference network for face anti-spoofing.arXiv preprint arXiv:2105.01290, 2021
-
[39]
Pysodmetrics: A simple and efficient im- plementation of sod metrcis, 2020
Youwei Pang. Pysodmetrics: A simple and efficient im- plementation of sod metrcis, 2020
2020
-
[40]
Structure-measure: A new way to evaluate foreground maps
Deng-Ping Fan, Ming-Ming Cheng, Yun Liu, Tao Li, and Ali Borji. Structure-measure: A new way to evaluate foreground maps. InICCV, pages 4548–4557, 2017
2017
-
[41]
Frequency-tuned salient region detection
Radhakrishna Achanta, Sheila Hemami, Francisco Estrada, and Sabine Susstrunk. Frequency-tuned salient region detection. In2009 IEEE conference on computer vision and pattern recognition, pages 1597–1604. IEEE, 2009
2009
-
[42]
How to evaluate foreground maps? InCVPR, pages 248–255, 2014
Ran Margolin, Lihi Zelnik-Manor, and Ayellet Tal. How to evaluate foreground maps? InCVPR, pages 248–255, 2014
2014
-
[43]
Enhanced-alignment measure for binary foreground map evaluation
Deng-Ping Fan, Cheng Gong, Yang Cao, Bo Ren, Ming- Ming Cheng, and Ali Borji. Enhanced-alignment measure for binary foreground map evaluation. InIJCAI, pages 698–704, 2018
2018
-
[44]
Saliency filters: Contrast based filter- ing for salient region detection
Federico Perazzi, Philipp Kr¨ ahenb¨ uhl, Yael Pritch, and Alexander Hornung. Saliency filters: Contrast based filter- ing for salient region detection. InCVPR, pages 733–740, 2012
2012
-
[45]
Implicit-explicit motion learning for video camouflaged object detection.IEEE Transactions on Multimedia, 26:7188–7196, 2024
Wenjun Hui, Zhenfeng Zhu, Guanghua Gu, Meiqin Liu, and Yao Zhao. Implicit-explicit motion learning for video camouflaged object detection.IEEE Transactions on Multimedia, 26:7188–7196, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.