Recognition: unknown
SVSR: A Self-Verification and Self-Rectification Paradigm for Multimodal Reasoning
Pith reviewed 2026-05-10 15:55 UTC · model grok-4.3
The pith
Multimodal models learn to verify and correct their own reasoning steps through a three-stage training process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
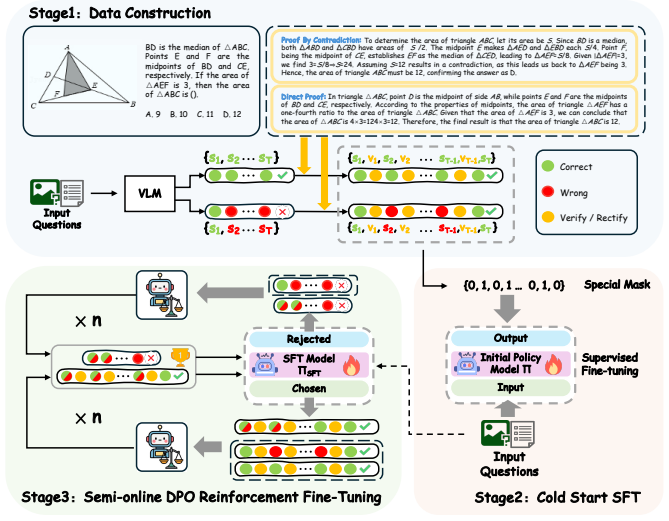
SVSR is a unified framework that explicitly integrates self-verification and self-rectification into the model's reasoning pipeline through a three-stage training paradigm. First, a high-quality unified preference dataset is constructed by refining reasoning traces from pre-trained vision-language models, incorporating both forward and backward reasoning to embed self-reflective signals. Second, cold-start supervised fine-tuning is performed on this dataset to learn structured, multi-step reasoning behaviors. Third, a Semi-online Direct Preference Optimization process is applied, continuously augmenting the training corpus with high-quality, model-generated reasoning traces filtered by a 1.
What carries the argument
The three-stage training paradigm that first builds a preference dataset with forward and backward reasoning traces, then uses cold-start supervised fine-tuning, and finally applies Semi-online DPO augmented by teacher-filtered model generations to teach self-verification and self-rectification.
If this is right
- Reasoning accuracy increases across diverse multimodal benchmarks.
- Generalization improves to unseen tasks and question types.
- Implicit reasoning ability strengthens even when no explicit reasoning traces are provided at inference time.
- The resulting systems become more dependable for complex visual understanding tasks.
Where Pith is reading between the lines
- The same three-stage approach of building reflective traces and filtering them with a stronger model could be tested on text-only reasoning benchmarks to check transfer.
- If the method works, it may reduce reliance on external verification modules in deployed multimodal systems.
- Over time the process might allow models to generate their own improving training data without repeated teacher intervention.
Load-bearing premise
Refining reasoning traces from pre-trained models and filtering new traces with a teacher model produces data that genuinely teaches robust self-verification rather than patterns or inherited biases.
What would settle it
If models trained with SVSR show no accuracy gain over strong baselines on held-out benchmarks that require reasoning steps absent from the constructed dataset, the claim that the method teaches generalizable self-verification would be falsified.
Figures


read the original abstract
Current multimodal models often suffer from shallow reasoning, leading to errors caused by incomplete or inconsistent thought processes. To address this limitation, we propose Self-Verification and Self-Rectification (SVSR), a unified framework that explicitly integrates self-verification and self-rectification into the model's reasoning pipeline, substantially improving robustness and reliability in complex visual understanding and multimodal reasoning tasks. SVSR is built on a novel three-stage training paradigm. First, we construct a high-quality unified preference dataset by refining reasoning traces from pre-trained vision-language models, incorporating both forward and backward reasoning to embed self-reflective signals. Second, we perform cold-start supervised fine-tuning on this dataset to learn structured, multi-step reasoning behaviors. Third, we apply a Semi-online Direct Preference Optimization (Semi-online DPO) process, continuously augmenting the training corpus with high-quality, model-generated reasoning traces filtered by a powerful teacher VLM. This pipeline enables the model to learn, elicit, and refine its ability to self-verify and self-rectify. Extensive experiments across diverse benchmarks demonstrate that SVSR improves reasoning accuracy and enables stronger generalization to unseen tasks and question types. Notably, once trained with explicit self-reflective reasoning, the model also exhibits improved implicit reasoning ability, outperforming strong baselines even when no explicit reasoning traces are provided. These results highlight the potential of SVSR for building more dependable, introspective, and cognitively aligned multimodal systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
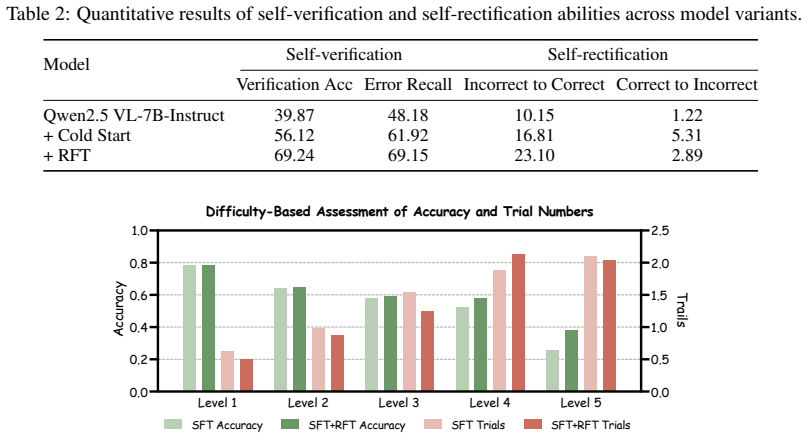
Summary. The paper proposes SVSR, a unified framework for multimodal reasoning in vision-language models that integrates explicit self-verification and self-rectification. It introduces a three-stage training paradigm: (1) constructing a high-quality unified preference dataset by refining forward and backward reasoning traces from pre-trained VLMs, (2) cold-start supervised fine-tuning to instill structured multi-step reasoning, and (3) semi-online Direct Preference Optimization (DPO) that augments data with model-generated traces filtered by a stronger teacher VLM. The central claims are that this pipeline substantially improves reasoning accuracy, enables stronger generalization to unseen tasks and question types, and yields improved implicit reasoning performance even when no explicit reasoning traces are provided at inference.
Significance. If the empirical outcomes are robust and the self-verification mechanism is shown to be internalized rather than an artifact of teacher distillation, SVSR would represent a meaningful step toward more reliable and introspective multimodal systems. The three-stage pipeline (preference data construction + SFT + semi-online DPO) is a concrete, reproducible training recipe that directly targets shallow reasoning; successful validation could influence subsequent work on self-reflective agents and preference optimization in VLMs.
major comments (2)
- [Abstract / three-stage training paradigm] Abstract / three-stage paradigm: The claim that the pipeline produces genuine self-verification/rectification that transfers to implicit reasoning (without traces) is load-bearing, yet the semi-online DPO stage selects traces only when approved by a teacher VLM. This introduces a plausible selection bias or distillation effect; no ablation isolating whether verification behavior persists absent teacher signals is described, leaving open the possibility that gains reflect memorization of refined traces or teacher-aligned patterns rather than learned self-reflection.
- [Abstract / experiments] Abstract / experiments: The abstract asserts 'extensive experiments across diverse benchmarks' with improvements in accuracy, generalization, and implicit reasoning, but reports no quantitative results, specific baselines, ablation studies, or metrics. Without these details, the magnitude, statistical significance, and robustness of the claimed gains cannot be evaluated, directly undermining assessment of the framework's effectiveness.
minor comments (2)
- [Abstract] The abstract introduces 'Semi-online DPO' without a concise definition or reference to its differences from standard online/offline DPO; a brief clarifying sentence would improve readability.
- [Abstract] The description of the preference dataset construction ('refining reasoning traces... incorporating both forward and backward reasoning') would benefit from one additional sentence on the concrete refinement procedure or quality criteria used.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major concern point by point below, clarifying our claims and outlining planned revisions to strengthen the presentation and empirical support.
read point-by-point responses
-
Referee: [Abstract / three-stage training paradigm] The claim that the pipeline produces genuine self-verification/rectification that transfers to implicit reasoning (without traces) is load-bearing, yet the semi-online DPO stage selects traces only when approved by a teacher VLM. This introduces a plausible selection bias or distillation effect; no ablation isolating whether verification behavior persists absent teacher signals is described, leaving open the possibility that gains reflect memorization of refined traces or teacher-aligned patterns rather than learned self-reflection.
Authors: We agree that the use of a teacher VLM for filtering in the semi-online DPO stage raises a valid question about whether the observed self-verification and implicit reasoning improvements stem from internalized capabilities or from distillation/selection effects. The SFT stage trains on refined traces that already embed forward and backward reasoning without ongoing teacher involvement at inference, and our experiments demonstrate gains in implicit reasoning (no traces provided) on unseen tasks. However, to directly isolate the contribution of self-reflection independent of teacher signals, we will add a new ablation in the revised manuscript comparing (i) the full SVSR pipeline, (ii) a variant using only SFT without DPO, and (iii) a DPO variant without teacher filtering. This will quantify whether verification behavior persists and transfers when teacher approval is removed. revision: partial
-
Referee: [Abstract / experiments] The abstract asserts 'extensive experiments across diverse benchmarks' with improvements in accuracy, generalization, and implicit reasoning, but reports no quantitative results, specific baselines, ablation studies, or metrics. Without these details, the magnitude, statistical significance, and robustness of the claimed gains cannot be evaluated, directly undermining assessment of the framework's effectiveness.
Authors: We acknowledge that the current abstract is high-level and does not include concrete numbers, which limits immediate evaluation of effect sizes. In the revised version we will expand the abstract to report key quantitative results (e.g., average accuracy gains on the main benchmarks, comparison to the strongest baselines, and the implicit-reasoning setting), while still respecting length constraints. The full paper already contains the detailed tables, ablations, and statistical details; the abstract revision will simply surface the most salient metrics upfront. revision: yes
Circularity Check
No circularity: empirical pipeline with no derivations or self-referential reductions
full rationale
The paper presents a three-stage training method (preference dataset construction from pre-trained VLMs, cold-start SFT, and Semi-online DPO with teacher VLM filtering) followed by benchmark evaluations. No equations, first-principles derivations, or predictions appear in the provided text. Claims of improved accuracy, generalization, and implicit reasoning are empirical performance statements, not tautological reductions to fitted inputs or self-citations. The method is self-contained as a procedural description whose validity rests on external experimental outcomes rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Refining reasoning traces from pre-trained vision-language models produces a high-quality unified preference dataset containing forward and backward reasoning
- domain assumption Semi-online DPO with teacher-filtered traces will elicit and refine self-verification abilities
Forward citations
Cited by 1 Pith paper
-
Verification Mirage: Mapping the Reliability Boundary of Self-Verification in Medical VQA
Self-verification in medical VQA creates a verification mirage where verifiers exhibit high error and agreement bias on wrong answers, with reliability strongly conditioned on task type.
Reference graph
Works this paper leans on
-
[1]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Training language models to self-correct via reinforcement learning
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, and Aleksandra Faust. Training language models to self-correct via reinforcement learning. 2024
2024
-
[3]
Mutual reasoning makes smaller llms stronger problem-solvers.arXiv preprint arXiv:2408.06195, 2024
Zhenting Qi, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, and Mao Yang. Mutual reasoning makes smaller llms stronger problem-solvers.arXiv preprint arXiv:2408.06195, 2024
-
[4]
Openai o1 system card.Preprint, 2024
OpenAI. Openai o1 system card.Preprint, 2024
2024
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
arXiv preprint arXiv:2501.04519 , year=
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rstar-math: Small llms can master math reasoning with self-evolved deep thinking.arXiv preprint arXiv:2501.04519, 2025
-
[7]
Kimi k1.5: Scaling reinforcement learning with llms
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1.5: Scaling reinforcement learning with llms. InarXiv preprint, 2025
2025
-
[8]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025
2025
-
[10]
Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems, 36, 2024
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[11]
Self-critiquing models for assisting human evaluators
William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. Self-critiquing models for assisting human evaluators.arXiv preprint arXiv:2206.05802, 2022
-
[12]
S 2r: Teaching llms to self-verify and self- correct via reinforcement learning,
Ruotian Ma, Peisong Wang, Cheng Liu, Xingyan Liu, Jiaqi Chen, Bang Zhang, Xin Zhou, Nan Du, and Jia Li. S 2r: Teaching llms to self-verify and self-correct via reinforcement learning. arXiv preprint arXiv:2502.12853, 2025
-
[13]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025. 10
work page internal anchor Pith review arXiv 2025
-
[14]
Online dpo: Online direct preference optimization with fast-slow chasing, 2024
Biqing Qi, Pengfei Li, Fangyuan Li, Junqi Gao, Kaiyan Zhang, and Bowen Zhou. Online dpo: Online direct preference optimization with fast-slow chasing, 2024
2024
-
[15]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. 2024
2024
-
[16]
Measuring multimodal mathematical reasoning with MATH-Vision dataset, 2024
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision (math-v) dataset. https://arxiv.org/ abs/2402.14804, 2024
-
[17]
https://huggingface.co/datasets/ XXXX/MMR1, 2024
MMR1: A multimodal math reasoning collection. https://huggingface.co/datasets/ XXXX/MMR1, 2024
2024
-
[18]
https://huggingface.co/datasets/ WaltonFuture/math12k_image, 2024
Waltonfuture/math12k_image dataset. https://huggingface.co/datasets/ WaltonFuture/math12k_image, 2024
2024
-
[19]
https://huggingface.co/ datasets/Ayush-Singh/maths-vision-task-splits, 2024
Ayush-singh/maths-vision-task-splits (800 examples). https://huggingface.co/ datasets/Ayush-Singh/maths-vision-task-splits, 2024
2024
-
[20]
https://huggingface.co/ datasets/We-Math, 2024
We-math: A multimodal math reasoning dataset (1.7 k). https://huggingface.co/ datasets/We-Math, 2024
2024
-
[21]
https://huggingface.co/datasets/CoMT/ creation, 2024
CoMT/creation dataset (500 examples). https://huggingface.co/datasets/CoMT/ creation, 2024
2024
-
[22]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
https://your-internal-repo.org/ unified-preferences, 2024
Gpt-4o generated unified preference dataset. https://your-internal-repo.org/ unified-preferences, 2024
2024
-
[24]
Dpo-scienceqa: Direct preference optimization for scientific question answering
François Longpré, Jerry Huang, Karolina Czarnowska, and et al. Dpo-scienceqa: Direct preference optimization for scientific question answering. InNeurIPS, 2023
2023
-
[25]
https://huggingface.co/datasets/XXXX/ nano-omni-vlm-dpo, 2024
nano-omni-vlm-dpo dataset (200 k). https://huggingface.co/datasets/XXXX/ nano-omni-vlm-dpo, 2024
2024
-
[26]
Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling, 2025
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, Lixin Gu, Xuehui Wang, Qingyun Li, Yimin Ren, Zixuan Chen, Jiapeng Luo, Jiahao Wang, Tan Jiang, Bo Wang, Conghui He, Botian Shi, Xingcheng Zhang, Han Lv, Yi Wang, Wenqi Shao, Pei Chu, Zhongying Tu, Tong He, Zhiyong Wu, Huipeng Deng, Jia...
2025
-
[27]
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models, 2025
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, Jiahao Wang, Nianchen Deng, Songze Li, Yinan He, Tan Jiang, Jiapeng Luo, Yi Wang, Conghui He, Botian Shi, Xingcheng Zh...
2025
-
[28]
Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution, 2024
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution, 2024. 11
2024
-
[29]
Minicpm: Unveiling the potential of small language models with scalable training strategies, 2024
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, Xinrong Zhang, Zheng Leng Thai, Kaihuo Zhang, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. Minicpm: Unveiling the potential of small langu...
2024
-
[30]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms, 2024
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, Ziteng Wang, Rob Fergus, Yann LeCun, and Saining Xie. Cambrian-1: A fully open, vision-centric exploration of multimodal llms, 2024
2024
-
[31]
Llava-onevision: Easy visual task transfer, 2024
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer, 2024
2024
-
[32]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InICLR, 2024. Available at https: //arxiv.org/abs/2310.02255
work page internal anchor Pith review arXiv 2024
-
[33]
https://your-benchmark-repo
Dynamath: Dynamic mathematical reasoning dataset. https://your-benchmark-repo. org/dynamath, 2024
2024
-
[34]
https:// your-benchmark-repo.org/mathverse, 2024
Mathverse: A multimodal mathematical reasoning benchmark. https:// your-benchmark-repo.org/mathverse, 2024
2024
-
[35]
A Diagram Is Worth A Dozen Images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. Ai2 diagrams (ai2d): A dataset for diagram understanding. https://arxiv.org/ abs/1603.07396, 2016
work page Pith review arXiv 2016
-
[36]
Mmstar: Multimodal reasoning and hallucination benchmark.https://your-benchmark-repo.org/mmstar, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. Mmstar: Multimodal reasoning and hallucination benchmark.https://your-benchmark-repo.org/mmstar, 2024
2024
-
[37]
Wait, let me recheck my solution
Mmvet: Medical multimodal evaluation of vision and text. https://your-benchmark-repo. org/mmvet, 2024. 12 A Further Methodological Insights Building the Dataset.Given the sampling from cutting-edge VLMs, we initially constructed a unified preference dataset using CoT-prompted VLMs. To build more effective validation and correction, we informed the VLM of ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.