Recognition: unknown
Adapting 2D Multi-Modal Large Language Model for 3D CT Image Analysis
Pith reviewed 2026-05-10 16:38 UTC · model grok-4.3
The pith
Transferring a 2D MLLM to 3D CT scans via a text-guided hierarchical mixture-of-experts layer reuses all pretrained parameters and improves medical report generation and visual question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By first transferring a 2D MLLM to support 3D medical volumetric inputs while reusing every pretrained parameter, then inserting a Text-Guided Hierarchical MoE framework that distinguishes tasks under text-prompt guidance, and finally applying a two-stage training strategy that learns both task-shared and task-specific image features, the resulting model extracts effective customized features for 3D CT analysis and outperforms prior 3D medical MLLMs on medical report generation and medical visual question answering.
What carries the argument
The Text-Guided Hierarchical MoE (TGH-MoE) framework, which routes the vision encoder's feature extraction according to the text prompt to produce task-tailored representations for different clinical tasks.
If this is right
- Existing 2D pretrained vision encoders can be reused for 3D medical volumes without retraining them from scratch.
- Text prompts can dynamically steer the extraction of image features suited to either report generation or visual question answering.
- A two-stage training process separates learning of features common across tasks from those unique to each task.
- Performance gains on both MRG and MVQA become achievable without requiring large-scale 3D medical pretraining corpora.
- All original parameters of the 2D MLLM remain intact, preserving the model's general multimodal alignment capabilities.
Where Pith is reading between the lines
- The same transfer-plus-MoE pattern could be tested on other scarce 3D modalities such as MRI or ultrasound where 2D foundation models already exist.
- Hierarchical routing guided by text might generalize to other multimodal medical tasks that require fine-grained task differentiation.
- If the method scales, it would lower the barrier to deploying strong multimodal reasoning in hospitals that lack massive 3D annotation resources.
- The approach invites direct comparison with fully 3D-pretrained models to quantify how much 2D pretraining contributes versus the added MoE.
Load-bearing premise
A 2D MLLM pretrained on natural images can be transferred to support 3D medical volumetric inputs while reusing all pre-trained parameters and still extract effective customized features via the added TGH-MoE.
What would settle it
A controlled experiment that trains the transferred model on the same 3D CT dataset and shows that its scores on MRG and MVQA fall below or equal those of existing 3D medical MLLMs would falsify the claimed advantage.
Figures




read the original abstract
3D medical image analysis is of great importance in disease diagnosis and treatment. Recently, multimodal large language models (MLLMs) have exhibited robust perceptual capacity, strong cross-modal alignment, and promising generalizability. Therefore, they have great potential to improve the performance of medical report generation (MRG) and medical visual question answering (MVQA), which serve as two important tasks in clinical scenarios. However, due to the scarcity of 3D medical images, existing 3D medical MLLMs suffer from insufficiently pretrained vision encoder and inability to extract customized image features for different kinds of tasks. In this paper, we propose to first transfer a 2D MLLM, which is well trained with 2D natural images, to support 3D medical volumetric inputs while reusing all of its pre-trained parameters. To enable the vision encoder to extract tailored image features for various tasks, we then design a Text-Guided Hierarchical MoE (TGH-MoE) framework, which can distinguish tasks under the guidance of the text prompt. Furthermore, we propose a two-stage training strategy to learn both task-shared and task-specific image features. As demonstrated empirically, our method outperforms existing 3D medical MLLMs in both MRG and MVQA tasks. Our code will be released once this paper is accepted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes transferring a 2D MLLM pretrained on natural images to 3D CT volumetric inputs while freezing all original parameters, introducing a Text-Guided Hierarchical MoE (TGH-MoE) module to extract task-customized features under text-prompt guidance, and applying a two-stage training regime to capture both shared and task-specific representations. The central claim is that this yields empirical outperformance over prior 3D medical MLLMs on medical report generation (MRG) and medical visual question answering (MVQA).
Significance. If the results hold under rigorous evaluation, the work would be significant for addressing 3D data scarcity in medical imaging by reusing large-scale 2D pretraining, offering an efficient path to improved clinical tools for report generation and VQA without full 3D retraining from scratch.
major comments (2)
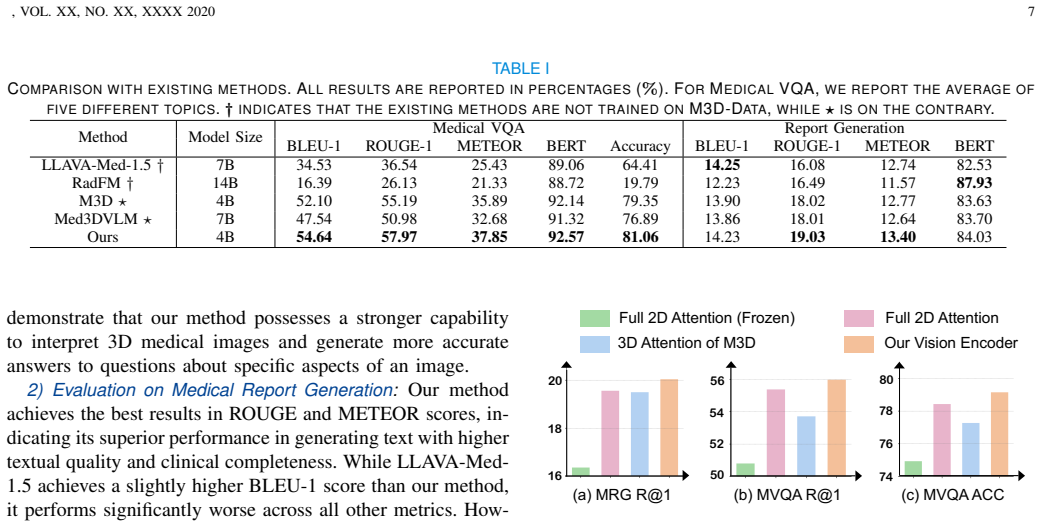
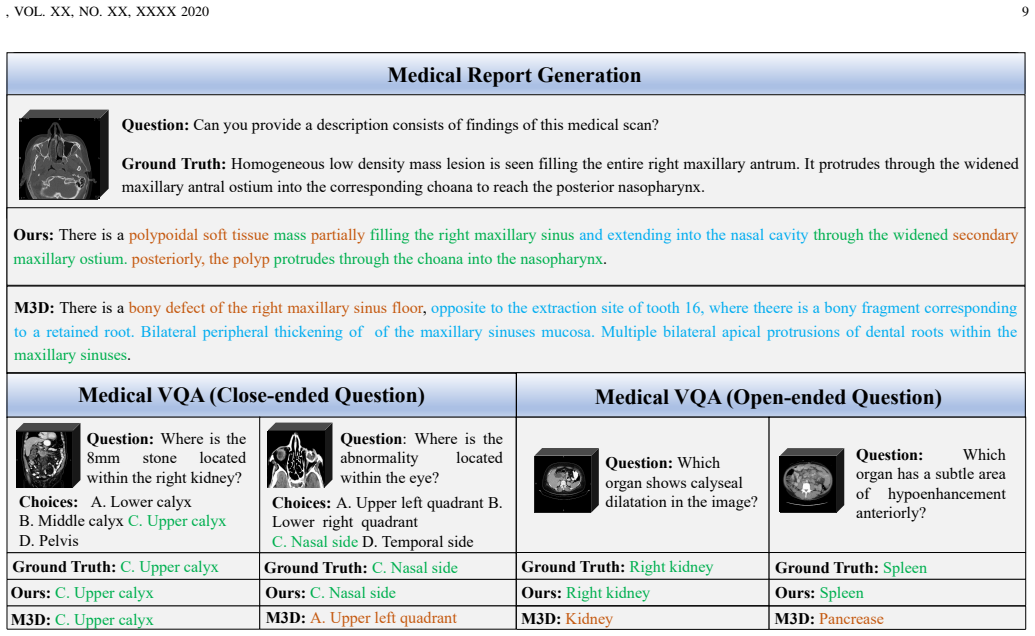
- [Abstract] Abstract: the claim that the method 'outperforms existing 3D medical MLLMs in both MRG and MVQA tasks' is presented without any datasets, metrics, baselines, error bars, or statistical tests, rendering the central empirical assertion impossible to assess for soundness.
- [Method] Method description (TGH-MoE and vision-encoder transfer): the 2D-pretrained vision encoder is frozen with no 3D operators (volumetric convolutions, slice-attention, or axial positional encodings) added; it is therefore unclear how inter-slice dependencies are recovered solely by the added MoE, which risks the claim that 'effective customized features' are extracted for 3D inputs.
minor comments (2)
- [Abstract] Abstract: expand the TGH-MoE acronym on first use and briefly indicate the two-stage training objectives.
- [Method] The paper should include a clear diagram or pseudocode for how 3D volumes are tokenized and fed to the frozen 2D encoder before TGH-MoE routing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity in both the abstract and method sections. We address each point below and have made revisions to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'outperforms existing 3D medical MLLMs in both MRG and MVQA tasks' is presented without any datasets, metrics, baselines, error bars, or statistical tests, rendering the central empirical assertion impossible to assess for soundness.
Authors: We agree that the original abstract was overly concise and did not provide enough context for readers to immediately evaluate the empirical claims. In the revised manuscript, we have updated the abstract to explicitly reference the primary datasets (3D CT volumes from clinical sources for MRG and MVQA), key metrics (BLEU, ROUGE, METEOR for report generation and accuracy/F1 for VQA), main baselines, and a statement that full results including error bars and statistical tests appear in Section 4. This change improves assessability while respecting abstract length constraints. revision: yes
-
Referee: [Method] Method description (TGH-MoE and vision-encoder transfer): the 2D-pretrained vision encoder is frozen with no 3D operators (volumetric convolutions, slice-attention, or axial positional encodings) added; it is therefore unclear how inter-slice dependencies are recovered solely by the added MoE, which risks the claim that 'effective customized features' are extracted for 3D inputs.
Authors: The 2D vision encoder processes individual axial slices of the 3D CT volume independently, reusing all pretrained parameters as stated in Section 3.1. Inter-slice dependencies are modeled via the Text-Guided Hierarchical MoE (TGH-MoE) module, which performs hierarchical routing and feature aggregation across slices conditioned on the input text prompt; this is combined with the two-stage training that first learns shared representations and then task-specific adaptations. The language model component further integrates cross-slice context. We have expanded the method description in the revision with additional explanatory text and a new schematic figure detailing the slice-wise encoding and MoE routing to clarify this mechanism. revision: partial
Circularity Check
No circularity: architectural proposal without derivation chain
full rationale
The paper proposes an empirical adaptation method—transferring a pretrained 2D MLLM to 3D CT volumes by freezing original parameters, inserting a Text-Guided Hierarchical MoE, and applying two-stage training—without presenting any equations, mathematical derivations, or closed-form predictions. Claims of outperformance on MRG and MVQA rest on experimental results rather than any reduction of outputs to inputs by construction, self-citation load-bearing premises, or ansatz smuggling. No self-definitional loops, fitted parameters renamed as predictions, or uniqueness theorems appear. The work is therefore self-contained as a design contribution.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Text-Guided Hierarchical MoE (TGH-MoE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwenet al., “Qwen2.5 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,
Z. Chenet al., “Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 24 185–24 198
2024
-
[3]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, and A. A. A. et al., “Phi-3 technical report: A highly capable language model locally on your phone,” 2024. [Online]. Available: https://arxiv.org/abs/2404.14219
work page internal anchor Pith review arXiv 2024
-
[4]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 11 975–11 986
2023
-
[5]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquabet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Spatio-temporal and retrieval-augmented modelling for chest x-ray report generation,
Y . Yanget al., “Spatio-temporal and retrieval-augmented modelling for chest x-ray report generation,”IEEE Transactions on Medical Imaging, 2025
2025
-
[7]
G. Wanget al., “Surgical-lvlm: Learning to adapt large vision-language model for grounded visual question answering in robotic surgery,”arXiv preprint arXiv:2405.10948, 2024
-
[8]
Collaboration between clinicians and vision–language models in radiology report generation,
R. Tannoet al., “Collaboration between clinicians and vision–language models in radiology report generation,”Nature Medicine, vol. 31, no. 2, pp. 599–608, 2025
2025
-
[9]
Interpretable bilingual multimodal large language model for diverse biomedical tasks,
L. Wanget al., “Interpretable bilingual multimodal large language model for diverse biomedical tasks,”arXiv preprint arXiv:2410.18387, 2024
-
[10]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day,
C. Liet al., “Llava-med: Training a large language-and-vision assistant for biomedicine in one day,”Advances in Neural Information Processing Systems, vol. 36, pp. 28 541–28 564, 2023
2023
-
[11]
M3d:Ad- vancing 3d medical image analysis with multi-modal large language models
F. Bai, Y . Du, T. Huang, M. Q.-H. Meng, and B. Zhao, “M3d: Advancing 3d medical image analysis with multi-modal large language models,” arXiv preprint arXiv:2404.00578, 2024
-
[12]
Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data,
C. Wu, X. Zhang, Y . Zhang, H. Hui, Y . Wang, and W. Xie, “Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data,”Nature Communications, vol. 16, no. 1, p. 7866, 2025
2025
-
[13]
Learning transferable visual models from natural language supervision,
A. Radfordet al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[14]
Adaptive mixtures of local experts,
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,”Neural computation, vol. 3, no. 1, pp. 79–87, 1991
1991
-
[15]
Learning to prompt for vision- language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision- language models,”International Journal of Computer Vision, vol. 130, no. 9, pp. 2337–2348, 2022
2022
-
[16]
Con- trastive learning of medical visual representations from paired images and text,
Y . Zhang, H. Jiang, Y . Miura, C. D. Manning, and C. P. Langlotz, “Con- trastive learning of medical visual representations from paired images and text,” inMachine learning for healthcare conference. PMLR, 2022, pp. 2–25
2022
-
[17]
Procedure-aware surgical video- language pretraining with hierarchical knowledge augmentation,
K. Yuan, N. Navab, N. Padoyet al., “Procedure-aware surgical video- language pretraining with hierarchical knowledge augmentation,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 122 952– 122 983, 2024
2024
-
[18]
Merlin: a computed tomography vision–language foundation model and dataset,
L. Blankemeieret al., “Merlin: a computed tomography vision–language foundation model and dataset,”Nature, pp. 1–11, 2026
2026
-
[19]
Triad: Vision foundation model for 3d magnetic resonance imaging,
S. Wanget al., “Triad: Vision foundation model for 3d magnetic resonance imaging,”Research Square, pp. rs–3, 2025
2025
-
[20]
Learning neuroimaging models from health system-scale data,
Y . Lyuet al., “Learning neuroimaging models from health system-scale data,”Nature Biomedical Engineering, pp. 1–13, 2026
2026
-
[21]
LLaMA: Open and Efficient Foundation Language Models
H. Touvronet al., “Llama: Open and efficient foundation language models,” 2023. [Online]. Available: https://arxiv.org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
T. GLMet al., “Chatglm: A family of large language models from glm-130b to glm-4 all tools,” 2024. [Online]. Available: https://arxiv.org/abs/2406.12793
work page internal anchor Pith review arXiv 2024
-
[23]
Towards accurate differential diagnosis with large language models,
D. McDuffet al., “Towards accurate differential diagnosis with large language models,”Nature, pp. 1–7, 2025
2025
-
[24]
Toward expert-level medical question answering with large language models,
K. Singhalet al., “Toward expert-level medical question answering with large language models,”Nature Medicine, vol. 31, no. 3, pp. 943–950, 2025
2025
-
[25]
S. Maet al., “Medla: A logic-driven multi-agent framework for com- plex medical reasoning with large language models,”arXiv preprint arXiv:2509.23725, 2025
-
[26]
A generalist vision–language foundation model for diverse biomedical tasks,
K. Zhanget al., “A generalist vision–language foundation model for diverse biomedical tasks,”Nature Medicine, pp. 1–13, 2024
2024
-
[27]
Y . Xin, G. C. Ates, K. Gong, and W. Shao, “Med3dvlm: An efficient vision-language model for 3d medical image analysis,”arXiv preprint arXiv:2503.20047, 2025
-
[28]
Dynamic graph enhanced contrastive learning for chest x-ray report generation,
M. Li, B. Lin, Z. Chen, H. Lin, X. Liang, and X. Chang, “Dynamic graph enhanced contrastive learning for chest x-ray report generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3334–3343
2023
-
[29]
A medical multimodal large language model for future pandemics,
F. Liuet al., “A medical multimodal large language model for future pandemics,”NPJ Digital Medicine, vol. 6, no. 1, p. 226, 2023
2023
-
[30]
Multimodal generative ai for medical image interpre- tation,
V . M. Raoet al., “Multimodal generative ai for medical image interpre- tation,”Nature, vol. 639, no. 8056, pp. 888–896, 2025
2025
-
[31]
Towards a holistic framework for multimodal llm in 3d brain ct radiology report generation,
C.-Y . Liet al., “Towards a holistic framework for multimodal llm in 3d brain ct radiology report generation,”Nature Communications, vol. 16, no. 1, p. 2258, 2025
2025
-
[32]
Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs,
A. E. Johnsonet al., “Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs,”arXiv preprint arXiv:1901.07042, 2019
-
[33]
Generating radiology re- ports via memory-driven transformer,
Z. Chen, Y . Song, T.-H. Chang, and X. Wan, “Generating radiology re- ports via memory-driven transformer,”arXiv preprint arXiv:2010.16056, 2020
-
[34]
Promptmrg: Diagnosis-driven prompts for medical report generation,
H. Jin, H. Che, Y . Lin, and H. Chen, “Promptmrg: Diagnosis-driven prompts for medical report generation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 3, 2024, pp. 2607– 2615
2024
-
[35]
Gmai-mmbench: A comprehensive multimodal evaluation benchmark towards general medical ai,
J. Yeet al., “Gmai-mmbench: A comprehensive multimodal evaluation benchmark towards general medical ai,”Advances in Neural Information Processing Systems, vol. 37, pp. 94 327–94 427, 2024
2024
-
[36]
Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm,
Y . Huet al., “Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2024, pp. 22 170– 22 183
2024
-
[37]
Lmt++: Adaptively collaborating llms with multi- specialized teachers for continual vqa in robotic surgical videos,
Y . Duet al., “Lmt++: Adaptively collaborating llms with multi- specialized teachers for continual vqa in robotic surgical videos,”IEEE Transactions on Medical Imaging, 2025
2025
-
[38]
Interactive and ex- plainable region-guided radiology report generation,
T. Tanida, P. M ¨uller, G. Kaissis, and D. Rueckert, “Interactive and ex- plainable region-guided radiology report generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7433–7442
2023
-
[39]
Z. Zenget al., “Surgvlm: A large vision-language model and sys- tematic evaluation benchmark for surgical intelligence,”arXiv preprint arXiv:2506.02555, 2025
-
[40]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeeret al., “Outrageously large neural networks: The sparsely- gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Roformer: En- hanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “Roformer: En- hanced transformer with rotary position embedding,”Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[42]
Do vision transformers see like convolutional neural networks?
M. Raghu, T. Unterthiner, S. Kornblith, C. Zhang, and A. Dosovitskiy, “Do vision transformers see like convolutional neural networks?”Ad- vances in neural information processing systems, vol. 34, pp. 12 116– 12 128, 2021
2021
-
[43]
Pace: Unified multi-modal dialogue pre-training with progressive and compositional experts,
Y . Li, B. Hui, Z. Yin, M. Yang, F. Huang, and Y . Li, “Pace: Unified multi-modal dialogue pre-training with progressive and compositional experts,”arXiv preprint arXiv:2305.14839, 2023
-
[44]
Scaling vision with sparse mixture of experts,
C. Riquelmeet al., “Scaling vision with sparse mixture of experts,” Advances in Neural Information Processing Systems, vol. 34, pp. 8583– 8595, 2021
2021
-
[45]
Y . Gouet al., “Mixture of cluster-conditional lora experts for vision- language instruction tuning,”arXiv preprint arXiv:2312.12379, 2023
-
[46]
S. Jiang, T. Zheng, Y . Zhang, Y . Jin, L. Yuan, and Z. Liu, “Med- moe: Mixture of domain-specific experts for lightweight medical vision- language models,”arXiv preprint arXiv:2404.10237, 2024
-
[47]
arXiv preprint arXiv:2401.15947 , year=
B. Linet al., “Moe-llava: Mixture of experts for large vision-language models,”arXiv preprint arXiv:2401.15947, 2024
-
[48]
Lora: Low-rank adaptation of large language models
E. J. Huet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[49]
Zero: Memory optimizations toward training trillion parameter models,
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He, “Zero: Memory optimizations toward training trillion parameter models,” inSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020, pp. 1–16
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.