Recognition: unknown
Class-Adaptive Cooperative Perception for Multi-Class LiDAR-based 3D Object Detection in V2X Systems
Pith reviewed 2026-05-10 15:41 UTC · model grok-4.3
The pith
A class-adaptive architecture routes small and large objects through separate fusion paths to improve multi-class LiDAR detection in V2X systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
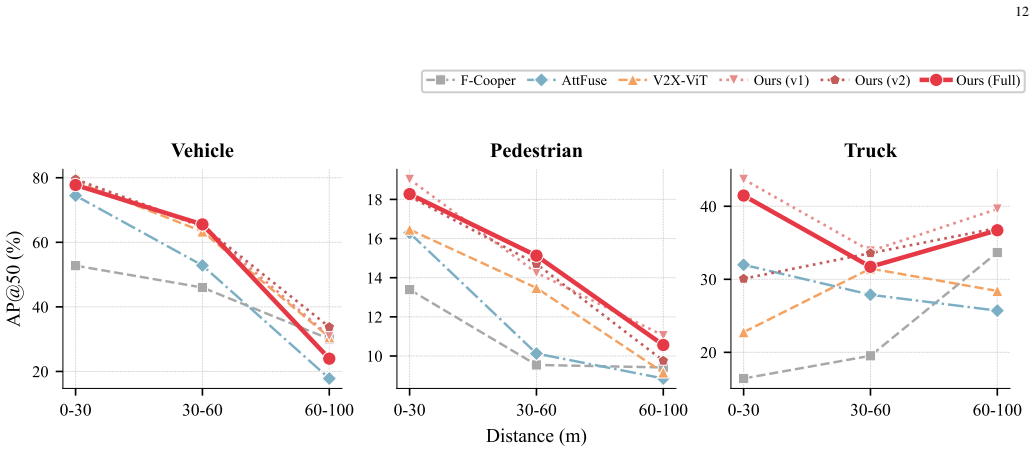
The class-adaptive cooperative perception architecture integrates multi-scale window attention with learned scale routing, a class-specific fusion module that places small and large objects into separate attentive pathways, bird's-eye-view enhancement through parallel dilated convolution and channel recalibration, and class-balanced objective weighting. On the V2X-Real benchmark under vehicle-centric, infrastructure-centric, vehicle-to-vehicle, infrastructure-to-infrastructure, and vehicle-to-infrastructure protocols with fixed backbones, this design produces higher mean detection performance than strong intermediate-fusion baselines, with the largest gains on trucks, clear improvements on 3
What carries the argument
class-specific fusion module that separates small and large objects into attentive fusion pathways
If this is right
- Trucks receive larger accuracy gains because large-object features avoid dilution by small-object processing routes.
- Pedestrian detection rises because small-object pathways preserve fine point details that uniform fusion often loses.
- Mean average precision improves across all tested V2X cooperation modes without sacrificing car performance.
- Class-balanced weighting reduces training bias toward the most common category in the dataset.
Where Pith is reading between the lines
- The same routing idea could extend to other sensors such as cameras where object scale also affects feature resolution.
- If the learned scale routing proves stable, it might reduce the need for separate models per cooperation range or density level.
- Applying the approach in datasets with more varied weather or occlusion would check whether class adaptation still helps when point density varies for reasons beyond object size.
Load-bearing premise
The observed gains on trucks and pedestrians arise specifically from the class-adaptive fusion and attention components rather than from training details or the particular point-density patterns in the V2X-Real dataset.
What would settle it
Retraining an otherwise identical uniform-fusion baseline on the same V2X-Real splits and backbones and measuring whether the per-class gaps on trucks and pedestrians shrink to zero would test whether the class-specific pathways are the source of the reported improvements.
Figures





read the original abstract
Cooperative perception allows connected vehicles and roadside infrastructure to share sensor observations, creating a fused scene representation beyond the capability of any single platform. However, most cooperative 3D object detectors use a uniform fusion strategy for all object classes, which limits their ability to handle the different geometric structures and point-sampling patterns of small and large objects. This problem is further reinforced by narrow evaluation protocols that often emphasize a single dominant class or only a few cooperation settings, leaving robust multi-class detection across diverse vehicle-to-everything interactions insufficiently explored. To address this gap, we propose a class-adaptive cooperative perception architecture for multi-class 3D object detection from LiDAR data. The model integrates four components: multi-scale window attention with learned scale routing for spatially adaptive feature extraction, a class-specific fusion module that separates small and large objects into attentive fusion pathways, bird's-eye-view enhancement through parallel dilated convolution and channel recalibration for richer contextual representation, and class-balanced objective weighting to reduce bias toward frequent categories. Experiments on the V2X-Real benchmark cover vehicle-centric, infrastructure-centric, vehicle-to-vehicle, infrastructure-to-infrastructure, and vehicle-to-infrastructure settings under identical backbone and training configurations. The proposed method consistently improves mean detection performance over strong intermediate-fusion baselines, with the largest gains on trucks, clear improvements on pedestrians, and competitive results on cars. These results show that aligning feature extraction and fusion with class-dependent geometry and point density leads to more balanced cooperative perception in realistic vehicle-to-everything deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a class-adaptive cooperative perception architecture for multi-class LiDAR-based 3D object detection in V2X systems. It combines multi-scale window attention with learned scale routing, a class-specific fusion module separating small and large objects, BEV enhancement via parallel dilated convolutions and channel recalibration, and class-balanced objective weighting. Experiments on the V2X-Real benchmark across vehicle-centric, infrastructure-centric, V2V, I2I, and V2I settings report consistent mean AP improvements over strong intermediate-fusion baselines, with largest gains on trucks, clear gains on pedestrians, and competitive results on cars, under identical backbone and training configurations.
Significance. If the reported gains are attributable to the class-adaptive components rather than training or backbone differences, the work would meaningfully advance multi-class cooperative perception by addressing uniform fusion's limitations with class-dependent geometry and point density. This could improve robustness in realistic V2X deployments where object scales and sampling patterns vary widely.
major comments (2)
- [Experiments] Experiments section: the central claim that improvements arise specifically from the four listed components (multi-scale window attention with scale routing, class-specific fusion pathways, BEV dilated+recalibration, and class-balanced weighting) is not supported by component-wise ablations. No results isolate the contribution of class-specific fusion versus a uniform-fusion baseline with only the class-balanced loss, or remove scale routing while retaining the rest, leaving attribution to the motivating premise (V2X-Real multi-class point-density variation) untested.
- [Abstract] Abstract and Experiments: quantitative metrics, per-class AP values, ablation tables, error bars, and statistical significance tests are referenced but not detailed in the provided text, so the reported 'consistent improvements' and 'largest gains on trucks' cannot be verified or compared to baselines.
minor comments (2)
- [Method] Notation for the class-specific fusion pathways and scale routing mechanism should be formalized with equations to clarify how attentive pathways are separated and how routing is learned.
- [Introduction] The V2X-Real benchmark description would benefit from explicit statistics on per-class point density distributions across the five cooperation settings to ground the motivation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for strengthening the attribution of results and the presentation of quantitative details. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that improvements arise specifically from the four listed components (multi-scale window attention with scale routing, class-specific fusion pathways, BEV dilated+recalibration, and class-balanced weighting) is not supported by component-wise ablations. No results isolate the contribution of class-specific fusion versus a uniform-fusion baseline with only the class-balanced loss, or remove scale routing while retaining the rest, leaving attribution to the motivating premise (V2X-Real multi-class point-density variation) untested.
Authors: We agree that component-wise ablations are necessary to rigorously support the claim that gains stem from the class-adaptive design rather than other factors. The current experiments compare the full model against strong intermediate-fusion baselines under identical backbones and training, but do not include the specific isolations requested (e.g., class-specific fusion vs. uniform fusion with only class-balanced loss, or ablating scale routing). We will add these targeted ablations on the V2X-Real benchmark in the revised manuscript to directly test attribution to multi-class point-density variation. revision: yes
-
Referee: [Abstract] Abstract and Experiments: quantitative metrics, per-class AP values, ablation tables, error bars, and statistical significance tests are referenced but not detailed in the provided text, so the reported 'consistent improvements' and 'largest gains on trucks' cannot be verified or compared to baselines.
Authors: The full manuscript's Experiments section contains tables with per-class AP values across all V2X settings, ablation results, and baseline comparisons. However, the abstract summarizes without specific numbers, and the excerpt provided to the referee may not have included the full tables or error bars. We will revise the abstract to report key quantitative metrics (e.g., mean AP gains and per-class improvements on trucks/pedestrians) and augment the experiments with error bars and significance tests where appropriate. revision: partial
Circularity Check
No circularity: purely empirical architecture evaluated on external benchmark
full rationale
The paper presents a class-adaptive cooperative perception architecture for multi-class 3D detection and reports empirical gains on the V2X-Real benchmark under fixed backbone/training settings. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or described content. The central claim reduces to measured AP improvements versus baselines rather than any self-referential construction. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deep neural networks with attention can learn spatially adaptive and class-dependent features from LiDAR point clouds
Reference graph
Works this paper leans on
-
[1]
Collaborative perception in autonomous driving: Methods, datasets, and challenges,
Y . Han, H. Zhang, H. Li, Y . Jin, C. Lang, and Y . Li, “Collaborative perception in autonomous driving: Methods, datasets, and challenges,” IEEE Intelligent Transportation Systems Magazine, vol. 16, no. 1, pp. 6–25, 2024, early access 2023; published 2024
2024
-
[2]
V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer,
R. Xu, H. Xiang, Z. Tu, X. Xia, M.-H. Yang, and J. Ma, “V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer,” in Proceedings of the European Conference on Computer Vision (ECCV). Springer, 2022, pp. 402–418
2022
-
[3]
OPV2V: An open benchmark dataset and fusion pipeline for perception with vehicle- to-vehicle communication,
R. Xu, H. Xiang, X. Xia, X. Han, J. Liu, and J. Ma, “OPV2V: An open benchmark dataset and fusion pipeline for perception with vehicle- to-vehicle communication,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2022, pp. 2583–2589
2022
-
[4]
Q. Chen, X. Ma, S. Tang, J. Guo, Q. Yang, and S. Fu, “F-Cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3d point clouds,” inProceedings of the ACM/IEEE Sym- posium on Edge Computing (SEC), 2019, pp. 34–46, arXiv:1909.06459
-
[5]
V2X-Real: A large-scale dataset for vehicle-to-everything cooperative perception,
H. Xiang, Z. Zheng, X. Xia, R. Xu, L. Gao, Z. Zhou, X. Han, X. Ji, M. Li, Z. Meng, L. Jin, M. Lei, Z. Ma, Z. He, H. Ma, Y . Yuan, Y . Zhao, and J. Ma, “V2X-Real: A large-scale dataset for vehicle-to-everything cooperative perception,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2024, arXiv:2403.16034
-
[6]
HYDRO-3D: Hybrid object detection and tracking for cooperative perception using 3D LiDAR,
J. Ma, W. Liu, R. Xu, X. Xia, and Z. Meng, “HYDRO-3D: Hybrid object detection and tracking for cooperative perception using 3D LiDAR,” IEEE Transactions on Intelligent Vehicles, vol. 8, no. 8, pp. 4307–4318, 2023
2023
-
[7]
Interruption-aware cooperative perception for V2X communication- aided autonomous driving,
S. Ren, Z. Lei, Z. Wang, M. Dianati, Y . Wang, S. Chen, and W. Zhang, “Interruption-aware cooperative perception for V2X communication- aided autonomous driving,”IEEE Transactions on Intelligent Vehicles, vol. 9, no. 4, pp. 4698–4714, 2024
2024
-
[8]
Cooperative perception for 3D object detection in driving scenarios using infrastruc- ture sensors,
E. Arnold, M. Dianati, R. de Temple, and S. Fallah, “Cooperative perception for 3D object detection in driving scenarios using infrastruc- ture sensors,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 3, pp. 1852–1864, 2022
2022
-
[9]
Improving vulnerable road-users detection through hybrid collaborative perception and detection refinement,
S. Oubouabdellah, M.-Q. Dao, E. Malis, E. H ´ery, J. Moreau, and V . Fr´emont, “Improving vulnerable road-users detection through hybrid collaborative perception and detection refinement,” inProceedings of the 28th IEEE International Conference on Intelligent Transportation Systems (ITSC), Gold Coast, Australia, November 2025
2025
-
[10]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2980–2988
2017
-
[11]
Class-balanced grouping and sampling for point cloud 3d object detection,
B. Zhu, Z. Jiang, X. Zhou, Z. Li, and G. Yu, “Class-balanced grouping and sampling for point cloud 3D object detection,”arXiv preprint arXiv:1908.09492, 2019, addresses severe class imbalance in nuScenes via balanced sampling; shows>20 mAP gain over na ¨ıve training
-
[12]
nuScenes: A multi- modal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuScenes: A multi- modal dataset for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 11 621–11 631
2020
-
[13]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 12 697–12 705
2019
-
[14]
SECOND: Sparsely embedded convolutional detection,
Y . Yan, Y . Mao, and B. Li, “SECOND: Sparsely embedded convolutional detection,”Sensors, vol. 18, no. 10, p. 3337, 2018
2018
-
[15]
Center-based 3D object detection and tracking,
T. Yin, X. Zhou, and P. Kr ¨ahenb¨uhl, “Center-based 3D object detection and tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 11 784–11 793
2021
-
[16]
Towards long-tailed 3D detection,
N. Peri, A. Dave, D. Ramanan, and S. Kong, “Towards long-tailed 3D detection,” inProceedings of the 6th Conference on Robot Learning (CoRL), ser. Proceedings of Machine Learning Research, vol. 205. PMLR, 2023, pp. 1904–1915, formally studies long-tailed class distri- butions in 3D detection; shows rare-class AP can be>10×lower than common-class AP
2023
-
[17]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2117–2125
2017
-
[18]
V oxelNet: End-to-end learning for point cloud based 3D object detection,
Y . Zhou and O. Tuzel, “V oxelNet: End-to-end learning for point cloud based 3D object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 4490– 4499
2018
-
[19]
PV- RCNN: Point-voxel feature set abstraction for 3D object detection,
S. Shi, C. Guo, L. Jiang, Z. Wang, J. Shi, X. Wang, and H. Li, “PV- RCNN: Point-voxel feature set abstraction for 3D object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 10 529–10 538
2020
-
[20]
V2VNet: Vehicle-to-vehicle communication for joint per- ception and prediction,
T.-H. Wang, S. Manivasagam, M. Liang, B. Yang, W. Zeng, and R. Urtasun, “V2VNet: Vehicle-to-vehicle communication for joint per- ception and prediction,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2020, pp. 605–621
2020
-
[21]
When2com: Multi-agent perception via communication graph grouping,
Y .-C. Liu, J. Tian, N. Glaser, and Z. Kira, “When2com: Multi-agent perception via communication graph grouping,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 4106–4115
2020
-
[22]
Learning distilled collaboration graph for multi-agent perception,
Y . Li, S. Ren, P. Wu, S. Chen, C. Feng, and W. Zhang, “Learning distilled collaboration graph for multi-agent perception,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021, pp. 29 541–29 552
2021
-
[23]
Where2comm: Communication-efficient collaborative perception via spatial confi- dence maps,
Y . Hu, S. Fang, Z. Lei, Y . Zhong, and S. Chen, “Where2comm: Communication-efficient collaborative perception via spatial confi- dence maps,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 4874–4886
2022
-
[24]
CoBEVT: Cooperative bird’s eye view semantic segmentation with sparse transformers,
R. Xu, H. Xiang, X. Han, X. Xia, Z. Meng, J. Chen, and J. Ma, “CoBEVT: Cooperative bird’s eye view semantic segmentation with sparse transformers,” inProceedings of the 6th Conference on Robot Learning (CoRL), vol. 205. PMLR, 2022, pp. 989–1000. 15
2022
-
[25]
DAIR-V2X: A large-scale dataset for vehicle- infrastructure cooperative 3D object detection,
H. Yu, Y . Luo, M. Shu, Y . Huo, Z. Yang, Y . Shi, Z. Guo, H. Li, X. Hu, J. Yuan, and Z. Nie, “DAIR-V2X: A large-scale dataset for vehicle- infrastructure cooperative 3D object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 21 361–21 370
2022
-
[26]
V2V4Real: A real- world large-scale dataset for vehicle-to-vehicle cooperative perception,
R. Xu, X. Xia, J. Li, H. Li, S. Zhang, Z. Tu, Z. Meng, H. Xiang, X. Dong, R. Song, H. Ma, J. Ma, and W. Tian, “V2V4Real: A real- world large-scale dataset for vehicle-to-vehicle cooperative perception,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 13 712–13 722
2023
-
[27]
PointNet++: Deep hierarchical feature learning on point sets in a metric space,
C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “PointNet++: Deep hierarchical feature learning on point sets in a metric space,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017, pp. 5099– 5108
2017
-
[28]
From points to parts: 3D object detection from point cloud with part-aware and part-aggregation network,
S. Shi, Z. Wang, J. Shi, X. Wang, and H. Li, “From points to parts: 3D object detection from point cloud with part-aware and part-aggregation network,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 43, no. 8, pp. 2647–2664, 2021
2021
-
[29]
Class-balanced loss based on effective number of samples,
Y . Cui, M. Jia, T.-Y . Lin, Y . Song, and S. Belongie, “Class-balanced loss based on effective number of samples,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 9268–9277
2019
-
[30]
FCOS: Fully convolutional one-stage object detection,
Z. Tian, C. Shen, H. Chen, and T. He, “FCOS: Fully convolutional one-stage object detection,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 9627–9636
2019
-
[31]
X. Zhou, D. Wang, and P. Kr ¨ahenb¨uhl, “Objects as points,”arXiv preprint arXiv:1904.07850, 2019
-
[32]
TANet: Robust 3D object detection from point clouds with triple attention,
Z. Liu, Z. Zhou, Y . Xu, Z. Wang, and W. Li, “TANet: Robust 3D object detection from point clouds with triple attention,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 7, 2020, pp. 11 677–11 684
2020
-
[33]
Structure aware single-stage 3D object detection from point cloud,
C. He, H. Zeng, J. Huang, X.-S. Hua, and L. Zhang, “Structure aware single-stage 3D object detection from point cloud,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 11 873–11 882
2020
-
[34]
Mask R-CNN,
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick, “Mask R-CNN,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2961–2969
2017
-
[35]
Cascade R-CNN: Delving into high quality object detection,
Z. Cai and N. Vasconcelos, “Cascade R-CNN: Delving into high quality object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6154–6162
2018
-
[36]
Hybrid task cascade for instance segmentation,
K. Chen, J. Pang, J. Wang, Y . Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Shi, W. Ouyang, C. C. Loy, and D. Lin, “Hybrid task cascade for instance segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4974– 4983
2019
-
[37]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7132–7141
2018
-
[38]
CBAM: Convolutional block attention module,
S. Woo, J. Park, J.-Y . Lee, and I. S. Kweon, “CBAM: Convolutional block attention module,” inProceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 3–19
2018
-
[39]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inProceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[40]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2021, pp. 10 012–10 022
2021
-
[41]
Deformable DETR: Deformable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable DETR: Deformable transformers for end-to-end object detection,” in Proceedings of the International Conference on Learning Representa- tions (ICLR), 2021
2021
-
[42]
Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs,
L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 4, pp. 834–848, 2017
2017
-
[43]
BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y . Qiao, and J. Dai, “BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2022, pp. 1–18
2022
-
[44]
RepPoints: Point set representation for object detection,
Z. Yang, S. Liu, H. Hu, L. Wang, and S. Lin, “RepPoints: Point set representation for object detection,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 9657– 9666
2019
-
[45]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inProceedings of the International Conference on Learning Represen- tations (ICLR), 2015. Blessing Agyei Kyemreceived the BSc in civil engineering from the Kwame Nkrumah University of Science and Technology, Ghana, in 2023. He worked as a Junior Data Scientist at Bismuth Tech- nologies ...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.