Recognition: no theorem link
MonoEM-GS: Monocular Expectation-Maximization Gaussian Splatting SLAM
Pith reviewed 2026-05-10 16:12 UTC · model grok-4.3
The pith
MonoEM-GS stabilizes noisy monocular geometry predictions from foundation models into a consistent Gaussian Splatting map using an Expectation-Maximization process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MonoEM-GS couples Gaussian Splatting with an Expectation--Maximization formulation to stabilize geometry, and employs ICP-based alignment for monocular pose estimation. Beyond geometry, MonoEM-GS parameterizes Gaussians with multi-modal features, enabling in-place open-set segmentation and other downstream queries directly on the reconstructed map.
What carries the argument
The Expectation-Maximization formulation that iteratively refines Gaussian parameters to reconcile view-dependent geometric predictions, combined with multi-modal feature parameterization on the same Gaussians.
If this is right
- Monocular pose estimation is achieved through ICP-based alignment of the stabilized map.
- Open-set segmentation becomes possible directly on the reconstructed Gaussian map without additional models.
- The system produces a globally consistent representation from noisy, view-dependent priors.
- The pipeline is evaluated on standard benchmarks including 7-Scenes, TUM RGB-D, and Replica.
Where Pith is reading between the lines
- This approach could reduce drift in long-term monocular mapping by explicitly modeling the uncertainty in foundation-model outputs.
- Downstream tasks like object recognition or navigation could query the map in place rather than re-processing images.
- Similar EM stabilization might be applied to other neural scene representations beyond Gaussians.
Load-bearing premise
That the view-dependent and noisy geometric predictions from foundation models can be reliably stabilized into a globally consistent Gaussian Splatting representation by the proposed EM formulation and ICP alignment without introducing new inconsistencies or drift.
What would settle it
Running the system on long image sequences with repeated viewpoint changes and checking whether the reconstructed geometry shows accumulating drift or inconsistent surface positions across frames.
Figures



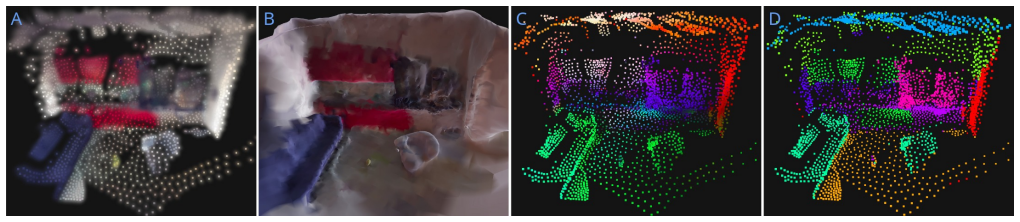



read the original abstract
Feed-forward geometric foundation models can infer dense point clouds and camera motion directly from RGB streams, providing priors for monocular SLAM. However, their predictions are often view-dependent and noisy: geometry can vary across viewpoints and under image transformations, and local metric properties may drift between frames. We present MonoEM-GS, a monocular mapping pipeline that integrates such geometric predictions into a global Gaussian Splatting representation while explicitly addressing these inconsistencies. MonoEM-GS couples Gaussian Splatting with an Expectation--Maximization formulation to stabilize geometry, and employs ICP-based alignment for monocular pose estimation. Beyond geometry, MonoEM-GS parameterizes Gaussians with multi-modal features, enabling in-place open-set segmentation and other downstream queries directly on the reconstructed map. We evaluate MonoEM-GS on 7-Scenes, TUM RGB-D and Replica, and compare against recent baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MonoEM-GS, a monocular SLAM pipeline that integrates noisy, view-dependent geometric predictions from foundation models into a global Gaussian Splatting map via an Expectation-Maximization (EM) formulation for stabilization, uses ICP-based alignment for pose estimation, and augments Gaussians with multi-modal features to support in-place open-set segmentation and other queries. The system is evaluated on the 7-Scenes, TUM RGB-D, and Replica datasets against recent baselines.
Significance. If the EM loop demonstrably produces metric-consistent maps without introducing scale or orientation drift, the work would offer a practical way to leverage foundation-model priors in monocular dense reconstruction while adding multi-task capability through the feature parameterization. The combination of EM stabilization with Gaussian Splatting and ICP is a coherent technical direction, though its impact depends on the strength of the supporting analysis and results.
major comments (2)
- [Abstract and §3] Abstract and §3 (EM formulation): the central claim that the E-step assignment of foundation-model points to Gaussians followed by M-step updates to means, covariances, opacities, and multi-modal features produces globally metric-consistent geometry is load-bearing, yet no equations, pseudocode, convergence analysis, or drift bounds are supplied; without a global scale anchor or regularization term to counteract the relative/view-dependent nature of the input priors, it is unclear whether mismatches in assignment propagate inconsistencies across frames.
- [§4] §4 (pose estimation and mapping loop): the ICP-based monocular alignment is described at a high level but no ablation or quantitative comparison isolates its contribution to consistency versus the EM component; this is required to substantiate that the overall pipeline avoids new drift relative to pure foundation-model or standard Gaussian-SLAM baselines.
minor comments (2)
- [Abstract] The abstract lists evaluation datasets but does not name the specific baselines, metrics (e.g., ATE, reconstruction accuracy, segmentation IoU), or quantitative improvements; these details should appear in the abstract or early results section for immediate clarity.
- [§3] Notation for the multi-modal feature parameterization (e.g., how features are stored per Gaussian and queried) is introduced only at a high level; a short table or explicit equations would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the clarity and analysis of the EM formulation and the mapping loop. We will revise the manuscript accordingly to address these points.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (EM formulation): the central claim that the E-step assignment of foundation-model points to Gaussians followed by M-step updates to means, covariances, opacities, and multi-modal features produces globally metric-consistent geometry is load-bearing, yet no equations, pseudocode, convergence analysis, or drift bounds are supplied; without a global scale anchor or regularization term to counteract the relative/view-dependent nature of the input priors, it is unclear whether mismatches in assignment propagate inconsistencies across frames.
Authors: We agree that a more explicit mathematical presentation of the EM procedure is warranted. The revised manuscript will include the full E-step assignment equations (soft probabilities based on Mahalanobis distance to Gaussian means) and M-step closed-form updates for means, covariances, opacities, and multi-modal features. We will also add pseudocode for the per-frame EM iteration and a short discussion of convergence under the standard EM assumptions. The global Gaussian Splatting map itself functions as the scale anchor through joint optimization across all observations; no additional regularization term is introduced because the shared parameters enforce consistency. While we do not derive new drift bounds, the empirical results on 7-Scenes, TUM RGB-D, and Replica already quantify the absence of noticeable scale or orientation drift relative to baselines. A brief paragraph summarizing this mechanism and the supporting metrics will be added. revision: yes
-
Referee: [§4] §4 (pose estimation and mapping loop): the ICP-based monocular alignment is described at a high level but no ablation or quantitative comparison isolates its contribution to consistency versus the EM component; this is required to substantiate that the overall pipeline avoids new drift relative to pure foundation-model or standard Gaussian-SLAM baselines.
Authors: We concur that an ablation isolating the ICP alignment from the EM stabilization would strengthen the claims. In the revision we will add a dedicated ablation subsection that reports absolute trajectory error, relative pose error, and map reconstruction metrics for three variants: (i) full MonoEM-GS, (ii) EM disabled (direct per-frame fusion into the Gaussian map), and (iii) ICP replaced by the foundation-model pose estimates alone. These results will be compared against the original baselines to demonstrate that the combination prevents additional drift. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The abstract and provided context describe MonoEM-GS as coupling Gaussian Splatting with an EM formulation for stabilizing noisy view-dependent geometry from foundation models, plus ICP for pose estimation, with multi-modal feature parameterization for downstream tasks. No equations, fitting procedures, or derivation steps are detailed that reduce any prediction or result to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled via prior work, and no renaming of known results occurs. The pipeline is presented as an integration approach evaluated on external benchmarks (7-Scenes, TUM RGB-D, Replica), making the claims self-contained against independent data rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Real-Time RGB- D Camera Relocalization,
B. Glocker, S. Izadi, J. Shotton, and A. Criminisi, “Real-Time RGB- D Camera Relocalization,” in2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), 2013, pp. 173–179
2013
-
[2]
A Benchmark for the Evaluation of RGB-D SLAM Systems,
J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A Benchmark for the Evaluation of RGB-D SLAM Systems,” inProc. of the International Conference on Intelligent Robot Systems (IROS), Oct. 2012
2012
-
[3]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Ma, Y . Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Verma,et al., “The Replica Dataset: A Digital Replica of Indoor Spaces,”arXiv preprint arXiv:1906.05797, 2019
work page internal anchor Pith review arXiv 1906
-
[4]
ORB-SLAM: A Versatile and Accurate Monocular SLAM System,
R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos, “ORB-SLAM: A Versatile and Accurate Monocular SLAM System,”IEEE Transactions on Robotics, vol. 31, no. 5, pp. 1147–1163, 2015
2015
-
[5]
VGGT: Visual Geometry Grounded Transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “VGGT: Visual Geometry Grounded Transformer,” in Proceedings of the Computer Vision and Pattern Recognition Con- ference, 2025, pp. 5294–5306
2025
-
[6]
DUSt3R: Geometric 3D Vision Made Easy,
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud, “DUSt3R: Geometric 3D Vision Made Easy,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 697–20 709
2024
-
[7]
Grounding Image Matching in 3D with MASt3R,
V . Leroy, Y . Cabon, and J. Revaud, “Grounding Image Matching in 3D with MASt3R,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 71–91
2024
-
[8]
MUSt3R: Multi-view Network for Stereo 3D Recon- struction,
Y . Cabon, L. Stoffl, L. Antsfeld, G. Csurka, B. Chidlovskii, J. Revaud, and V . Leroy, “MUSt3R: Multi-view Network for Stereo 3D Recon- struction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 1050–1060
2025
-
[9]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Y . Wang, J. Zhou, H. Zhu, W. Chang, Y . Zhou, Z. Li, J. Chen, J. Pang, C. Shen, and T. He, “Pi3: Permutation-Equivariant Visual Geometry Learning,”arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Continuous 3d perception model with persistent state.arXiv preprint arXiv:2501.12387, 2025
Q. Wang, Y . Zhang, A. Holynski, A. A. Efros, and A. Kanazawa, “Continuous 3D Perception Model with Persistent State,”arXiv preprint arXiv:2501.12387, 2025
-
[11]
arXiv preprint arXiv:2505.12549 (2025)
D. Maggio, H. Lim, and L. Carlone, “VGGT-SLAM: Dense RGB SLAM Optimized on the SL(4) Manifold,”arXiv preprint arXiv:2505.12549, 2025
-
[12]
VGGT-SLAM 2.0: Real-time Dense Feed- forward Scene Reconstruction,
D. Maggio and L. Carlone, “VGGT-SLAM 2.0: Real-Time Dense Feed-forward Scene Reconstruction,”arXiv preprint arXiv:2601.19887, 2026
-
[13]
MASt3R-SLAM: Real- time Dense SLAM with 3D Reconstruction Priors,
R. Murai, E. Dexheimer, and A. J. Davison, “MASt3R-SLAM: Real- time Dense SLAM with 3D Reconstruction Priors,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 695–16 705
2025
-
[14]
Colored Point Cloud Registration Revisited,
J. Park, Q.-Y . Zhou, and V . Koltun, “Colored Point Cloud Registration Revisited,” inProceedings of the IEEE international Conference on Computer Vision, 2017, pp. 143–152
2017
-
[15]
Efficient Variants of the ICP Algo- rithm,
S. Rusinkiewicz and M. Levoy, “Efficient Variants of the ICP Algo- rithm,” inProceedings of the Third International Conference on 3-D Digital Imaging and Modeling. IEEE, 2001, pp. 145–152
2001
-
[16]
Object Modelling by Registration of Multiple Range Images,
Y . Chen and G. Medioni, “Object Modelling by Registration of Multiple Range Images,”Image and Vision Computing, vol. 10, no. 3, pp. 145–155, 1992
1992
-
[17]
3D Gaussian Splatting for Real-time Radiance Field Rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, G. Drettakis,et al., “3D Gaussian Splatting for Real-time Radiance Field Rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[18]
ViSTA-SLAM: Visual SLAM with Symmetric Two-view Association,
G. Zhang, S. Qian, X. Wang, and D. Cremers, “ViSTA-SLAM: Visual SLAM with Symmetric Two-view Association,”arXiv preprint arXiv:2509.01584, 2025
-
[19]
K. Deng, Z. Ti, J. Xu, J. Yang, and J. Xie, “VGGT-Long: Chunk it, Loop it, Align it–Pushing VGGT’s Limits on Kilometer-scale Long RGB Sequences,”arXiv preprint arXiv:2507.16443, 2025
-
[20]
Thrun, W
S. Thrun, W. Burgard, and D. Fox,Probabilistic Robotics, ser. Intelli- gent Robotics and Autonomous Agents series. MIT Press, 2005. [On- line]. Available: https://books.google.de/books?id=2Zn6AQAAQBAJ
2005
-
[21]
Gaussian Splatting SLAM,
H. Matsuki, R. Murai, P. H. J. Kelly, and A. J. Davison, “Gaussian Splatting SLAM,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[22]
Splat- SLAM: Globally Optimized RGB-only SLAM with 3D Gaussians,
E. Sandstr ¨om, G. Zhang, K. Tateno, M. Oechsle, M. Niemeyer, Y . Zhang, M. Patel, L. Van Gool, M. Oswald, and F. Tombari, “Splat- SLAM: Globally Optimized RGB-only SLAM with 3D Gaussians,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1680–1691
2025
-
[23]
SplaTAM: Splat Track & Map 3D Gaussians for Dense RGB-D SLAM,
N. Keetha, J. Karhade, K. M. Jatavallabhula, G. Yang, S. Scherer, D. Ramanan, and J. Luiten, “SplaTAM: Splat Track & Map 3D Gaussians for Dense RGB-D SLAM,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 357–21 366
2024
-
[24]
Hi-SLAM2: Geometry-aware Gaussian SLAM for Fast Monocular Scene Reconstruction,
W. Zhang, Q. Cheng, D. Skuddis, N. Zeller, D. Cremers, and N. Haala, “Hi-SLAM2: Geometry-aware Gaussian SLAM for Fast Monocular Scene Reconstruction,”IEEE Transactions on Robotics, vol. 41, pp. 6478–6493, 2025
2025
-
[25]
SING3R-SLAM: Submap-based Indoor Monocular Gaussian SLAM with 3D Reconstruction Priors
K. Li, M. Niemeyer, S. Wang, S. Gasperini, N. Navab, and F. Tombari, “SING3R-SLAM: Submap-based Indoor Monocular Gaussian SLAM with 3D Reconstruction Priors,”arXiv preprint arXiv:2511.17207, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth Anything 3: Recovering the Visual Space from Any Views,”arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
N. Keetha, N. M ¨uller, J. Sch ¨onberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antunes,et al., “MapAnything: Universal Feed-Forward Metric 3D Reconstruction,”arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby,et al., “DINOv2: Learning Robust Visual Features without Supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa,et al., “DI- NOv3,”arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
OMCL: Open- vocabulary Monte Carlo Localization,
E. Kruzhkov, R. Memmesheimer, and S. Behnke, “OMCL: Open- vocabulary Monte Carlo Localization,”IEEE Robotics and Automation Letters, vol. 11, no. 3, pp. 2698–2705, 2026
2026
-
[31]
Open-V ocabulary Online Semantic Mapping for SLAM,
T. B. Martins, M. R. Oswald, and J. Civera, “Open-V ocabulary Online Semantic Mapping for SLAM,”IEEE Robotics and Automation Letters, 2025
2025
-
[32]
RayFronts: Open-set Semantic Ray Frontiers for Online Scene Understanding and Exploration,
O. Alama, A. Bhattacharya, H. He, S. Kim, Y . Qiu, W. Wang, C. Ho, N. Keetha, and S. Scherer, “RayFronts: Open-set Semantic Ray Frontiers for Online Scene Understanding and Exploration,” in 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, pp. 5930–5937
2025
-
[33]
The Faiss library,
M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P.-E. Mazar ´e, M. Lomeli, L. Hosseini, and H. J ´egou, “The Faiss library,” 2024
2024
-
[34]
Updating Mean and Variance Estimates: An Improved Method,
D. West, “Updating Mean and Variance Estimates: An Improved Method,”Communications of the ACM, vol. 22, no. 9, pp. 532–535, 1979
1979
-
[35]
gsplat: An Open- source Library for Gaussian Splatting,
V . Ye, R. Li, J. Kerr, M. Turkulainen, B. Yi, Z. Pan, O. Seiskari, J. Ye, J. Hu, M. Tancik, and A. Kanazawa, “gsplat: An Open- source Library for Gaussian Splatting,”Journal of Machine Learning Research, vol. 26, no. 34, pp. 1–17, 2025
2025
-
[36]
evo: Python package for the evaluation of odometry and SLAM
M. Grupp, “evo: Python package for the evaluation of odometry and SLAM.” https://github.com/MichaelGrupp/evo, 2017
2017
-
[37]
ConceptGraphs: Open-vocabulary 3D Scene Graphs for Perception and Planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa,et al., “ConceptGraphs: Open-vocabulary 3D Scene Graphs for Perception and Planning,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 5021–5028
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.