Recognition: unknown
Self-supervised Pretraining of Cell Segmentation Models
Pith reviewed 2026-05-10 14:59 UTC · model grok-4.3
The pith
Self-supervised pretraining on unlabeled cell images produces representations better aligned with microscopy than those from natural-image models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
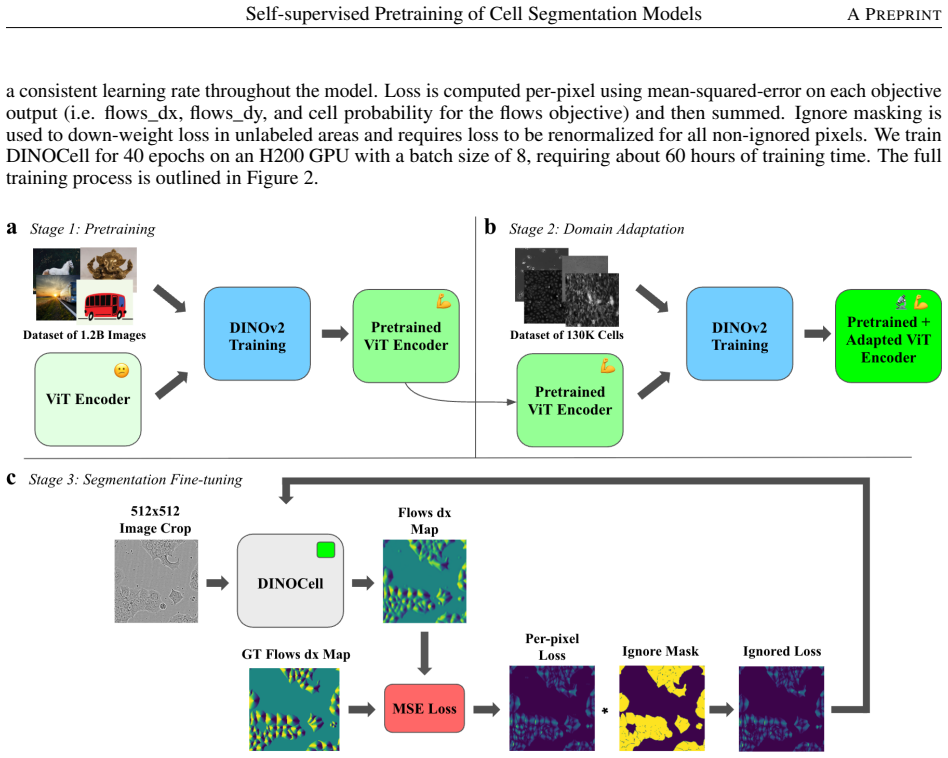
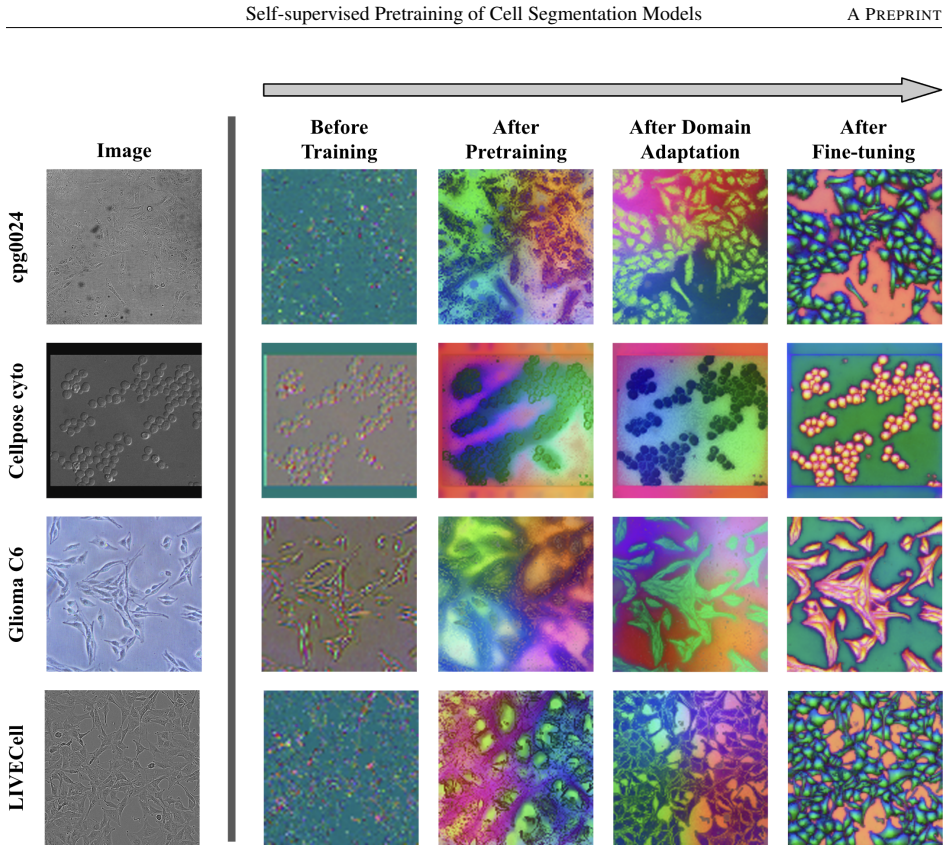
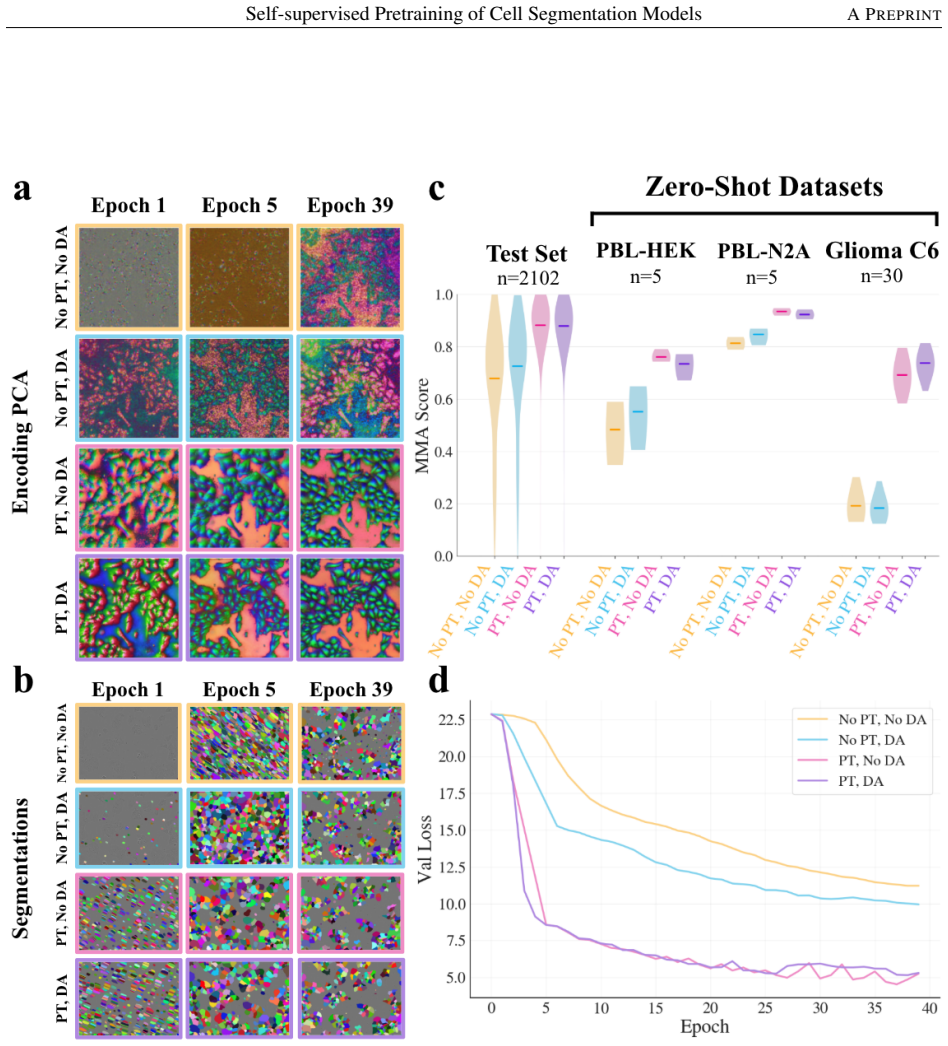
The framework adapts representations from a natural-image model to microscopy data by performing continued self-supervised training on unlabeled cell images before supervised fine-tuning for instance segmentation. This produces higher segmentation performance on the LIVECell benchmark and demonstrates strong zero-shot performance on three out-of-distribution microscopy datasets compared to direct initialization with weights from natural-image segmentation models.
What carries the argument
Continued self-supervised pretraining on unlabeled cell images to adapt natural-image model representations to the microscopy domain.
Load-bearing premise
That the observed improvements in segmentation performance stem from the continued self-supervised pretraining step creating representations more suitable for microscopy rather than from other elements of the model training or data selection process.
What would settle it
A direct comparison where the continued self-supervised pretraining is omitted but all other training steps and data are kept identical, and the resulting model shows no improvement or worse performance on the cell segmentation benchmark and out-of-distribution tests.
Figures



read the original abstract
Instance segmentation enables the analysis of spatial and temporal properties of cells in microscopy images by identifying the pixels belonging to each cell. However, progress is constrained by the scarcity of high-quality labeled microscopy datasets. Many recent approaches address this challenge by initializing models with segmentation-pretrained weights from large-scale natural-image models such as Segment Anything Model (SAM). However, representations learned from natural images often encode objectness and texture priors that are poorly aligned with microscopy data, leading to degraded performance under domain shift. We propose DINOCell, a self-supervised framework for cell instance segmentation that leverages representations from DINOv2 and adapts them to microscopy through continued self-supervised training on unlabeled cell images prior to supervised fine-tuning. On the LIVECell benchmark, DINOCell achieves a SEG score of 0.784, improving by 10.42% over leading SAM-based models, and demonstrates strong zero-shot performance on three out-of-distribution microscopy datasets. These results highlight the benefits of domain-adapted self-supervised pretraining for robust cell segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DINOCell, a self-supervised framework that initializes from DINOv2 weights and performs continued self-supervised pretraining on unlabeled cell microscopy images before supervised fine-tuning for instance segmentation. It claims a SEG score of 0.784 on the LIVECell benchmark (10.42% improvement over leading SAM-based models) and strong zero-shot performance on three out-of-distribution microscopy datasets, attributing the gains to better alignment of representations with microscopy data via domain-adaptive pretraining.
Significance. If the performance gains are shown to arise specifically from the continued self-supervised pretraining step, the work would provide a useful method for adapting natural-image self-supervised models to microscopy, addressing domain shift and reducing dependence on scarce labeled cell data. Evaluation on an external public benchmark plus OOD zero-shot tests offers a reasonable basis for assessing robustness.
major comments (1)
- The central claim attributes the 10.42% SEG improvement and OOD gains to continued self-supervised pretraining on unlabeled cell images. However, no ablation is reported that applies the identical supervised fine-tuning protocol, augmentations, and loss to the unmodified original DINOv2 weights. This control experiment is load-bearing for isolating the contribution of the domain-adaptive pretraining from other training choices or backbone effects.
minor comments (3)
- The reported SEG scores lack error bars, standard deviations, or statistical significance tests, which weakens assessment of the reliability of the numeric gains.
- The abstract and provided description omit key details of the full training protocol, including hyperparameters, pretraining epochs, dataset sizes, and exact augmentations; these must be expanded in the methods for reproducibility.
- References to 'leading SAM-based models' in the abstract are not named or cited; specific model names and citations should appear in the results section for precise comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for highlighting an important aspect of our experimental design. We address the major comment below and commit to incorporating the requested control in the revised manuscript.
read point-by-point responses
-
Referee: The central claim attributes the 10.42% SEG improvement and OOD gains to continued self-supervised pretraining on unlabeled cell images. However, no ablation is reported that applies the identical supervised fine-tuning protocol, augmentations, and loss to the unmodified original DINOv2 weights. This control experiment is load-bearing for isolating the contribution of the domain-adaptive pretraining from other training choices or backbone effects.
Authors: We agree that this control experiment is essential for rigorously isolating the contribution of the continued self-supervised pretraining on unlabeled cell images. The original manuscript emphasizes comparisons to SAM-based models to demonstrate practical gains on the LIVECell benchmark and zero-shot transfer. However, to directly address the referee's point and substantiate the attribution to domain-adaptive pretraining, we will add the requested ablation in the revised version. Specifically, we will fine-tune the unmodified original DINOv2 weights using the identical supervised fine-tuning protocol, augmentations, and loss function employed for DINOCell, and report the resulting SEG score on LIVECell together with zero-shot performance on the three out-of-distribution microscopy datasets. These results will be presented in the experiments section (with an updated table) to allow clear comparison. We believe this addition will strengthen the manuscript without altering our core claims. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper's derivation chain consists of (1) taking DINOv2 weights, (2) continued self-supervised pretraining on unlabeled microscopy images, and (3) supervised fine-tuning for instance segmentation. The load-bearing claims are quantitative improvements on the independent LIVECell benchmark (SEG 0.784, +10.42% over SAM baselines) plus zero-shot results on three separate OOD microscopy datasets. These metrics are computed on held-out test data using standard segmentation metrics and are not defined in terms of the method's own fitted quantities. No equations appear in the provided text; no self-definitional loops, fitted-input-as-prediction, or load-bearing self-citations are present. The attribution of gains specifically to the continued pretraining step is an empirical question (addressed by the skeptic via missing ablations), but that is a question of experimental design, not circularity in the derivation itself. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised pretraining on unlabeled cell images produces representations better aligned with microscopy than natural-image pretraining
invented entities (1)
-
DINOCell
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Way, Maria Kost-Alimova, Tsukasa Shibue, William F
Gregory P. Way, Maria Kost-Alimova, Tsukasa Shibue, William F. Harrington, Stanley Gill, Federica Piccioni, Tim Becker, Hamdah Shafqat-Abbasi, William C. Hahn, Anne E. Carpenter, Francisca Vazquez, and Shantanu Singh. Predicting cell health phenotypes using image-based morphology profiling.Molecular Biology of the Cell, 32(9):995–1005, April 2021
2021
-
[2]
Cole and Danielle Hunt
Richard W. Cole and Danielle Hunt. Light Microscopy as a Tool to Detect Apoptosis and Other Cellular Changes and Damage.Journal of biomolecular techniques: JBT, 36(1):3fc1f5fe.5d696e01, April 2025
2025
-
[3]
Welter, Sofia Benavides, Trevor K
Emma M. Welter, Sofia Benavides, Trevor K. Archer, Oksana Kosyk, and Anthony S. Zannas. Machine learning- based morphological quantification of replicative senescence in human fibroblasts.GeroScience, 46(2):2425–2439, April 2024
2024
-
[4]
Morphology-based deep learning enables accurate detection of senescence in mesenchymal stem cell cultures.BMC biology, 22(1):1, January 2024
Liangge He, Mingzhu Li, Xinglie Wang, Xiaoyan Wu, Guanghui Yue, Tianfu Wang, Yan Zhou, Baiying Lei, and Guangqian Zhou. Morphology-based deep learning enables accurate detection of senescence in mesenchymal stem cell cultures.BMC biology, 22(1):1, January 2024
2024
-
[5]
S. Oja, P. Komulainen, A. Penttilä, J. Nystedt, and M. Korhonen. Automated image analysis detects aging in clinical-grade mesenchymal stromal cell cultures.Stem Cell Research & Therapy, 9(1):6, January 2018
2018
-
[6]
Pratik Kamat, Nico Macaluso, Chanhong Min, Yukang Li, Anshika Agrawal, Aaron Winston, Lauren Pan, Bartholomew Starich, Teasia Stewart, Pei-Hsun Wu, Jean Fan, Jeremy Walston, and Jude M. Phillip. Single-cell morphology encodes functional subtypes of senescence in aging human dermal fibroblasts.bioRxiv: The Preprint Server for Biology, page 2024.05.10.59363...
2024
-
[7]
Vasilevich, Steven Vermeulen, Marloes Kamphuis, Nadia Roumans, Said Eroumé, Dennie G
Aliaksei S. Vasilevich, Steven Vermeulen, Marloes Kamphuis, Nadia Roumans, Said Eroumé, Dennie G. A. J. Hebels, Jeroen van de Peppel, Rika Reihs, Nick R. M. Beijer, Aurélie Carlier, Anne E. Carpenter, Shantanu Singh, and Jan de Boer. On the correlation between material-induced cell shape and phenotypical response of human mesenchymal stem cells.Scientific...
2020
-
[8]
Isar Nassiri and Matthew N. McCall. Systematic exploration of cell morphological phenotypes associated with a transcriptomic query.Nucleic Acids Research, 46(19):e116, November 2018
2018
-
[9]
Gilkes, Jude M
Pei-Hsun Wu, Daniele M. Gilkes, Jude M. Phillip, Akshay Narkar, Thomas Wen-Tao Cheng, Jorge Marchand, Meng-Horng Lee, Rong Li, and Denis Wirtz. Single-cell morphology encodes metastatic potential.Science Advances, 6(4):eaaw6938, January 2020
2020
-
[10]
Sykora, Milan Mrksich, and Neda Bagheri
Zeynab Mousavikhamene, Daniel J. Sykora, Milan Mrksich, and Neda Bagheri. Morphological features of single cells enable accurate automated classification of cancer from non-cancer cell lines.Scientific Reports, 11(1):24375, December 2021. 14 Self-supervised Pretraining of Cell Segmentation ModelsA PREPRINT
2021
-
[11]
Schneider, Wayne S
Caroline A. Schneider, Wayne S. Rasband, and Kevin W. Eliceiri. NIH Image to ImageJ: 25 years of image analysis.Nature Methods, 9(7):671–675, July 2012
2012
-
[12]
Roerdink and Arnold Meijster
Jos B.T.M. Roerdink and Arnold Meijster. The Watershed Transform: Definition, Algorithms and Parallelization Strategies.Fundamenta Informaticae, 41(1-2):187, January 2000
2000
-
[13]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment Anything, April 2023. arXiv:2304.02643 [cs]
work page internal anchor Pith review arXiv 2023
-
[14]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick La...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation, May 2015. arXiv:1505.04597 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
U-Net: deep learning for cell counting, detection, and morphometry.Nature Methods, 16(1):67–70, January 2019
Thorsten Falk, Dominic Mai, Robert Bensch, Özgün Çiçek, Ahmed Abdulkadir, Yassine Marrakchi, Anton Böhm, Jan Deubner, Zoe Jäckel, Katharina Seiwald, Alexander Dovzhenko, Olaf Tietz, Cristina Dal Bosco, Sean Walsh, Deniz Saltukoglu, Tuan Leng Tay, Marco Prinz, Klaus Palme, Matias Simons, Ilka Diester, Thomas Brox, and Olaf Ronneberger. U-Net: deep learning...
2019
-
[17]
Cellpose: a generalist algorithm for cellular segmentation.Nature Methods, 18(1):100–106, January 2021
Carsen Stringer, Tim Wang, Michalis Michaelos, and Marius Pachitariu. Cellpose: a generalist algorithm for cellular segmentation.Nature Methods, 18(1):100–106, January 2021
2021
-
[18]
Cutler, Carsen Stringer, Teresa W
Kevin J. Cutler, Carsen Stringer, Teresa W. Lo, Luca Rappez, Nicholas Stroustrup, S. Brook Peterson, Paul A. Wiggins, and Joseph D. Mougous. Omnipose: a high-precision morphology-independent solution for bacterial cell segmentation.Nature Methods, 19(11):1438–1448, November 2022
2022
-
[19]
Segment anything in medical images.Nature Communications, 15(1):654, January 2024
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images.Nature Communications, 15(1):654, January 2024
2024
-
[20]
Malta, Saahil Sanganeriya, Emilio Aponte, Caitlin van Zyl, Danfei Xu, and Craig Forest
Alexandra Dunnum VandeLoo, Nathan J. Malta, Saahil Sanganeriya, Emilio Aponte, Caitlin van Zyl, Danfei Xu, and Craig Forest. SAMCell: Generalized label-free biological cell segmentation with segment anything.PLOS ONE, 20(9):e0319532, September 2025
2025
-
[21]
CellSAM: a foundation model for cell segmentation
Markus Marks, Uriah Israel, Rohit Dilip, Qilin Li, Changhua Yu, Emily Laubscher, Ahamed Iqbal, Elora Pradhan, Ada Ates, Martin Abt, Caitlin Brown, Edward Pao, Shenyi Li, Alexander Pearson-Goulart, Pietro Perona, Georgia Gkioxari, Ross Barnowski, Yisong Yue, and David Van Valen. CellSAM: a foundation model for cell segmentation. Nature Methods, 22(12):2585...
2025
-
[22]
Cellpose-SAM: superhuman generalization for cellular segmentation, May 2025
Marius Pachitariu, Michael Rariden, and Carsen Stringer. Cellpose-SAM: superhuman generalization for cellular segmentation, May 2025. Pages: 2025.04.28.651001 Section: New Results
2025
-
[23]
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked Autoencoders Are Scalable Vision Learners, December 2021. arXiv:2111.06377 [cs]
-
[24]
A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A Simple Framework for Contrastive Learning of Visual Representations, July 2020. arXiv:2002.05709 [cs]
work page internal anchor Pith review arXiv 2020
-
[25]
Emerging properties in self-supervised vision transformers.arXiv preprint arXiv:2104.14294,
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging Properties in Self-Supervised Vision Transformers, May 2021. arXiv:2104.14294 [cs]
-
[26]
Wei Zhuo, Zhiyue Tang, Wufeng Xue, Hao Ding, Junkai Ji, and Linlin Shen. UINO-FSS: Unifying Representation Learning and Few-shot Segmentation via Hierarchical Distillation and Mamba-HyperCorrelation, November 2025. arXiv:2504.15669 [cs]
-
[27]
Mohammed Baharoon, Waseem Qureshi, Jiahong Ouyang, Yanwu Xu, Abdulrhman Aljouie, and Wei Peng. Evaluating General Purpose Vision Foundation Models for Medical Image Analysis: An Experimental Study of DINOv2 on Radiology Benchmarks, September 2024. arXiv:2312.02366 [cs]
-
[28]
Beilei Cui, Mobarakol Islam, Long Bai, and Hongliang Ren. Surgical-DINO: adapter learning of foundation models for depth estimation in endoscopic surgery.International Journal of Computer Assisted Radiology and Surgery, 19(6):1013–1020, 2024
2024
-
[29]
Carpenter, Beth A
Erin Weisbart, Ankur Kumar, John Arevalo, Anne E. Carpenter, Beth A. Cimini, and Shantanu Singh. Cell Painting Gallery: an open resource for image-based profiling.Nature Methods, 21(10):1775–1777, October 2024. 15 Self-supervised Pretraining of Cell Segmentation ModelsA PREPRINT
2024
-
[30]
Sokolnicki, and Anne E
Vebjorn Ljosa, Katherine L. Sokolnicki, and Anne E. Carpenter. Annotated high-throughput microscopy image sets for validation.Nature Methods, 9(7):637–637, July 2012
2012
-
[31]
Li, Gabriella Rustici, Aleksandra Tarkowska, Anatole Chessel, Simone Leo, Bálint Antal, Richard K
Eleanor Williams, Josh Moore, Simon W. Li, Gabriella Rustici, Aleksandra Tarkowska, Anatole Chessel, Simone Leo, Bálint Antal, Richard K. Ferguson, Ugis Sarkans, Alvis Brazma, Rafael E. Carazo Salas, and Jason R. Swedlow. Image Data Resource: a bioimage data integration and publication platform.Nature Methods, 14(8):775–781, August 2017
2017
-
[32]
DIC image reconstruction using an energy minimization framework to visualize optical path length distribution.Scientific Reports, 6:30420, July 2016
Krisztian Koos, József Molnár, Lóránd Kelemen, Gábor Tamás, and Peter Horvath. DIC image reconstruction using an energy minimization framework to visualize optical path length distribution.Scientific Reports, 6:30420, July 2016
2016
-
[33]
Blood Cell Segmentation Dataset, 2023
Deponker Depto, Shazidur Rahman, Mekayel Hosen, Shapna Akter, Tamanna Reme, Aimon Rahman, Hasib Zunai, Sohel Rahman, and Jeet Lahiri. Blood Cell Segmentation Dataset, 2023
2023
-
[34]
DeepBacs – Escherichia coli bright field segmentation dataset, October 2021
Christoph Spahn and Mike Heilemann. DeepBacs – Escherichia coli bright field segmentation dataset, October 2021
2021
-
[35]
DeepBacs – Escherichia coli release from stationary phase - Bright field segmentation dataset and StarDist model, March 2022
Christoph Spahn and Mike Heilemann. DeepBacs – Escherichia coli release from stationary phase - Bright field segmentation dataset and StarDist model, March 2022
2022
-
[36]
DeepBacs – Staphylococcus aureus widefield segmentation dataset, October 2021
Pedro Matos Pereira and Mariana Pinho. DeepBacs – Staphylococcus aureus widefield segmentation dataset, October 2021
2021
-
[37]
Greenwald, David Van Valen, Erin Weisbart, Beth A Cimini, Trevor Cheung, Oscar Brück, Gary D
Jun Ma, Ronald Xie, Shamini Ayyadhury, Cheng Ge, Anubha Gupta, Ritu Gupta, Song Gu, Yao Zhang, Gihun Lee, Joonkee Kim, Wei Lou, Haofeng Li, Eric Upschulte, Timo Dickscheid, José Guilherme de Almeida, Yixin Wang, Lin Han, Xin Yang, Marco Labagnara, V ojislav Gligorovski, Maxime Scheder, Sahand Jamal Rahi, Carly Kempster, Alice Pollitt, Leon Espinosa, Tam M...
2022
-
[38]
A convolutional neural network segments yeast microscopy images with high accuracy
Nicola Dietler, Matthias Minder, V ojislav Gligorovski, Augoustina Maria Economou, Denis Alain Henri Lucien Joly, Ahmad Sadeghi, Chun Hei Michael Chan, Mateusz Kozi´nski, Martin Weigert, Anne-Florence Bitbol, and Sahand Jamal Rahi. A convolutional neural network segments yeast microscopy images with high accuracy. Nature Communications, 11(1):5723, November 2020
2020
-
[39]
Jackson, Nabeel Khalid, Nicola Bevan, Timothy Dale, Andreas Dengel, Sheraz Ahmed, Johan Trygg, and Rickard Sjögren
Christoffer Edlund, Timothy R. Jackson, Nabeel Khalid, Nicola Bevan, Timothy Dale, Andreas Dengel, Sheraz Ahmed, Johan Trygg, and Rickard Sjögren. LIVECell—A large-scale dataset for label-free live cell segmentation. Nature Methods, 18(9):1038–1045, September 2021
2021
-
[40]
McCourty, Berardo M
Tianhao Zhang, Heather J. McCourty, Berardo M. Sanchez-Tafolla, Anton Nikolaev, and Lyudmila S. Mihaylova. MorphoSeg: An uncertainty-aware deep learning method for biomedical segmentation of complex cellular morphologies.Neurocomputing, 647:130511, September 2025
2025
-
[41]
Smith, Fred A
Athul Vijayan, Tejasvinee Atul Mody, Qin Yu, Adrian Wolny, Lorenzo Cerrone, Soeren Strauss, Miltos Tsiantis, Richard S. Smith, Fred A. Hamprecht, Anna Kreshuk, and Kay Schneitz. A deep learning-based toolkit for 3D nuclei segmentation and quantitative analysis in cellular and tissue context.Development, 151(14):dev202800, July 2024
2024
-
[42]
Glioma C6: A Novel Dataset for Training and Benchmarking Cell Segmentation, November
Roman Malashin, Svetlana Pashkevich, Daniil Ilyukhin, Arseniy V olkov, Valeria Yachnaya, Andrey Denisov, and Maria Mikhalkova. Glioma C6: A Novel Dataset for Training and Benchmarking Cell Segmentation, November
- [43]
-
[44]
Reith, Jannik Franzen, Dinesh R
Fabian H. Reith, Jannik Franzen, Dinesh R. Palli, J. Lorenz Rumberger, and Dagmar Kainmueller. SelfAdapt: Unsupervised Domain Adaptation of Cell Segmentation Models, August 2025. arXiv:2508.11411 [cs]
-
[45]
A systematic evaluation of computational methods for cell segmentation.Briefings in Bioinformatics, 25(5):bbae407, September 2024
Yuxing Wang, Junhan Zhao, Hongye Xu, Cheng Han, Zhiqiang Tao, Dawei Zhou, Tong Geng, Dongfang Liu, and Zhicheng Ji. A systematic evaluation of computational methods for cell segmentation.Briefings in Bioinformatics, 25(5):bbae407, September 2024
2024
-
[46]
Jackson, Johan Trygg, Rickard Sjögren, Andreas Dengel, and Sheraz Ahmed
Nabeel Khalid, Fabian Schmeisser, Mohammadmahdi Koochali, Mohsin Munir, Christoffer Edlund, Timothy R. Jackson, Johan Trygg, Rickard Sjögren, Andreas Dengel, and Sheraz Ahmed. Point2Mask: A Weakly Supervised Approach for Cell Segmentation Using Point Annotation. In Guang Yang, Angelica Aviles-Rivero, Michael Roberts, and Carola-Bibiane Schönlieb, editors,...
2022
-
[47]
High-Throughput Low-Cost Segmentation of Brightfield Microscopy Live Cell Images, August 2025
Surajit Das, Gourav Roy, and Pavel Zun. High-Throughput Low-Cost Segmentation of Brightfield Microscopy Live Cell Images, August 2025. arXiv:2508.14106 [q-bio] version: 2. 16 Self-supervised Pretraining of Cell Segmentation ModelsA PREPRINT
-
[48]
Contrast limited adaptive histogram equalization
Karel Zuiderveld. Contrast limited adaptive histogram equalization. InGraphics gems IV, pages 474–485. Academic Press Professional, Inc., USA, August 1994
1994
-
[49]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, June 2021. arXiv:2010.11929 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[50]
CNN-watershed: A watershed transform with predicted markers for corneal endothelium image segmentation.Biomedical Signal Processing and Control, 68:102805, July 2021
Adrian Kucharski and Anna Fabija ´nska. CNN-watershed: A watershed transform with predicted markers for corneal endothelium image segmentation.Biomedical Signal Processing and Control, 68:102805, July 2021
2021
-
[51]
iBOT: Image BERT Pre-Training with Online Tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. iBOT: Image BERT Pre-Training with Online Tokenizer, January 2022. arXiv:2111.07832 [cs]
work page internal anchor Pith review arXiv 2022
-
[52]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization, January 2019. arXiv:1711.05101 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[53]
Balak, Pavel Karas, Tereza Bolcková, Markéta Štreitová, Craig Carthel, Stefano Coraluppi, Nathalie Harder, Karl Rohr, Klas E
Martin Maška, Vladimír Ulman, David Svoboda, Pavel Matula, Petr Matula, Cristina Ederra, Ainhoa Urbiola, Tomás España, Subramanian Venkatesan, Deepak M.W. Balak, Pavel Karas, Tereza Bolcková, Markéta Štreitová, Craig Carthel, Stefano Coraluppi, Nathalie Harder, Karl Rohr, Klas E. G. Magnusson, Joakim Jaldén, Helen M. Blau, Oleh Dzyubachyk, Pavel Kˇrížek, ...
2014
-
[54]
Sorokin, Petr Matula, Carlos Ortiz-de Solórzano, and Michal Kozubek
Pavel Matula, Martin Maška, Dmitry V . Sorokin, Petr Matula, Carlos Ortiz-de Solórzano, and Michal Kozubek. Cell Tracking Accuracy Measurement Based on Comparison of Acyclic Oriented Graphs.PLOS ONE, 10(12):e0144959, December 2015
2015
-
[55]
I.T. Jolliffe. Principal Component Analysis | Springer Nature Link, 2002. 6 Supplementary Materials 6.1 Fine-tuning Dataset Descriptions BBBC030 [ 32]: The BBBC030 dataset contains 60 images of Chinese Hamster Ovary (CHO) cells. The images were taken on a DIC microscope with a 20x magnification. The dataset is available here: https://bbbc.broadinstitute.o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.