Recognition: unknown
LoViF 2026 The First Challenge on Weather Removal in Videos
Pith reviewed 2026-05-10 16:16 UTC · model grok-4.3
The pith
The LoViF 2026 challenge supplies a paired synthetic-real dataset to benchmark video restoration under rain and snow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By releasing the WRV dataset and running the challenge, the authors establish a concrete testbed in which algorithms must restore clean video sequences from inputs degraded by adverse weather while preserving scene structure, motion, and producing temporally coherent output.
What carries the argument
The WRV dataset of 18 videos with 1216 paired synthesized-degraded and real ground-truth frames, split equally into train, validation, and test sets, together with the joint fidelity-plus-perceptual evaluation protocol.
If this is right
- Future video restoration methods can be compared directly on the same paired data and metrics.
- Emphasis on temporal consistency will favor algorithms that model frame-to-frame coherence rather than frame-independent processing.
- Public release of the dataset and fact sheets enables rapid iteration and extension by the community.
- The 1:1:1 split encourages methods that generalize from limited training data to unseen test sequences.
Where Pith is reading between the lines
- The paired real-ground-truth design may transfer to other video restoration problems such as low-light enhancement or motion blur removal.
- If the synthesis model proves too simple, longer or more diverse weather sequences will be required to close the domain gap.
- Success on this benchmark could accelerate deployment of weather-robust video pipelines in surveillance and autonomous driving.
Load-bearing premise
The synthetic weather overlays applied to real clean frames reproduce the appearance, statistics, and motion dynamics of actual rain and snow in video.
What would settle it
Quantitative or visual failure of top challenge entries when tested on a new set of naturally captured rainy or snowy videos that were never passed through the synthesis pipeline.
Figures





read the original abstract
This paper presents a review of the LoViF 2026 Challenge on Weather Removal in Videos. The challenge encourages the development of methods for restoring clean videos from inputs degraded by adverse weather conditions such as rain and snow, with an emphasis on achieving visually plausible and temporally consistent results while preserving scene structure and motion dynamics. To support this task, we introduce a new short-form WRV dataset tailored for video weather removal. It consists of 18 videos 1,216 synthesized frames paired with 1,216 real-world ground-truth frames at a resolution of 832 x 480, and is split into training, validation, and test sets with a ratio of 1:1:1. The goal of this challenge is to advance robust and realistic video restoration under real-world weather conditions, with evaluation protocols that jointly consider fidelity and perceptual quality. The challenge attracted 37 participants and received 5 valid final submissions with corresponding fact sheets, contributing to progress in weather removal for videos. The project is publicly available at https://www.codabench.org/competitions/13462/.
Editorial analysis
A structured set of objections, weighed in public.
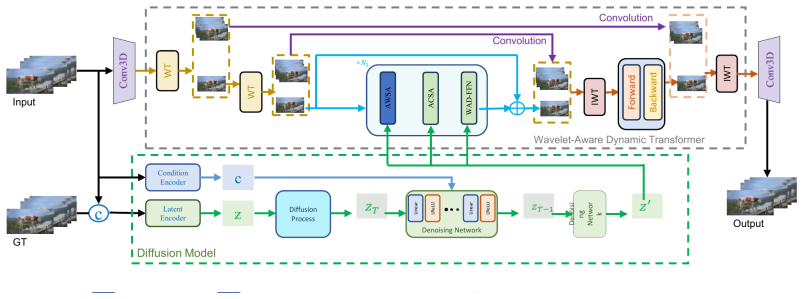
Referee Report
Summary. This paper reviews the LoViF 2026 Challenge on Weather Removal in Videos. It describes the task of restoring clean videos from inputs degraded by rain and snow while preserving temporal consistency and scene structure. The authors introduce the WRV dataset consisting of 18 videos with 1,216 synthesized degraded frames paired with 1,216 real-world ground-truth frames at 832 x 480 resolution, split 1:1:1 into training, validation, and test sets. The challenge attracted 37 participants and received 5 valid final submissions with fact sheets; the project is hosted publicly on CodaBench.
Significance. If the reported participation numbers and dataset release are accurate, the manuscript provides a useful organizational record of community activity in video weather removal. The public dataset and challenge platform constitute a concrete resource that can support future benchmarking of temporally consistent restoration methods. No machine-checked proofs or parameter-free derivations are present, but the factual documentation of submissions and the open availability of the competition infrastructure are clear strengths for a challenge report.
minor comments (1)
- Abstract: the phrase '18 videos 1,216 synthesized frames' lacks punctuation or a conjunction and should be rephrased for readability (e.g., '18 videos and 1,216 synthesized frames').
Simulated Author's Rebuttal
We thank the referee for the positive summary of our manuscript and the recommendation to accept. No major comments were raised in the report.
Circularity Check
No circularity: purely descriptive challenge report
full rationale
The manuscript is an organizational report on a competition, stating participation counts (37 entrants, 5 submissions), introducing a small synthetic dataset (18 videos, 1216 frames), and describing evaluation protocols without any equations, derivations, predictions, or load-bearing technical claims. No self-citations, ansatzes, or fitted inputs are invoked; the contribution reduces to factual enumeration and dataset release rather than any asserted equivalence or inference that could be circular by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The oxford radar robotcar dataset: A radar extension to the oxford robotcar dataset
Dan Barnes, Matthew Gadd, Paul Murcutt, Paul Newman, and Ingmar Posner. The oxford radar robotcar dataset: A radar extension to the oxford robotcar dataset. In2020 IEEE international conference on robotics and automation (ICRA), pages 6433–6438. IEEE, 2020. 1
2020
-
[2]
Flux.2: Frontier visual intelligence
Black Forest Labs. Flux.2: Frontier visual intelligence. https://bfl.ai/blog/flux-2, 2025. 3
2025
-
[3]
Basicvsr++: Improving video super- resolution with enhanced propagation and alignment
Kelvin CK Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy. Basicvsr++: Improving video super- resolution with enhanced propagation and alignment. In CVPR, pages 5972–5981, 2022. 1
2022
-
[4]
Snow removal in video: A new dataset and a novel method
Haoyu Chen, Jingjing Ren, Jinjin Gu, Hongtao Wu, Xuequan Lu, Haoming Cai, and Lei Zhu. Snow removal in video: A new dataset and a novel method. InICCV, pages 13165– 13176, 2023. 1, 6
2023
-
[5]
Robust video content alignment and compensation for rain removal in a cnn framework
Jie Chen, Cheen-Hau Tan, Junhui Hou, Lap-Pui Chau, and He Li. Robust video content alignment and compensation for rain removal in a cnn framework. InCVPR, pages 6286– 6295, 2018. 7
2018
-
[6]
All snow re- moved: Single image desnowing algorithm using hierarchi- cal dual-tree complex wavelet representation and contradict channel loss
Wei-Ting Chen, Hao-Yu Fang, Cheng-Lin Hsieh, Cheng-Che Tsai, I Chen, Jian-Jiun Ding, and Sy-Yen Kuo. All snow re- moved: Single image desnowing algorithm using hierarchi- cal dual-tree complex wavelet representation and contradict channel loss. InICCV, pages 4196–4205, 2021. 1
2021
-
[7]
LoViF 2026 challenge on real-world all-in-one im- age restoration: Methods and results
Xiang Chen, Hao Li, Jiangxin Dong, Jinshan Pan, Xin Li, et al. LoViF 2026 challenge on real-world all-in-one im- age restoration: Methods and results. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
2026
-
[8]
Lin Chih-Hao et al. Controllable weather synthesis and removal with video diffusion models.arXiv preprint arXiv:2505.00704, 2025. 1
-
[9]
Adair: Adaptive all-in-one image restoration via frequency mining and mod- ulation
Yuning Cui, Syed Waqas Zamir, Salman Khan, Alois Knoll, Mubarak Shah, and Fahad Shahbaz Khan. Adair: Adaptive all-in-one image restoration via frequency mining and mod- ulation. InICLR, pages 57335–57356, 2025. 5
2025
-
[10]
Learning truncated causal history model for video restoration
Amirhosein Ghasemabadi, Muhammad Kamran Janjua, Mo- hammad Salameh, and Di Niu. Learning truncated causal history model for video restoration. InNeurIPS, 2024. 6
2024
-
[11]
Multi-scale progressive fusion network for single image deraining
Kui Jiang, Zhongyuan Wang, Peng Yi, Chen Chen, Baojin Huang, Yimin Luo, Jiayi Ma, and Junjun Jiang. Multi-scale progressive fusion network for single image deraining. In CVPR, pages 8346–8355, 2020. 1
2020
-
[12]
Focal frequency loss for image reconstruction and synthesis
Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. Focal frequency loss for image reconstruction and synthesis. InICCV, pages 13919–13929, 2021. 7
2021
-
[13]
Raindrop clarity: A dual-focused dataset for day and night raindrop removal
Yeying Jin, Xin Li, Jiadong Wang, Yan Zhang, and Malu Zhang. Raindrop clarity: A dual-focused dataset for day and night raindrop removal. InECCV, pages 1–17. Springer,
-
[14]
Foundir: Unleashing million-scale training data to advance foundation models for image restoration
Hao Li, Xiang Chen, Jiangxin Dong, Jinhui Tang, and Jin- shan Pan. Foundir: Unleashing million-scale training data to advance foundation models for image restoration. InICCV, pages 12626–12636, 2025. 4
2025
-
[15]
Ntire 2025 challenge on day and night raindrop removal for dual-focused images: Methods and results
Xin Li, Yeying Jin, Xin Jin, Zongwei Wu, Bingchen Li, Yufei Wang, Wenhan Yang, Yu Li, Zhibo Chen, Bihan Wen, et al. Ntire 2025 challenge on day and night raindrop removal for dual-focused images: Methods and results. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1172–1183, 2025. 1
2025
-
[16]
NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Xin Li, Yeying Jin, Suhang Yao, Beibei Lin, Zhaoxin Fan, Wending Yan, Xin Jin, Zongwei Wu, Bingchen Li, Peishu Shi, Yufei Yang, Yu Li, Zhibo Chen, Bihan Wen, Robby Tan, Radu Timofte, et al. NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results . InProceedings of the IEEE/CVF Con- ference on Computer...
2026
-
[17]
LoViF 2026 the first challenge on human- oriented semantic image quality assessment: Methods and results
Xin Li, Daoli Xu, Wei Luo, Guoqiang Xiang, Haoran Li, Chengyu Zhuang, Zhibo Chen, Jian Guan, and Weipin- gand others Li. LoViF 2026 the first challenge on human- oriented semantic image quality assessment: Methods and results. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Work- shops, 2026. 2
2026
-
[18]
Desnownet: Context-aware deep network for snow removal
Yun-Fu Liu, Da-Wei Jaw, Shih-Chia Huang, and Jenq-Neng Hwang. Desnownet: Context-aware deep network for snow removal. InIEEE TIP, pages 3064–3073, 2018. 1
2018
-
[19]
The 1st workshop on low- level vision frontiers (lovif) at cvpr 2026.https:// lovif-cvpr2026-workshop.github.io/, 2026
LoViF Organizing Committee. The 1st workshop on low- level vision frontiers (lovif) at cvpr 2026.https:// lovif-cvpr2026-workshop.github.io/, 2026. 2
2026
-
[20]
LoViF 2026 the first challenge on holistic quality assessment for 4d world model (physcore)
Wei Luo, Yiting Lu, Xin Li, Haoran Li, Fengbin Guan, Chen Gao, Xin Jin, Yong Li, Zhibo Chen, et al. LoViF 2026 the first challenge on holistic quality assessment for 4d world model (physcore). InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
2026
-
[21]
3d weather editing with 4d gaussian field
Chenghao Qian, Wenjing Li, Yuhu Guo, and Gustav Markkula. 3d weather editing with 4d gaussian field. 1
-
[22]
Allweather-net: Unified image enhancement for autonomous driving under adverse weather and low-light conditions
Chenghao Qian, Mahdi Rezaei, Saeed Anwar, Wenjing Li, Tanveer Hussain, Mohsen Azarmi, and Wei Wang. Allweather-net: Unified image enhancement for autonomous driving under adverse weather and low-light conditions. InInternational Conference on Pattern Recognition, pages 151–166. Springer, 2024. 1
2024
-
[23]
Weathergs: 3d scene reconstruction in adverse weather conditions via gaussian splatting
Chenghao Qian, Yuhu Guo, Wenjing Li, and Gustav Markkula. Weathergs: 3d scene reconstruction in adverse weather conditions via gaussian splatting. In2025 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 185–191. IEEE, 2025. 1
2025
-
[24]
Weatherdg: Llm-assisted procedural weather generation for domain-generalized semantic segmentation.IEEE Robotics and Automation Letters, 2025
Chenghao Qian, Yuhu Guo, Yuhong Mo, and Wenjing Li. Weatherdg: Llm-assisted procedural weather generation for domain-generalized semantic segmentation.IEEE Robotics and Automation Letters, 2025. 1
2025
-
[25]
Weatheredit: Controllable weather editing with 4d gaussian field
Chenghao Qian, Wenjing Li, Yuhu Guo, and Gustav Markkula. Weatheredit: Controllable weather editing with 4d gaussian field. InProceedings of the AAAI Conference on Artificial Intelligence, pages 8511–8519, 2026. 1
2026
-
[26]
LoViF 2026 the first challenge on weather removal in videos
Chenghao Qian, Xin Li, Yeying Jin, Shangquan Sun, et al. LoViF 2026 the first challenge on weather removal in videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
2026
-
[27]
Ffa-net: Feature fusion attention network for single image dehazing
Xu Qin, Zhilin Wang, Yuanchao Bai, Xiaodong Xie, and Huizhu Jia. Ffa-net: Feature fusion attention network for single image dehazing. InAAAI, pages 11908–11915, 2020. 1
2020
-
[28]
Rethinking video deblurring with wavelet-aware dy- namic transformer and diffusion model
Chen Rao, Guangyuan Li, Zehua Lan, Jiakai Sun, Junsheng Luan, Lei Zhao, Huaizhong Lin, Jianfeng Dong, and Wei Xing. Rethinking video deblurring with wavelet-aware dy- namic transformer and diffusion model. InECCV, pages 421–437. Springer, 2025. 7
2025
-
[29]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMICCAI, pages 234–241. Springer, 2015. 4
2015
-
[30]
Se- mantic foggy scene understanding with synthetic data
Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Se- mantic foggy scene understanding with synthetic data. In International Journal of Computer Vision, pages 973–992. Springer, 2018. 1
2018
-
[31]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 5
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Vision transformers for single image dehazing
Yuda Song, Zhuqing He, Hui Qian, and Xin Du. Vision transformers for single image dehazing. InIEEE TIP, pages 1927–1941, 2023. 1
1927
-
[33]
Zero-shot video deraining with video diffusion models
Tuomas Varanka, Juan Luis Gonzalez, Hyeongwoo Kim, Pablo Garrido, and Xu Yao. Zero-shot video deraining with video diffusion models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 677–687, 2026. 1
2026
-
[34]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, 2017. 4
2017
-
[35]
Edvr: Video restoration with enhanced deformable convolutional networks
Xintao Wang, Kelvin CK Chan, Ke Yu, Chao Dong, and Chen Change Loy. Edvr: Video restoration with enhanced deformable convolutional networks. InCVPRW, pages 1954–1963, 2019. 1
1954
-
[36]
Basicsr: Open source image and video restoration toolbox.https://github.com/ XPixelGroup/BasicSR, 2022
Xintao Wang, Liangbin Xie, Ke Yu, Kelvin CK Chan, Chao Dong, and Chen Change Loy. Basicsr: Open source image and video restoration toolbox.https://github.com/ XPixelGroup/BasicSR, 2022. 6
2022
-
[37]
Image quality assessment: From error visibility to structural similarity.IEEE TIP, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: From error visibility to structural similarity.IEEE TIP, 13(4):600–612, 2004. 2
2004
-
[38]
Video enhancement with task-oriented flow
Tianfan Xue, Baian Chen, Jiajun Wu, Donglai Wei, and William T Freeman. Video enhancement with task-oriented flow. InInternational Journal of Computer Vision, pages 1106–1125. Springer, 2019. 1
2019
-
[39]
Self-learning video rain streak removal: When cyclic consistency meets temporal correspondence
Wenhan Yang, Robby T Tan, Shiqi Wang, Yuming Fang, and Jiaying Liu. Self-learning video rain streak removal: When cyclic consistency meets temporal correspondence. In CVPR, pages 1720–1729, 2020. 1
2020
-
[40]
Video adverse- weather-component suppression network via weather mes- senger and adversarial backpropagation
Yijun Yang, Wenhan Yang, and Robby T Tan. Video adverse- weather-component suppression network via weather mes- senger and adversarial backpropagation. InICCV, pages 13200–13210, 2023. 1
2023
-
[41]
Multi-stage progressive image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Multi-stage progressive image restoration. InCVPR, pages 14821–14831, 2021. 1
2021
-
[42]
The 1st LoViF challenge on efficient vlm for multimodal cre- ative quality scoring: Methods and results
Jusheng Zhang, Qinhan Lyu, Sizhuo Ma, Sheng Cao, Jian Wang, Xin Li, Keze Wang, Yongsen Zheng, Jing Yang, et al. The 1st LoViF challenge on efficient vlm for multimodal cre- ative quality scoring: Methods and results. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
2026
-
[43]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, pages 586–595,
-
[44]
Image super-resolution using very deep residual channel attention networks
Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. InECCV, pages 294– 310, 2018. 6
2018
-
[45]
Egvd: Event-guided video deraining.IEEE Transactions on Neural Networks and Learning Systems,
Yueyi Zhang, Jin Wang, Wenming Weng, Xiaoyan Sun, and Zhiwei Xiong. Egvd: Event-guided video deraining.IEEE Transactions on Neural Networks and Learning Systems,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.