Recognition: no theorem link
Governed Reasoning for Institutional AI
Pith reviewed 2026-05-10 15:28 UTC · model grok-4.3
The pith
Institutional decisions require a governed AI architecture that mandates human review before execution to prevent silent errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cognitive Core is a governed decision substrate built from nine typed cognitive primitives (retrieve, classify, investigate, verify, challenge, reflect, deliberate, govern, generate), a four-tier governance model where human review is a condition of execution rather than a post-hoc check, a tamper-evident SHA-256 hash-chain audit ledger endogenous to computation, and a demand-driven delegation architecture supporting both declared and autonomously reasoned epistemic sequences. On an 11-case balanced prior authorization appeal evaluation set, Cognitive Core reaches 91% accuracy with zero silent errors while prompt-based ReAct reaches 55% accuracy with 5-6 silent errors and Plan-and-Solve ReAc
What carries the argument
Cognitive Core, the system of nine typed cognitive primitives combined with four-tier governance requiring human review as a precondition for execution and an endogenous tamper-evident hash-chain audit ledger.
If this is right
- New institutional decision domains can be deployed by editing YAML configuration files instead of writing new code.
- Accountability is maintained through a hash-chain ledger that records every reasoning step as part of the computation itself.
- Governability, defined as reliably knowing when to defer to humans, becomes a required evaluation axis alongside accuracy.
- Execution of any determination depends on explicit governance signals, eliminating the possibility of silent incorrect outputs.
Where Pith is reading between the lines
- The same primitive-and-governance structure could be tested in adjacent regulated domains such as financial compliance or legal document review.
- The demand-driven delegation mechanism might allow the system to scale to longer reasoning chains without increasing silent-error risk.
- Making the nine primitives the fixed interface could simplify auditing and verification across different institutions.
- The configuration-driven deployment model reduces the engineering barrier for adopting governed AI in smaller organizations.
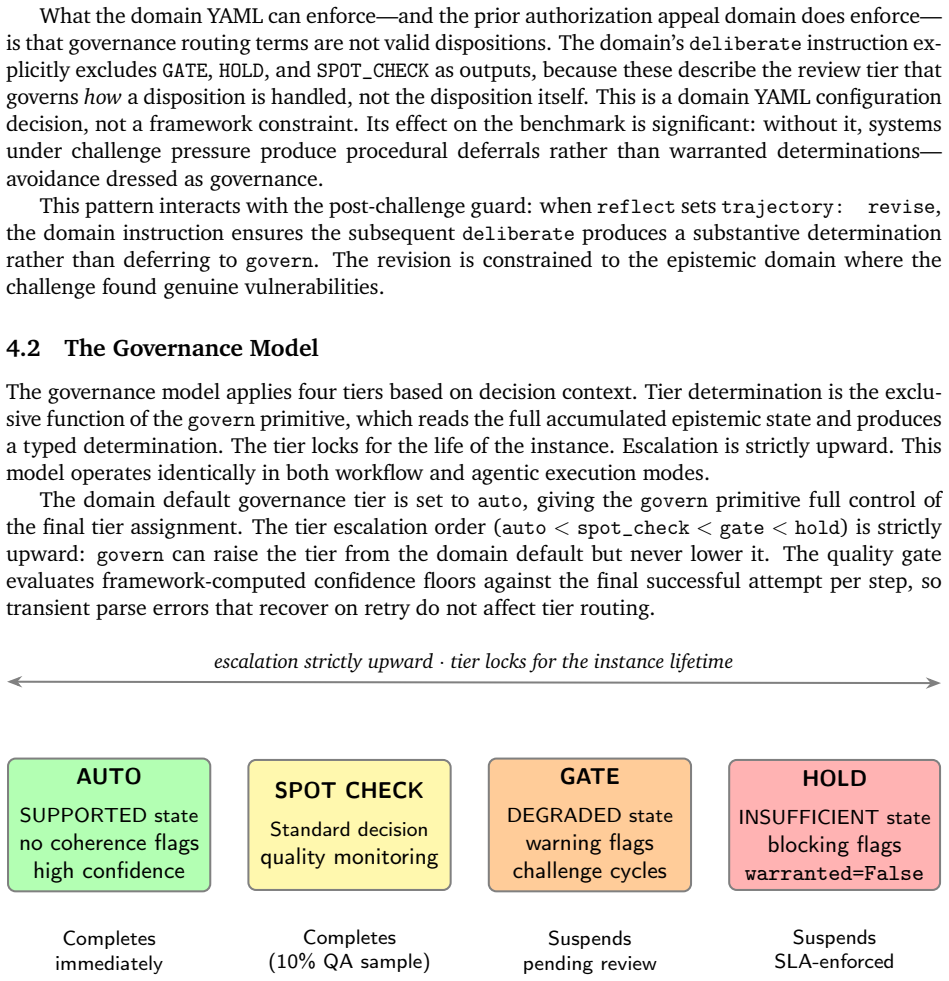
Load-bearing premise
The 11-case evaluation set is representative of real-world institutional decisions and that prompt-based implementations of ReAct and Plan-and-Solve accurately reflect realistic deployment alternatives to a governed framework.
What would settle it
A larger test on hundreds of actual prior authorization cases in which Cognitive Core produces silent errors at rates comparable to or higher than the ReAct and Plan-and-Solve baselines.
Figures




read the original abstract
Institutional decisions -- regulatory compliance, clinical triage, prior authorization appeal -- require a different AI architecture than general-purpose agents provide. Agent frameworks infer authority conversationally, reconstruct accountability from logs, and produce silent errors: incorrect determinations that execute without any human review signal. We propose Cognitive Core: a governed decision substrate built from nine typed cognitive primitives (retrieve, classify, investigate, verify, challenge, reflect, deliberate, govern, generate), a four-tier governance model where human review is a condition of execution rather than a post-hoc check, a tamper-evident SHA-256 hash-chain audit ledger endogenous to computation, and a demand-driven delegation architecture supporting both declared and autonomously reasoned epistemic sequences. We benchmark three systems on an 11-case balanced prior authorization appeal evaluation set. Cognitive Core achieves 91% accuracy against 55% (ReAct) and 45% (Plan-and-Solve). The governance result is more significant: CC produced zero silent errors while both baselines produced 5-6. We introduce governability -- how reliably a system knows when it should not act autonomously -- as a primary evaluation axis for institutional AI alongside accuracy. The baselines are implemented as prompts, representing the realistic deployment alternative to a governed framework. A configuration-driven domain model means deploying a new institutional decision domain requires YAML configuration, not engineering capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Cognitive Core as a governed decision substrate for institutional AI tasks such as prior authorization appeals. It is built from nine typed cognitive primitives (retrieve, classify, investigate, verify, challenge, reflect, deliberate, govern, generate), a four-tier governance model that treats human review as a precondition for execution, an endogenous tamper-evident SHA-256 hash-chain audit ledger, and demand-driven delegation supporting declared and reasoned epistemic sequences. The authors benchmark the system against prompt-based ReAct and Plan-and-Solve implementations on an 11-case balanced prior authorization appeal evaluation set, reporting 91% accuracy and zero silent errors for Cognitive Core versus 55% and 45% accuracy with 5-6 silent errors for the baselines. They introduce governability as a primary evaluation axis alongside accuracy and note that new domains can be deployed via YAML configuration rather than custom engineering.
Significance. If the reported performance and governance advantages are substantiated with complete methodological detail, the work could meaningfully advance institutional AI by shifting emphasis from general-purpose agent frameworks to systems that embed accountability, auditability, and explicit non-autonomous behavior as first-class properties. The configuration-driven deployment model and the explicit focus on silent-error prevention are practical strengths that address real deployment barriers in regulated domains.
major comments (1)
- [Abstract and Evaluation] Abstract and Evaluation section: The central claims of 91% accuracy with zero silent errors (versus 55%/45% and 5-6 silent errors for the baselines) rest on an 11-case evaluation set, yet the manuscript supplies no case-selection criteria, protocol for establishing ground truth, inter-annotator agreement statistics, operational definition of silent error (including how it is detected), or statistical significance tests. With n=11, these omissions make it impossible to determine whether the accuracy gap or the governability result is robust, reproducible, or free of selection bias, rendering the primary empirical support for the architecture load-bearing but unsupported.
minor comments (1)
- [Abstract] The abstract refers to a 'balanced' evaluation set without specifying the balance criterion or case distribution; this should be clarified in the evaluation section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying key gaps in the reporting of our evaluation. We address the comment below and will make corresponding revisions to improve transparency.
read point-by-point responses
-
Referee: Abstract and Evaluation section: The central claims of 91% accuracy with zero silent errors (versus 55%/45% and 5-6 silent errors for the baselines) rest on an 11-case evaluation set, yet the manuscript supplies no case-selection criteria, protocol for establishing ground truth, inter-annotator agreement statistics, operational definition of silent error (including how it is detected), or statistical significance tests. With n=11, these omissions make it impossible to determine whether the accuracy gap or the governability result is robust, reproducible, or free of selection bias, rendering the primary empirical support for the architecture load-bearing but unsupported.
Authors: We agree that the current manuscript does not supply adequate methodological detail on the evaluation. In the revised version we will expand the Evaluation section to describe the case-selection criteria used to construct the balanced 11-case set, the protocol followed to establish ground truth, inter-annotator agreement statistics where they were collected, an explicit operational definition of silent error together with the mechanism by which it is detected via the governance tiers and audit ledger, and a discussion of the limitations imposed by the small sample size. We will also clarify that, given n=11, the results are presented as descriptive illustrations of the architecture rather than as statistically powered claims, and we will make the evaluation cases available in supplementary material to support reproducibility and independent assessment of selection bias. revision: yes
Circularity Check
No circularity; empirical claims rest on direct measurement rather than self-referential derivation.
full rationale
The paper describes an architecture (Cognitive Core with nine primitives, four-tier governance, hash-chain ledger) and then reports direct empirical results on an 11-case prior-authorization set: 91% accuracy and zero silent errors versus 55%/45% and 5-6 silent errors for prompt-based ReAct and Plan-and-Solve. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the supplied text. Governability is introduced as an explicit new evaluation axis defined by the presence/absence of human-review signals, not presupposed by the accuracy numbers. The central claims are therefore measurements of the implemented system against baselines, not reductions of outputs to inputs by construction. The small evaluation set raises external-validity concerns but does not create circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Nine typed cognitive primitives are sufficient to model institutional decision processes
- domain assumption Human review can be reliably inserted as a condition of execution via the four-tier model
invented entities (1)
-
Cognitive Core
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Springer, 3rd ed., 2019
Weske, M.Business Process Management: Concepts, Languages, Architectures. Springer, 3rd ed., 2019
2019
-
[2]
Proposal for a Regulation on Artificial Intelligence (AI Act)
European Commission. Proposal for a Regulation on Artificial Intelligence (AI Act). EUR-Lex, 2021. 25
2021
-
[3]
Towards A Rigorous Science of Interpretable Machine Learning
Doshi-Velez, F. and Kim, B. Towards a rigorous science of interpretable machine learning. arXiv:1702.08608, 2017
work page internal anchor Pith review arXiv 2017
-
[4]
LangGraph: Build stateful, multi-actor applications with LLMs.https:// github.com/langchain-ai/langgraph, 2024
LangChain AI. LangGraph: Build stateful, multi-actor applications with LLMs.https:// github.com/langchain-ai/langgraph, 2024
2024
-
[5]
The Joint Commission, 2024
Joint Commission.Provision of Care, Treatment, and Services Standards. The Joint Commission, 2024
2024
-
[6]
MIT Press, 1998
Klein, G.Sources of Power: How People Make Decisions. MIT Press, 1998
1998
-
[7]
and Olsen, J.P.Rediscovering Institutions: The Organizational Basis of Politics
March, J.G. and Olsen, J.P.Rediscovering Institutions: The Organizational Basis of Politics. Free Press, 1989
1989
-
[8]
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature Machine Intelligence, 1(5):206–215, 2019
Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature Machine Intelligence, 1(5):206–215, 2019
2019
- [9]
-
[10]
Macmillan, 4th ed., 1997
Simon, H.A.Administrative Behavior. Macmillan, 4th ed., 1997
1997
-
[11]
MIT Press, 3rd ed., 1996
Simon, H.A.The Sciences of the Artificial. MIT Press, 3rd ed., 1996
1996
-
[12]
Temporal: Build invincible apps.https://temporal.io, 2024
Temporal Technologies. Temporal: Build invincible apps.https://temporal.io, 2024
2024
-
[13]
ReAct: Synergizing Reasoning and Acting in Language Models.ICLR, 2023
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. ReAct: Synergizing Reasoning and Acting in Language Models.ICLR, 2023
2023
-
[14]
Academic Press, 2nd ed., 2000
Zeigler, B.P., Kim, T.G., and Praehofer, H.Theory of Modeling and Simulation. Academic Press, 2nd ed., 2000
2000
-
[15]
and Vangheluwe, H
Van Tendeloo, Y. and Vangheluwe, H. The Modelling and Simulation of DEVS Models in PythonPDEVS.Simulation: Transactions of the Society for Modeling and Simulation Interna- tional, 2014
2014
-
[16]
Cognitive Core: Governed Reasoning for Institutional AI.https://github.com/ dioufseck-rgb/cognitive-core, 2026
Seck, M. Cognitive Core: Governed Reasoning for Institutional AI.https://github.com/ dioufseck-rgb/cognitive-core, 2026
2026
-
[17]
InProceedings of the 61st Annual Meeting of the ACL, pp
Wang, L., Xu, W., Lan, Y., Hu, Z., Lan, Y., Lee, R.K.W., andLim, E.P.Plan-and-SolvePrompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. InProceedings of the 61st Annual Meeting of the ACL, pp. 2609–2634, Toronto, Canada, 2023
2023
-
[18]
Gu, L., Zhu, Y., Sang, H., Wang, Z., Sui, D., Tang, W., Harrison, E., Gao, J., Yu, L., and Ma, L. MedAgentAudit: Diagnosing and Quantifying Collaborative Failure Modes in Medical Multi- Agent Systems.arXiv:2510.10185, 2025
-
[19]
This is a deliberate design choice, not a limitation
Gent, E.AI’sWrongAnswersAreBad.ItsWrongReasoningIsWorse.IEEESpectrum, December 2025.https://spectrum.ieee.org/ai-reasoning-failures 26 A Baseline Agent Implementations A.1 Implementation Philosophy The ReAct and Plan-and-Solve baselines are implemented as prompts — which is what a well- resourced engineering team would actually deploy for this task withou...
2025
-
[20]
Defines all four dispositions (OVERTURN, UPHOLD, PARTIAL, REMAND) as equally valid out- comes
-
[21]
States that UPHOLD and REMAND are correct answers when evidence supports them
-
[22]
Requires a procedural defect check (CHSC 1374.31(b)) as the first evaluation step
-
[23]
Instructs that when criteria are not met and no higher source overrides them, the denial stands
-
[24]
C004 produced OVERTURN despite the explicit instruction that UPHOLD is correct when criteria are not met
Defines REMAND as the correct disposition when the denial notice itself is procedurally defective The neutral framing fixed REMAND detection (D001 and D003 both correct) but did not resolve approval prior bias on UPHOLD cases. C004 produced OVERTURN despite the explicit instruction that UPHOLD is correct when criteria are not met. The approval prior opera...
-
[25]
Is structured to reach whichever disposition the evidence supports—all four dispositions equally valid
-
[26]
Includes a procedural defect check as a required plan element 27
-
[27]
Requires a disposition decision tree: under what conditions is each of OVERTURN / UPHOLD / PARTIAL / REMAND the correct answer?
-
[28]
Phase2(Execution)receivesthefullplanplusthecompletecaseinputanddomainknowledge
For each plan step, specifies both the positive and negative finding The planning phase generates 11–19K character plans that correctly identify the regulatory hi- erarchy, applicable criteria, and decision conditions. Phase2(Execution)receivesthefullplanplusthecompletecaseinputanddomainknowledge. Itis instructed to follow the plan’s disposition decision ...
-
[29]
At least 2 cases per disposition class (OVERTURN, UPHOLD, REMAND, PARTIAL)
-
[30]
Cases from multiple letter groups (A, B, C, D, E, G) to ensure diversity
-
[31]
Inclusion of known hard cases (G003 authority sycophancy, B001 per-level asymmetry, C003 procedural defect)
-
[32]
Case GT Key Reasoning A001OVERTURN Myelomalacia on MRI, PT contraindicated by physician declaration
Exclusion of cases that are near-duplicates within the same disposition class 28 B.2 Case Descriptions Table 5: 11-case evaluation set: case descriptions and ground truth reasoning. Case GT Key Reasoning A001OVERTURN Myelomalacia on MRI, PT contraindicated by physician declaration. CIC 10169.5(a)(1) and (a)(3) both apply. Plan criteria legally unenforceab...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.