Recognition: unknown
Efficient Process Reward Modeling via Contrastive Mutual Information
Pith reviewed 2026-05-10 16:36 UTC · model grok-4.3
The pith
Contrastive pointwise mutual information automatically labels rewards for each reasoning step using only internal model probabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CPMI quantifies a reasoning step's contribution by computing the difference in pointwise mutual information between the step paired with the correct target and the step paired with hard-negative alternatives, using the model's token-level probabilities directly as the signal for reward labeling.
What carries the argument
Contrastive pointwise mutual information (CPMI), which contrasts a step's information gain toward the correct answer against hard-negative alternatives to produce an automatic step-level reward score.
If this is right
- Process reward models can be trained on much larger datasets because labeling no longer requires expensive repeated sampling.
- Verification of chain-of-thought steps becomes feasible at scale for mathematical reasoning tasks without proportional increases in compute.
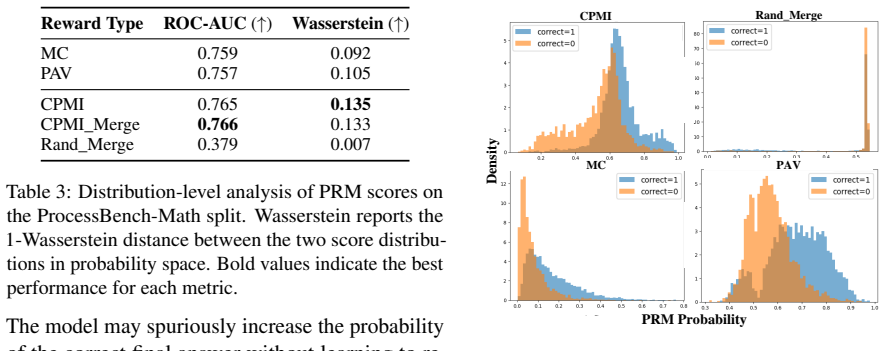
- Accuracy on process-level evaluation and downstream benchmarks improves or matches Monte Carlo baselines while cutting dataset construction time by 84 percent and token generation by 98 percent.
- Reward signals for intermediate steps can be generated on the fly from a single forward pass rather than requiring external estimation procedures.
Where Pith is reading between the lines
- The approach suggests that internal model uncertainty estimates can stand in for external verification signals across other structured generation tasks such as code or proof construction.
- If CPMI generalizes, it could enable online reward modeling where the same model both generates and scores its own reasoning steps during inference.
- The contrastive framing may extend to settings where only partial outcome labels are available, by using model-derived negatives to simulate missing supervision.
- Combining CPMI with outcome-based rewards could create hybrid training objectives that balance step-level and final-answer signals with minimal added cost.
Load-bearing premise
The model's internal token probabilities, when contrasted with hard-negative alternatives, reliably indicate whether a reasoning step contributes to reaching the correct final answer.
What would settle it
A controlled comparison on a held-out set of human-annotated reasoning trajectories where high-CPMI steps are shown not to correlate with actual progress toward correct answers more strongly than low-CPMI steps, or where training a process reward model on CPMI labels produces lower accuracy than one trained on Monte Carlo labels.
Figures





read the original abstract
Recent research has devoted considerable effort to verifying the intermediate reasoning steps of chain-of-thought (CoT) trajectories using process reward models (PRMs) and other verifier models. However, training a PRM typically requires human annotators to assign reward scores to each reasoning step, which is both costly and time-consuming. Existing automated approaches, such as Monte Carlo (MC) estimation, also demand substantial computational resources due to repeated LLM rollouts. To overcome these limitations, we propose contrastive pointwise mutual information (CPMI), a novel automatic reward labeling method that leverages the model's internal probability to infer step-level supervision while significantly reducing the computational burden of annotating dataset. CPMI quantifies how much a reasoning step increases the mutual information between the step and the correct target answer relative to hard-negative alternatives. This contrastive signal serves as a proxy for the step's contribution to the final solution and yields a reliable reward. The experimental results show that CPMI-based labeling reduces dataset construction time by 84% and token generation by 98% compared to MC estimation, while achieving higher accuracy on process-level evaluations and mathematical reasoning benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces contrastive pointwise mutual information (CPMI) as an automatic labeling method for process reward models (PRMs) in chain-of-thought trajectories. CPMI computes a contrast between a reasoning step's pointwise mutual information with the correct final answer versus hard-negative alternatives, using only the base LLM's internal token probabilities as a proxy for the step's contribution to the solution. The work claims this yields reliable rewards while reducing dataset construction time by 84% and token generation by 98% relative to Monte Carlo estimation, with higher accuracy on process-level evaluations and mathematical reasoning benchmarks.
Significance. If the CPMI proxy is shown to correlate reliably with ground-truth step quality, the approach would meaningfully advance scalable PRM training by removing dependence on human annotation and expensive rollouts, enabling broader use of process supervision for reasoning verification in LLMs.
major comments (2)
- [Abstract] Abstract: the claim that CPMI 'yields a reliable reward' and produces higher-accuracy PRMs rests on the unverified assumption that the model's internal probabilities, when contrasted against hard-negatives, indicate genuine causal contribution to the correct answer. No direct correlation study between CPMI scores and human/MC-derived step labels is reported, leaving the proxy validity untested.
- [Experimental results] The experimental results section does not describe controls for hard-negative construction (e.g., minimal edits that flip correctness) or statistical significance testing of the accuracy gains, both of which are load-bearing for the superiority claim over MC estimation.
minor comments (2)
- [Method] Clarify in the method description whether the PRM is trained on labels from the same base model or a separate verifier, to address potential circularity in the reward signal.
- [Abstract] The abstract reports efficiency numbers without specifying the exact hardware, batch sizes, or number of rollouts used in the MC baseline, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The comments have prompted us to clarify the validation of our method and strengthen the experimental reporting. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that CPMI 'yields a reliable reward' and produces higher-accuracy PRMs rests on the unverified assumption that the model's internal probabilities, when contrasted against hard-negatives, indicate genuine causal contribution to the correct answer. No direct correlation study between CPMI scores and human/MC-derived step labels is reported, leaving the proxy validity untested.
Authors: We acknowledge that the original manuscript does not present a direct correlation study between CPMI scores and human-annotated or MC-derived step labels. The reliability of the proxy is supported indirectly by the fact that PRMs trained using CPMI labels achieve higher accuracy on process-level evaluations and mathematical reasoning benchmarks than those using MC estimation. To address this concern directly, we have added a new analysis in the revised manuscript that examines the correlation between CPMI and MC rewards on a sample of reasoning steps, as well as a qualitative discussion of why the contrastive approach captures causal contribution. We believe this addition provides the requested validation without altering the core claims. revision: yes
-
Referee: [Experimental results] The experimental results section does not describe controls for hard-negative construction (e.g., minimal edits that flip correctness) or statistical significance testing of the accuracy gains, both of which are load-bearing for the superiority claim over MC estimation.
Authors: We agree with the referee that the experimental section would benefit from more details on hard-negative construction and from statistical significance testing. In the revised version of the manuscript, we have expanded the description of how hard negatives are constructed, specifying the use of minimal edits to the reasoning steps that result in incorrect final answers. We have also included statistical significance tests for the reported accuracy improvements over MC estimation, using appropriate tests such as McNemar's test for paired comparisons, and report the resulting p-values. These revisions ensure the superiority claims are more robustly supported. revision: yes
Circularity Check
No circularity: CPMI is an independent proxy validated empirically
full rationale
The paper introduces CPMI as a contrastive measure computed from the base LLM's token probabilities to automatically label process rewards, serving as a cheaper alternative to MC rollouts. The derivation defines CPMI explicitly in terms of pointwise mutual information contrasts against hard negatives, then reports downstream empirical gains on labeling efficiency and benchmark accuracy. No equation or claim reduces the final result to its inputs by construction, nor does any load-bearing step rely on self-citation chains or fitted parameters renamed as predictions. The proxy's validity is treated as an empirical question tested via separate PRM training and evaluation, not assumed tautologically from the definition.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
Anti-Self-Distillation reverses self-distillation signals via PMI to fix overconfidence on structural tokens, matching GRPO baseline accuracy 2-10x faster with up to 11.5 point gains across 4B-30B models.
Reference graph
Works this paper leans on
-
[1]
Alphamath almost zero: process supervision without process
Alphamath almost zero: Process supervision without process.arXiv preprint arXiv:2405.03553. Wenhu Chen and 1 others. 2022. Program of thoughts prompting: Disentangling computation from reason- ing for numerical reasoning tasks.arXiv preprint arXiv:2211.12588. Jie Cheng, Ruixi Qiao, Lijun Li, Chao Guo, Junle Wang, Gang Xiong, Yisheng Lv, and Fei-Yue Wang. ...
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, and 1 others. 2024. Omni-math: A universal olympiad level mathematic benchmark for large lan- guage models. InProceedings of the International Conference on Learning Representations (ICLR). Luyu Gao, Aman Madaan, Shuyan...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Rewarding progress: Scaling auto- mated process verifiers for llm reasoning
Hlmea: Unsupervised entity alignment based on hybrid language models.Proceedings of the AAAI Conference on Artificial Intelligence, 39(11):11888– 11896. Wei Liu, Siya Qi, Xinyu Wang, Chen Qian, Yali Du, and Yulan He. 2025. Nover: Incentive training for language models via verifier-free reinforcement learn- ing. Amrith Setlur, Chirag Nagpal, Adam Fisch, Xi...
-
[4]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Math-shepherd: Verify and reinforce llms step- by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, Bangkok, Thailand. Association for Computational Linguistics. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, A...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.