Recognition: 2 theorem links
· Lean TheoremAnti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
Pith reviewed 2026-05-13 01:25 UTC · model grok-4.3
The pith
Reversing the self-distillation objective counters per-token biases from privileged context and accelerates math reasoning training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
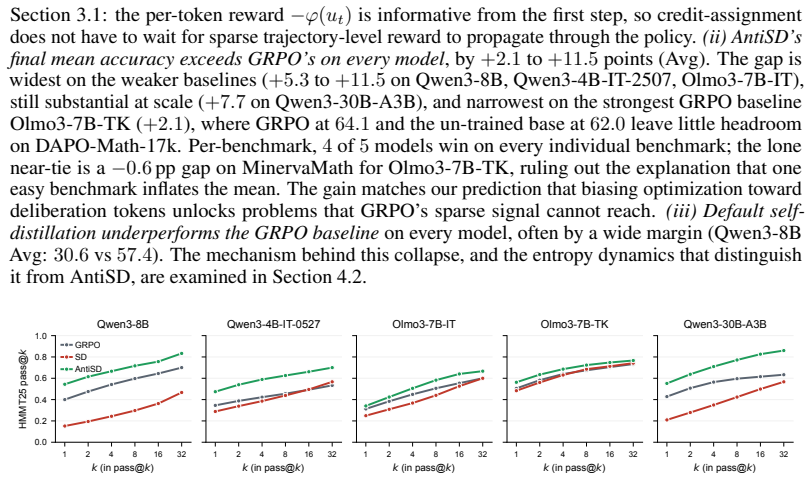
On-policy self-distillation fails to deliver reliable gains in math reasoning because the privileged context inflates the teacher's confidence on tokens already implied by the solution and deflates it on deliberation tokens. Anti-Self-Distillation ascends the divergence between student and teacher instead of descending it, reversing the per-token sign and yielding a naturally bounded advantage in one step. An entropy-triggered gate disables the term once teacher entropy collapses. The resulting method reaches the GRPO baseline accuracy in 2 to 10 times fewer training steps and improves final accuracy by up to 11.5 points across models from 4B to 30B parameters.
What carries the argument
The Anti-Self-Distillation objective that ascends the divergence from the teacher policy, diagnosed by pointwise mutual information on per-token effects and controlled by an entropy-triggered gate.
If this is right
- Models reach the GRPO baseline accuracy in 2 to 10 times fewer training steps.
- Final accuracy improves by up to 11.5 points over the baseline.
- The method works as a drop-in replacement inside existing reinforcement learning pipelines for reasoning.
- The gains hold across model sizes from 4B to 30B parameters on math reasoning benchmarks.
- Self-improvement becomes more reliable because the training signal no longer requires a stronger external teacher.
Where Pith is reading between the lines
- The PMI diagnosis of token-level bias could be applied to other distillation or knowledge-transfer settings beyond reasoning RL.
- If the same confidence-inflation pattern appears on non-math tasks such as coding, the reversal approach may transfer directly.
- Combining the bounded advantage with other RL estimators could further stabilize training on longer reasoning traces.
- A direct test would measure whether AntiSD reduces the volume of verified solutions needed to reach a given accuracy level.
Load-bearing premise
The privileged context inflates the teacher's confidence on tokens already implied by the solution and deflates it on deliberation tokens that drive multi-step search.
What would settle it
An experiment that keeps the same models, benchmarks, and training setup but removes the sign reversal or the entropy gate and still observes the reported speed-up and accuracy gains would show the claimed mechanism is not responsible.
Figures




read the original abstract
On-policy self-distillation, where a student is pulled toward a copy of itself conditioned on privileged context (e.g., a verified solution or feedback), offers a promising direction for advancing reasoning capability without a stronger external teacher. Yet in math reasoning the gains are inconsistent, even when the same approach succeeds elsewhere. A pointwise mutual information analysis traces the failure to the privileged context itself: it inflates the teacher's confidence on tokens already implied by the solution (structural connectives, verifiable claims) and deflates it on deliberation tokens ("Wait", "Let", "Maybe") that drive multi-step search. We propose Anti-Self-Distillation (AntiSD), which ascends a divergence between student and teacher rather than descending it: this reverses the per-token sign and yields a naturally bounded advantage in one step. An entropy-triggered gate disables the term once the teacher entropy collapses, completing a drop-in replacement for default self-distillation. Across five models from 4B to 30B parameters on math reasoning benchmarks, AntiSD reaches the GRPO baseline's accuracy in 2 to 10x fewer training steps and improves final accuracy by up to 11.5 points. AntiSD opens a path to scalable self-improvement, where a language model bootstraps its own reasoning through its training signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper diagnoses failures of on-policy self-distillation in math reasoning via pointwise mutual information (PMI) analysis, which shows that privileged context inflates teacher confidence on structural/implied tokens while deflating it on deliberation tokens. It proposes Anti-Self-Distillation (AntiSD) that ascends rather than descends the divergence, yielding a bounded advantage, combined with an entropy-triggered gate to disable the term upon teacher entropy collapse. The method is presented as a drop-in replacement for standard self-distillation, with empirical claims of reaching GRPO baseline accuracy in 2-10x fewer steps and final accuracy gains up to 11.5 points across 4B-30B models on math benchmarks.
Significance. If the empirical results hold and the mechanism is mechanistically validated, AntiSD offers a lightweight, self-contained way to improve reasoning RL without external teachers, potentially aiding scalable self-improvement. The PMI diagnostic provides a concrete, falsifiable lens on token-level confidence mismatches that could generalize beyond the reported setting. The one-step bounded advantage and entropy gate are practical strengths that reduce hyperparameter sensitivity.
major comments (3)
- [§3] §3 (PMI analysis): The diagnosis that privileged context deflates probability on deliberation tokens (e.g., 'Wait', 'Let', 'Maybe') is plausible, but the manuscript provides no per-token probability measurements or checkpoint comparisons showing that ascending the divergence under AntiSD specifically raises these probabilities relative to standard self-distillation while the baseline does the opposite. Without this link, the reported accuracy and speed gains could stem from the entropy gate or other implementation details rather than the diagnosed cause.
- [§5] §5 (experiments): The central claims of 2-10x fewer training steps and up to 11.5-point gains are reported only via aggregate accuracy and step counts across five models; no ablation isolating the divergence-ascent term, no per-token analysis, and no statistical tests or variance across runs are supplied to confirm robustness or attribute gains to the PMI-motivated mechanism.
- [§4.2] §4.2 (entropy gate): The precise condition for disabling the AntiSD term (e.g., entropy threshold, measurement over which tokens) is not formalized, making it difficult to reproduce the claimed speedups or determine whether the gate is load-bearing for the final accuracy improvements.
minor comments (2)
- [Abstract] The abstract states specific numerical gains but supplies no baseline details, number of runs, or benchmark names; these should be added for immediate clarity.
- [§4] Notation for the divergence ascent and the one-step bounded advantage should be explicitly contrasted with the standard KL or reverse-KL objectives in an equation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight opportunities to strengthen the mechanistic evidence, experimental rigor, and reproducibility of Anti-Self-Distillation. We address each point below and will incorporate the suggested additions and clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (PMI analysis): The diagnosis that privileged context deflates probability on deliberation tokens (e.g., 'Wait', 'Let', 'Maybe') is plausible, but the manuscript provides no per-token probability measurements or checkpoint comparisons showing that ascending the divergence under AntiSD specifically raises these probabilities relative to standard self-distillation while the baseline does the opposite. Without this link, the reported accuracy and speed gains could stem from the entropy gate or other implementation details rather than the diagnosed cause.
Authors: We agree that an explicit link between the PMI diagnosis and the effect of divergence ascent would strengthen the mechanistic claim. In the revised version we will add per-token probability trajectories extracted from training checkpoints for representative deliberation tokens (e.g., 'Wait', 'Let', 'Maybe') under GRPO, standard self-distillation, and AntiSD. These plots will show that AntiSD increases probability mass on deliberation tokens while standard self-distillation decreases it, directly connecting the PMI analysis to the observed training dynamics and final gains. revision: yes
-
Referee: [§5] §5 (experiments): The central claims of 2-10x fewer training steps and up to 11.5-point gains are reported only via aggregate accuracy and step counts across five models; no ablation isolating the divergence-ascent term, no per-token analysis, and no statistical tests or variance across runs are supplied to confirm robustness or attribute gains to the PMI-motivated mechanism.
Authors: We acknowledge that the current experimental section relies on aggregate metrics. The revised manuscript will include: (i) an ablation that isolates the divergence-ascent term by comparing full AntiSD against a variant that retains only the entropy gate; (ii) the per-token probability analysis described above; and (iii) results from three independent runs per model size with mean, standard deviation, and paired statistical tests (e.g., Wilcoxon) to quantify robustness. These additions will allow readers to attribute performance differences specifically to the PMI-motivated component. revision: yes
-
Referee: [§4.2] §4.2 (entropy gate): The precise condition for disabling the AntiSD term (e.g., entropy threshold, measurement over which tokens) is not formalized, making it difficult to reproduce the claimed speedups or determine whether the gate is load-bearing for the final accuracy improvements.
Authors: We will formalize the entropy gate in Section 4.2 of the revision. The condition will be stated as: the AntiSD term is disabled for a given sequence when the average teacher entropy (computed over all tokens in the generated response) falls below a threshold τ = 0.8 nats; the threshold is applied uniformly across the sequence rather than per-token. We will also report the fraction of steps in which the gate activates across runs, clarifying its contribution to the observed speedups. revision: yes
Circularity Check
No significant circularity in derivation or claims.
full rationale
The paper motivates AntiSD via a PMI diagnosis of how privileged context affects per-token teacher probabilities, then defines the method as ascending (rather than descending) a divergence with an entropy gate. No equations, derivations, or self-referential steps appear in the abstract or described text that reduce the reported speedups or accuracy gains to a fitted quantity or input by construction. The empirical results on math benchmarks are independent measurements, not tautological outputs of the method definition itself. No load-bearing self-citations, uniqueness theorems, or renamed known results are invoked to force the central claims. This is a standard empirical proposal whose validity rests on external benchmark outcomes rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Privileged context inflates teacher confidence on implied tokens and deflates it on deliberation tokens
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ut = log πT(yt | x, c, y<t) / πS(yt | x, y<t) = PMI(yt ; c | x, y<t); AntiSD ascends DJSD via −φ(ut) with φ(u) = ½(softplus(u) − log 2)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Across five models ... AntiSD reaches the GRPO baseline's accuracy in 2 to 10× fewer training steps
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
work page 2024
-
[2]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs
Jasper Dekoninck, Nikola Jovanovi´c, Tim Gehrunger, Kári Rögnvalddson, Ivo Petrov, Chenhao Sun, and Martin Vechev. Beyond benchmarks: MathArena as an evaluation platform for mathematics with LLMs.arXiv preprint arXiv:2605.00674, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Revisiting on-policy distillation: Empirical failure modes and simple fixes, 2026
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes, 2026
work page 2026
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
arXiv preprint arXiv:2603.08660 , year=
Bingxiang He, Yuxin Zuo, Zeyuan Liu, Shangziqi Zhao, Zixuan Fu, Junlin Yang, Cheng Qian, Kaiyan Zhang, Yuchen Fan, Ganqu Cui, et al. How far can unsupervised rlvr scale llm training? arXiv preprint arXiv:2603.08660, 2026
-
[7]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of llms?arXiv preprint arXiv:2603.24472, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team, Angang Du, Bofei Gao, Bowen Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1.5: Scaling reinforcement learning with LLMs.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Efficient Process Reward Modeling via Contrastive Mutual Information
Nakyung Lee, Sangwoo Hong, and Jungwoo Lee. Efficient process reward modeling via contrastive mutual information.arXiv preprint arXiv:2604.10660, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
work page 2022
-
[12]
Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimization via sample routing.arXiv preprint arXiv:2604.02288, 2026
-
[13]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[15]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in neural information processing systems, 36:21558–21572, 2023. 10
work page 2023
-
[16]
Unifying distillation and privileged information.arXiv preprint arXiv:1511.03643, 2015
David Lopez-Paz, Léon Bottou, Bernhard Schölkopf, and Vladimir Vapnik. Unifying distillation and privileged information.arXiv preprint arXiv:1511.03643, 2015
-
[17]
https://thinkingmachines.ai/blog/ on-policy-distillation/
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Con- nectionism, 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy- distillation
-
[18]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. Improve mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592, 2024
work page internal anchor Pith review arXiv 2024
-
[19]
Policy invariance under reward transforma- tions: Theory and application to reward shaping
Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transforma- tions: Theory and application to reward shaping. InProceedings of the International Conference on Machine Learning (ICML), volume 99, pages 278–287. Citeseer, 1999
work page 1999
-
[20]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, Shan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
On-policy self-distillation for reasoning compression.arXiv e-prints, pages arXiv–2603, 2026
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. On-policy self-distillation for reasoning compression.arXiv e-prints, pages arXiv–2603, 2026
work page 2026
-
[22]
Rewarding progress: Scaling automated process verifiers for LLM reasoning
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding progress: Scaling automated process verifiers for LLM reasoning. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=A6Y7AqlzLW
work page 2025
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
work page 2025
-
[25]
Vladimir Vapnik and Akshay Vashist. A new learning paradigm: Learning using privileged information.Neural networks, 22(5-6):544–557, 2009
work page 2009
-
[26]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
work page 2024
-
[27]
MiMo-V2-Flash Technical Report
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
PACED: Distillation and On-Policy Self-Distillation at the Frontier of Student Competence
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. Paced: Distillation and on- policy self-distillation at the frontier of student competence.arXiv preprint arXiv:2603.11178, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review arXiv 2026
-
[32]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
American invitational mathematics examination (aime) 2024, 2024
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024
work page 2024
-
[34]
American invitational mathematics examination (aime) 2025, 2025
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025, 2025
work page 2025
-
[35]
American invitational mathematics examination (aime) 2026, 2026
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2026, 2026
work page 2026
-
[36]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025. 12 Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information Supplementary Material Table of Contents A Proofs and Deferred Statements . . . . . . . . . . . . . . . . . . . . . . . . . . ....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.