Recognition: unknown
OccuBench: Evaluating AI Agents on Real-World Professional Tasks via Language Environment Simulation
Pith reviewed 2026-05-10 16:39 UTC · model grok-4.3
The pith
No single AI model dominates all professional industries when tested on 100 real-world tasks via simulated environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
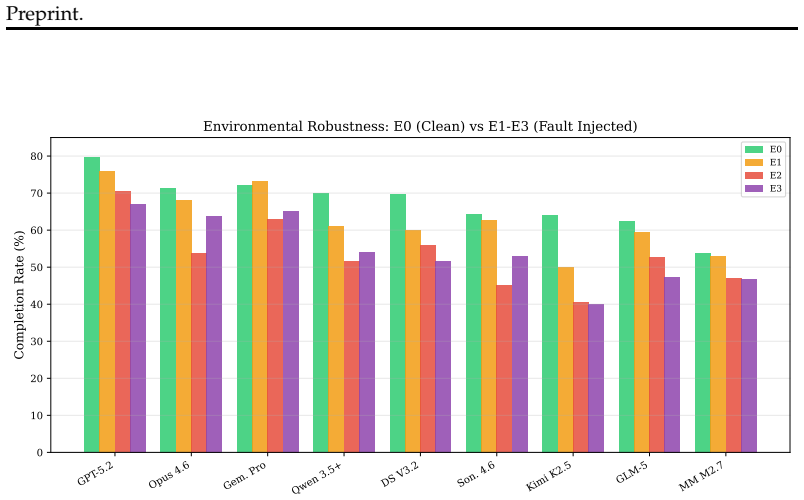
OccuBench covers 100 real-world professional task scenarios across 10 industry categories and 65 specialized domains, enabled by Language Environment Simulators that simulate domain-specific environments through LLM-driven tool response generation. Evaluation of 15 frontier models across 8 families shows that no single model dominates all industries, implicit faults are harder than explicit or mixed faults because they lack overt error signals, larger models and higher reasoning effort improve performance, and strong agents are not necessarily strong environment simulators.
What carries the argument
Language Environment Simulators (LESs) that generate domain-specific tool responses and environment states via LLMs to enable controlled agent evaluation in professional domains without public real-world access.
If this is right
- Models will need to be chosen for specific industries rather than relying on overall performance averages.
- Agents must develop the ability to detect and respond to data degradation without receiving explicit error signals.
- Further increases in model scale and reasoning effort will likely produce additional gains on complex occupational tasks.
- Benchmark validity requires separate verification that the simulators themselves match real tool behaviors.
Where Pith is reading between the lines
- Benchmarks of this form could guide targeted development of agents for particular occupational fields.
- The gap between task performance and simulator quality points to the value of creating dedicated simulation models.
- Extending fault injection to more subtle or domain-specific degradation patterns could expose additional capability limits.
Load-bearing premise
That LLM-driven simulations of domain-specific tool responses and professional environments are accurate and unbiased enough to support reliable agent evaluation.
What would settle it
Direct comparison of the same agents' success rates and relative rankings when interacting with the simulated benchmark environments versus the actual deployed professional software systems.
Figures
















read the original abstract
AI agents are expected to perform professional work across hundreds of occupational domains (from emergency department triage to nuclear reactor safety monitoring to customs import processing), yet existing benchmarks can only evaluate agents in the few domains where public environments exist. We introduce OccuBench, a benchmark covering 100 real-world professional task scenarios across 10 industry categories and 65 specialized domains, enabled by Language Environment Simulators (LESs) that simulate domain-specific environments through LLM-driven tool response generation. Our multi-agent synthesis pipeline automatically produces evaluation instances with guaranteed solvability, calibrated difficulty, and document-grounded diversity. OccuBench evaluates agents along two complementary dimensions: task completion across professional domains and environmental robustness under controlled fault injection (explicit errors, implicit data degradation, and mixed faults). We evaluate 15 frontier models across 8 model families and find that: (1) no single model dominates all industries, as each has a distinct occupational capability profile; (2) implicit faults (truncated data, missing fields) are harder than both explicit errors (timeouts, 500s) and mixed faults, because they lack overt error signals and require the agent to independently detect data degradation; (3) larger models, newer generations, and higher reasoning effort consistently improve performance. GPT-5.2 improves by 27.5 points from minimal to maximum reasoning effort; and (4) strong agents are not necessarily strong environment simulators. Simulator quality is critical for LES-based evaluation reliability. OccuBench provides the first systematic cross-industry evaluation of AI agents on professional occupational tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OccuBench, a benchmark covering 100 professional task scenarios across 10 industry categories and 65 specialized domains. It relies on Language Environment Simulators (LESs) that use LLMs to generate domain-specific tool responses and environments. A multi-agent synthesis pipeline automatically creates evaluation instances with guaranteed solvability, calibrated difficulty, and controlled fault injection (explicit errors, implicit data degradation, mixed). The evaluation of 15 frontier models across 8 families yields four main findings: no single model dominates all industries; implicit faults are harder than explicit or mixed faults; performance scales with model size, generation, and reasoning effort; and strong agents are not necessarily strong simulators.
Significance. If the LES simulations are faithful proxies for real occupational environments, OccuBench would fill an important gap by enabling systematic cross-industry evaluation of agents on tasks where public environments do not exist. The automatic pipeline with guaranteed solvability and explicit fault injection is a clear methodological strength that supports reproducible instance generation. The empirical observation that implicit faults lack overt signals and thus require independent detection is a useful distinction for future robustness work.
major comments (2)
- [LES construction and evaluation pipeline] The central claims—no model dominates industries, implicit faults are hardest, scaling with size/reasoning, and agents ≠ simulators—all rest on the assumption that LLM-driven LES outputs are sufficiently accurate and unbiased proxies for real domain tools. The manuscript reports no human-expert or real-system ground-truth comparisons for simulator fidelity across the 65 domains (see LES construction and evaluation sections). Without such validation, systematic biases in tool responses (e.g., missing domain constraints in nuclear monitoring or customs) could distort both task-completion scores and the implicit-vs-explicit fault ordering.
- [Multi-agent synthesis pipeline] The multi-agent synthesis pipeline is described as producing 'calibrated difficulty,' yet the free parameters used for difficulty calibration and the procedure for setting them are not fully specified. This leaves open the possibility that calibration choices interact with the fault-injection mechanism and affect the reported relative difficulty of fault types.
minor comments (2)
- [Abstract] The abstract reports a 27.5-point improvement for GPT-5.2 from minimal to maximum reasoning effort; clarify whether this is an absolute percentage-point gain on the primary metric and provide the exact metric name.
- [Results tables] Tables reporting per-industry or per-fault-type scores should include error bars or statistical tests to support claims of consistent scaling or ordering.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us identify areas to improve the clarity and transparency of our work on OccuBench. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [LES construction and evaluation pipeline] The central claims—no model dominates industries, implicit faults are hardest, scaling with size/reasoning, and agents ≠ simulators—all rest on the assumption that LLM-driven LES outputs are sufficiently accurate and unbiased proxies for real domain tools. The manuscript reports no human-expert or real-system ground-truth comparisons for simulator fidelity across the 65 domains (see LES construction and evaluation sections). Without such validation, systematic biases in tool responses (e.g., missing domain constraints in nuclear monitoring or customs) could distort both task-completion scores and the implicit-vs-explicit fault ordering.
Authors: We acknowledge that the manuscript does not include human-expert or real-system ground-truth comparisons for LES fidelity across the 65 domains. Conducting such validations at this scale is practically challenging due to limited access to proprietary occupational systems and the specialized expertise required. Our LES construction instead relies on document-grounded prompting and multi-agent synthesis with solvability guarantees to reduce the risk of arbitrary biases. We will revise the manuscript to add an explicit 'Limitations' subsection discussing potential simulator biases and our mitigation strategies, allowing readers to interpret the results with appropriate caution. revision: yes
-
Referee: [Multi-agent synthesis pipeline] The multi-agent synthesis pipeline is described as producing 'calibrated difficulty,' yet the free parameters used for difficulty calibration and the procedure for setting them are not fully specified. This leaves open the possibility that calibration choices interact with the fault-injection mechanism and affect the reported relative difficulty of fault types.
Authors: The difficulty calibration procedure, including the free parameters (such as task complexity thresholds and target success rates from pilot evaluations), is described in Appendix B. We will expand this description into the main text of the revised manuscript, explicitly stating the parameter values used and confirming that calibration was performed on a held-out pilot set independently of the final fault-type evaluations to avoid any interaction effects. revision: yes
Circularity Check
No circularity; empirical benchmark construction with direct measurements
full rationale
The paper constructs OccuBench via a multi-agent synthesis pipeline and LLM-driven Language Environment Simulators, then reports direct empirical results from evaluating 15 models on the resulting instances. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All four main findings (no model dominates, implicit faults hardest, scaling benefits, agents vs simulators) are presented as outcomes of running the benchmark rather than reductions to its own inputs by construction. The evaluation is therefore self-contained against external model runs.
Axiom & Free-Parameter Ledger
free parameters (1)
- difficulty calibration parameters
axioms (1)
- domain assumption LLM-driven tool response generation produces realistic domain-specific environments
Reference graph
Works this paper leans on
-
[1]
MCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers
https://www.anthropic.com/ claude-4-system-card, 2025a. Anthropic. Introducing Claude Opus 4.5. https://www.anthropic.com/news/ claude-opus-4-5, 2025b. Anthropic. System card: Claude Sonnet 4.6. https://anthropic.com/ claude-sonnet-4-6-system-card, 2025c. Anthropic. Introducing Claude Opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, 2025d. Chait...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Internalizing world models via self-play finetuning for agentic RL.arXiv preprint arXiv:2510.15047,
Shiqi Chen, Tongyao Zhu, Zian Wang, Jinghan Zhang, Kangrui Wang, Siyang Gao, Teng Xiao, Yee Whye Teh, Junxian He, and Manling Li. Internalizing world models via self-play finetuning for agentic RL.arXiv preprint arXiv:2510.15047,
-
[3]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI. DeepSeek-V3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Mobile-Bench: An evaluation benchmark for LLM-based mobile agents
Shihan Deng et al. Mobile-Bench: An evaluation benchmark for LLM-based mobile agents. arXiv preprint arXiv:2407.00993,
-
[5]
Cl-bench: A benchmark for context learning
Shihan Dou et al. CL-bench: A benchmark for context learning.arXiv preprint arXiv:2602.03587,
-
[6]
GLM-5: from Vibe Coding to Agentic Engineering
GLM-5-Team. GLM-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763,
work page internal anchor Pith review arXiv
-
[7]
arXiv preprint arXiv:2411.06559 , year=
Yu Gu, Kai Zhang, Yuting Ning, Boyuan Zheng, Boyu Gou, Tianci Xue, Cheng Chang, Sanjari Srivastava, Yanan Xie, Peng Qi, Huan Sun, and Yu Su. Is your LLM secretly a world model of the internet? model-based planning for web agents.arXiv preprint arXiv:2411.06559,
-
[8]
Kimi K2.5: Visual Agentic Intelligence
21 Preprint. Kimi Team. Kimi K2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Simulating environments with reasoning models for agent training.arXiv preprint arXiv:2511.01824,
Yuetai Li, Huseyin A Inan, Xiang Yue, Wei-Ning Chen, Lukas Wutschitz, Janardhan Kulkarni, Radha Poovendran, Robert Sim, and Saravan Rajmohan. Simulating environments with reasoning models for agent training.arXiv preprint arXiv:2511.01824,
-
[10]
Vimo: A generative visual gui world model for app agents
Dezhao Luo, Bohan Tang, Kang Li, Georgios Papoudakis, Jifei Song, Shaogang Gong, Jianye Hao, Jun Wang, and Kun Shao. ViMo: A generative visual GUI world model for app agents.arXiv preprint arXiv:2504.13936,
-
[11]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill et al. Terminal-Bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868,
work page internal anchor Pith review arXiv
-
[12]
GAIA: a benchmark for General AI Assistants
Gr´egoire Mialon, Cl´ementine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983,
work page internal anchor Pith review arXiv
-
[13]
Swe-lancer: Can frontier llms earn $1 million from real world freelance software engineering?
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. SWE- Lancer: Can frontier LLMs earn $1 million from real-world freelance software engineering? arXiv preprint arXiv:2502.12115,
-
[14]
OpenAI. GPT-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior.arXiv preprint arXiv:2304.03442,
work page internal anchor Pith review arXiv
-
[16]
Tejal Patwardhan et al. GDPval: Evaluating AI model performance on real-world economi- cally valuable tasks.arXiv preprint arXiv:2510.04374,
-
[17]
arXiv:2508.20453 [cs.CL] https://arxiv.org/abs/ 2508.20453
Zhenting Wang et al. MCP-Bench: Benchmarking tool-using LLM agents with complex real-world tasks via MCP servers.arXiv preprint arXiv:2508.20453,
-
[18]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei et al. BrowseComp: A simple yet challenging benchmark for browsing agents. arXiv preprint arXiv:2504.12516,
work page internal anchor Pith review arXiv
-
[19]
Zijian Wu et al. MCPMark: A benchmark for stress-testing realistic and comprehensive MCP use.arXiv preprint arXiv:2509.24002,
-
[20]
Webworld: A large-scale world model for web agent training.arXiv preprint arXiv:2602.14721,
Zikai Xiao, Jianhong Tu, Chuhang Zou, Yuxin Zuo, Zhi Li, Peng Wang, Bowen Yu, Fei Huang, Junyang Lin, and Zuozhu Liu. WebWorld: A large-scale world model for web agent training.arXiv preprint arXiv:2602.14721,
-
[21]
$OneMillion-Bench: How far are language agents from human experts?arXiv preprint arXiv:2603.07980,
Qianyu Yang, Yang Liu, Jiaqi Li, Jun Bai, et al. $OneMillion-Bench: How far are language agents from human experts?arXiv preprint arXiv:2603.07980,
-
[22]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045,
work page internal anchor Pith review arXiv
-
[23]
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, Qi Liu, Zhifang Sui, and Tong Yang. Claw-eval: Toward trustworthy evaluation of autonomous agents.arXiv preprint arXiv:2604.06132,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.