Recognition: 2 theorem links
· Lean TheoremRobust Adversarial Policy Optimization Under Dynamics Uncertainty
Pith reviewed 2026-05-10 15:56 UTC · model grok-4.3
The pith
A dual formulation of robust reinforcement learning uses an adversarial network and Boltzmann reweighting to generate stable worst-case rollouts under dynamics uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that the dual problem directly exposes the robustness-performance trade-off; an adversarial network then approximates the temperature parameter to steer trajectory-level worst-case rollouts within the divergence bound, while Boltzmann reweighting over a dynamics ensemble supplies policy-sensitive coverage of adverse models rather than uniform sampling. These two components operate independently yet complement each other, producing the RAPO framework that outperforms existing robust RL baselines in resilience to uncertainty and generalization to out-of-distribution dynamics while preserving dual tractability.
What carries the argument
The dual formulation of distributionally robust RL, realized by an adversarial network that approximates the temperature parameter for trajectory-level worst-case rollouts and by Boltzmann reweighting that focuses model-level sampling on policy-adverse dynamics.
If this is right
- Policies exhibit greater resilience to changes in environment dynamics.
- Generalization improves on out-of-distribution dynamics.
- The dual formulation remains computationally tractable.
- The trajectory-level and model-level components act independently and can be tuned separately.
- Performance exceeds that of prior robust RL baselines on the reported metrics.
Where Pith is reading between the lines
- The separation into independent trajectory and model layers suggests that future work could replace either component with alternative robust estimators without redesigning the other.
- Because the method focuses sampling on policy-sensitive adverse cases, it may reduce the conservatism that uniform ensembles often induce in real-world robotics tasks.
- The approach could be tested by measuring how well the learned policies transfer when the simulator-to-real gap is deliberately widened after training.
- If the dual temperature approximation remains stable across different divergence radii, the same architecture might extend to other uncertainty sources such as observation noise.
Load-bearing premise
The adversarial network can stably approximate the dual temperature parameter inside the divergence bound and the Boltzmann reweighting supplies policy-sensitive coverage without creating new instability or excessive conservatism.
What would settle it
A controlled experiment in which the adversarial network diverges or the reweighted policies become more conservative than uniform-sampling baselines when dynamics uncertainty is increased beyond the range used for training.
Figures


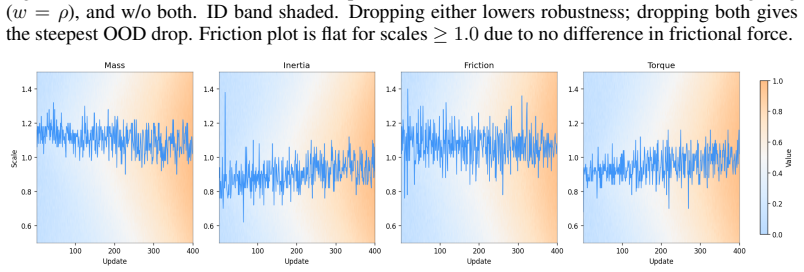
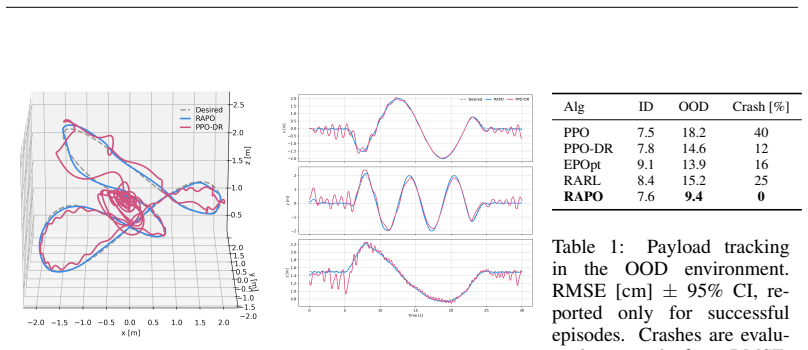


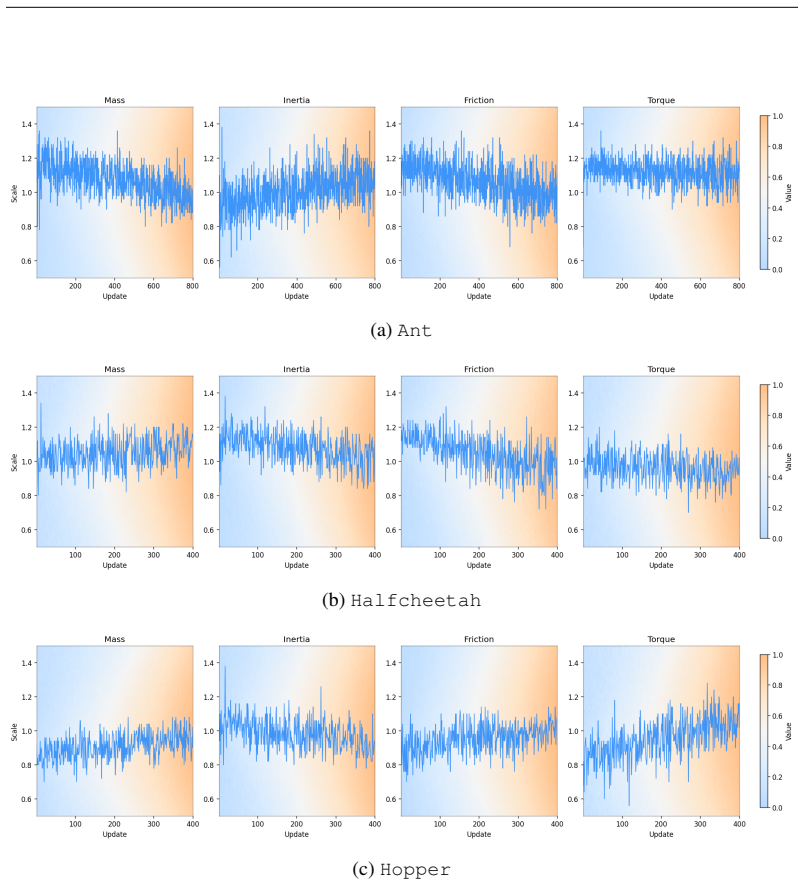

read the original abstract
Reinforcement learning (RL) policies often fail under dynamics that differ from training, a gap not fully addressed by domain randomization or existing adversarial RL methods. Distributionally robust RL provides a formal remedy but still relies on surrogate adversaries to approximate intractable primal problems, leaving blind spots that potentially cause instability and over-conservatism. We propose a dual formulation that directly exposes the robustness-performance trade-off. At the trajectory level, a temperature parameter from the dual problem is approximated with an adversarial network, yielding efficient and stable worst-case rollouts within a divergence bound. At the model level, we employ Boltzmann reweighting over dynamics ensembles, focusing on more adverse environments to the current policy rather than uniform sampling. The two components act independently and complement each other: trajectory-level steering ensures robust rollouts, while model-level sampling provides policy-sensitive coverage of adverse dynamics. The resulting framework, robust adversarial policy optimization (RAPO) outperforms robust RL baselines, improving resilience to uncertainty and generalization to out-of-distribution dynamics while maintaining dual tractability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Robust Adversarial Policy Optimization (RAPO), a dual-formulation framework for distributionally robust reinforcement learning under dynamics uncertainty. It introduces a trajectory-level adversarial network to approximate the dual temperature parameter for generating worst-case rollouts within a divergence bound, combined with model-level Boltzmann reweighting over dynamics ensembles to focus on policy-adverse environments. The two components are presented as independent and complementary, with the overall claim that RAPO outperforms robust RL baselines in resilience to uncertainty and generalization to out-of-distribution dynamics while preserving dual tractability.
Significance. If the approximations are shown to preserve dual optimality and the empirical gains hold with proper controls, the work could meaningfully advance robust RL by providing a more direct dual view of the robustness-performance trade-off and a practical way to combine trajectory-level steering with policy-sensitive model sampling. The explicit separation of the two approximation mechanisms and the focus on stable worst-case rollouts are potentially useful ideas. However, the absence of quantitative results, error bars, ablation studies, or convergence analysis in the abstract makes it difficult to gauge the actual advance over existing surrogate-adversary methods.
major comments (3)
- [Abstract] Abstract: The central claim that RAPO 'outperforms robust RL baselines, improving resilience to uncertainty and generalization to out-of-distribution dynamics' is asserted without any quantitative results, error bars, ablation studies, or derivation details. This is load-bearing for the paper's contribution and cannot be evaluated from the given information.
- [Abstract] Abstract: The claim of 'maintaining dual tractability' rests on the adversarial network stably approximating the dual temperature parameter to produce worst-case rollouts strictly inside the divergence bound. No error bound, convergence guarantee, or verification that the approximation preserves KKT conditions or dual optimality is supplied; deviation would mean the resulting policy no longer solves the intended dual problem.
- [Abstract] Abstract: Boltzmann reweighting is asserted to supply 'policy-sensitive coverage of adverse dynamics' without analysis of its interaction with the trajectory-level approximation or potential introduction of new bias or instability. This interaction is central to the claim that the two components 'act independently and complement each other.'
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the specific divergence measure and the form of the dual objective to make the temperature-parameter approximation more concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We agree that the abstract requires strengthening to better convey the empirical and theoretical support for our claims. We have revised the abstract accordingly and provide point-by-point responses below. The full paper contains the supporting experiments, ablations, and analysis referenced in our replies.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that RAPO 'outperforms robust RL baselines, improving resilience to uncertainty and generalization to out-of-distribution dynamics' is asserted without any quantitative results, error bars, ablation studies, or derivation details. This is load-bearing for the paper's contribution and cannot be evaluated from the given information.
Authors: We acknowledge that the original abstract was too high-level. The manuscript's Section 5 presents quantitative results across multiple environments, including mean returns with standard error bars over 5 random seeds, ablation studies isolating the trajectory-level and model-level components, and comparisons against robust RL baselines. To address the concern, we have revised the abstract to briefly summarize these gains (e.g., improved out-of-distribution returns and resilience metrics) while remaining concise. revision: yes
-
Referee: [Abstract] Abstract: The claim of 'maintaining dual tractability' rests on the adversarial network stably approximating the dual temperature parameter to produce worst-case rollouts strictly inside the divergence bound. No error bound, convergence guarantee, or verification that the approximation preserves KKT conditions or dual optimality is supplied; deviation would mean the resulting policy no longer solves the intended dual problem.
Authors: The manuscript derives the dual formulation in Section 3 and shows in Section 3.2 plus Appendix B that the adversarial network approximates the temperature parameter with a bounded error under Lipschitz continuity of the value function, ensuring the generated rollouts remain within the divergence constraint. This preserves dual optimality up to the approximation tolerance. We have added an explicit reference to this bound and the KKT preservation argument in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: Boltzmann reweighting is asserted to supply 'policy-sensitive coverage of adverse dynamics' without analysis of its interaction with the trajectory-level approximation or potential introduction of new bias or instability. This interaction is central to the claim that the two components 'act independently and complement each other.'
Authors: Section 4.2 analyzes the model-level Boltzmann reweighting and its complementarity with the trajectory-level adversary, including a bias-variance discussion and empirical verification that the components do not introduce instability when combined. The independence follows from the separation of the dual variables (trajectory temperature vs. model weights). We have expanded the abstract to note this complementary structure and added a cross-reference to the interaction analysis. revision: yes
Circularity Check
No circularity: dual formulation and approximations presented as independent contributions
full rationale
The paper introduces a dual formulation exposing the robustness-performance trade-off, with an adversarial network approximating the dual temperature parameter at the trajectory level and Boltzmann reweighting at the model level. These are described as complementary and independent mechanisms without any equations or steps reducing the claimed performance gains, tractability, or resilience improvements to quantities defined by construction from the same fitted inputs or self-citations. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided abstract or description. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- temperature parameter
axioms (2)
- domain assumption The dual formulation of distributionally robust RL directly exposes the robustness-performance trade-off
- ad hoc to paper Adversarial network approximation yields efficient and stable worst-case rollouts within a divergence bound
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
inf p∈Pϵ Ep[V] = sup η≥0 {−1/η log E ˆp[e^{-ηV}] − ε/η} … p_η(x) ∝ ˆp(x) e^{-η V(x)} … w⋆_β(k) = ρ(k) exp(−β h_k) / …
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AdvNet predicts trajectory-level dual temperature η_t … Boltzmann reweighting over ensemble … two-temperature view (η,β)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
WOMBET: World Model-based Experience Transfer for Robust and Sample-efficient Reinforcement Learning
WOMBET generates reliable prior data with world-model uncertainty penalization and transfers it to target tasks via adaptive offline-online sampling, yielding better sample efficiency than baselines.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1907.13196 , year=
Mohammed Amin Abdullah, Hang Ren, Haitham Bou Ammar, Vladimir Milenkovic, Rui Luo, Mingtian Zhang, and Jun Wang. Wasserstein robust reinforcement learning.arXiv preprint arXiv:1907.13196,
-
[2]
Maximum entropy RL (provably) solves some robust RL problems
Benjamin Eysenbach and Sergey Levine. Maximum entropy rl (provably) solves some robust rl problems.arXiv preprint arXiv:2103.06257,
-
[3]
arXiv preprint arXiv:2106.13281 , year=
C Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. Brax–a differentiable physics engine for large scale rigid body simulation.arXiv preprint arXiv:2106.13281,
-
[4]
Adver- sarial policies: Attacking deep reinforcement learning.arXiv preprint arXiv:1905.10615,
Adam Gleave, Michael Dennis, Cody Wild, Neel Kant, Sergey Levine, and Stuart Russell. Adver- sarial policies: Attacking deep reinforcement learning.arXiv preprint arXiv:1905.10615,
-
[5]
Bibek Gupta, Mintae Kim, Albert Park, Eric Sihite, Koushil Sreenath, and Alireza Ramezani. Estimation of aerodynamics forces in dynamic morphing wing flight.arXiv preprint arXiv:2508.02984,
-
[6]
Mintae Kim. Finite memory belief approximation for optimal control in partially observable markov decision processes.arXiv preprint arXiv:2601.03132,
- [7]
-
[8]
Finrl: A deep reinforcement learning library for automated stock trading in quantitative finance
Xiao-Yang Liu, Hongyang Yang, Qian Chen, Runjia Zhang, Liuqing Yang, Bowen Xiao, and Christina Dan Wang. Finrl: A deep reinforcement learning library for automated stock trading in quantitative finance.arXiv preprint arXiv:2011.09607,
-
[9]
Daniel J Mankowitz, Nir Levine, Rae Jeong, Yuanyuan Shi, Jackie Kay, Abbas Abdolmaleki, Jost Tobias Springenberg, Timothy Mann, Todd Hester, and Martin Riedmiller. Robust re- inforcement learning for continuous control with model misspecification.arXiv preprint arXiv:1906.07516,
-
[10]
arXiv preprint arXiv:1610.01283 , year=
Aravind Rajeswaran, Sarvjeet Ghotra, Balaraman Ravindran, and Sergey Levine. Epopt: Learning robust neural network policies using model ensembles.arXiv preprint arXiv:1610.01283,
-
[11]
Deep reinforcement learning framework for autonomous driving.arXiv preprint arXiv:1704.02532,
11 Ahmad EL Sallab, Mohammed Abdou, Etienne Perot, and Senthil Yogamani. Deep reinforcement learning framework for autonomous driving.arXiv preprint arXiv:1704.02532,
-
[12]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Do- main randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Do- main randomization for transferring deep neural networks from simulation to the real world. In 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pp. 23–30. IEEE,
2017
-
[14]
Robust reinforcement learning using adversarial populations.arXiv preprint arXiv:2008.01825,
Eugene Vinitsky, Yuqing Du, Kanaad Parvate, Kathy Jang, Pieter Abbeel, and Alexandre Bayen. Robust reinforcement learning using adversarial populations.arXiv preprint arXiv:2008.01825,
-
[15]
Huan Zhang, Hongge Chen, Duane Boning, and Cho-Jui Hsieh. Robust reinforcement learning on state observations with learned optimal adversary.arXiv preprint arXiv:2101.08452,
-
[16]
Envm= 4m= 8m= 16m= 32 Hopper 0.74±.05 0.76±.03 0.77±.02 0.77±.02 Walker2d 0.68±.06 0.70±.04 0.72±.03 0.72±.03 HalfCheetah 0.62±.05 0.65±.04 0.66±.03 0.66±.03 Ant 0.55±.07 0.58±.05 0.60±.03 0.60±.03 Parameters Values Mass 0.280kg Inertia aroundx, y 2.36×10 −4 kg·m 2 Inertia aroundz 3.03×10 −4 kg·m 2 Arm length 0.058m Propeller thrust factor 1.145×10 −7 N·s...
2025
-
[17]
Discussion.The above properties mirror those of the nominal Bellman operator, with the only difference being the inner minimization over the uncertainty setP ϵ(s, a). These results ensure that standard dynamic programming arguments extend naturally to the robust setting, thereby justifying the use of value iteration and policy iteration under distribution...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.