Recognition: unknown
Neural Generalized Mixed-Effects Models
Pith reviewed 2026-05-10 16:22 UTC · model grok-4.3
The pith
Replacing the linear predictor in generalized mixed-effects models with a neural network yields a flexible NGMM that models nonlinear relationships in grouped data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
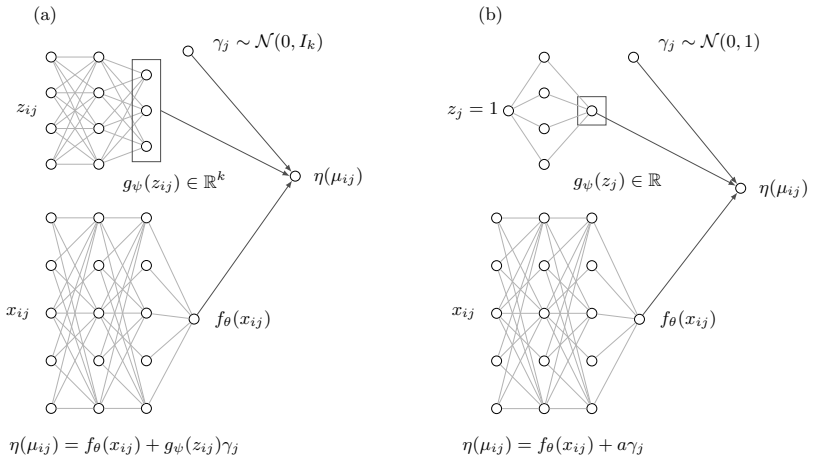
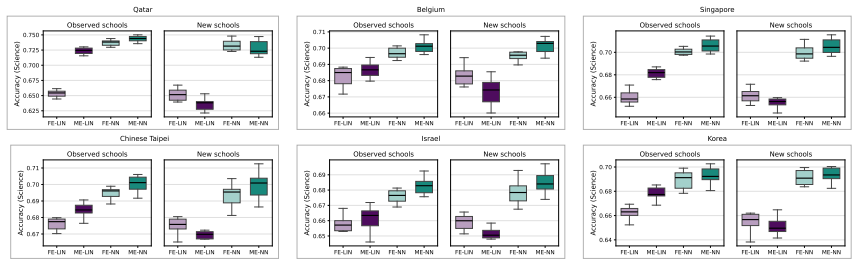
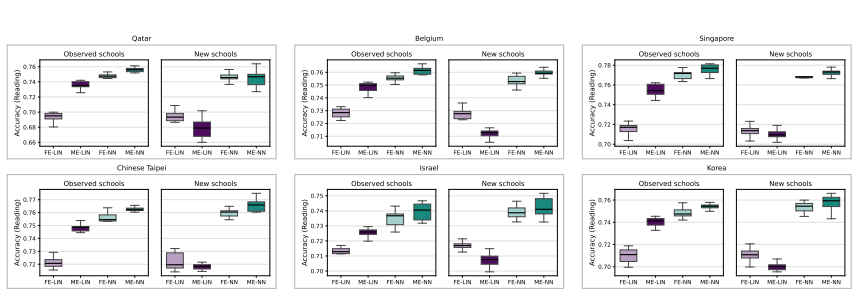
Generalized linear mixed-effects models assume the natural parameter is a linear function of covariates plus a latent random effect. Substituting a neural network for the linear function produces the neural generalized mixed-effects model, which can represent nonlinear covariate-response dependencies. Model fitting maximizes an approximate marginal likelihood via an efficient, differentiable procedure whose error bound decays at a Gaussian-tail rate. This framework improves predictive accuracy on nonlinear synthetic data and real datasets and extends naturally to richer latent variable structures.
What carries the argument
The neural generalized mixed-effects model (NGMM), formed by inserting a neural network in place of the linear predictor inside a GLMM, together with a specialized optimizer for its approximate marginal likelihood.
If this is right
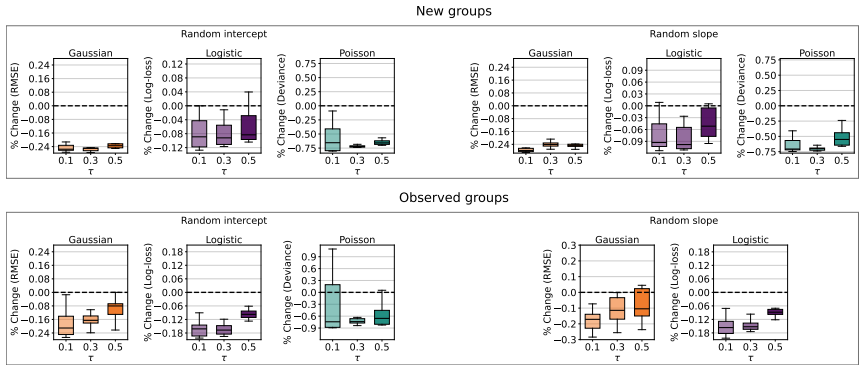
- NGMM improves over standard GLMMs on synthetic data where covariate-response relationships are nonlinear.
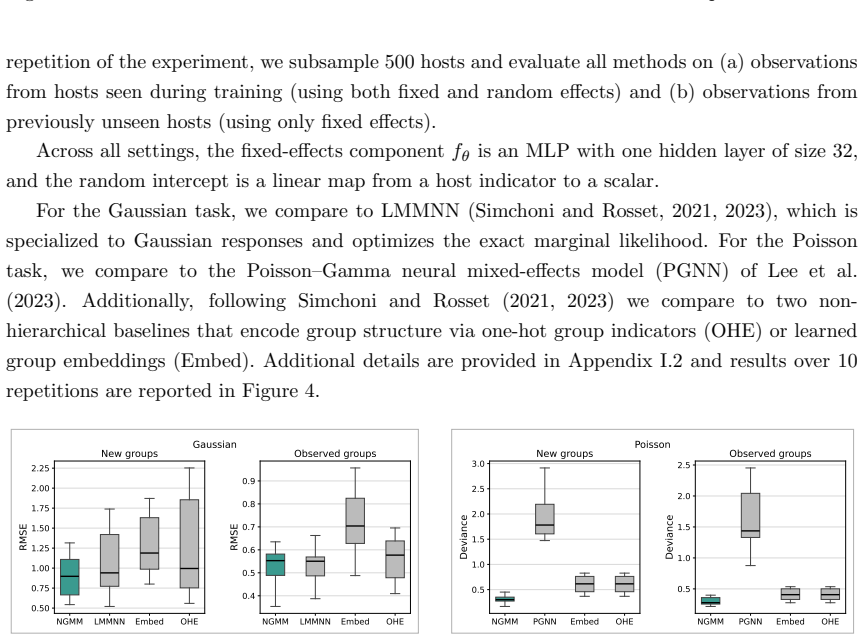
- On real-world datasets NGMM outperforms prior methods.
- The model extends to more complex latent-variable models, illustrated by analysis of a large student proficiency dataset.
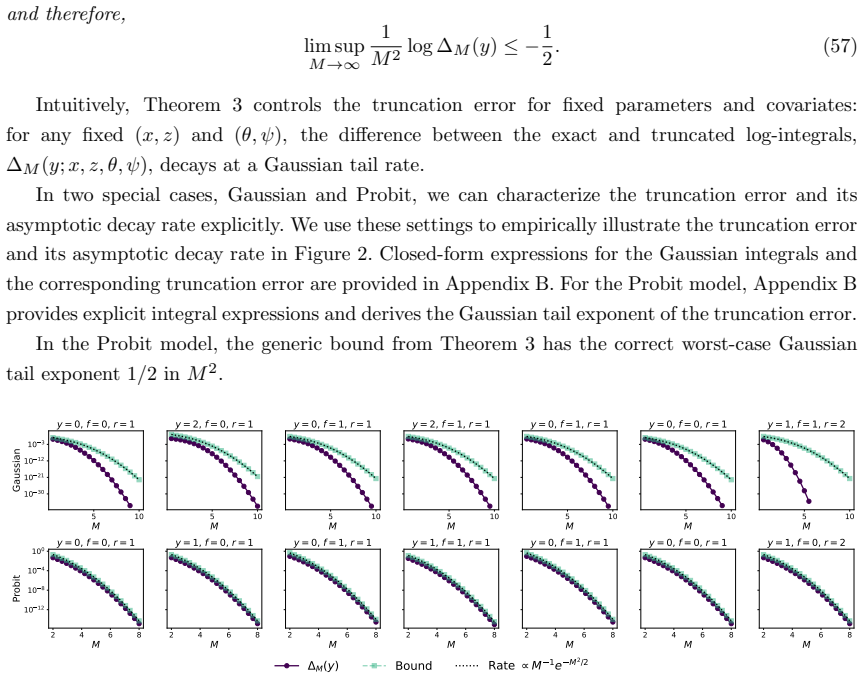
- The approximation error decays at a Gaussian-tail rate in a user-chosen parameter.
Where Pith is reading between the lines
- If the neural network component scales to larger architectures without optimization issues, NGMMs could handle high-dimensional covariates in hierarchical settings more effectively than linear alternatives.
- Since the procedure is differentiable, it may integrate with gradient-based methods for joint learning of network and other model components.
- Applications in fields like education or medicine could benefit from modeling nonlinear effects within groups without losing the random effect structure for unobserved heterogeneity.
Load-bearing premise
The optimization procedure can efficiently maximize the approximate marginal likelihood for the neural network parameters without getting stuck in poor local optima or requiring excessive computation.
What would settle it
Running NGMM and a standard GLMM on a dataset generated from a known nonlinear function plus random effects, then checking if NGMM recovers the nonlinearity and achieves lower prediction error than the linear baseline.
Figures






read the original abstract
Generalized linear mixed-effects models (GLMMs) are widely used to analyze grouped and hierarchical data. In a GLMM, each response is assumed to follow an exponential-family distribution where the natural parameter is given by a linear function of observed covariates and a latent group-specific random effect. Since exact marginalization over the random effects is typically intractable, model parameters are estimated by maximizing an approximate marginal likelihood. In this paper, we replace the linear function with neural networks. The result is a more flexible model, the neural generalized mixed-effects model (NGMM), which captures complex relationships between covariates and responses. To fit NGMM to data, we introduce an efficient optimization procedure that maximizes the approximate marginal likelihood and is differentiable with respect to network parameters. We show that the approximation error of our objective decays at a Gaussian-tail rate in a user-chosen parameter. On synthetic data, NGMM improves over GLMMs when covariate-response relationships are nonlinear, and on real-world datasets it outperforms prior methods. Finally, we analyze a large dataset of student proficiency to demonstrate how NGMM can be extended to more complex latent-variable models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the neural generalized mixed-effects model (NGMM) as an extension of generalized linear mixed-effects models (GLMMs) where the linear predictor is replaced by a neural network to model complex nonlinear relationships between covariates and responses in grouped data. It introduces an efficient optimization procedure for maximizing the approximate marginal likelihood that is end-to-end differentiable with respect to the neural network parameters, and claims that the approximation error decays at a Gaussian-tail rate with respect to a user-chosen parameter. Empirical results on synthetic data demonstrate improvements over standard GLMMs in nonlinear settings, while real-world datasets show outperformance over prior methods, with an additional demonstration on a large student proficiency dataset for more complex latent-variable extensions.
Significance. If the claims regarding the optimization efficiency and the Gaussian-tail error decay hold, this work provides a valuable contribution to the field of statistical modeling by bridging neural networks with mixed-effects models, enabling more flexible analysis of hierarchical data. The end-to-end differentiability of the procedure and the explicit error bound are notable strengths that support practical implementation and theoretical grounding. The empirical results on both synthetic and real data, including the extension to complex latent-variable models, further underscore its potential utility.
minor comments (3)
- [Abstract] Abstract: the statement that 'the approximation error of our objective decays at a Gaussian-tail rate in a user-chosen parameter' would benefit from an explicit reference to the relevant theorem or proposition (likely in §3) that establishes the rate and identifies the parameter, to allow readers to assess the claim without searching the full text.
- [Methods] The optimization procedure is described as efficient and differentiable, but the manuscript would be strengthened by a brief discussion (e.g., in the methods section) of safeguards against poor local optima, such as initialization strategies or convergence diagnostics, given that this is central to the fitting claim.
- [Experiments] In the real-world experiments, the comparison to 'prior methods' should include a clear table or list of baselines with their specific implementations (e.g., which GLMM variants or neural baselines), to ensure the outperformance claim is fully reproducible.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, accurate summary of the NGMM contributions, and recommendation for minor revision. We appreciate the recognition of the optimization efficiency, end-to-end differentiability, Gaussian-tail error bound, and empirical results on synthetic, real-world, and large-scale latent-variable settings.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The central step is a direct modeling substitution: replace the linear predictor in a standard GLMM with a neural network to obtain NGMM. The fitting procedure maximizes an approximate marginal likelihood (standard for GLMMs) and is made end-to-end differentiable by construction via automatic differentiation once the random-effect integral is approximated differentiably. The stated Gaussian-tail decay of approximation error is a conventional tail-bound result once a tunable approximation parameter (e.g., Laplace or similar) is fixed; it does not depend on the neural-network substitution itself. No self-definitional equations, fitted quantities renamed as predictions, or load-bearing self-citations appear. Empirical results on synthetic and real data are external validations, not internal reductions. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network parameters
axioms (2)
- domain assumption Responses follow exponential-family distributions with natural parameter from linear or neural function plus random effect.
- domain assumption Approximate marginal likelihood can be maximized differentiably w.r.t. network parameters.
Forward citations
Cited by 1 Pith paper
-
Robust Representation Learning through Explicit Environment Modeling
Explicitly modeling and marginalizing environment variation via generalized random-intercept models produces representations that support robust average prediction across unseen environments and outperform invariant-l...
Reference graph
Works this paper leans on
- [1]
-
[2]
PISA 2012 Technical Report
OECD. PISA 2012 Technical Report. Technical report, OECD Publishing, Paris,
2012
-
[3]
C. Analysis of numerical errors Recall that, for a fixed truncation radiusM= 1 2(ξ1 −ξ 0)>0, our estimation procedure targets the truncated empirical objective ¯ℓM(θ, ψ) := 1 m mX j=1 h njX i=1 logh(y ij) +H(ξ 1;y j,X j,Z j, θ, ψ) i ,(125) but in practice replacesHby its numerical approximation ˜Hand optimizes the ODE-based objective ˜ℓM(θ, ψ) := 1 m mX j...
1993
-
[4]
same-school
with quadrature evaluation of ˜Hr(M) for each sampled group. Truncation bounds. The truncation analysis in Section 3 extends to the multivariate integral above. The key step in Theorem 3 is an envelope bound of the form exp(L(ξ))≤ eC(y) exp −1 2 ξ2 ,(180) which follows from bounding the exponential-family term by a constant (via the convex conjugate A∗) a...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.