Recognition: unknown
When Verification Fails: How Compositionally Infeasible Claims Escape Rejection
Pith reviewed 2026-05-10 16:30 UTC · model grok-4.3
The pith
Models verify scientific claims by checking only the salient constraint, accepting many that violate non-salient ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
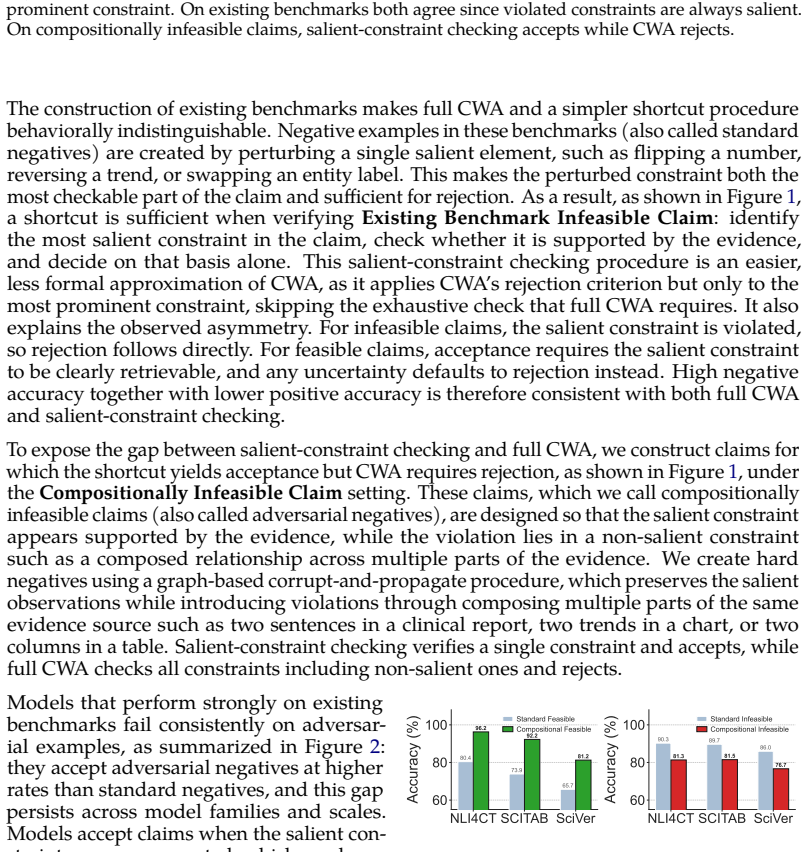
Existing benchmarks construct infeasible claims by perturbing a single salient element, so they cannot distinguish rigorous closed-world verification from salient-constraint checking. New compositionally infeasible claims—salient constraint supported, non-salient constraint contradicted—reveal that saturating models over-accept these claims. Model context interventions place families on a shared ROC curve, indicating that verification gaps reflect threshold differences and that the compositional inference bottleneck is structural and resistant to strategy guidance alone.
What carries the argument
Compositionally infeasible claims that keep the salient constraint supported while contradicting a non-salient constraint, used to test whether verification applies the closed-world assumption to all constraints or only the salient one.
If this is right
- Models that pass current benchmarks can still accept claims containing contradicted non-salient constraints.
- The compositional inference bottleneck persists across prompting strategies and model families.
- Differences between models appear as shifts along a shared ROC curve rather than changes in underlying reasoning.
- Strategy guidance alone cannot move models off the curve to full compositional verification.
Where Pith is reading between the lines
- Benchmark scores may systematically overestimate true verification reliability in any domain where claims contain multiple constraints.
- If the bottleneck is structural, training data that explicitly rewards checking every constraint could be required rather than relying on scale or prompting.
- The same shortcut pattern could appear in other verification tasks once benchmarks are constructed to hold salient support constant while varying non-salient support.
Load-bearing premise
The newly constructed claims isolate salient-constraint shortcut behavior rather than other model limitations or data artifacts.
What would settle it
Models that systematically reject claims in which any non-salient constraint is contradicted (while still accepting fully supported claims) would show they are not relying on the salient-constraint shortcut.
Figures








read the original abstract
Scientific claim verification, the task of determining whether claims are entailed by scientific evidence, is fundamental to establishing discoveries in evidence while preventing misinformation. This process involves evaluating each asserted constraint against validated evidence. Under the Closed-World Assumption (CWA), a claim is accepted if and only if all asserted constraints are positively supported. We show that existing verification benchmarks cannot distinguish models enforcing this standard from models applying a simpler shortcut called salient-constraint checking, which applies CWA's rejection criterion only to the most salient constraint and accepts when that constraint is supported. Because existing benchmarks construct infeasible claims by perturbing a single salient element they are insufficient at distinguishing between rigorous claim verification and simple salient-constraint reliance. To separate the two, we construct compositionally infeasible claims where the salient constraint is supported but a non-salient constraint is contradicted. Across model families and modalities, models that otherwise saturate existing benchmarks consistently over-accept these claims, confirming the prevalence of such shortcut reasoning. Via model context interventions, we show that different models and prompting strategies occupy distinct positions on a shared ROC curve, indicating that the gap between model families reflects differences in verification threshold rather than underlying reasoning ability, and that the compositional inference bottleneck is a structural property of current verification behavior that strategy guidance alone cannot overcome.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing scientific claim verification benchmarks cannot distinguish models that enforce the Closed-World Assumption (CWA) across all constraints from those using a salient-constraint checking shortcut. By constructing compositionally infeasible claims (salient constraint supported, non-salient contradicted), the authors show that models saturating prior benchmarks over-accept these claims. Model context interventions are used to argue that family differences reflect verification thresholds on a shared ROC curve rather than reasoning ability, establishing the compositional inference bottleneck as structural and resistant to strategy guidance.
Significance. If the isolation of salient-constraint shortcut behavior holds, the work provides a useful empirical probe into verification failures across model families and modalities, highlighting why prompting alone may not suffice. The construction of new test cases and the ROC-based framing of threshold vs. ability differences are concrete contributions that could inform more robust verification systems.
major comments (2)
- [Abstract] Abstract (construction of compositionally infeasible claims): the central claim that over-acceptance specifically demonstrates salient-constraint shortcut reliance (rather than general compositional weakness, misparsing, or generation artifacts) is load-bearing but unsupported by any described validation. No ablation, human probing, or control condition is referenced to confirm that the non-salient constraint is ignored even absent the contradiction or that salience is robust across models.
- [Abstract] Abstract (model context interventions and ROC analysis): the assertion that models occupy distinct positions on a shared ROC curve (indicating threshold differences rather than reasoning ability) and that the bottleneck is structural requires the specific interventions, metrics, and statistical tests used; without these details the structural-property conclusion cannot be evaluated and risks conflating threshold tuning with inability to integrate constraints.
minor comments (1)
- The abstract would be clearer if it briefly stated the number of models, modalities, and claims tested to convey experimental scale.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our abstract. We address each major comment below with references to the full manuscript and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (construction of compositionally infeasible claims): the central claim that over-acceptance specifically demonstrates salient-constraint shortcut reliance (rather than general compositional weakness, misparsing, or generation artifacts) is load-bearing but unsupported by any described validation. No ablation, human probing, or control condition is referenced to confirm that the non-salient constraint is ignored even absent the contradiction or that salience is robust across models.
Authors: We agree the abstract is highly condensed and does not enumerate the supporting controls. The full manuscript addresses this directly: Section 3.2 details the construction process with explicit salience annotations derived from human raters; Section 4 reports human probing experiments on a 200-claim subset confirming that annotators consistently identify the salient constraint and that models accept claims when only the salient constraint is supported (even without contradiction); Section 3.3 includes ablation controls removing the non-salient contradiction and generation-artifact checks via paraphrasing and reordering. These results show acceptance rates remain high only when the shortcut applies, distinguishing it from general compositional failure. We will revise the abstract to reference these validations concisely. revision: yes
-
Referee: [Abstract] Abstract (model context interventions and ROC analysis): the assertion that models occupy distinct positions on a shared ROC curve (indicating threshold differences rather than reasoning ability) and that the bottleneck is structural requires the specific interventions, metrics, and statistical tests used; without these details the structural-property conclusion cannot be evaluated and risks conflating threshold tuning with inability to integrate constraints.
Authors: The full paper supplies the requested details. Section 5 describes the model-context interventions (salient-constraint masking, non-salient masking, and full-context baselines) applied uniformly across families. Section 6 presents the ROC analysis using precision-recall curves, with models positioned via their operating points; metrics include AUC and F1 at fixed thresholds, with statistical separation tested via bootstrap confidence intervals and paired Wilcoxon signed-rank tests (p < 0.01). These establish that family differences align with threshold shifts on a common curve rather than distinct reasoning capacities. We will add a single sentence to the abstract summarizing the intervention type and ROC framing to permit direct evaluation. revision: yes
Circularity Check
No circularity: empirical construction of test cases with direct model evaluation
full rationale
The paper conducts an empirical study by constructing new compositionally infeasible claims (salient constraint supported, non-salient contradicted) and evaluating model acceptance rates across families and modalities. No equations, derivations, fitted parameters, or self-citation chains are present that reduce any claim to its inputs by construction. The central observation—that models over-accept these claims—rests on external benchmark comparisons and context interventions, which are falsifiable via the reported experiments rather than tautological. This matches the default expectation of a non-circular empirical paper self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Closed-World Assumption (CWA) defines claim acceptance as requiring positive support for every asserted constraint
Reference graph
Works this paper leans on
-
[1]
Reading and reasoning over chart images for evidence-based automated fact-checking
Mubashara Akhtar, Oana Cocarascu, and Elena Simperl. Reading and reasoning over chart images for evidence-based automated fact-checking. InFindings of the Association for Computational Linguistics: EACL 2023, pp. 399–414,
2023
-
[2]
Chartcheck: Explainable fact-checking over real-world chart images
Mubashara Akhtar, Nikesh Subedi, Vivek Gupta, Sahar Tahmasebi, Oana Cocarascu, and Elena Simperl. Chartcheck: Explainable fact-checking over real-world chart images. In Findings of the Association for Computational Linguistics: ACL 2024, pp. 13921–13937,
2024
-
[3]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction, 2024.URL https://arxiv. org/abs/2406.11717,
work page internal anchor Pith review arXiv 2024
-
[4]
Complex claim verification with evidence retrieved in the wild
Jifan Chen, Grace Kim, Aniruddh Sriram, Greg Durrett, and Eunsol Choi. Complex claim verification with evidence retrieved in the wild. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 3569–3587,
2024
-
[5]
ArXivabs/1909.02164(2019),https://api.semanticscholar.org/CorpusID: 1989173392
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. Tabfact: A large-scale dataset for table-based fact verification.arXiv preprint arXiv:1909.02164,
-
[6]
Don’t take the easy way out: Ensemble based methods for avoiding known dataset biases
Christopher Clark, Mark Yatskar, and Luke Zettlemoyer. Don’t take the easy way out: Ensemble based methods for avoiding known dataset biases. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language Processing (EMNLP-IJCNLP), pp. 4069–4082,
2019
-
[7]
Chain-of-verification reduces hallucination in large language models
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. Chain-of-verification reduces hallucination in large language models. InFindings of the association for computational linguistics: ACL 2024, pp. 3563–3578,
2024
-
[8]
Reasoning robustness of llms to adversarial typographical errors
Esther Gan, Yiran Zhao, Liying Cheng, Mao Yancan, Anirudh Goyal, Kenji Kawaguchi, Min- Yen Kan, and Michael Shieh. Reasoning robustness of llms to adversarial typographical errors. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 10449–10459,
2024
-
[9]
Evaluating models’ local decision boundaries via contrast sets
Matt Gardner, Yoav Artzi, Victoria Basmov, Jonathan Berant, Ben Bogin, Sihao Chen, Pradeep Dasigi, Dheeru Dua, Yanai Elazar, Ananth Gottumukkala, et al. Evaluating models’ local decision boundaries via contrast sets. InFindings of the Association for Computational Linguistics: EMNLP 2020, pp. 1307–1323,
2020
-
[10]
Annotation artifacts in natural language inference data
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel Bowman, and Noah A Smith. Annotation artifacts in natural language inference data. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pp. 107–112,
2018
-
[11]
Evaluating llms’ mathematical and coding competency through ontology- guided interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, and Soujanya Poria. Evaluating llms’ mathematical and coding competency through ontology- guided interventions. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 22811–22849,
2025
-
[12]
Large Language Models Cannot Self-Correct Reasoning Yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798,
work page internal anchor Pith review arXiv
-
[13]
Safety tax: Safety alignment makes your large reasoning models less reasonable
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, Zachary Yahn, Yichang Xu, and Ling Liu. Safety tax: Safety alignment makes your large reasoning models less reasonable. arXiv preprint arXiv:2503.00555,
-
[14]
Nli4ct: Multi-evidence natural language inference for clinical trial reports
Mael Jullien, Marco Valentino, Hannah Frost, Paul O’Regan, D´onal Landers, and Andre Freitas. Nli4ct: Multi-evidence natural language inference for clinical trial reports. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 16745–16764,
2023
-
[15]
Semeval-2024 task 2: Safe biomedical natural language inference for clinical trials
Ma¨el Jullien, Marco Valentino, and Andr´e Freitas. Semeval-2024 task 2: Safe biomedical natural language inference for clinical trials. InProceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), pp. 1947–1962,
2024
-
[16]
Dynabench: Rethinking benchmarking in NLP
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit Bansal, Christopher Potts, and Adina Williams. Dynabench: Rethinking benchmarking in NLP. In Kristina Toutanova, A...
2021
-
[17]
Dynabench: Rethinking benchmarking in NLP
Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.324. URL https:// aclanthology.org/2021.naacl-main.324/. Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, et al. Prometheus: Inducing fine-grained evaluation capability in language models. InThe Twe...
-
[18]
Evaluating verifiability in generative search engines
Nelson F Liu, Tianyi Zhang, and Percy Liang. Evaluating verifiability in generative search engines. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 7001–7025,
2023
-
[19]
Scitab: A challeng- ing benchmark for compositional reasoning and claim verification on scientific tables
Xinyuan Lu, Liangming Pan, Qian Liu, Preslav Nakov, and Min-Yen Kan. Scitab: A challeng- ing benchmark for compositional reasoning and claim verification on scientific tables. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 7787–7813,
2023
-
[20]
Chartqapro: A more diverse and challenging benchmark for chart question answering
Ahmed Masry, Mohammed Saidul Islam, Mahir Ahmed, Aayush Bajaj, Firoz Kabir, Aarya- man Kartha, Md Tahmid Rahman Laskar, Mizanur Rahman, Shadikur Rahman, Mehrad Shahmohammadi, et al. Chartqapro: A more diverse and challenging benchmark for chart question answering. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 19123–19151,
2025
-
[21]
Thomas McCoy, Shunyu Yao, Dan Friedman, Matthew Hardy, and Thomas L
R Thomas McCoy, Shunyu Yao, Dan Friedman, Matthew Hardy, and Thomas L Griffiths. Embers of autoregression: Understanding large language models through the problem they are trained to solve.arXiv preprint arXiv:2309.13638,
-
[22]
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 12076–12100,
2023
-
[23]
doi: 10.18653/v1/2020.acl-main.135
Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.135. URL https://aclanthology.org/2020.acl-main. 135/. 12 Preprint. Under review. David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst confe...
-
[24]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
Paul R¨ottger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)...
2024
-
[25]
Pelican: Correcting hallucination in vision- llms via claim decomposition and program of thought verification
Pritish Sahu, Karan Sikka, and Ajay Divakaran. Pelican: Correcting hallucination in vision- llms via claim decomposition and program of thought verification. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 8228–8248,
2024
-
[26]
Temporal dynamics-aware adversarial attacks on discrete-time dynamic graph models
Kartik Sharma, Rakshit Trivedi, Rohit Sridhar, and Srijan Kumar. Temporal dynamics-aware adversarial attacks on discrete-time dynamic graph models. InProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining, pp. 2023–2035,
2023
-
[27]
Can vlms actually see and read? a survey on modality collapse in vision-language models
Mong Yuan Sim, Wei Emma Zhang, Xiang Dai, and Biaoyan Fang. Can vlms actually see and read? a survey on modality collapse in vision-language models. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 24452–24470,
2025
-
[28]
Ai-liedar: Examine the trade-off between utility and truthfulness in llm agents
Zhe Su, Xuhui Zhou, Sanketh Rangreji, Anubha Kabra, Julia Mendelsohn, Faeze Brahman, and Maarten Sap. Ai-liedar: Examine the trade-off between utility and truthfulness in llm agents. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pape...
2025
-
[29]
Fever: a large-scale dataset for fact extraction and verification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. Fever: a large-scale dataset for fact extraction and verification. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 809–819,
2018
-
[30]
Lost in the Middle: How Language Models Use Long Contexts
doi: 10.1162/tacl a 00475. URL https: //aclanthology.org/2022.tacl-1.31/. Ming Tu, Guangtao Wang, Jing Huang, Yun Tang, Xiaodong He, and Bowen Zhou. Multi- hop reading comprehension across multiple documents by reasoning over heterogeneous graphs. In Anna Korhonen, David Traum, and Llu´ıs M`arquez (eds.),Proceedings of the 57th Annual Meeting of the Assoc...
work page internal anchor Pith review doi:10.1162/tacl 2022
-
[31]
Association for Computational Linguistics. doi: 10.18653/v1/P19-1260. URLhttps://aclanthology.org/P19-1260/. Hemish Veeraboina. Aime problem set 1983-2024,
-
[32]
Juraj Vladika, Phillip Schneider, and Florian Matthes
URL https://www.kaggle.com/ datasets/hemishveeraboina/aime-problem-set-1983-2024. Juraj Vladika, Phillip Schneider, and Florian Matthes. Healthfc: Verifying health claims with evidence-based medical fact-checking. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pp...
1983
-
[33]
Under review
13 Preprint. Under review. Juraj Vladika, Ivana Hacajova, and Florian Matthes. Step-by-step fact verification system for medical claims with explainable reasoning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pp. 805–816,
2025
-
[34]
Fact or fiction: Verifying scientific claims
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. Fact or fiction: Verifying scientific claims. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 7534–7550,
2020
-
[35]
Scifact-open: Towards open-domain scientific claim verification
David Wadden, Kyle Lo, Bailey Kuehl, Arman Cohan, Iz Beltagy, Lucy Lu Wang, and Hannaneh Hajishirzi. Scifact-open: Towards open-domain scientific claim verification. In Findings of the Association for Computational Linguistics: EMNLP 2022, pp. 4719–4734,
2022
-
[36]
Sciriff: A resource to enhance language model instruction-following over scientific literature
David Wadden, Kejian Shi, Jacob Morrison, Alan Li, Aakanksha Naik, Shruti Singh, Nitzan Barzilay, Kyle Lo, Tom Hope, Luca Soldaini, et al. Sciriff: A resource to enhance language model instruction-following over scientific literature. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 6083–6120,
2025
-
[37]
Unveiling confirmation bias in chain-of- thought reasoning
Yue Wan, Xiaowei Jia, and Xiang Lorraine Li. Unveiling confirmation bias in chain-of- thought reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 3788–3804,
2025
-
[38]
Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Aky¨urek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human...
2024
-
[39]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pp. 2369–2380,
2018
-
[40]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review arXiv
-
[41]
Congzhi Zhang, Linhai Zhang, and Deyu Zhou. Causal walk: Debiasing multi-hop fact verification with front-door adjustment. InProceedings of the AAAI conference on artificial intelligence, volume 38, pp. 19533–19541, 2024a. Zhehao Zhang, Jiaao Chen, and Diyi Yang. Darg: Dynamic evaluation of large language models via adaptive reasoning graph.Advances in Ne...
-
[42]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Denny Zhou, Nathanael Sch¨arli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models, 2023.URL https://arxiv. org/abs/2205.10625,
work page internal anchor Pith review arXiv 2023
-
[43]
Variation in Verification: Understanding Verification Dynamics in Large Language Models
14 Preprint. Under review. Yefan Zhou, Austin Xu, Yilun Zhou, Janvijay Singh, Jiang Gui, and Shafiq Joty. Variation in verification: Understanding verification dynamics in large language models.arXiv preprint arXiv:2509.17995,
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
and AIME (Veeraboina, 2023). Both datasets require multi-step reasoning where a correct solution must satisfy multiple constraints simultaneously, making them natural analogues to the compositional verification setting in the main paper. We select GPT-4o-mini as the solver because it achieves non-trivial but imperfect accuracy on both tasks, producing a m...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.