Recognition: unknown
Semantic-Geometric Dual Compression: Training-Free Visual Token Reduction for Ultra-High-Resolution Remote Sensing Understanding
Pith reviewed 2026-05-10 15:25 UTC · model grok-4.3
The pith
Splitting visual tokens into semantic and geometric streams cuts computation for ultra-high-resolution remote sensing while raising accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
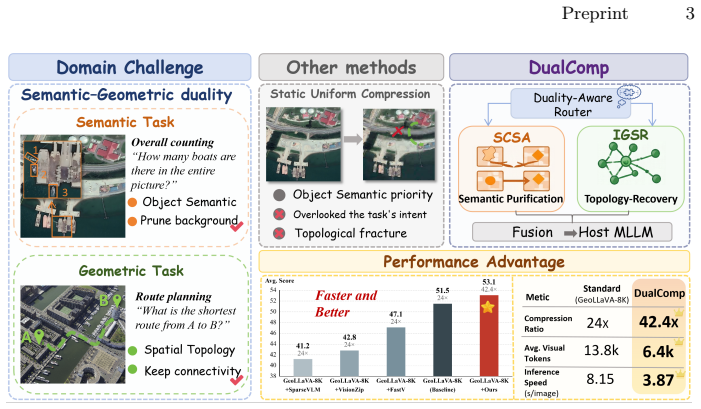
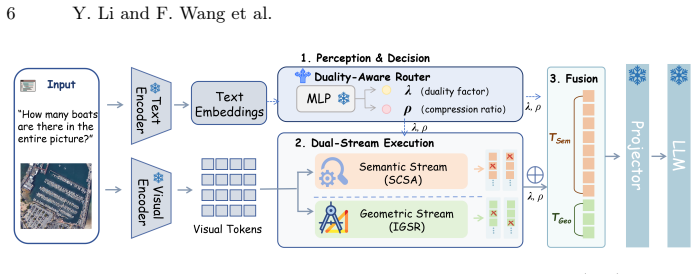
DualComp decouples token processing into an object semantic stream that applies size-adaptive clustering to prune redundant background while shielding small objects, and a scene geometric stream that uses greedy path-tracing to reconstruct spatial topology, all directed by a lightweight pre-trained router and without any task-specific training.
What carries the argument
The task-adaptive dual-stream framework, consisting of a router that splits features plus the Spatially-Contiguous Semantic Aggregator for background aggregation and the Instruction-Guided Structure Recoverer for topology recovery.
If this is right
- Multimodal models can process ultra-high-resolution remote sensing images with far fewer tokens and no accuracy loss.
- Both object-level and scene-level remote sensing tasks improve at once rather than trading off.
- The entire compression process runs without any task-specific training or fine-tuning.
- The same dual-path logic scales across different remote sensing benchmarks that mix semantics and geometry.
Where Pith is reading between the lines
- The semantic-geometric split could transfer to other high-resolution vision domains such as medical scans or autonomous driving where detail and layout both matter.
- Energy use for satellite-data AI would drop if the router overhead stays small at deployment scale.
- Integrating the router directly into the vision encoder might remove the separate pre-training step entirely.
Load-bearing premise
A lightweight pre-trained router can correctly separate semantic and geometric aspects of the image features, and the clustering plus path-tracing steps keep every necessary detail without further tuning.
What would settle it
Run DualComp and a uniform baseline on a set of ultra-high-resolution images that contain both tiny objects and intricate spatial layouts; if accuracy falls below the baseline when the router receives mismatched task signals, the separation claim fails.
Figures


read the original abstract
Multimodal Large Language Models (MLLMs) have demonstrated immense potential in Earth observation. However, the massive visual tokens generated when processing Ultra-High-Resolution (UHR) imagery introduce prohibitive computational overhead, severely bottlenecking their inference efficiency. Existing visual token compression methods predominantly adopt static and uniform compression strategies, neglecting the inherent "Semantic-Geometric Duality" in remote sensing interpretation tasks. Specifically, object semantic tasks focus on the abstract semantics of objects and benefit from aggressive background pruning, whereas scene geometric tasks critically rely on the integrity of spatial topology. To address this challenge, we propose DualComp, a task-adaptive dual-stream token compression framework. Dynamically guided by a lightweight pre-trained router, DualComp decouples feature processing into two dedicated pathways. In the object semantic stream, the Spatially-Contiguous Semantic Aggregator (SCSA) utilizes size-adaptive clustering to aggregates redundant background while protecting small object. In the scene geometric stream, the Instruction-Guided Structure Recoverer (IGSR) introduces a greedy path-tracing topology completion mechanism to reconstruct spatial skeletons. Experiments on the UHR remote sensing benchmark XLRS-Bench demonstrate that DualComp accomplishes high-fidelity remote sensing interpretation at an exceptionally low computational cost, achieving simultaneous improvements in both efficiency and accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DualComp, a training-free dual-stream visual token compression framework for MLLMs processing ultra-high-resolution remote sensing imagery. A lightweight pre-trained router decouples tokens into an object semantic stream (using Spatially-Contiguous Semantic Aggregator with size-adaptive clustering to prune background while protecting small objects) and a scene geometric stream (using Instruction-Guided Structure Recoverer with greedy path-tracing to reconstruct spatial topology). Experiments on XLRS-Bench are claimed to show simultaneous gains in efficiency and accuracy by exploiting semantic-geometric duality.
Significance. If the empirical results and router reliability hold, the work would be significant for enabling scalable MLLM inference on UHR remote sensing data without fine-tuning, by providing a task-adaptive compression strategy that avoids uniform token reduction.
major comments (2)
- [Method (router description)] The router's ability to correctly decouple semantic vs. geometric tokens is load-bearing for the dual-stream claim and the reported accuracy lift, yet the manuscript supplies no architecture details, training corpus, or remote-sensing-specific validation; domain shift in scale/spectral statistics could cause systematic misrouting and collapse the method to a single suboptimal path.
- [Experiments / Abstract] The central claim of simultaneous efficiency and accuracy improvements on XLRS-Bench is unsupported by any quantitative metrics, baselines, ablations, or error analysis in the provided text, preventing evaluation of whether SCSA and IGSR actually preserve necessary information.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of the router and experimental results.
read point-by-point responses
-
Referee: [Method (router description)] The router's ability to correctly decouple semantic vs. geometric tokens is load-bearing for the dual-stream claim and the reported accuracy lift, yet the manuscript supplies no architecture details, training corpus, or remote-sensing-specific validation; domain shift in scale/spectral statistics could cause systematic misrouting and collapse the method to a single suboptimal path.
Authors: We agree that the router is central and that the current description is insufficient. We will revise the method section to include the router's architecture (a lightweight two-layer MLP with sigmoid output for binary semantic/geometric routing), the training corpus (ImageNet plus a curated remote-sensing subset to reduce domain shift), and remote-sensing-specific validation (routing accuracy on XLRS-Bench samples with manual annotations). These additions will allow readers to assess robustness against misrouting. revision: yes
-
Referee: [Experiments / Abstract] The central claim of simultaneous efficiency and accuracy improvements on XLRS-Bench is unsupported by any quantitative metrics, baselines, ablations, or error analysis in the provided text, preventing evaluation of whether SCSA and IGSR actually preserve necessary information.
Authors: We acknowledge that the provided manuscript text does not contain the supporting quantitative results. We will expand the experiments section with tables reporting token reduction ratios, FLOPs, latency, and accuracy on XLRS-Bench against uniform compression baselines, plus ablations isolating SCSA (size-adaptive clustering) and IGSR (path-tracing), and error analysis on object preservation and topology integrity. This will substantiate the abstract claim and demonstrate information preservation. revision: yes
Circularity Check
No circularity: method is a descriptive framework with no derivations, equations, or self-referential reductions.
full rationale
The paper introduces DualComp as a training-free dual-stream compression approach guided by a pre-trained router, with SCSA and IGSR as custom components. No mathematical derivations, equations, parameter fittings, or uniqueness theorems appear in the text. Performance claims are framed as experimental results on XLRS-Bench rather than tautological outcomes from the same inputs or self-citations. The router is described as lightweight and pre-trained without any indication of fitting to validation data. This is a standard engineering proposal whose central claims rest on empirical validation, not on any reduction to its own definitions or prior self-references.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Remote sensing interpretation tasks exhibit an inherent semantic-geometric duality that can be decoupled for compression
invented entities (3)
-
DualComp framework
no independent evidence
-
Spatially-Contiguous Semantic Aggregator (SCSA)
no independent evidence
-
Instruction-Guided Structure Recoverer (IGSR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., faces, S.A., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
NeurIPS35, 23716–23736 (2022) 2, 4
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. NeurIPS35, 23716–23736 (2022) 2, 4
2022
-
[3]
Anthropic: Anthropic ai (2023),https://www.anthropic.com11
2023
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.129661(2), 3 (2023) 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025
Bai, L., Cai, Z., Cao, Y., Cao, M., Cao, W., Chen, C., Chen, H., Chen, K., Chen, P., Chen, Y., et al.: Intern-s1: A scientific multimodal foundation model. arXiv preprint arXiv:2508.15763 (2025) 4, 11
-
[6]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025) 4, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 4, 10, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Token Merging: Your ViT But Faster
Bolya, D., Fu, C.Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461 (2022) 4
work page internal anchor Pith review arXiv 2022
-
[9]
Machine Learning111(9), 3125–3160 (2022) 2
Castillo-Navarro, J., Le Saux, B., Boulch, A., Audebert, N., Lefèvre, S.: Semi- supervised semantic segmentation in earth observation: The minifrance suite, dataset analysis and multi-task network study. Machine Learning111(9), 3125–3160 (2022) 2
2022
-
[10]
In: ECCV
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In: ECCV. pp. 19–35 (2024) 2, 4, 5, 11
2024
-
[11]
Science China Information Sciences67(12), 220101 (2024) 2
Chen, Z., Wang, W., Tian, H., Ye, S., Gao, Z., Cui, E., Tong, W., Hu, K., Luo, J., Ma, Z., et al.: How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. Science China Information Sciences67(12), 220101 (2024) 2
2024
-
[12]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025) 11 16 Y. Li and F. Wang et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
NeurIPS36, 49250–49267 (2023) 2, 4
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. NeurIPS36, 49250–49267 (2023) 2, 4
2023
-
[14]
arXiv preprint arXiv:2501.09532 , year=
Han, J., Du, L., Wu, Y., Zhou, X., Du, H., Zheng, W.: Adafv: Rethinking of visual-language alignment for vlm acceleration. arXiv preprint arXiv:2501.09532 (2025) 4
-
[15]
ISPRS Journal of Photogrammetry and Remote Sensing224, 272–286 (2025) 2, 5
Hu, Y., Yuan, J., Wen, C., Lu, X., Liu, Y., Li, X.: Rsgpt: A remote sensing vision language model and benchmark. ISPRS Journal of Photogrammetry and Remote Sensing224, 272–286 (2025) 2, 5
2025
-
[16]
In: CVPR
Kuckreja, K., Danish, M.S., Naseer, M., Das, A., Khan, S., Khan, F.S.: Geochat: Grounded large vision-language model for remote sensing. In: CVPR. pp. 27831– 27840 (2024) 2, 5, 11
2024
-
[17]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
In: ICML
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: ICML. pp. 19730–19742 (2023) 4
2023
-
[19]
arXiv preprint arXiv:2411.09301 (2024),https://arxiv.org/abs/ 2411.093015
Li, Z., Muhtar, D., Gu, F., Zhang, X., Xiao, P., He, G., Zhu, X.: Lhrs-bot-nova: Improved multimodal large language model for remote sensing vision-language interpretation. arXiv preprint arXiv:2411.09301 (2024),https://arxiv.org/abs/ 2411.093015
-
[20]
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (2024) 2, 5, 11
2024
-
[21]
NeurIPS36, 34892– 34916 (2023) 4
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. NeurIPS36, 34892– 34916 (2023) 4
2023
-
[22]
Liu, R., Fu, B., Song, J., Li, K., Li, W., Xue, L., Qiao, H., Zhang, W., Meng, D., Cao, X.: Zoomearth: Active perception for ultra-high-resolution geospatial vision-language tasks. arXiv preprint arXiv:2511.12267 (2025) 2, 5, 11
-
[23]
Liu, X., Lian, Z.: Rsunivlm: A unified vision language model for remote sensing via granularity-oriented mixture of experts. arXiv preprint arXiv:2412.05679 (2024), https://arxiv.org/abs/2412.056795
-
[24]
In: ICCV
Luo, J., Zhang, Y., Yang, X., Wu, K., Zhu, Q., Liang, L., Chen, J., Li, Y.: When large vision-language model meets large remote sensing imagery: Coarse-to-fine text-guided token pruning. In: ICCV. pp. 9206–9217 (2025) 2, 5, 11
2025
-
[25]
Nature Reviews Neuroscience13(11), 758–768 (2012) 4
Menzel, R.: The honeybee as a model for understanding the basis of cognition. Nature Reviews Neuroscience13(11), 758–768 (2012) 4
2012
-
[26]
In: ECCV
Muhtar, D., Li, Z., Gu, F., Zhang, X., Xiao, P.: Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model. In: ECCV. pp. 440–457 (2024) 2
2024
-
[27]
OpenAI: Introducing gpt-5.2. Tech. rep., OpenAI (2025),https://openai.com/ index/introducing-gpt-5-2/11
2025
-
[28]
arXiv preprint arXiv:2403.20213 (2024),https://arxiv.org/abs/ 2403.202135
Pang, C., Weng, X., Wu, J., Li, J., Liu, Y., Sun, J., Li, W., Wang, S., Feng, L., Xia, G.S., He, C.: Vhm: Versatile and honest vision language model for remote sensing image analysis. arXiv preprint arXiv:2403.20213 (2024),https://arxiv.org/abs/ 2403.202135
-
[29]
In: ICML
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML. pp. 8748–8763 (2021) 7, 9 Preprint 17
2021
-
[30]
In: ICCV
Shang, Y., Cai, M., Xu, B., Lee, Y.J., Yan, Y.: Llava-prumerge: Adaptive token reduction for efficient large multimodal models. In: ICCV. pp. 22857–22867 (2025) 2
2025
-
[31]
arXiv preprint arXiv:2506.01667 (2025), https://arxiv.org/abs/2506.016675
Shu, Y., Ren, B., Xiong, Z., Paudel, D.P., Gool, L.V., Demir, B., Sebe, N., Rota, P.: Earthmind: Leveraging cross-sensor data for advanced earth observation inter- pretation with a unified multimodal llm. arXiv preprint arXiv:2506.01667 (2025), https://arxiv.org/abs/2506.016675
-
[32]
arXiv preprint arXiv:2402.06475 (2024), https://arxiv.org/abs/2402.064755
Silva, J.D., Magalhães, J., Tuia, D., Martins, B.: Large language models for caption- ing and retrieving remote sensing images. arXiv preprint arXiv:2402.06475 (2024), https://arxiv.org/abs/2402.064755
-
[33]
arXiv preprint arXiv:2412.15190 (2025),https://arxiv.org/abs/2412.151905
Soni, S., Dudhane, A., Debary, H., Fiaz, M., Munir, M.A., Danish, M.S., Fraccaro, P., Watson, C.D., Klein, L.J., Khan, F.S., Khan, S.: Earthdial: Turning multi- sensory earth observations to interactive dialogues. arXiv preprint arXiv:2412.15190 (2025),https://arxiv.org/abs/2412.151905
-
[34]
arXiv preprint arXiv:2511.21150 (2025) 2
Sun, S., Zhang, Y., Song, H., Guo, Z., Chen, C., Zhang, Y., Yao, Y., Liu, Z., Sun, M.: Llava-uhd v3: Progressive visual compression for efficient native-resolution encoding in mllms. arXiv preprint arXiv:2511.21150 (2025) 2
-
[35]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023) 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
NeurIPS30(2017) 4
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. NeurIPS30(2017) 4
2017
-
[38]
arXiv preprint arXiv:2511.20085 (2025) 5
Wang, C., Luo, Z., Liu, R., Ran, C., Fan, S., Chen, X., He, C.: Vicot-agent: A vision- interleaved chain-of-thought framework for interpretable multimodal reasoning and scalable remote sensing analysis. arXiv preprint arXiv:2511.20085 (2025) 5
-
[39]
GeoLLaVA-8K: Scaling remote-sensing multimodal large language models to 8K resolution,
Wang, F., Chen, M., Li, Y., Wang, D., Wang, H., Guo, Z., Wang, Z., Shan, B., Lan, L., Wang, Y., et al.: Geollava-8k: Scaling remote-sensing multimodal large language models to 8k resolution. arXiv preprint arXiv:2505.21375 (2025) 2, 5, 11
-
[40]
Wang, F., Wang, H., Guo, Z., Wang, D., Wang, Y., Chen, M., Ma, Q., Lan, L., Yang, W., Zhang, J., et al.: Xlrs-bench: Could your multimodal llms understand extremely large ultra-high-resolution remote sensing imagery? In: CVPR. pp. 14325–14336 (2025) 10
2025
-
[41]
arXiv preprint arXiv:2601.02783 (2026),https://arxiv.org/abs/2601.027835
Wang, J., Zhong, Y., Chen, Z., Zheng, Z., Ma, A., Zhang, L.: Earthvl: A progressive earth vision-language understanding and generation framework. arXiv preprint arXiv:2601.02783 (2026),https://arxiv.org/abs/2601.027835
-
[42]
Wang, P., Hu, H., Tong, B., Zhang, Z., Yao, F., Feng, Y., Zhu, Z., Chang, H., Diao, W., Ye, Q., Sun, X.: Ringmogpt: A unified remote sensing foundation model for vision, language, and grounded tasks. IEEE Transactions on Geoscience and Remote Sensing63, 1–20 (2025).https://doi.org/10.1109/TGRS.2024.3510833 5
-
[43]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024) 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
arXiv preprint arXiv:2411.10442 , year=
Wang, W., Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Zhu, J., Zhu, X., Lu, L., Qiao, Y., et al.: Enhancing the reasoning ability of multimodal large language models via mixed preference optimization. arXiv preprint arXiv:2411.10442 (2024) 4, 11 18 Y. Li and F. Wang et al
-
[45]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Xia, G.S., Bai, X., Ding, J., Zhu, Z., Belongie, S., Luo, J., Datcu, M., Pelillo, M., Zhang, L.: Dota: A large-scale dataset for object detection in aerial images. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3974–3983 (2018) 2
2018
-
[46]
Xing, L., Huang, Q., Dong, X., Lu, J., Zhang, P., Zang, Y., Cao, Y., He, C., Wang, J., Wu, F., et al.: Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction. arXiv preprint arXiv:2410.17247 (2024) 2, 4, 5
-
[47]
In: CVPR
Yang, S., Chen, Y., Tian, Z., Wang, C., Li, J., Yu, B., Jia, J.: Visionzip: Longer is better but not necessary in vision language models. In: CVPR. pp. 19792–19802 (2025) 2, 4, 5, 11
2025
-
[48]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Ye, Q., Xu, H., Xu, G., Ye, J., Yan, M., Zhou, Y., Wang, J., Hu, A., Shi, P., Shi, Y., et al.: mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178 (2023) 2, 4
work page Pith review arXiv 2023
-
[49]
In: AAAI
Ye, W., Wu, Q., Lin, W., Zhou, Y.: Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. In: AAAI. vol. 39, pp. 22128–22136 (2025) 2
2025
-
[50]
In: CVPR
Ye, X., Gan, Y., Ge, Y., Zhang, X.P., Tang, Y.: Atp-llava: Adaptive token pruning for large vision language models. In: CVPR. pp. 24972–24982 (2025) 2
2025
-
[51]
In: CVPR
Ye, X., Gan, Y., Ge, Y., Zhang, X.P., Tang, Y.: Atp-llava: Adaptive token pruning for large vision language models. In: CVPR. pp. 24972–24982 (2025) 4
2025
-
[52]
arXiv preprint arXiv:2601.22674 (2026) 4
Yu, H., Li, W., Qu, X., Wang, S., Chen, J., Zhu, J.: Visiontrim: Unified vision token compression for training-free mllm acceleration. arXiv preprint arXiv:2601.22674 (2026) 4
-
[53]
arXiv preprint arXiv:2508.01548 (2025) 2
Zeng, Q.S., Li, Y., Wang, Q., Jiang, P.T., Wu, Z., Cheng, M.M., Hou, Q.: A glimpse to compress: Dynamic visual token pruning for large vision-language models. arXiv preprint arXiv:2508.01548 (2025) 2
-
[54]
ISPRS Journal of Pho- togrammetry and Remote Sensing221, 64–77 (2025) 5
Zhan, Y., Xiong, Z., Yuan, Y.: Skyeyegpt: Unifying remote sensing vision-language tasks via instruction tuning with large language model. ISPRS Journal of Pho- togrammetry and Remote Sensing221, 64–77 (2025) 5
2025
-
[55]
VScan: Rethinking Visual Token Reduction for Efficient Large Vision- Language Models
Zhang, C., Ma, K., Fang, T., Yu, W., Zhang, H., Zhang, Z., Xie, Y., Sycara, K., Mi, H., Yu, D.: Vscan: Rethinking visual token reduction for efficient large vision-language models. arXiv preprint arXiv:2505.22654 (2025) 2, 4
-
[56]
Zhang, Q., Cheng, A., Lu, M., Zhuo, Z., Wang, M., Cao, J., Guo, S., She, Q., Zhang, S.: [CLS] attention is all you need for training-free visual token pruning: Make vlm inference faster. arXiv preprint arXiv:2412.01818v1 (2024) 4, 8
-
[57]
arXiv preprint arXiv:2407.13596 (2024),https://arxiv.org/abs/2407.135965
Zhang, W., Cai, M., Zhang, T., Li, J., Zhuang, Y., Mao, X.: Earthmarker: A visual prompting multi-modal large language model for remote sensing. arXiv preprint arXiv:2407.13596 (2024),https://arxiv.org/abs/2407.135965
-
[58]
IEEE Transactions on Geoscience and Remote Sensing62, 1–20 (2024) 5
Zhang, W., Cai, M., Zhang, T., Zhuang, Y., Mao, X.: Earthgpt: A universal multimodal large language model for multisensor image comprehension in remote sensing domain. IEEE Transactions on Geoscience and Remote Sensing62, 1–20 (2024) 5
2024
-
[59]
Zhang, Y., Fan, C.K., Ma, J., Zheng, W., Huang, T., Cheng, K., Gudovskiy, D., Okuno, T., Nakata, Y., Keutzer, K., et al.: Sparsevlm: Visual token sparsification for efficient vision-language model inference. arXiv preprint arXiv:2410.04417 (2024) 4, 5, 11
-
[60]
arXiv preprint arXiv:2411.07688 (2024) 5 Preprint 19
Zhang, Z., Shen, H., Zhao, T., Guan, Z., Chen, B., Wang, Y., Jia, X., Cai, Y., Shang, Y., Yin, J.: Imagerag: Enhancing ultra high resolution remote sensing imagery analysis with imagerag. arXiv preprint arXiv:2411.07688 (2024) 5 Preprint 19
-
[61]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision- language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023) 2, 4
work page internal anchor Pith review arXiv 2023
-
[62]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., bit, Y.D., Tian, H., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025) 4, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.