Recognition: unknown
Hierarchical Textual Knowledge for Enhanced Image Clustering
Pith reviewed 2026-05-10 15:02 UTC · model grok-4.3
The pith
Hierarchical textual knowledge built from LLMs improves image clustering by distinguishing visually similar but semantically different classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
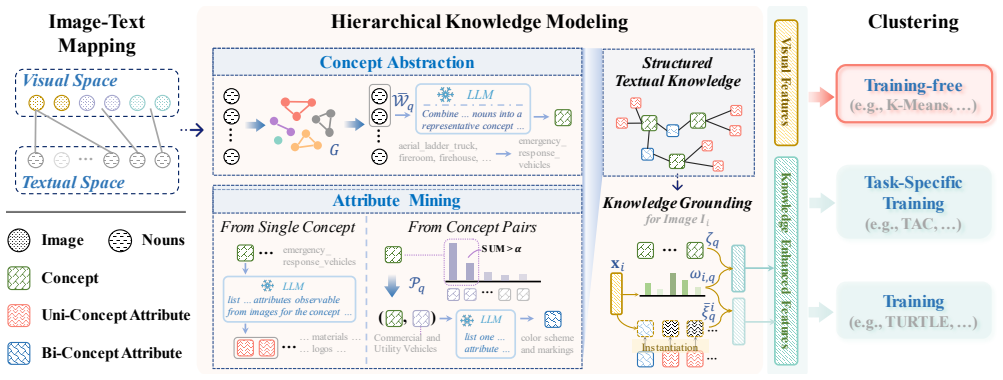
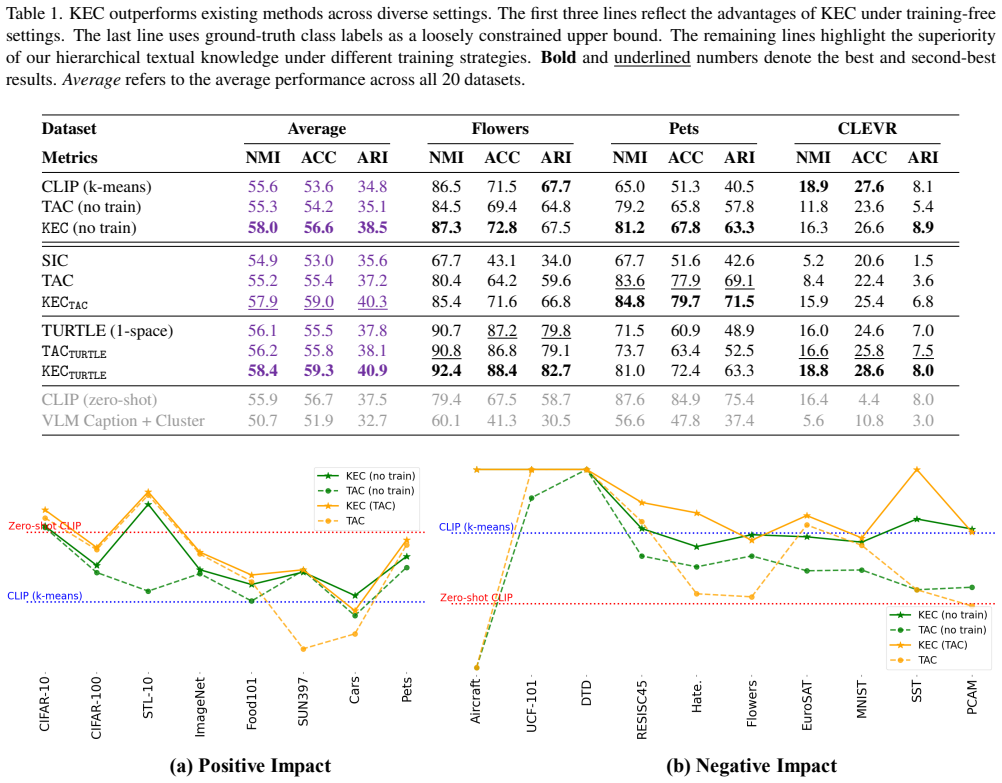
We propose a knowledge-enhanced clustering method that constructs hierarchical concept-attribute structured knowledge via structured prompts to LLMs, instantiates this knowledge for each input image, and fuses it with original visual features to guide various downstream clustering algorithms, yielding consistent improvements and outperforming zero-shot CLIP on fourteen of twenty diverse datasets while avoiding the performance drops seen with naive textual knowledge.
What carries the argument
The hierarchical concept-attribute structured knowledge, built by first condensing textual labels into abstract concepts and then extracting discriminative attributes for single concepts and similar pairs through LLM prompts, which is then instantiated per image to create knowledge-enhanced features.
Load-bearing premise
The LLM-generated hierarchical concept-attribute knowledge must be accurate and discriminative enough to help rather than harm when fused with visual features.
What would settle it
On a held-out dataset of visually similar classes, measure whether adding the KEC knowledge raises or lowers standard clustering metrics such as normalized mutual information or adjusted rand index compared to the visual-only baseline.
Figures




read the original abstract
Image clustering aims to group images in an unsupervised fashion. Traditional methods focus on knowledge from visual space, making it difficult to distinguish between visually similar but semantically different classes. Recent advances in vision-language models enable the use of textual knowledge to enhance image clustering. However, most existing methods rely on coarse class labels or simple nouns, overlooking the rich conceptual and attribute-level semantics embedded in textual space. In this paper, we propose a knowledge-enhanced clustering (KEC) method that constructs a hierarchical concept-attribute structured knowledge with the help of large language models (LLMs) to guide clustering. Specifically, we first condense redundant textual labels into abstract concepts and then automatically extract discriminative attributes for each single concept and similar concept pairs, via structured prompts to LLMs. This knowledge is instantiated for each input image to achieve the knowledge-enhanced features. The knowledge-enhanced features with original visual features are adapted to various downstream clustering algorithms. We evaluate KEC on 20 diverse datasets, showing consistent improvements across existing methods using additional textual knowledge. KEC without training outperforms zero-shot CLIP on 14 out of 20 datasets. Furthermore, the naive use of textual knowledge may harm clustering performance, while KEC provides both accuracy and robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Knowledge-Enhanced Clustering (KEC) method that uses LLMs to construct hierarchical concept-attribute structured knowledge from textual labels. Labels are first condensed into abstract concepts, then discriminative attributes are extracted for individual concepts and similar concept pairs via structured prompts; this knowledge is instantiated per image and fused with visual features to improve downstream clustering algorithms. Experiments across 20 datasets report consistent gains over baselines, with KEC (no training) outperforming zero-shot CLIP on 14/20 datasets and greater robustness than naive textual knowledge integration.
Significance. If the central results hold, the work would be significant for showing how structured, hierarchical textual knowledge from LLMs can augment visual features in unsupervised clustering, particularly for semantically distinct but visually similar classes. The broad evaluation on 20 diverse datasets and the explicit contrast with naive text use are strengths that provide a useful benchmark for future multimodal clustering methods.
major comments (3)
- [§3.2] §3.2 (Attribute Extraction): The central claim that the hierarchical concept-attribute knowledge provides reliably beneficial discriminative signal rests on the quality of LLM outputs, yet the manuscript contains no validation (e.g., consistency across multiple LLM runs, automated checks, or human evaluation of attribute accuracy/discriminativeness). This is load-bearing because any observed gains could arise from dataset artifacts rather than the proposed hierarchy.
- [§4.3] §4.3 (Main Results, Table reporting 14/20 wins): The outperformance over zero-shot CLIP is presented without statistical significance tests, error bars, or variance analysis across runs. This undermines the robustness claim, as it is unclear whether the 14/20 figure reflects reliable improvement or dataset-specific effects.
- [§4.4] §4.4 (Ablations/Robustness): While the abstract states that naive textual knowledge can harm performance and KEC provides robustness, no ablations on prompt sensitivity, LLM choice, or failure modes (e.g., when attributes introduce noise) are reported. These are needed to substantiate that the structured hierarchy, rather than incidental factors, drives the gains.
minor comments (2)
- [§3.3] The notation for knowledge instantiation and feature fusion (e.g., how attributes are combined with visual embeddings) would benefit from an explicit equation or pseudocode for reproducibility.
- A few figure legends (e.g., those showing concept hierarchies) are terse; expanding them to describe what each panel illustrates would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional evidence would strengthen the manuscript. We address each major comment below with clarifications and commit to targeted revisions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Attribute Extraction): The central claim that the hierarchical concept-attribute knowledge provides reliably beneficial discriminative signal rests on the quality of LLM outputs, yet the manuscript contains no validation (e.g., consistency across multiple LLM runs, automated checks, or human evaluation of attribute accuracy/discriminativeness). This is load-bearing because any observed gains could arise from dataset artifacts rather than the proposed hierarchy.
Authors: We agree that validating the quality of the LLM-generated attributes is essential to support the central claims. The original manuscript did not include such validation. In the revised version we will add a human evaluation of attribute accuracy and discriminativeness on a sampled subset of concepts across several datasets, along with consistency metrics obtained by repeating LLM calls with different random seeds. revision: yes
-
Referee: [§4.3] §4.3 (Main Results, Table reporting 14/20 wins): The outperformance over zero-shot CLIP is presented without statistical significance tests, error bars, or variance analysis across runs. This undermines the robustness claim, as it is unclear whether the 14/20 figure reflects reliable improvement or dataset-specific effects.
Authors: We acknowledge that the reported 14/20 outperformance is based on single runs without error bars or significance testing. In the revision we will repeat the clustering experiments with multiple random seeds (where the algorithms admit stochasticity) and include mean results with standard deviations together with appropriate statistical tests. revision: yes
-
Referee: [§4.4] §4.4 (Ablations/Robustness): While the abstract states that naive textual knowledge can harm performance and KEC provides robustness, no ablations on prompt sensitivity, LLM choice, or failure modes (e.g., when attributes introduce noise) are reported. These are needed to substantiate that the structured hierarchy, rather than incidental factors, drives the gains.
Authors: The manuscript does contrast KEC against naive textual integration and shows that the latter can degrade performance. We agree, however, that explicit ablations on prompt sensitivity, LLM choice, and failure cases are missing. We will expand the experimental section to include these analyses, testing alternative prompt formulations, a second LLM, and qualitative discussion of cases where attributes may add noise. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an empirical method (KEC) that uses external LLMs via structured prompts to condense labels into concepts and extract attributes, then fuses the resulting textual knowledge with visual features before feeding into standard clustering algorithms. All performance claims rest on direct evaluation across 20 datasets rather than any closed-form derivation, fitted-parameter prediction, or self-referential definition. No equations, uniqueness theorems, or load-bearing self-citations appear in the abstract or method description that would reduce the central result to its own inputs by construction. The approach is therefore self-contained against external benchmarks (LLM outputs and visual encoders) and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can extract accurate and discriminative concept-attribute knowledge from textual labels via structured prompts
Reference graph
Works this paper leans on
-
[1]
Food-101 - mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101 - mining discriminative components with random forests. InECCV (6), pages 446–461. Springer, 2014. 1
2014
-
[2]
Semantic-enhanced image clustering
Shaotian Cai, Liping Qiu, Xiaojun Chen, Qin Zhang, and Longteng Chen. Semantic-enhanced image clustering. In AAAI, pages 6869–6878. AAAI Press, 2023. 1, 3, 4, 5, 6
2023
-
[3]
Tensorized and compressed multi-view sub- space clustering via structured constraint.IEEE Trans
Wei Chang, Huimin Chen, Feiping Nie, Rong Wang, and Xuelong Li. Tensorized and compressed multi-view sub- space clustering via structured constraint.IEEE Trans. Pat- tern Anal. Mach. Intell., 46(12):10434–10451, 2024. 3
2024
-
[4]
Generic attention- model explainability for interpreting bi-modal and encoder- decoder transformers
Hila Chefer, Shir Gur, and Lior Wolf. Generic attention- model explainability for interpreting bi-modal and encoder- decoder transformers. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 397–406, 2021. 2
2021
-
[5]
Remote sens- ing image scene classification: Benchmark and state of the art.Proc
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sens- ing image scene classification: Benchmark and state of the art.Proc. IEEE, 105(10):1865–1883, 2017. 1
2017
-
[6]
Image clustering via the principle of rate reduction in the age of pretrained models
Tianzhe Chu, Shengbang Tong, Tianjiao Ding, Xili Dai, Benjamin David Haeffele, Ren ´e Vidal, and Yi Ma. Image clustering via the principle of rate reduction in the age of pretrained models. InICLR. OpenReview.net, 2024. 1, 3
2024
-
[7]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InCVPR, pages 3606–3613. IEEE Computer Society,
-
[8]
Ng, and Honglak Lee
Adam Coates, Andrew Y . Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In AISTATS, pages 215–223. JMLR.org, 2011. 1
2011
-
[9]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, pages 248–255. IEEE Computer Society,
-
[10]
Haeffele
Tianjiao Ding, Shengbang Tong, Kwan Ho Ryan Chan, Xili Dai, Yi Ma, and Benjamin D. Haeffele. Unsupervised man- ifold linearizing and clustering. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 5427–5438. IEEE, 2023. 3
2023
-
[11]
Let go of your labels with unsupervised transfer
Artyom Gadetsky, Yulun Jiang, and Maria Brbic. Let go of your labels with unsupervised transfer. InICML. OpenRe- view.net, 2024. 1, 3, 5, 6
2024
-
[12]
Personalized clustering via targeted representation learning
Xiwen Geng, Suyun Zhao, Yixin Yu, Borui Peng, Pan Du, Hong Chen, Cuiping Li, and Mengdie Wang. Personalized clustering via targeted representation learning. InAAAI-25, Sponsored by the Association for the Advancement of Artifi- cial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 16790–16798. AAAI Press, 2025. 3
2025
-
[13]
Efficient constrained k-center clustering with background knowledge
Longkun Guo, Chaoqi Jia, Kewen Liao, Zhigang Lu, and Minhui Xue. Efficient constrained k-center clustering with background knowledge. InThirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Confer- ence on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial I...
2024
-
[14]
Graph cut-guided maxi- mal coding rate reduction for learning image embedding and clustering
Wei He, Zhiyuan Huang, Xianghan Meng, Xianbiao Qi, Rong Xiao, and Chun-Guang Li. Graph cut-guided maxi- mal coding rate reduction for learning image embedding and clustering. InComputer Vision - ACCV 2024 - 17th Asian Conference on Computer Vision, Hanoi, Vietnam, December 8-12, 2024, Proceedings, Part X, pages 359–376. Springer,
2024
-
[15]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE J
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens., 12(7):2217–2226,
-
[16]
Lawrence Zitnick, and Ross B
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross B. Girshick. CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. InCVPR, pages 1988–
1988
-
[17]
IEEE Computer Society, 2017. 7, 1
2017
-
[18]
The hateful memes challenge: Detecting hate speech in multimodal memes
Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Pratik Ringshia, and Davide Testuggine. The hateful memes challenge: Detecting hate speech in multimodal memes. InNeurIPS, 2020. 1
2020
-
[19]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In ICCV Workshops, pages 554–561. IEEE Computer Society,
-
[20]
Krizhevsky and G
A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images.Handbook of Systemic Autoim- mune Diseases, 1(4), 2009. 1
2009
-
[21]
Ryu, and Kangwook Lee
Sehyun Kwon, Jaeseung Park, Minkyu Kim, Jaewoong Cho, Ernest K. Ryu, and Kangwook Lee. Image clustering condi- tioned on text criteria. InICLR. OpenReview.net, 2024. 1, 3
2024
-
[22]
Gradient-based learning applied to document recog- nition.Proc
Yann LeCun, L ´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recog- nition.Proc. IEEE, 86(11):2278–2324, 1998. 1
1998
-
[23]
Image clustering with external guidance
Yunfan Li, Peng Hu, Dezhong Peng, Jiancheng Lv, Jianping Fan, and Xi Peng. Image clustering with external guidance. InICML. OpenReview.net, 2024. 1, 3, 4, 5, 6
2024
-
[24]
Interactive deep clustering via value mining
Honglin Liu, Peng Hu, Changqing Zhang, Yunfan Li, and Xi Peng. Interactive deep clustering via value mining. In Advances in Neural Information Processing Systems 38: An- nual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024. 3
2024
-
[25]
Weiwei Liu, Xiao-Bo Shen, and Ivor W. Tsang. Sparse embedded k-means clustering. InNIPS, pages 3319–3327,
-
[26]
Learned trajectory embedding for subspace clustering
Yaroslava Lochman, Carl Olsson, and Christopher Zach. Learned trajectory embedding for subspace clustering. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 19092–19102. IEEE, 2024. 2
2024
-
[27]
Phys- liquid: A physics-informed dataset for estimating 3d geom- etry and volume of transparent deformable liquids
Ke Ma, Yizhou Fang, Jean-Baptiste Weibel, Shuai Tan, Xinggang Wang, Yang Xiao, Yi Fang, and Tian Xia. Phys- liquid: A physics-informed dataset for estimating 3d geom- etry and volume of transparent deformable liquids. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 7782–7790, 2026. 3
2026
-
[28]
Macqueen
J. Macqueen. Some methods for classification and analysis of multivariate observations.Proc. Symp. Math. Statist. and Probability, 5th, 1, 1967. 1
1967
-
[29]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew B. Blaschko, and Andrea Vedaldi. Fine-grained visual classi- fication of aircraft.CoRR, abs/1306.5151, 2013. 1
work page internal anchor Pith review arXiv 2013
-
[30]
Divclust: Controlling diversity in deep clus- tering
Ioannis Maniadis Metaxas, Georgios Tzimiropoulos, and Ioannis Patras. Divclust: Controlling diversity in deep clus- tering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 3418–3428. IEEE, 2023. 3
2023
-
[31]
George A. Miller. Wordnet: A lexical database for english. Commun. ACM, 38(11):39–41, 1995. 1, 3, 6
1995
-
[32]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In ICVGIP, pages 722–729. IEEE Computer Society, 2008. 7, 1
2008
-
[33]
Parkhi, Andrea Vedaldi, Andrew Zisserman, and C
Omkar M. Parkhi, Andrea Vedaldi, Andrew Zisserman, and C. V . Jawahar. Cats and dogs. InCVPR, pages 3498–3505. IEEE Computer Society, 2012. 7, 1
2012
-
[34]
Platt, M
J.C. Platt, M. Czerwinski, and B.A. Field. Phototoc: au- tomatic clustering for browsing personal photographs. In Fourth International Conference on Information, Communi- cations and Signal Processing, 2003 and the Fourth Pacific Rim Conference on Multimedia. Proceedings of the 2003 Joint, pages 6–10 V ol.1, 2003. 1
2003
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, pages 8748–8763. PMLR, 2021. 1, 3, 5
2021
-
[36]
Yu, and Lifang He
Yazhou Ren, Jingyu Pu, Zhimeng Yang, Jie Xu, Guofeng Li, Xiaorong Pu, Philip S. Yu, and Lifang He. Deep cluster- ing: A comprehensive survey.IEEE Trans. Neural Networks Learn. Syst., 36(4):5858–5878, 2025. 1
2025
-
[37]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101: A dataset of 101 human actions classes from videos in the wild.CoRR, abs/1212.0402, 2012. 1
work page internal anchor Pith review arXiv 2012
-
[38]
Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition.Neural Net- works, 32:323–332, 2012. 1
2012
-
[39]
Text- guided image clustering
Andreas Stephan, Lukas Miklautz, Kevin Sidak, Jan Philip Wahle, Bela Gipp, Claudia Plant, and Benjamin Roth. Text- guided image clustering. InEACL (1), pages 2960–2976. Association for Computational Linguistics, 2024. 1, 3
2024
-
[40]
Li Sun, Zhenhao Huang, Hao Peng, Yujie Wang, Chunyang Liu, and Philip S. Yu. Lsenet: Lorentz structural entropy neural network for deep graph clustering. InICML. Open- Review.net, 2024. 1
2024
-
[41]
Alpha- clip: A CLIP model focusing on wherever you want
Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, and Jiaqi Wang. Alpha- clip: A CLIP model focusing on wherever you want. In CVPR, pages 13019–13029. IEEE, 2024. 2
2024
-
[42]
Veeling, Jasper Linmans, Jim Winkens, Taco Co- hen, and Max Welling
Bastiaan S. Veeling, Jasper Linmans, Jim Winkens, Taco Co- hen, and Max Welling. Rotation equivariant cnns for digital pathology. InMICCAI (2), pages 210–218. Springer, 2018. 1
2018
-
[43]
Large graph clustering with simultaneous spec- tral embedding and discretization.IEEE Trans
Zhen Wang, Zhaoqing Li, Rong Wang, Feiping Nie, and Xuelong Li. Large graph clustering with simultaneous spec- tral embedding and discretization.IEEE Trans. Pattern Anal. Mach. Intell., 43(12):4426–4440, 2021. 1, 2
2021
-
[44]
Ehinger, James Hays, Antonio Torralba, and Aude Oliva
Jianxiong Xiao, Krista A. Ehinger, James Hays, Antonio Torralba, and Aude Oliva. SUN database: Exploring a large collection of scene categories.Int. J. Comput. Vis., 119(1): 3–22, 2016. 1
2016
-
[45]
Hailong Yan, Shice Liu, Tao Wang, Xiangtao Zhang, Yijie Zhong, Jinwei Chen, Le Zhang, and Bo Li. Animeagent: Is the multi-agent via image-to-video models a good disney storytelling artist?CoRR, abs/2602.20664, 2026. 1
-
[46]
Multi-modal proxy learning towards personalized visual multiple clustering
Jiawei Yao, Qi Qian, and Juhua Hu. Multi-modal proxy learning towards personalized visual multiple clustering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 14066–14075. IEEE, 2024. 3
2024
-
[47]
Deciphering ’what’ and ’where’ visual pathways from spectral clustering of layer- distributed neural representations
Xiao Zhang and David Yunis. Deciphering ’what’ and ’where’ visual pathways from spectral clustering of layer- distributed neural representations. InCVPR, pages 4165–
-
[48]
Video supervised for 3d reconstruction from single image.Multim
Yijie Zhong, Zhengxing Sun, Shoutong Luo, Yunhan Sun, and Yi Wang. Video supervised for 3d reconstruction from single image.Multim. Tools Appl., 81(11):15061–15083,
-
[49]
3 Hierarchical Textual Knowledge for Enhanced Image Clustering Supplementary Material
-
[50]
It is organized as follows: • section 7 lists all notations and their meanings
Content List We provide additional details and results to complement the main paper. It is organized as follows: • section 7 lists all notations and their meanings. • section 8 provides the details of 20 datasets used. • section 9 describes implementation details of all the com- pared methods and the proposed method KEC. • section 10 presents complete res...
-
[51]
We hope this could assist readers in better understanding the items presented in our work
Symbol Definitions We list the symbols used throughout this paper along with their meanings in Table 3. We hope this could assist readers in better understanding the items presented in our work
-
[52]
Details of each dataset are provided in Table 4
More Details of the Datasets We evaluate our knowledge-enhanced clustering method on 20 vision datasets. Details of each dataset are provided in Table 4. These datasets cover a wide range of vision tasks, including: • General object classification datasets: CIFAR-10 [19], CIFAR-100 [19], STL-10 [8], ImageNet [9]; • Fine-grained object classification datas...
2000
-
[53]
Implementation of the Compared Methods K-Means and other traditional clustering methods
More Implementation Details 9.1. Implementation of the Compared Methods K-Means and other traditional clustering methods. We apply k-means clustering [27] on top of pre-trained features as a simple baseline that only uses knowledge from visual space. Following the previous work [22], we implement traditional clustering methods, such as k- means, using the...
2024
-
[54]
a bad photo of the [class]
-
[55]
a photo of the large [class]
-
[56]
a [class] in a video game
-
[57]
for each newly added dataset and overwrite the getitem method accordingly
a photo of the small [class]. for each newly added dataset and overwrite the getitem method accordingly. Text-Aided Image Clustering.TAC [22] also proposes leveraging external knowledge in the textual space. Un- like SIC, TAC computes the text features of each image us- ing noun features, without assigning explicit pseudo-labels. We utilize the open-sourc...
2024
-
[58]
CLIP (k-means) and TURTLE (1-space) utilize only visual space knowledge, while zero-shot CLIP incorporates ground-truth label knowledge from the textual space
Main Results Across All Datasets We present the complete numerical results in Table 6. CLIP (k-means) and TURTLE (1-space) utilize only visual space knowledge, while zero-shot CLIP incorporates ground-truth label knowledge from the textual space. SIC, TAC (no train), and KEC utilize textual space knowledge differently. Additionally, we apply two training ...
-
[59]
For higher-level or subjective categories, the improve- ments are less pronounced compared to other datasets. This suggests that such tasks may require a certain degree of human-machine collaboration to better construct effective textual knowledge (which will be further discussed in the Limitations and Future Work section)
-
[60]
In contrast, without additional constraints, KEC adopts a more general perspective to interpret these categories, demonstrating strong generalization capability
For some fine-grained datasets, such as Aircraft and Cars, which focus on specific domains, CLIP (zero-shot) bene- fits from directly using ground-truth fine-grained labels, en- abling it to effortlessly focus on subtle category differences. In contrast, without additional constraints, KEC adopts a more general perspective to interpret these categories, d...
-
[61]
Results of ablation studies across all datasets We present the results of ablation experiments for the pro- posed method across each dataset in Table 7
More Ablation Studies 11.1. Results of ablation studies across all datasets We present the results of ablation experiments for the pro- posed method across each dataset in Table 7. We gradually introduce different levels of knowledge and their compo- nents using the LLMs. 11.2. Further analysis on parameter selections Parameters in Image-Text Mapping.Duri...
-
[62]
Waxy texture
Constructed Knowledge Space 12.1. Reducing Redundancy Compared to TAC. To better understand the effectiveness and efficiency of hier- archical knowledge construction, we compare the size of the knowledge space produced by TAC and our method (KEC) across 20 datasets. As shown in Figure 5, KEC signifi- cantly reduces the number of textual elements in the co...
-
[63]
However, in rare cases, such as CIFAR-100, only 38 concepts are formed
Limitation and Future Work While our proposed KEC achieves strong and consistent performance across diverse datasets and clustering set- tings, we highlight several limitations that also point toward promising future extensions: Concept quantity may not always be larger than the tar- get cluster number.In most cases, the number of con- cepts generated by ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.