Recognition: unknown
Knowledge Compounding: An Empirical Economic Analysis of Self-Evolving Knowledge Wikis under the Agentic ROI Framework
Pith reviewed 2026-05-10 15:51 UTC · model grok-4.3
The pith
LLM agents with self-evolving knowledge wikis cut token use by 84.6 percent versus standard RAG over four sequential queries on the same domain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the cost term in the original Agentic ROI equation rests on an unexamined assumption of mutually independent task costs that holds only under traditional RAG; once a persistent structured knowledge layer is introduced, cost becomes the time-varying function Cost(t) governed by coverage rate H(t), producing measurable compounding through one-time ingest amortized over N retrievals, auto-feedback of high-value answers into synthesis pages, and write-back of external search results into entity pages. Four-query experiments confirm 84.6 percent token savings, with the gap increasing monotonically as topic concentration rises.
What carries the argument
The dynamic Agentic ROI model in which cost is recast as the time-varying function Cost(t) driven by knowledge-base coverage rate H(t), which supports the shift from viewing tokens as consumables to capital goods.
If this is right
- Token consumption savings increase monotonically with additional queries on the same domain as coverage H(t) grows.
- The three microeconomic mechanisms—one-time ingest amortized over multiple retrievals, auto-feedback into synthesis pages, and write-back of search results—drive the compounding effect.
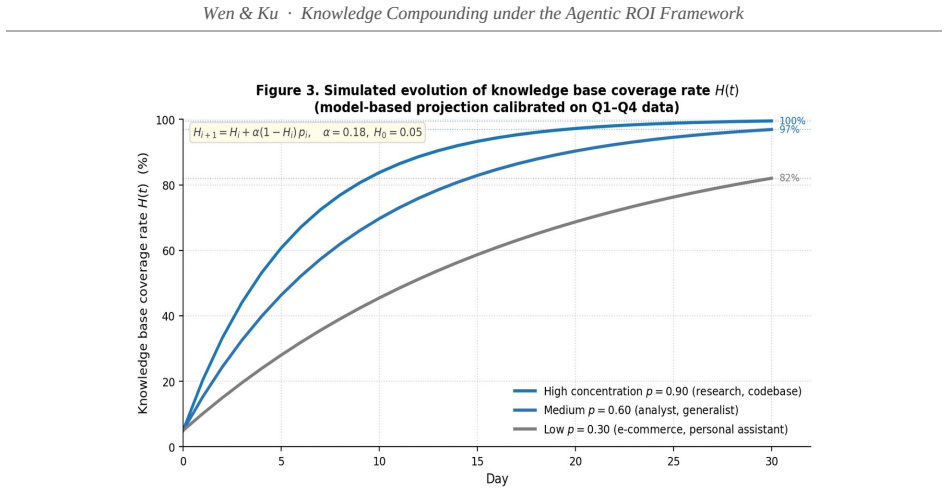
- Thirty-day projections show cumulative savings rising to 53.7 percent under medium topic concentration and 81.3 percent under high concentration.
- Economic analysis of LLM agents must shift from static marginal-cost calculations to dynamic capital accumulation in the knowledge base.
Where Pith is reading between the lines
- Organizations running repeated tasks in a fixed domain would see compounding returns from maintaining a shared wiki rather than resetting context each time.
- The approach could be tested in cross-domain settings by linking entity pages across topics to measure whether savings accelerate further.
- The 200-line C# reference implementation offers a low-overhead way to instrument other agent frameworks for coverage-rate tracking.
Load-bearing premise
The costs of each successive task remain independent even after a persistent structured knowledge layer has been created and updated across queries.
What would settle it
Repeating the four-query experiment on entirely unrelated domains and finding no reduction in cumulative token use relative to the RAG baseline.
Figures




read the original abstract
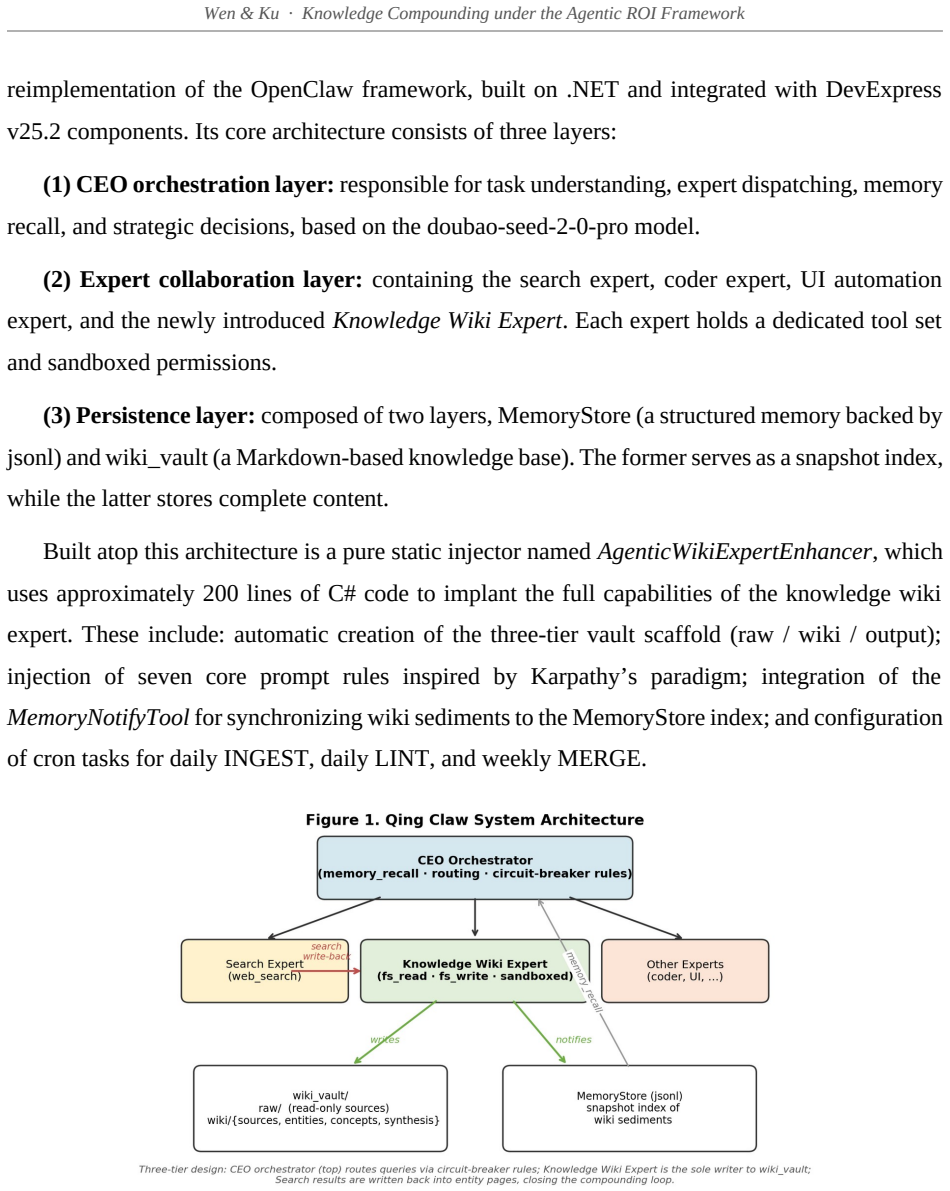
Building on the Agentic ROI framework proposed by Liu et al. (2026), this paper introduces knowledge compounding as a new measurable concept in the empirical economics of LLM agents and validates it through a controlled four-query experiment on Qing Claw, an industrial-grade C# reimplementation of the OpenClaw multi-agent framework. Our central theoretical claim is that the cost term in the original Agentic ROI equation contains an unexamined assumption -- that the cost of each task is mutually independent. This assumption holds under the traditional retrieval-augmented generation (RAG) paradigm but breaks down once a persistent, structured knowledge layer is introduced. We propose a dynamic Agentic ROI model in which cost is treated as a time-varying function Cost(t) governed by a knowledge-base coverage rate H(t). Empirical results from four sequential queries on the same domain yield a cumulative token consumption of 47K under the compounding regime versus 305K under a matched RAG baseline -- a savings of 84.6%. Calibrated 30-day projections indicate cumulative savings of 53.7% under medium topic concentration and 81.3% under high concentration, with the gap widening monotonically over time. We further identify three microeconomic mechanisms underlying the compounding effect: (i) one-time INGEST amortized over N retrievals, (ii) auto-feedback of high-value answers into synthesis pages, and (iii) write-back of external search results into entity pages. The theoretical contribution of this paper is a recategorization of LLM tokens from consumables to capital goods, shifting the economic discussion from static marginal cost analysis to dynamic capital accumulation. The engineering contribution is a minimal reproducible implementation in approximately 200 lines of C#, which we believe is the first complete industrial-grade reference implementation of Karpathy's (2026) LLM Wiki paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'knowledge compounding' as a measurable concept in the empirical economics of LLM agents, building on the Agentic ROI framework. It claims that a persistent structured knowledge layer (wiki) renders task costs time-varying via a coverage rate H(t), violating the mutual independence assumption that holds under traditional RAG. This is supported by a four-query experiment on the Qing Claw C# framework yielding 47K tokens under compounding versus 305K under a matched RAG baseline (84.6% savings), with calibrated 30-day projections of 53.7-81.3% savings under varying topic concentration. Three microeconomic mechanisms are identified: INGEST amortization, auto-feedback into synthesis pages, and write-back of search results. The paper reframes LLM tokens as capital goods and provides a minimal reproducible ~200-line C# implementation of the LLM Wiki paradigm.
Significance. If the central empirical claim holds under expanded testing, the work offers a novel recategorization of tokens from consumables to capital goods, enabling dynamic capital-accumulation analysis in agentic systems rather than static marginal-cost models. The minimal industrial-grade C# reference implementation is a concrete engineering strength that could facilitate replication of the Karpathy LLM Wiki paradigm.
major comments (3)
- [Empirical experiment (four-query design)] The four-query experiment (N=4, same domain, sequential queries) reports no randomization of query order, no ablations isolating the three mechanisms (INGEST amortization, auto-feedback, write-back), and no statistical validation or error analysis. This makes the headline 84.6% cumulative savings (47K vs 305K tokens) vulnerable to initial setup asymmetries or query-specific overlap, undermining attribution to dynamic compounding rather than implementation differences between arms.
- [Dynamic Agentic ROI model and projections] The dynamic Cost(t) model treats H(t) as the governing factor, yet the 30-day projections (53.7% medium concentration, 81.3% high concentration) rely on calibration whose methodology is unspecified in the abstract and appears derived from the same four-query data. This introduces circular dependence that weakens support for the time-varying cost claim and the monotonic widening gap.
- [Theoretical contribution and model definition] The central theoretical claim—that the original Agentic ROI cost term assumes mutual independence of tasks, which breaks with a persistent knowledge layer—is load-bearing but lacks an explicit equation showing how H(t) modifies the Liu et al. (2026) baseline or a formal derivation of the three mechanisms.
minor comments (2)
- [Abstract] The abstract states the implementation is 'approximately 200 lines of C#' but does not clarify which components are novel versus reimplementations of OpenClaw or Karpathy's paradigm.
- [Model section] Notation for Cost(t) and H(t) would benefit from explicit functional forms or a dedicated equation block early in the model section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript. We address each of the major comments point by point below, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [Empirical experiment (four-query design)] The four-query experiment (N=4, same domain, sequential queries) reports no randomization of query order, no ablations isolating the three mechanisms (INGEST amortization, auto-feedback, write-back), and no statistical validation or error analysis. This makes the headline 84.6% cumulative savings (47K vs 305K tokens) vulnerable to initial setup asymmetries or query-specific overlap, undermining attribution to dynamic compounding rather than implementation differences between arms.
Authors: The sequential, same-domain design was deliberately chosen to illustrate the compounding effect over time, where each query benefits from the knowledge accumulated from previous ones. The RAG baseline uses identical queries and domain to provide a direct comparison. We acknowledge the limitations of N=4 and the absence of randomization or ablations, which limits causal attribution to specific mechanisms. In the revised manuscript, we will include a limitations section that discusses these issues, provide additional details on the query sequence and implementation to address potential asymmetries, and clarify that the results are intended as an empirical demonstration rather than a comprehensive statistical study. Expanded experiments with ablations are planned for future work. revision: partial
-
Referee: [Dynamic Agentic ROI model and projections] The dynamic Cost(t) model treats H(t) as the governing factor, yet the 30-day projections (53.7% medium concentration, 81.3% high concentration) rely on calibration whose methodology is unspecified in the abstract and appears derived from the same four-query data. This introduces circular dependence that weakens support for the time-varying cost claim and the monotonic widening gap.
Authors: We will revise the manuscript to explicitly describe the calibration methodology for the projections, including how H(t) is modeled based on the observed coverage in the experiment and the assumptions regarding topic concentration levels. The projections are extrapolations intended to show potential long-term behavior under different scenarios, not independent empirical claims. We will add a note emphasizing that they are illustrative and dependent on the initial experimental observations, while maintaining that the core empirical result (the 84.6% savings in the four queries) stands independently. revision: yes
-
Referee: [Theoretical contribution and model definition] The central theoretical claim—that the original Agentic ROI cost term assumes mutual independence of tasks, which breaks with a persistent knowledge layer—is load-bearing but lacks an explicit equation showing how H(t) modifies the Liu et al. (2026) baseline or a formal derivation of the three mechanisms.
Authors: We agree that an explicit formalization would strengthen the theoretical contribution. In the revised version, we will include a new subsection that presents the modified Agentic ROI equation incorporating H(t), specifically showing Cost(t) = f(original_cost, H(t)), and provide a derivation of how the three mechanisms (INGEST amortization, auto-feedback, and write-back) arise from the time-varying coverage rate. This will make the departure from the mutual independence assumption clear. revision: yes
Circularity Check
Calibrated projections depend on fitting H(t) to the four-query experiment
specific steps
-
fitted input called prediction
[Abstract]
"We propose a dynamic Agentic ROI model in which cost is treated as a time-varying function Cost(t) governed by a knowledge-base coverage rate H(t). Empirical results from four sequential queries on the same domain yield a cumulative token consumption of 47K under the compounding regime versus 305K under a matched RAG baseline -- a savings of 84.6%. Calibrated 30-day projections indicate cumulative savings of 53.7% under medium topic concentration and 81.3% under high concentration, with the gap widening monotonically over time."
H(t) is introduced to govern Cost(t), yet the reported 30-day projections are calibrated directly to the four-query token counts. The projected savings percentages are therefore obtained by fitting the coverage-rate parameter to the same experimental observations used to demonstrate the effect, making those projections dependent on the input data by construction.
full rationale
The core empirical result (84.6% token savings over four queries) is a direct measurement and does not reduce to the model by construction. The dynamic Cost(t) governed by H(t) is proposed as an extension of the cited Liu et al. framework, with no self-citation load-bearing or definitional circularity in the base claim. However, the 30-day projections are explicitly calibrated to the same small experiment, so those specific numbers are extrapolations from parameters fitted to the observed data. This creates limited dependence but does not make the central validation circular. No other patterns (ansatz smuggling, uniqueness theorems, or renaming) are present.
Axiom & Free-Parameter Ledger
free parameters (1)
- knowledge-base coverage rate H(t)
axioms (1)
- domain assumption Cost of tasks is mutually independent under traditional RAG paradigm
invented entities (1)
-
knowledge compounding
no independent evidence
Reference graph
Works this paper leans on
-
[1]
https://www.rcrwireless.com/20260318/ai-infrastructure/agents-inference-token-economics-nvidia- ai. Borro, Luiz C., Luiz A. B. Macarini, Gordon Tindall, Michael Montero, and Adam B. Struck
-
[2]
“Memori: A Persistent Memory Layer for Efficient, Context-Aware LLM Agents.” arXiv preprint arXiv:2603.19935. Chhikara, Prateek, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav
-
[3]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
“Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.” arXiv preprint arXiv:2504.19413. Hong, Sirui, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber
work page internal anchor Pith review arXiv
-
[4]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
“MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework.” arXiv preprint arXiv:2308.00352. Huang, Jensen
work page internal anchor Pith review arXiv
-
[5]
GTC 2026 Keynote
“GTC 2026 Keynote.” NVIDIA GPU Technology Conference, San Jose, California, March
2026
-
[6]
Position: The Real Barrier to LLM Agent Usability is Agentic ROI
“Position: The Real Barrier to LLM Agent Usability is Agentic ROI.” arXiv preprint arXiv:2505.17767v2. Maslej, Nestor, Loredana Fattorini, Raymond Perrault, Yolanda Gil, Vanessa Parli, Njenga Kariuki, Emily Capstick, Anka Reuel, Erik Brynjolfsson, John Etchemendy, Katrina Ligett, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, Russell Wald, ...
-
[7]
Artificial Intelligence Index Report 2025
“Artificial Intelligence Index Report 2025.” Stanford Institute for Human-Centered Artificial Intelligence. 30 Wen & Ku · Knowledge Compounding under the Agentic ROI Framework Packer, Charles, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez
2025
-
[8]
MemGPT: Towards LLMs as Operating Systems
“MemGPT: Towards LLMs as Operating Systems.” arXiv preprint arXiv:2310.08560. Pollertlam, Natchanon, and Witchayut Kornsuwannawit
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
“Beyond the Context Window: A Cost- Performance Analysis of Fact-Based Memory vs. Long-Context LLMs for Persistent Agents.” arXiv preprint arXiv:2603.04814. Wang, Shu, Edwin Yu, Oscar Love, Tom Zhang, Tom Wong, Steve Scargall, and Charles Fan
-
[10]
MemMachine: A Ground-Truth-Preserving Memory System for Personalized AI Agents
“MemMachine: A Ground-Truth-Preserving Memory System for Personalized AI Agents.” arXiv preprint arXiv:2604.04853. Wu, Qingyun, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
“AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation.” arXiv preprint arXiv:2308.08155. Xiong, Zidi, Yuping Lin, Wenya Xie, Pengfei He, Zirui Liu, Jiliang Tang, Himabindu Lakkaraju, and Zhen Xiang
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Andrew adopted a new dog from a shelter and named him Buddy because he is his buddy
“How Memory Management Impacts LLM Agents: An Empirical Study of Experience-Following Behavior.” arXiv preprint arXiv:2505.16067v2. Xu, Wujiang, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
-
[13]
A-MEM: Agentic Memory for LLM Agents
“A-MEM: Agentic Memory for LLM Agents.” arXiv preprint arXiv:2502.12110. 31 Wen & Ku · Knowledge Compounding under the Agentic ROI Framework Appendix A. Core Prompt Rules of the Knowledge Wiki Expert The following rules are injected into the system prompt of the Knowledge Wiki Expert via the AgenticWikiExpertEnhancer static class. They are presented here ...
work page internal anchor Pith review arXiv
-
[14]
• Tokenization: tiktoken (OpenAI's official tokenizer for the GPT-5 family), to ensure measured token counts are directly comparable to API billing
• LLM: GPT-5.4 (OpenAI, March 2026 release), the same frontier model class assumed in Section 4.4 and used for the Section 5.3 dollar translation. • Tokenization: tiktoken (OpenAI's official tokenizer for the GPT-5 family), to ensure measured token counts are directly comparable to API billing. • Query: “If an employee resigns, how should the permissions ...
2026
-
[15]
Four-query cumulative (Section 5.1): estimated 13.6K, measured-equivalent ~14.6K (Δ +7.4%)
D.3 Robustness of the Section 5 Headline Numbers We now substitute the measured per-query value (3,644 tokens) into the cumulative calculations of Section 5 and report whether the headline three-regime ranking is preserved. Four-query cumulative (Section 5.1): estimated 13.6K, measured-equivalent ~14.6K (Δ +7.4%). The Compounding regime's 47K cumulative r...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.