Recognition: unknown
Retrieval as Generation: A Unified Framework with Self-Triggered Information Planning
Pith reviewed 2026-05-10 15:17 UTC · model grok-4.3
The pith
Retrieval control can be folded directly into a model's token generation so one autoregressive process handles both evidence gathering and answer synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRIP expresses retrieval decisions inside ordinary autoregressive decoding by means of control-token emission. Self-Triggered Information Planning lets the model decide retrieval timing, query reformulation, and termination within a single generation sequence. The approach is supervised by a training set that aligns specific token patterns with answerable, partially answerable, and multi-hop queries, thereby coupling retrieval and reasoning without external modules.
What carries the argument
Self-Triggered Information Planning: the mechanism that lets the model emit control tokens to decide, inside one autoregressive trajectory, when to retrieve, how to reformulate the query, and when to terminate.
If this is right
- Retrieval and generation become a single coordinated process without separate controllers or classifiers.
- The model can perform dynamic multi-step inference by integrating new evidence as soon as it is retrieved.
- Smaller models become competitive on complex QA tasks that normally require much larger systems.
- End-to-end training becomes possible because the same loss signal supervises both reasoning and retrieval decisions.
Where Pith is reading between the lines
- The control-token approach could be tested on tasks outside question answering, such as iterative code completion or scientific hypothesis refinement.
- Removing the external retrieval module might reduce overall system latency and simplify deployment pipelines.
- One could measure whether the learned control tokens produce consistent retrieval policies across different base language models.
Load-bearing premise
The specially constructed training set with fixed token patterns for different query types will teach generalizable retrieval behavior rather than causing the model to overfit to those patterns.
What would settle it
Evaluate the trained model on a fresh collection of queries whose types and required retrieval patterns do not match the answerable, partially answerable, or multi-hop categories used during training and measure whether retrieval timing and reformulation remain effective.
Figures










read the original abstract
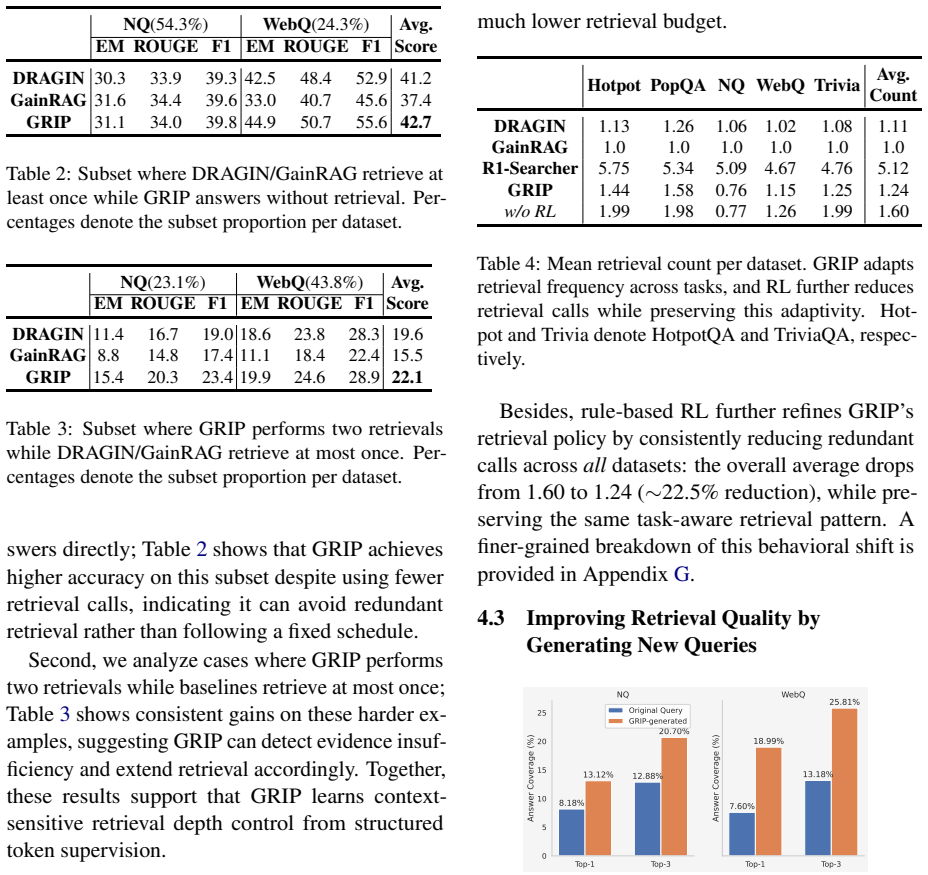
We revisit retrieval-augmented generation (RAG) by embedding retrieval control directly into generation. Instead of treating retrieval as an external intervention, we express retrieval decisions within token-level decoding, enabling end-to-end coordination without additional controllers or classifiers. Under the paradigm of Retrieval as Generation, we propose \textbf{GRIP} (\textbf{G}eneration-guided \textbf{R}etrieval with \textbf{I}nformation \textbf{P}lanning), a unified framework in which the model regulates retrieval behavior through control-token emission. Central to GRIP is \textit{Self-Triggered Information Planning}, which allows the model to decide when to retrieve, how to reformulate queries, and when to terminate, all within a single autoregressive trajectory. This design tightly couples retrieval and reasoning and supports dynamic multi-step inference with on-the-fly evidence integration. To supervise these behaviors, we construct a structured training set covering answerable, partially answerable, and multi-hop queries, each aligned with specific token patterns. Experiments on five QA benchmarks show that GRIP surpasses strong RAG baselines and is competitive with GPT-4o while using substantially fewer parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GRIP, a unified Retrieval-as-Generation framework that embeds retrieval decisions, query reformulation, and termination directly into a single autoregressive generation pass via control-token emission under Self-Triggered Information Planning. A structured training set is constructed to align answerable, partially answerable, and multi-hop queries with specific token patterns; experiments on five QA benchmarks are reported to show GRIP outperforming strong RAG baselines while remaining competitive with GPT-4o at substantially lower parameter count.
Significance. If the empirical gains are robust, the work offers a conceptually clean alternative to modular RAG pipelines by eliminating separate retrievers or controllers and enabling dynamic, on-the-fly evidence integration within one model trajectory. The explicit supervision of planning behaviors via token patterns is a concrete contribution that could be extended to other agentic or multi-step reasoning settings.
major comments (2)
- [Experiments / Training Data Construction] The central empirical claim (surpassing RAG baselines on five QA benchmarks) rests on the assumption that the model acquires generalizable retrieval planning rather than memorizing the constructed token-pattern alignments in the training set. No ablation is described that randomizes or removes these explicit patterns, tests out-of-distribution query types, or measures sensitivity to the supervision format; without such controls the performance advantage could be an artifact of the training distribution rather than evidence of end-to-end coordination.
- [Abstract / Experiments] The abstract states that GRIP is 'competitive with GPT-4o while using substantially fewer parameters,' yet no quantitative metrics, baseline details, error analysis, or ablation tables are supplied in the provided summary. The load-bearing comparison therefore cannot be verified from the given information.
minor comments (2)
- [Method] Notation for control tokens and the exact decoding procedure for emitting retrieval actions should be formalized with an equation or pseudocode in the method section to make the 'single autoregressive trajectory' claim precise.
- [Experiments] The five QA benchmarks are not named; listing them and reporting per-benchmark scores (including variance across runs) would strengthen the results section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments / Training Data Construction] The central empirical claim (surpassing RAG baselines on five QA benchmarks) rests on the assumption that the model acquires generalizable retrieval planning rather than memorizing the constructed token-pattern alignments in the training set. No ablation is described that randomizes or removes these explicit patterns, tests out-of-distribution query types, or measures sensitivity to the supervision format; without such controls the performance advantage could be an artifact of the training distribution rather than evidence of end-to-end coordination.
Authors: We agree that explicit controls are needed to rule out memorization of token patterns. While the five QA benchmarks already span varied query complexities, we did not report an ablation randomizing or ablating the supervision format. In the revision we will add this ablation (training with randomized control tokens) together with additional out-of-distribution query evaluations to demonstrate that performance gains derive from learned self-triggered planning. revision: yes
-
Referee: [Abstract / Experiments] The abstract states that GRIP is 'competitive with GPT-4o while using substantially fewer parameters,' yet no quantitative metrics, baseline details, error analysis, or ablation tables are supplied in the provided summary. The load-bearing comparison therefore cannot be verified from the given information.
Authors: The full manuscript supplies the requested details: quantitative metrics and parameter counts appear in Section 4 and Table 2, baseline descriptions in Section 4.1, error analysis in Appendix C, and ablation tables in Section 4.3. The abstract is intentionally concise; we will insert explicit cross-references to these tables and sections to improve verifiability. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's contribution is an empirical supervised learning framework (GRIP) that embeds retrieval decisions into autoregressive token generation via control tokens, trained on an explicitly constructed dataset with aligned patterns for query types and evaluated on separate QA benchmarks. No equations, self-citations, or parameter-fitting steps are presented that reduce any claimed result to its inputs by construction. The training data construction is overt supervision rather than a hidden self-referential loop, and performance claims rest on external benchmark comparisons rather than renaming or re-deriving fitted quantities.
Axiom & Free-Parameter Ledger
free parameters (1)
- Control token patterns
axioms (1)
- domain assumption Autoregressive token generation can incorporate control signals for external retrieval actions without breaking coherence
invented entities (1)
-
Self-Triggered Information Planning
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Beyond Semantic Relevance: Counterfactual Risk Minimization for Robust Retrieval-Augmented Generation
CoRM-RAG uses a cognitive perturbation protocol to simulate biases and trains an Evidence Critic to retrieve documents that support correct decisions even under adversarial query changes.
-
Chain of Evidence: Pixel-Level Visual Attribution for Iterative Retrieval-Augmented Generation
CoE applies vision-language models directly to document screenshots to deliver pixel-level bounding-box attribution for evidence in iterative retrieval-augmented generation, outperforming text baselines on visual-layo...
Reference graph
Works this paper leans on
-
[1]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Karl Moritz Hermann, Tomas Kocisky, Edward Grefen- stette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. 2015. Teaching machines to read and comprehend.Advances in neural information processing systems, 28. Xanh Ho, A. Nguyen, Saku Sugawara, and Akiko Aiz...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[2]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
When not to trust language models: Investigat- ing effectiveness of parametric and non-parametric memories. InAnnual Meeting of the Association for Computational Linguistics. Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-context retrieval-augmented lan- guage models.Transactions of the Ass...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
R2ag: Incorporating retrieval information into retrieval augmented generation. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 11584–11596. Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Be- rant. Making retrieval-augmented language models robust to irrelevant context. InICLR 2024 Workshop on Large Language Model (LLM) Agen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
– If initial_intermediary was incorrect or incomplete, discard or correct it
Re-summarize the intermediary fact that is most useful for answering the question, by combining the question, the retrieved documents, and initial_intermediary. – If initial_intermediary was incorrect or incomplete, discard or correct it. – Verify whether any retrieved document contains incorrect or misleading information based on your own knowledge, and ...
-
[5]
Based on that finalized intermediary fact, plus the question and retrieved documents, generate a new search query that is highly likely to return evidence needed for the full answer. Output: Produce exactly one line in the following format, with no extra text: [Intermediary] <your refined known fact> [RETRIEVE] <your new query> --- Question: {question} Re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.