Recognition: unknown
Low-rank Optimization Trajectories Modeling for LLM RLVR Acceleration
Pith reviewed 2026-05-10 16:02 UTC · model grok-4.3
The pith
Extracting the rank-1 subspace of early LoRA updates and modeling its nonlinear trajectory allows skipping many RLVR training steps for LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The rank-1 subspace of parameter differences does not evolve linearly during RLVR and grows more dominant under LoRA; modeling its trajectory with a nonlinear predictor trained on early steps permits reliable forward extrapolation of the full model parameters, which accelerates RLVR by reducing the number of required training iterations.
What carries the argument
Nonlinear predictor trained on the rank-1 subspace of LoRA parameter differences extracted at multiple early training steps.
If this is right
- RLVR training runs can reach equivalent final performance with approximately 37.5 percent less compute.
- The acceleration works with a range of RLVR algorithms and across different tasks.
- The rank-1 component becomes increasingly dominant over the course of LoRA training, which justifies focusing extrapolation on that subspace.
- Parameter updates can be predicted and extended without retraining the full model at every step.
Where Pith is reading between the lines
- If the nonlinear low-rank trajectory is stable, the same extraction-and-prediction pattern could be tested on other optimization methods that use low-rank adapters.
- The approach might combine with existing step-skipping or early-stopping heuristics to produce still larger savings.
- Scaling the method to larger base models would test whether the rank-1 dominance pattern continues to hold.
- An analytic form for the nonlinear predictor, if discovered, could remove the need to train a separate model for extrapolation.
Load-bearing premise
The rank-1 subspace observed in the first few LoRA steps can be captured accurately by a nonlinear predictor and extrapolated forward without instability or loss of final model performance.
What would settle it
Compare the final reward or capability scores of a model trained with full RLVR steps against one using NExt extrapolation on identical tasks and seeds; equal or better scores with the extrapolated version would support the claim.
Figures

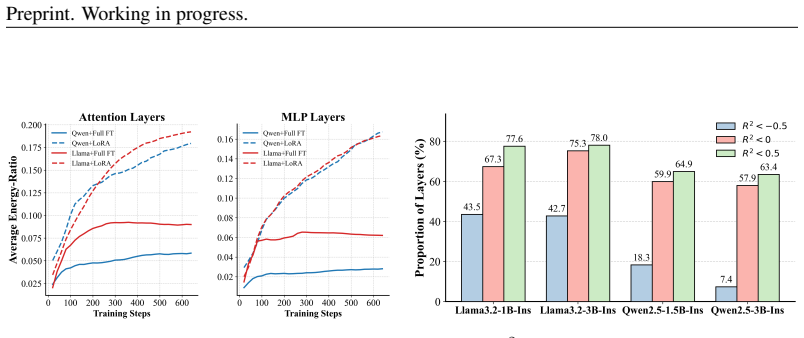
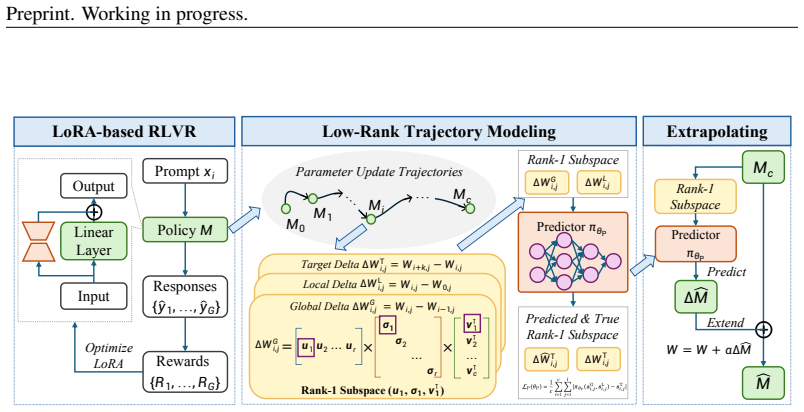



read the original abstract
Recently, scaling reinforcement learning with verifiable rewards (RLVR) for large language models (LLMs) has emerged as an effective training paradigm for significantly improving model capabilities, which requires guiding the model to perform extensive exploration and learning, leading to substantial computational overhead and becoming a key challenge. To reduce the number of training steps, Prior work performs linear extrapolation of model parameters. However, the dynamics of model parameter updates during RLVR training remain insufficiently understood. To further investigate the evolution of LLMs during RLVR training, we conduct empirical experiments and find that the rank-1 subspace of the model does not evolve linearly, and its dominance over the original parameters is further amplified during LoRA training. Based on the above insights, we propose the \textbf{N}onlinear \textbf{Ext}rapolation of low-rank trajectories (\textbf{NExt}), a novel framework that models and extrapolates low-rank parameter trajectories in a nonlinear manner. Concretely, we first train the model using LoRA and extract the rank-1 subspace of parameter differences at multiple training steps, which is then used for the subsequent nonlinear extrapolation. Afterward, we utilized the extracted rank-1 subspace to train a predictor, which can model the trajectory of parameter updates during RLVR, and then perform the predict-extend process to extrapolate model parameters, achieving the acceleration of RLVR. To further study and understand NExt, we conduct comprehensive experiments that demonstrate the effectiveness and robustness of the method. Our method reduces computational overhead by approximately 37.5\% while remaining compatible with a wide range of RLVR algorithms and tasks. We release our code in https://github.com/RUCAIBox/NExt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RLVR training dynamics for LLMs exhibit nonlinear evolution in the dominant rank-1 subspace of LoRA parameter differences, which can be modeled by training a predictor on early-step subspaces and then extrapolated forward via a predict-extend process. This NExt framework is reported to accelerate training by approximately 37.5% computational overhead reduction while preserving final model performance and remaining compatible with diverse RLVR algorithms and tasks; code is released.
Significance. If validated, the result would address a central bottleneck in scaling RLVR for LLMs by reducing training steps without performance loss. The empirical observation that rank-1 subspaces become more dominant and evolve nonlinearly during LoRA-based RLVR provides a useful insight into optimization trajectories. Releasing code is a positive contribution to reproducibility.
major comments (3)
- [Experiments] Experiments section: the 37.5% overhead reduction claim is central but lacks reported metrics quantifying extrapolation fidelity, such as cosine similarity or alignment between predicted and actual rank-1 subspaces at later training steps. Without these, it is difficult to confirm that the nonlinear predictor avoids divergence or suboptimal convergence in the reward-guided RLVR setting.
- [Method (§3)] Method (§3): the predictor is trained on rank-1 subspaces extracted from the same run's early LoRA steps and then used for forward extrapolation; additional analysis is required to show that this does not overfit to initial dynamics or introduce instability, given that RLVR involves dynamic exploration that may deviate from early nonlinear patterns.
- [Ablations] Ablations: no ablation is presented on the nonlinear predictor architecture, hyperparameters, or choice of rank-1 extraction, making it unclear whether reported gains are attributable to nonlinearity versus other aspects of the framework or baseline comparisons.
minor comments (2)
- [Abstract] Abstract: the claim of compatibility with a 'wide range' of RLVR algorithms would be strengthened by explicitly listing the specific algorithms and tasks evaluated in the experiments.
- [§3] Notation in §3: the precise mathematical definition of the rank-1 subspace extraction (e.g., via SVD on parameter differences) should be formalized with an equation for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of NExt to address computational bottlenecks in RLVR for LLMs. We address each major comment point by point below, with plans for revisions that strengthen the empirical support without altering the core claims.
read point-by-point responses
-
Referee: Experiments section: the 37.5% overhead reduction claim is central but lacks reported metrics quantifying extrapolation fidelity, such as cosine similarity or alignment between predicted and actual rank-1 subspaces at later training steps. Without these, it is difficult to confirm that the nonlinear predictor avoids divergence or suboptimal convergence in the reward-guided RLVR setting.
Authors: We agree that direct fidelity metrics would provide clearer validation of the extrapolation process. While the manuscript already demonstrates that final model performance is preserved across tasks (indicating no catastrophic divergence), we will add cosine similarity, Frobenius norm differences, and subspace alignment metrics between predicted and ground-truth rank-1 subspaces at multiple extrapolation horizons in the revised Experiments section. These will be reported alongside the existing overhead and performance results to explicitly address concerns about stability in the RLVR setting. revision: yes
-
Referee: Method (§3): the predictor is trained on rank-1 subspaces extracted from the same run's early LoRA steps and then used for forward extrapolation; additional analysis is required to show that this does not overfit to initial dynamics or introduce instability, given that RLVR involves dynamic exploration that may deviate from early nonlinear patterns.
Authors: We acknowledge the need for explicit checks against overfitting to early dynamics. The current experiments already show consistent gains across diverse RLVR algorithms and tasks, suggesting the learned nonlinear patterns generalize beyond the initial steps. In the revision, we will expand §3 with additional analysis: (i) predictor performance on held-out intermediate steps within the same run, and (ii) sensitivity tests under varying exploration intensities. This will demonstrate that the predict-extend process remains stable despite RLVR's dynamic nature. revision: yes
-
Referee: Ablations: no ablation is presented on the nonlinear predictor architecture, hyperparameters, or choice of rank-1 extraction, making it unclear whether reported gains are attributable to nonlinearity versus other aspects of the framework or baseline comparisons.
Authors: We agree that targeted ablations would better isolate the contribution of nonlinearity. In the revised manuscript, we will add an Ablations subsection that includes: comparisons of linear vs. nonlinear predictors, variations in predictor depth/width and training horizon, and alternative rank-1 extraction thresholds. These will be evaluated on the same benchmarks to confirm that the acceleration stems primarily from the nonlinear modeling of low-rank trajectories. revision: yes
Circularity Check
No significant circularity in NExt derivation or claims
full rationale
The paper extracts rank-1 subspaces from early LoRA steps in the same RLVR run, fits a nonlinear predictor to those subspaces, and extrapolates forward to skip later steps. This is standard time-series modeling and extrapolation rather than a self-definitional or fitted-input-called-prediction loop; the predictor is not tautologically restating its training data, and the headline 37.5% overhead reduction is presented as an empirical outcome validated by experiments across algorithms and tasks. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to force the result. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- nonlinear predictor parameters
axioms (1)
- domain assumption Rank-1 subspace of parameter differences dominates and can be extrapolated nonlinearly from early LoRA steps
Reference graph
Works this paper leans on
-
[1]
Back to basics: Revisiting reinforce-style optimization for learn- ing from human feedback in llms
Arash Ahmadian, Chris Cremer, Matthias Gall ´e, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet ¨Ust¨un, and Sara Hooker. Back to basics: Revisiting reinforce-style optimization for learn- ing from human feedback in llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Ba...
2024
-
[2]
Ihab Asaad, Maha Shadaydeh, and Joachim Denzler
URLhttps://huggingface.co/datasets/math-ai/amc23. Ihab Asaad, Maha Shadaydeh, and Joachim Denzler. Gradient extrapolation for debiased represen- tation learning.CoRR, abs/2503.13236,
-
[3]
arXiv preprint arXiv:2510.00553 , year=
Yuchen Cai, Ding Cao, Xin Xu, Zijun Yao, Yuqing Huang, Zhenyu Tan, Benyi Zhang, Guiquan Liu, and Junfeng Fang. On predictability of reinforcement learning dynamics for large language models.arXiv preprint arXiv:2510.00553,
-
[4]
Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles
Jiangjie Chen, Qianyu He, Siyu Yuan, Aili Chen, Zhicheng Cai, Weinan Dai, Hongli Yu, Qiying Yu, Xuefeng Li, Jiaze Chen, Hao Zhou, and Mingxuan Wang. Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles.CoRR, abs/2505.19914, 2025a. Zhipeng Chen, Kun Zhou, Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, and Ji-Rong ...
-
[5]
Bassett, and Sara Hooker
Everlyn Chimoto, Jay Gala, Orevaoghene Ahia, Julia Kreutzer, Bruce A. Bassett, and Sara Hooker. Critical learning periods: Leveraging early training dynamics for efficient data pruning. InFind- ings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, Findings of ACL, pp. 9407–9426. Associa...
2024
-
[6]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 4299–4307,
2017
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. CoRR, abs/2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Jia Deng, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, and Ji-Rong Wen. Decomposing the entropy- performance exchange: The missing keys to unlocking effective reinforcement learning.arXiv preprint arXiv:2508.02260,
-
[9]
Loss functions in deep learning: A comprehensive review.CoRR, abs/2504.04242,
Omar Elharrouss, Yasir Mahmood, Yassine Bechqito, Mohamed Adel Serhani, Elarbi Badidi, Ja- mal Riffi, and Hamid Tairi. Loss functions in deep learning: A comprehensive review.CoRR, abs/2504.04242,
-
[10]
Meta-ensemble parameter learning.CoRR, abs/2210.01973,
Zhengcong Fei, Shuman Tian, Junshi Huang, Xiaoming Wei, and Xiaolin Wei. Meta-ensemble parameter learning.CoRR, abs/2210.01973,
-
[11]
Incremental cost-effectiveness ratios (icers): The silence of the lambda.Social Science & Medicine, 62(9):2091–2100,
Amiram Gafni and Stephen Birch. Incremental cost-effectiveness ratios (icers): The silence of the lambda.Social Science & Medicine, 62(9):2091–2100,
2091
-
[12]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu, Jason Klein Liu, Haotian Xu, and Wei Shen. Reinforce++: Stabilizing critic-free policy optimization with global normalization.CoRR, abs/2501.03262,
work page internal anchor Pith review arXiv
-
[13]
Guanhua Huang, Tingqiang Xu, Mingze Wang, Qi Yi, Xue Gong, Siheng Li, Ruibin Xiong, Kejiao Li, Yuhao Jiang, and Bo Zhou. Low-probability tokens sustain exploration in reinforcement learning with verifiable reward.CoRR, abs/2510.03222,
-
[14]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondrich, Andrey ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Taylor, and Adriana Romero-Soriano
Boris Knyazev, Michal Drozdzal, Graham W. Taylor, and Adriana Romero-Soriano. Parameter pre- diction for unseen deep architectures. InAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pp. 29433–29448,
2021
-
[16]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[17]
Tao Lin, Lingjing Kong, Sebastian U
URLhttps://openreview.net/forum?id=v8L0pN6EOi. Tao Lin, Lingjing Kong, Sebastian U. Stich, and Martin Jaggi. Extrapolation for large-batch training in deep learning. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Proceedings of Machine Learning Research, pp. 6094–6104. PMLR,
2020
-
[18]
Tuning language models by proxy.arXiv preprint arXiv:2401.08565,
Alisa Liu, Xiaochuang Han, Yizhong Wang, Yulia Tsvetkov, Yejin Choi, and Noah A Smith. Tuning language models by proxy.arXiv preprint arXiv:2401.08565,
-
[19]
Working in progress
17 Preprint. Working in progress. Ziche Liu, Rui Ke, Yajiao Liu, Feng Jiang, and Haizhou Li. Take the essence and discard the dross: A rethinking on data selection for fine-tuning large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguis- tics: Human Language Technologie...
2025
-
[20]
Part II: ROLL flash - accelerating RLVR and agentic training with asynchrony.CoRR, abs/2510.11345,
Han Lu, Zichen Liu, Shaopan Xiong, Yancheng He, Wei Gao, Yanan Wu, Weixun Wang, Jiashun Liu, Yang Li, Haizhou Zhao, Ju Huang, Siran Yang, Xiaoyang Li, Yijia Luo, Zihe Liu, Ling Pan, Junchi Yan, Wei Wang, Wenbo Su, Jiamang Wang, Lin Qu, and Bo Zheng. Part II: ROLL flash - accelerating RLVR and agentic training with asynchrony.CoRR, abs/2510.11345,
-
[21]
Simpo: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward. InAdvances in Neural Information Processing Systems 38: Annual Con- ference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024,
2024
-
[22]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural In- formation Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - ...
2023
-
[23]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark.CoRR, abs/2311.12022,
work page internal anchor Pith review arXiv
-
[24]
Yanwei Ren, Haotian Zhang, Likang Xiao, Xikai Zhang, Jiaxing Huang, Jiayan Qiu, Baosheng Yu, Quan Chen, and Liu Liu. Recycling failures: Salvaging exploration in rlvr via fine-grained off-policy guidance.arXiv preprint arXiv:2602.24110,
-
[25]
Early weight averaging meets high learning rates for llm pre-training
Sunny Sanyal, Atula Neerkaje, Jean Kaddour, Abhishek Kumar, and Sujay Sanghavi. Early weight averaging meets high learning rates for llm pre-training.arXiv preprint arXiv:2306.03241,
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.CoRR, abs/1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
Haoxiang Sun, Yingqian Min, Zhipeng Chen, Wayne Xin Zhao, Zheng Liu, Zhongyuan Wang, Lei Fang, and Ji-Rong Wen. Challenging the boundaries of reasoning: An olympiad-level math benchmark for large language models.CoRR, abs/2503.21380,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Rethinking sample polarity in reinforcement learning with verifiable rewards
Xinyu Tang, Yuliang Zhan, Zhixun Li, Wayne Xin Zhao, Zhenduo Zhang, Zujie Wen, Zhiqiang Zhang, and Jun Zhou. Rethinking sample polarity in reinforcement learning with verifiable re- wards.CoRR, abs/2512.21625, 2025a. Xinyu Tang, Zhenduo Zhang, Yurou Liu, Wayne Xin Zhao, Zujie Wen, Zhiqiang Zhang, and Jun Zhou. Towards high data efficiency in reinforcement...
-
[30]
Changxin Tian, Jiapeng Wang, Qian Zhao, Kunlong Chen, Jia Liu, Ziqi Liu, Jiaxin Mao, Wayne Xin Zhao, Zhiqiang Zhang, and Jun Zhou. Wsm: decay-free learning rate schedule via checkpoint merging for llm pre-training.arXiv preprint arXiv:2507.17634,
-
[31]
Aletheia: What makes RLVR for code verifiers tick?CoRR, abs/2601.12186,
Vatsal Venkatkrishna, Indraneil Paul, and Iryna Gurevych. Aletheia: What makes RLVR for code verifiers tick?CoRR, abs/2601.12186,
-
[32]
Binghai Wang, Rui Zheng, Lu Chen, Yan Liu, Shihan Dou, Caishuang Huang, Wei Shen, Senjie Jin, Enyu Zhou, Chenyu Shi, Songyang Gao, Nuo Xu, Yuhao Zhou, Xiaoran Fan, Zhiheng Xi, Jun Zhao, Xiao Wang, Tao Ji, Hang Yan, Lixing Shen, Zhan Chen, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, and Yu-Gang Jiang. Secrets of RLHF in large language models ...
-
[33]
Rlvr-world: Training world models with reinforcement learning.arXiv preprint arXiv:2505.13934,
Jialong Wu, Shaofeng Yin, Ningya Feng, and Mingsheng Long. Rlvr-world: Training world models with reinforcement learning.arXiv preprint arXiv:2505.13934,
-
[34]
Training large language models for reasoning through reverse curriculum reinforcement learning
Zhiheng Xi, Wenxiang Chen, Boyang Hong, Senjie Jin, Rui Zheng, Wei He, Yiwen Ding, Shichun Liu, Xin Guo, Junzhe Wang, Honglin Guo, Wei Shen, Xiaoran Fan, Yuhao Zhou, Shihan Dou, Xiao Wang, Xinbo Zhang, Peng Sun, Tao Gui, Qi Zhang, and Xuanjing Huang. Training large language models for reasoning through reverse curriculum reinforcement learning. InForty-fi...
2024
-
[35]
Prox- ythinker: Test-time guidance through small visual reasoners.arXiv preprint arXiv:2505.24872,
Zilin Xiao, Jaywon Koo, Siru Ouyang, Jefferson Hernandez, Yu Meng, and Vicente Ordonez. Prox- ythinker: Test-time guidance through small visual reasoners.arXiv preprint arXiv:2505.24872,
-
[36]
arXiv preprint arXiv:2502.14768 , year=
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. Logic-rl: Unleashing LLM reasoning with rule-based reinforcement learning.CoRR, abs/2502.14768,
-
[37]
arXiv preprint arXiv:2504.14945 , year =
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance.arXiv preprint arXiv:2504.14945,
-
[38]
Efficient reinforcement learning with large language model priors.arXiv preprint arXiv:2410.07927,
Xue Yan, Yan Song, Xidong Feng, Mengyue Yang, Haifeng Zhang, Haitham Bou Ammar, and Jun Wang. Efficient reinforcement learning with large language model priors.arXiv preprint arXiv:2410.07927,
-
[39]
Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration
Zhicheng Yang, Zhijiang Guo, Yinya Huang, Yongxin Wang, Dongchun Xie, Yiwei Wang, Xiaodan Liang, and Jing Tang. Depth-breadth synergy in RLVR: unlocking LLM reasoning gains with adaptive exploration.CoRR, abs/2508.13755,
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl- zoo: Investigating and taming zero reinforcement learning for open base models in the wild. CoRR, abs/2503.18892,
work page internal anchor Pith review arXiv
-
[42]
Wenxuan Zhang, Hou Pong Chan, Yiran Zhao, Mahani Aljunied, Jianyu Wang, Chaoqun Liu, Yue Deng, Zhiqiang Hu, Weiwen Xu, Yew Ken Chia, et al. Seallms 3: Open foundation and chat multilingual large language models for southeast asian languages. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Li...
-
[43]
Secrets of RLHF in large language models part I: PPO.CoRR, abs/2307.04964, 2023
Rui Zheng, Shihan Dou, Songyang Gao, Yuan Hua, Wei Shen, Binghai Wang, Yan Liu, Senjie Jin, Qin Liu, Yuhao Zhou, Limao Xiong, Lu Chen, Zhiheng Xi, Nuo Xu, Wenbin Lai, Minghao Zhu, Cheng Chang, Zhangyue Yin, Rongxiang Weng, Wensen Cheng, Haoran Huang, Tianxiang Sun, Hang Yan, Tao Gui, Qi Zhang, Xipeng Qiu, and Xuanjing Huang. Secrets of RLHF in large langu...
-
[44]
Xinyu Zhou, Boyu Zhu, Haotian Zhang, Huiming Wang, and Zhijiang Guo. Efficient rlvr training via weighted mutual information data selection.arXiv preprint arXiv:2603.01907,
-
[45]
Data-Efficient RLVR via Off-Policy Influence Guidance
Erle Zhu, Dazhi Jiang, Yuan Wang, Xujun Li, Jiale Cheng, Yuxian Gu, Yilin Niu, Aohan Zeng, Jie Tang, Minlie Huang, et al. Data-efficient rlvr via off-policy influence guidance.arXiv preprint arXiv:2510.26491, 2025a. Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng. The surprising effectiveness of negative reinforcement in LLM rea...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.