Recognition: no theorem link
CAGenMol: Condition-Aware Diffusion Language Model for Goal-Directed Molecular Generation
Pith reviewed 2026-05-10 15:45 UTC · model grok-4.3
The pith
A condition-aware discrete diffusion model paired with reinforcement learning generates molecules that satisfy multiple conflicting structural and property goals while preserving validity and diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
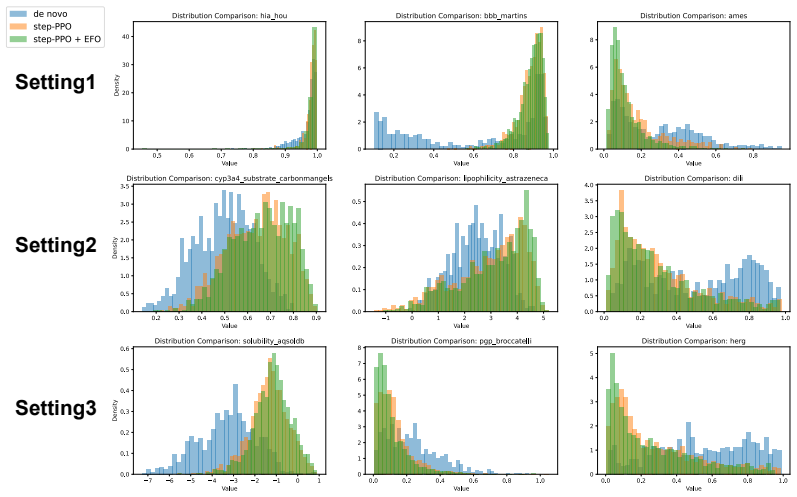
CAGenMol formulates molecular design as conditional denoising in a discrete diffusion framework over molecular sequences, guided by heterogeneous structural and property signals. By integrating reinforcement learning, the model aligns the generation trajectory with non-differentiable objectives. The non-autoregressive diffusion enables iterative refinement at inference time, leading to improved performance in binding affinity, drug-likeness, and overall success rates on structure-conditioned, property-conditioned, and dual-conditioned tasks.
What carries the argument
Condition-aware discrete diffusion over molecular sequences, where denoising steps receive guidance from structural and property signals and are aligned to non-differentiable goals through reinforcement learning.
If this is right
- Higher binding affinity is achieved on structure-conditioned generation tasks.
- Drug-likeness scores rise on property-conditioned generation tasks.
- Overall success rates increase when both structure and property constraints must be met simultaneously.
- Non-autoregressive generation permits iterative fragment-level refinement at inference time.
Where Pith is reading between the lines
- The same conditioning-plus-RL alignment pattern could be tested on other sequence-structured objects that require multi-objective optimization, such as polymer or catalyst design.
- Adding further conditioning signals like predicted toxicity or synthetic accessibility would test whether the framework scales to richer real-world constraints.
- Measuring how often the iterative refinement step corrects invalid intermediates could quantify the practical value of the non-autoregressive property.
Load-bearing premise
Heterogeneous structural and property signals can effectively guide conditional denoising in discrete diffusion, and reinforcement learning can align trajectories to non-differentiable objectives without reducing chemical validity or diversity.
What would settle it
A head-to-head experiment on the same structure-conditioned, property-conditioned, and dual-conditioned benchmarks in which CAGenMol shows no consistent gains over baselines in binding affinity, drug-likeness, or success rate would falsify the central claim.
Figures




read the original abstract
Goal-directed molecular generation requires satisfying heterogeneous constraints such as protein--ligand compatibility and multi-objective drug-like properties, yet existing methods often optimize these constraints in isolation, failing to reconcile conflicting objectives (e.g., affinity vs. safety), and struggle to navigate the non-differentiable chemical space without compromising structural validity. To address these challenges, we propose CAGenMol, a condition-aware discrete diffusion framework over molecular sequences that formulates molecular design as conditional denoising guided by heterogeneous structural and property signals. By coupling discrete diffusion with reinforcement learning, the model aligns the generation trajectory with non-differentiable objectives while preserving chemical validity and diversity. The non-autoregressive nature of diffusion language model further enables iterative refinement of molecular fragments at inference time. Experiments on structure-conditioned, property-conditioned, and dual-conditioned benchmarks demonstrate consistent improvements over state-of-the-art methods in binding affinity, drug-likeness, and success rate, highlighting the effectiveness of our framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CAGenMol, a condition-aware discrete diffusion language model for goal-directed molecular generation. It formulates molecular design as conditional denoising of molecular sequences guided by heterogeneous structural and property signals, couples this with reinforcement learning to align generation trajectories to non-differentiable objectives, and leverages the non-autoregressive nature for iterative fragment refinement at inference. Experiments on structure-conditioned, property-conditioned, and dual-conditioned benchmarks are claimed to show consistent improvements over state-of-the-art methods in binding affinity, drug-likeness, and success rate while preserving chemical validity and diversity.
Significance. If the results hold with rigorous validation, the work could advance goal-directed molecular generation by offering a unified approach to reconciling conflicting heterogeneous constraints (e.g., affinity versus safety) in non-differentiable chemical space. The integration of discrete diffusion with RL for trajectory alignment and the inference-time refinement capability represent potentially useful technical contributions to AI-driven drug design.
major comments (2)
- [Experiments] The central experimental claims of consistent improvements over SOTA in binding affinity, drug-likeness, and success rate are not supported by any reported quantitative metrics, error bars, number of independent runs, statistical significance tests, or ablation studies on the RL coupling and condition-aware components. This undermines evaluation of the magnitude and reliability of the gains.
- [Methods] The description of how heterogeneous structural and property signals are incorporated into the conditional denoising process, and the precise RL integration (e.g., reward shaping, policy gradient on denoising steps, or handling of non-differentiable objectives), lacks sufficient technical detail to verify that trajectories are aligned without compromising validity or diversity.
minor comments (1)
- The abstract and claims would benefit from explicit listing of the specific baselines, benchmark datasets (e.g., exact PDB IDs or property thresholds), and success rate definitions used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and commit to a major revision that strengthens the experimental reporting and methodological clarity while preserving the core contributions of CAGenMol.
read point-by-point responses
-
Referee: [Experiments] The central experimental claims of consistent improvements over SOTA in binding affinity, drug-likeness, and success rate are not supported by any reported quantitative metrics, error bars, number of independent runs, statistical significance tests, or ablation studies on the RL coupling and condition-aware components. This undermines evaluation of the magnitude and reliability of the gains.
Authors: We acknowledge that the current manuscript presents experimental outcomes primarily through summarized claims and selected figures without accompanying tables of raw metrics, error bars, run counts, or statistical tests. In the revised version we will add comprehensive result tables reporting mean performance and standard deviation across at least five independent runs for all benchmarks, include error bars on all relevant plots, and perform paired statistical significance tests (e.g., Wilcoxon or t-tests) against the strongest baselines. We will also insert dedicated ablation studies that isolate the condition-aware conditioning module and the RL trajectory-alignment component, quantifying their individual contributions to binding affinity, drug-likeness, and success rate. revision: yes
-
Referee: [Methods] The description of how heterogeneous structural and property signals are incorporated into the conditional denoising process, and the precise RL integration (e.g., reward shaping, policy gradient on denoising steps, or handling of non-differentiable objectives), lacks sufficient technical detail to verify that trajectories are aligned without compromising validity or diversity.
Authors: We agree that the Methods section requires greater precision. The revised manuscript will expand the conditioning mechanism with explicit equations showing how structural (e.g., protein pocket embeddings) and property signals are projected, fused, and injected into the discrete diffusion transformer at each denoising step. For the RL component we will provide the exact reward formulation, the policy-gradient estimator applied over the diffusion trajectory, the reward-shaping schedule, and the validity-preserving mechanisms (masking and prior regularization) that prevent degradation of chemical validity or diversity. These additions will enable readers to verify the alignment procedure. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces CAGenMol as a novel condition-aware discrete diffusion model coupled with reinforcement learning for goal-directed molecular generation. Its central claims rest on the formulation of conditional denoising guided by structural and property signals, with empirical validation through experiments on structure-conditioned, property-conditioned, and dual-conditioned benchmarks showing improvements in binding affinity, drug-likeness, and success rate. No load-bearing steps in the provided abstract or described framework reduce by construction to self-definitions, fitted inputs renamed as predictions, or self-citation chains; the non-autoregressive iterative refinement and RL alignment are presented as methodological choices supported by external benchmarks rather than internal tautologies. The derivation chain is self-contained against independent experimental outcomes.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Pushing Biomolecular Utility-Diversity Frontiers with Supergroup Relative Policy Optimization
SGRPO expands the utility-diversity Pareto frontier in biomolecular design by using supergroup sampling and leave-one-out diversity rewards combined with utility signals.
Reference graph
Works this paper leans on
-
[1]
Drug discovery today, 24(5):1157–1165
Admet modeling approaches in drug discovery. Drug discovery today, 24(5):1157–1165. Paul G Francoeur, Tomohide Masuda, Jocelyn Sunseri, Andrew Jia, Richard B Iovanisci, Ian Snyder, and David R Koes. 2020. Three-dimensional convolu- tional neural networks and a cross-docked data set for structure-based drug design.Journal of chemical information and modeli...
-
[2]
InInternational conference on machine learning, pages 14631–14653
Multi-objective gflownets. InInternational conference on machine learning, pages 14631–14653. PMLR. Jan H Jensen. 2019. A graph-based genetic algorithm and generative model/monte carlo tree search for the exploration of chemical space.Chemical science, 10(12):3567–3572. Kerstin Kläser, Bła˙zej Banaszewski, Samuel Maddrell- Mander, Callum McLean, Luis Müll...
2019
-
[3]
Minimol: A parameter-efficient founda- tion model for molecular learning.arXiv preprint arXiv:2404.14986. Daniel E Koshland Jr. 1958. Application of a theory of enzyme specificity to protein synthesis.Proceedings of the National Academy of Sciences, 44(2):98–104. Mario Krenn, Florian Häse, AkshatKumar Nigam, Pas- cal Friederich, and Alan Aspuru-Guzik. 202...
-
[4]
Meng Liu, Youzhi Luo, Kanji Uchino, Koji Maruhashi, and Shuiwang Ji
Evolutionary-scale prediction of atomic-level protein structure with a language model.Science, 379(6637):1123–1130. Meng Liu, Youzhi Luo, Kanji Uchino, Koji Maruhashi, and Shuiwang Ji. 2022. Generating 3d molecules for target protein binding.arXiv preprint arXiv:2204.09410. Hannes H Loeffler, Jiazhen He, Alessandro Tibo, Jon Paul Janet, Alexey V oronov, L...
-
[5]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834. Shitong Luo, Jiaqi Guan, Jianzhu Ma, and Jian Peng
work page internal anchor Pith review arXiv
-
[6]
arXiv preprint arXiv:2404.12141 , year=
A 3d generative model for structure-based drug design.Advances in Neural Information Pro- cessing Systems, 34:6229–6239. Emmanuel Noutahi, Cristian Gabellini, Michael Craig, Jonathan SC Lim, and Prudencio Tossou. 2024. Gotta be safe: a new framework for molecular design. Digital Discovery, 3(4):796–804. Xingang Peng, Shitong Luo, Jiaqi Guan, Qi Xie, Jian ...
-
[7]
Proximal Policy Optimization Algorithms
Structure-based drug design with equivariant diffusion models.Nature Computational Science, 4(12):899–909. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingc...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Taming masked diffusion language mod- els via consistency trajectory reinforcement learn- ing with fewer decoding step.arXiv preprint arXiv:2509.23924. Naruki Yoshikawa, Kei Terayama, Masato Sumita, Teruki Homma, Kenta Oono, and Koji Tsuda. 2018. Population-based de novo molecule generation, us- ing grammatical evolution.Chemistry Letters, 47(11):1431–143...
-
[9]
Molecule generation for target protein binding with structural motifs. InThe eleventh international conference on learning representations. Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. 2025. d1: Scaling reasoning in diffu- sion large language models via reinforcement learn- ing.arXiv preprint arXiv:2504.12216. Kangyu Zheng, Yingzhou Lu, Z...
-
[10]
Each iteration begins by constructing a seed molecule xinit
Initialization via Fragment Attachment. Each iteration begins by constructing a seed molecule xinit. Two fragments are randomly sampled from the current vocabulary V and at- tached to form a valid Sequential Attachment- based Fragment Embedding (SAFE) represen- tation. This initialization strategy ensures that the starting molecules already contain sub- s...
-
[11]
Unlike token-level mask- ing, this operator acts at the semantic level of chemical substructures
Mutation via Fragment Remasking.To ex- plore the local chemical neighborhood ofxinit, we apply a mutation operator termedFrag- ment Remasking. Unlike token-level mask- ing, this operator acts at the semantic level of chemical substructures. A fragment is selected according to a decomposition rule Rremask and replaced by a sequence of mask tokens [M]. The ...
-
[12]
Given a partially masked molecule, the diffu- sion model iteratively denoises the masked positions while attending to the unmasked fragment-level context through self-attention
Reconstruction with Molecular Fragment Context.The masked region is reconstructed using the discrete diffusion model condi- tioned on the remaining molecular fragments. Given a partially masked molecule, the diffu- sion model iteratively denoises the masked positions while attending to the unmasked fragment-level context through self-attention. This condi...
-
[13]
It is then decomposed into fragments, which are scored using S(·) and merged into the vocabulary
Vocabulary Evolution.The newly gener- ated molecule xnew is evaluated by the task- specific scoring oracle. It is then decomposed into fragments, which are scored using S(·) and merged into the vocabulary. The vocab- ulary V is subsequently updated by retaining the top-V fragments from the union of the ex- isting and newly generated candidates. This feedb...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.