Recognition: unknown
NovBench: Evaluating Large Language Models on Academic Paper Novelty Assessment
Pith reviewed 2026-05-10 16:16 UTC · model grok-4.3
The pith
Large language models exhibit limited understanding of scientific novelty and often fail to follow instructions when assessing academic papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NovBench is presented as the first large-scale benchmark for LLM novelty assessment, built from 1,684 paper-review pairs that include explicit novelty descriptions from introductions and matching expert novelty evaluations. A four-dimensional framework (Relevance, Correctness, Coverage, Clarity) is used to score LLM-generated evaluations, and tests reveal that current models have limited comprehension of scientific novelty while fine-tuned models frequently exhibit instruction-following deficiencies.
What carries the argument
The NovBench dataset of paper-review pairs together with the four-dimensional evaluation framework (Relevance, Correctness, Coverage, Clarity) used to score LLM-generated novelty assessments.
If this is right
- Targeted fine-tuning must simultaneously improve novelty comprehension and instruction adherence for better results.
- Current general-purpose LLMs are not yet reliable enough to replace or substantially assist human reviewers on novelty judgments.
- The benchmark can be used to track progress as models are updated or retrained on peer-review data.
- Human peer review remains essential until models demonstrate stronger performance on this task.
Where Pith is reading between the lines
- Improved performance on this benchmark could enable AI tools that pre-screen submissions for obvious lack of novelty before human review begins.
- The same four-dimensional framework might extend to evaluating other peer-review dimensions such as methodological soundness or clarity of claims.
- General advances in LLM reasoning may not automatically solve domain-specific tasks like novelty detection without explicit training on research papers.
- Publishers could adopt similar benchmarks to certify models for use in editorial workflows.
Load-bearing premise
The novelty descriptions taken from paper introductions and the expert-written evaluations accurately reflect the true novelty of the underlying research.
What would settle it
If a new or retrained model produces novelty evaluations that receive high scores across all four dimensions on the NovBench pairs and matches expert judgments closely, the claim of limited understanding would be challenged.
Figures




















read the original abstract
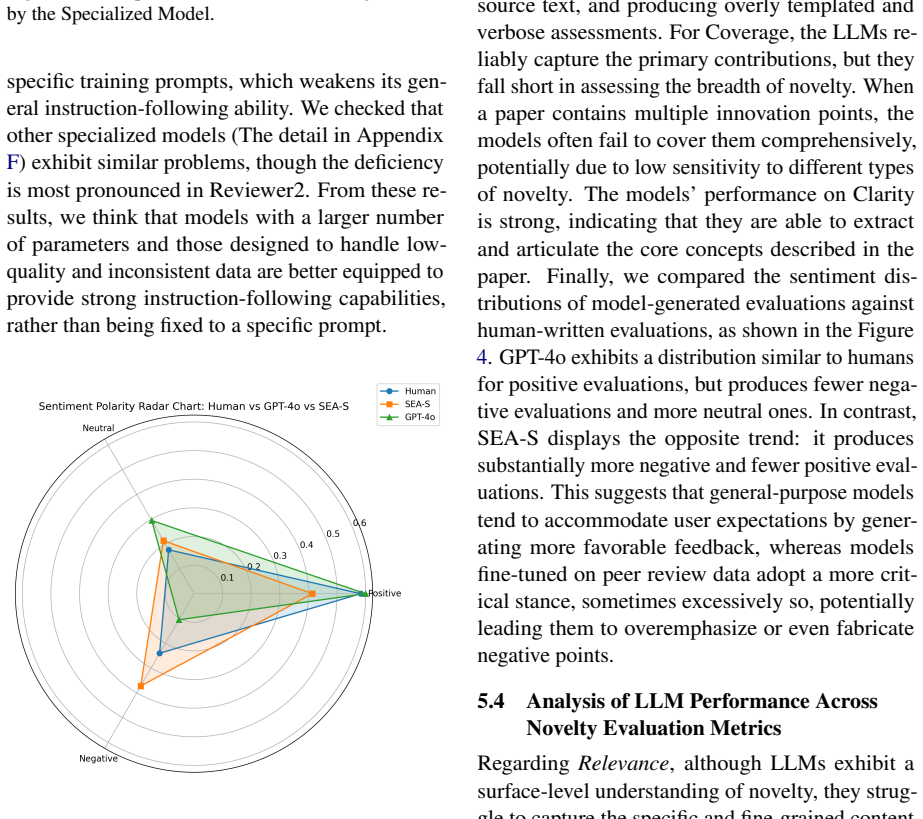
Novelty is a core requirement in academic publishing and a central focus of peer review, yet the growing volume of submissions has placed increasing pressure on human reviewers. While large language models (LLMs), including those fine-tuned on peer review data, have shown promise in generating review comments, the absence of a dedicated benchmark has limited systematic evaluation of their ability to assess research novelty. To address this gap, we introduce NovBench, the first large-scale benchmark designed to evaluate LLMs' capability to generate novelty evaluations in support of human peer review. NovBench comprises 1,684 paper-review pairs from a leading NLP conference, including novelty descriptions extracted from paper introductions and corresponding expert-written novelty evaluations. We focus on both sources because the introduction provides a standardized and explicit articulation of novelty claims, while expert-written novelty evaluations constitute one of the current gold standards of human judgment. Furthermore, we propose a four-dimensional evaluation framework (including Relevance, Correctness, Coverage, and Clarity) to assess the quality of LLM-generated novelty evaluations. Extensive experiments on both general and specialized LLMs under different prompting strategies reveal that current models exhibit limited understanding of scientific novelty, and that fine--tuned models often suffer from instruction-following deficiencies. These findings underscore the need for targeted fine-tuning strategies that jointly improve novelty comprehension and instruction adherence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NovBench, the first large-scale benchmark for evaluating LLMs on generating novelty assessments for academic papers. It consists of 1,684 paper-review pairs from a leading NLP conference, pairing novelty claims extracted from paper introductions with expert-written novelty evaluations as references. The authors propose a four-dimensional evaluation framework (Relevance, Correctness, Coverage, Clarity) and conduct experiments on general and specialized LLMs under various prompting strategies, concluding that current models exhibit limited understanding of scientific novelty while fine-tuned models frequently suffer from instruction-following deficiencies.
Significance. If the gold-standard references prove reliable, NovBench would fill an important gap by providing a systematic way to assess LLMs on a core peer-review task. The scale (1,684 pairs) and focus on both explicit novelty claims and expert judgments are strengths, and the findings could motivate better fine-tuning approaches that jointly target novelty comprehension and instruction adherence. The work is timely given increasing submission volumes and LLM use in review assistance.
major comments (3)
- [§3 (Benchmark Construction)] §3 (Benchmark Construction): The central claim that LLMs show limited novelty understanding rests on expert-written evaluations serving as valid gold standards, yet no inter-annotator agreement, cross-validation against citation-based novelty proxies, or consistency checks across reviewers are reported. Without these, low LLM scores may reflect misalignment with this particular dataset's subjectivity or conference bias rather than a general comprehension deficit.
- [§5 (Experiments)] §5 (Experiments): The abstract and high-level findings reference extensive experiments on prompting strategies and comparisons between general vs. fine-tuned models, but the manuscript supplies insufficient detail on data splits, exact prompting templates, baseline selection, or statistical significance tests. This prevents verification of the specific claim that fine-tuned models suffer from instruction-following deficiencies.
- [§4 (Evaluation Framework)] §4 (Evaluation Framework): The four-dimensional scoring (Relevance/Correctness/Coverage/Clarity) is introduced without reported inter-rater reliability for the LLM output annotations or concrete examples of how each dimension is operationalized on sample outputs. This makes the quantitative results hard to interpret and replicate.
minor comments (2)
- [Abstract] Abstract: Typo 'fine--tuned' should read 'fine-tuned'.
- [Discussion/Conclusion] The manuscript would benefit from a dedicated limitations section explicitly discussing potential biases in the chosen conference data and the subjectivity of novelty judgments.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating the revisions we will make to improve the paper's rigor and reproducibility.
read point-by-point responses
-
Referee: The central claim that LLMs show limited novelty understanding rests on expert-written evaluations serving as valid gold standards, yet no inter-annotator agreement, cross-validation against citation-based novelty proxies, or consistency checks across reviewers are reported. Without these, low LLM scores may reflect misalignment with this particular dataset's subjectivity or conference bias rather than a general comprehension deficit.
Authors: We acknowledge the importance of validating the gold standard. The novelty evaluations are drawn from actual single-reviewer assessments at a leading NLP conference, which is standard practice and precludes direct computation of inter-annotator agreement. In the revised manuscript, we will add a dedicated subsection discussing the inherent subjectivity of novelty judgments in peer review, along with a cross-validation analysis that correlates our benchmark scores with citation-based proxies and other external signals where data is available. This will help demonstrate that the observed LLM limitations reflect broader challenges in novelty comprehension rather than dataset-specific artifacts. revision: yes
-
Referee: The abstract and high-level findings reference extensive experiments on prompting strategies and comparisons between general vs. fine-tuned models, but the manuscript supplies insufficient detail on data splits, exact prompting templates, baseline selection, or statistical significance tests. This prevents verification of the specific claim that fine-tuned models suffer from instruction-following deficiencies.
Authors: We agree that additional experimental details are required for verification and reproducibility. The revised Section 5 will explicitly report the data split sizes and ratios, include all prompting templates in a new appendix, provide justification for baseline choices, and present statistical significance tests (e.g., paired t-tests or Wilcoxon tests) for the comparisons between general and fine-tuned models. We will also make the full code, prompts, and evaluation scripts publicly available to allow direct verification of the instruction-following deficiencies. revision: yes
-
Referee: The four-dimensional scoring (Relevance/Correctness/Coverage/Clarity) is introduced without reported inter-rater reliability for the LLM output annotations or concrete examples of how each dimension is operationalized on sample outputs. This makes the quantitative results hard to interpret and replicate.
Authors: We appreciate this point on operationalization and reliability. The dimensions were scored by the authors following written guidelines. In the revision, we will add a table with concrete examples illustrating how each dimension is applied to sample LLM outputs. We will also conduct a multi-annotator reliability study on a subset of outputs and report agreement metrics such as Cohen's or Fleiss' kappa to support the quantitative results. revision: yes
Circularity Check
No circularity: benchmark and evaluation rest on external conference data
full rationale
The paper constructs NovBench from 1,684 external paper-review pairs drawn from a leading NLP conference. Novelty descriptions are extracted directly from paper introductions, and expert-written evaluations serve as reference targets. The four-dimensional scoring framework (Relevance, Correctness, Coverage, Clarity) is defined independently of any LLM output or fitted parameter. Experiments simply compare model generations against these fixed external references under different prompts. No equations, self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the derivation chain; the empirical results are therefore not forced by construction from the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert-written novelty evaluations from the conference constitute a reliable gold standard for assessing LLM-generated novelty assessments.
- domain assumption The four-dimensional framework (Relevance, Correctness, Coverage, Clarity) is an appropriate and sufficient way to measure the quality of novelty evaluations.
Reference graph
Works this paper leans on
-
[1]
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.Preprint, arXiv:2501.12948. Jiangshu Du, Yibo Wang, Wenting Zhao, Zhongfen Deng, Shuaiqi Liu, Renze Lou, Henry Peng Zou, Pranav Narayanan Venkit, Nan Zhang, Mukund Sri- nath, Haoran Ranran Zhang, Vipul Gupta, Yinghui Li, Tao Li, Fei Wang, Qin Liu, Tianlin Liu, Pengzhi Gao...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Alireza Ghafarollahi and Markus J Buehler
Reviewer2: Optimizing review gen- eration through prompt generation.Preprint, arXiv:2402.10886. Google Gemini Team. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. Preprint, arXiv:2507.06261. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek K...
-
[3]
Cycleresearcher: Improving automated re- search via automated review. InThe Thirteenth Inter- national Conference on Learning Representations. Dustin Wright, Jiaxin Pei, David Jurgens, and Isabelle Augenstein. 2022. Modeling information change in science communication with semantically matched paraphrases. InProceedings of the 2022 Conference on Empirical...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
In this paper, we propose a novel transformer-based architecture that integrates syntactic information into language modeling
CA-GAR: Context-aware alignment of LLM generation for document retrieval. InFindings of the Association for Computational Linguistics: ACL 2025, pages 5836–5849, Vienna, Austria. Associa- tion for Computational Linguistics. Jianxiang Yu, Zichen Ding, Jiaqi Tan, Kangyang Luo, Zhenmin Weng, Chenghua Gong, Long Zeng, Ren- Jing Cui, Chengcheng Han, Qiushi Sun...
2025
-
[5]
Briefly summarize what the sentence is mainly saying
-
[6]
new” or “novel
Indicate whether it refers to this paper's own work, or to prior work or general background. Sentence: {sentence} Answer format: Main idea: ... Refers to: [This paper / Previous work / General background] #Step 3 Given the following context: Main idea: {main_idea} Refers to: {refers_to} Does this sentence describe the novelty or original contribution of t...
2019
-
[7]
Deduplicate and consolidate comments that are semantically identical or very similar into a single, concise statement
-
[8]
Categorize each consolidated comment into one of the following classes: - Positive Novelty Evaluations - Neutral Novelty Evaluations - Negative Novelty Evaluations
-
[9]
Use the exact output format: Positive Novelty Evaluations - [Consolidated positive comment 1] - [Consolidated positive comment 2] Neutral Novelty Evaluations - [Consolidated neutral comment 1] Negative Novelty Evaluations - [Consolidated negative comment 1] - [Consolidated negative comment 2] Here are the evaluations: {reviews} Figure 13: The Prompt for S...
-
[10]
Relevance Determine whether the model’s evaluation genuinely addresses the novelty of the paper rather than drifting into unrelated topics (e.g., dataset details, experimental results, writing quality, or background information)
-
[11]
Correctness Determine whether the model’s positive/neutral/negative stance aligns with the expert reviewer’s actual novelty evaluation
-
[12]
Coverage Determine whether the model captures multiple novelty points mentioned by the expert, rather than focusing on only one point or missing important aspects
-
[13]
Positive
Clarity Determine whether the evaluation is clear, specific, and meaningful, rather than vague, generic, or lacking detail. Final Output (Choose One) Please choose only one of the following: • Model A is better • Model B is better • Both are comparable Figure 15: Guideline of Human Evaluation. 22 You are a peer-review expert specializing in novelty evalua...
-
[14]
Sentences from the introduction of a paper that describe its novelty
-
[15]
Positive
Titles and abstracts of 5 related papers retrieved from a local literature database. Your task is to evaluate the novelty of the given paper by comparing it against the retrieved references. Output your evaluation strictly in the following format: Positive Novelty Evaluations - Neutral Novelty Evaluations - Negative Novelty Evaluations - Rules: - If the c...
-
[16]
Title: {retrieved_title_1} Abstract: {retrieved_abstract_1}
-
[17]
Title: {retrieved_title_2} Abstract: {retrieved_abstract_2}
-
[18]
Title: {retrieved_title_3} Abstract: {retrieved_abstract_3}
-
[19]
Title: {retrieved_title_4} Abstract: {retrieved_abstract_4}
-
[20]
Title: {retrieved_title_5} Abstract: {retrieved_abstract_5} Figure 18: The RAG prompt for different LLMs on NovBench. 25 ser wants me to understand that they are presenting a paper about LLMs and CRSs in Ecommerce. They will describe two types of collaborations. I need to wait for the full description of the collaborations to evaluate the novelty. My curr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.