Recognition: unknown
Back to Basics: Let Conversational Agents Remember with Just Retrieval and Generation
Pith reviewed 2026-05-10 15:22 UTC · model grok-4.3
The pith
Conversational memory works better with isolated turn retrieval and query-driven pruning than with complex summarization or reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
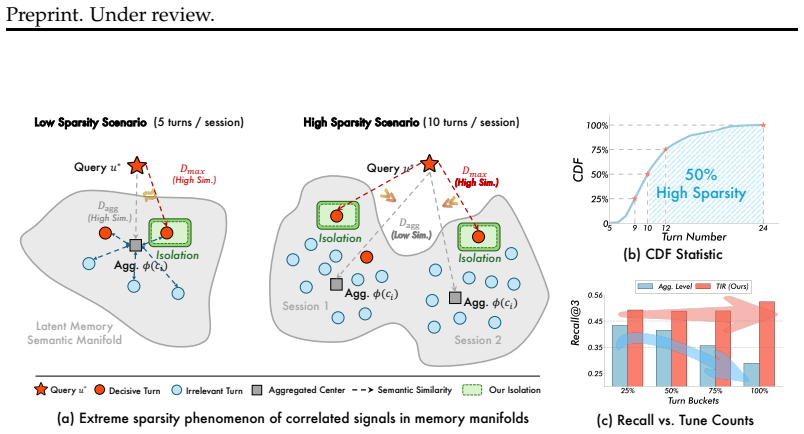
The primary bottleneck in conversational memory lies in the Signal Sparsity Effect within the latent knowledge manifold. Decisive Evidence Sparsity isolates relevant signals with longer sessions, and Dual-Level Redundancy adds inter-session interference plus intra-session filler that hinders generation. The framework addresses this through Turn Isolation Retrieval, which replaces global aggregation with max-activation at the turn level, and Query-Driven Pruning, which removes non-informative content to build a high-density evidence set for direct generation.
What carries the argument
Turn Isolation Retrieval (TIR) and Query-Driven Pruning (QDP), which isolate turn-level signals via max-activation and remove redundant sessions and filler to supply compact evidence for generation.
Load-bearing premise
That the identified Signal Sparsity Effect, Decisive Evidence Sparsity, and Dual-Level Redundancy are the main causes of degradation and that TIR plus QDP can extract high-density evidence without losing critical cross-turn context.
What would settle it
A set of dialogues where key facts span multiple turns such that isolating retrieval per turn drops accuracy below global aggregation baselines.
Figures








read the original abstract
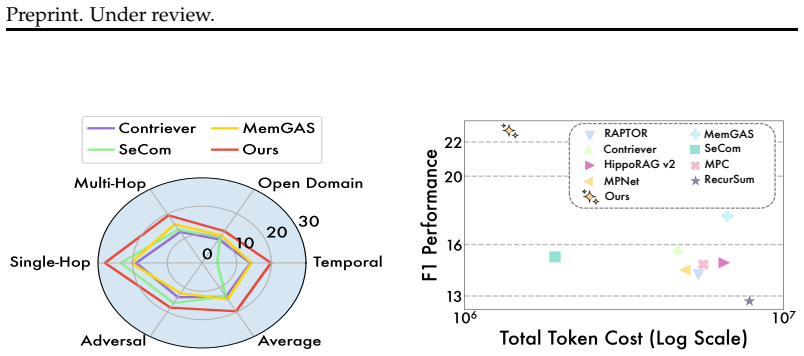
Existing conversational memory systems rely on complex hierarchical summarization or reinforcement learning to manage long-term dialogue history, yet remain vulnerable to context dilution as conversations grow. In this work, we offer a different perspective: the primary bottleneck may lie not in memory architecture, but in the \textit{Signal Sparsity Effect} within the latent knowledge manifold. Through controlled experiments, we identify two key phenomena: \textit{Decisive Evidence Sparsity}, where relevant signals become increasingly isolated with longer sessions, leading to sharp degradation in aggregation-based methods; and \textit{Dual-Level Redundancy}, where both inter-session interference and intra-session conversational filler introduce large amounts of non-informative content, hindering effective generation. Motivated by these insights, we propose \method, a minimalist framework that brings conversational memory back to basics, relying solely on retrieval and generation via Turn Isolation Retrieval (TIR) and Query-Driven Pruning (QDP). TIR replaces global aggregation with a max-activation strategy to capture turn-level signals, while QDP removes redundant sessions and conversational filler to construct a compact, high-density evidence set. Extensive experiments on multiple benchmarks demonstrate that \method achieves robust performance across diverse settings, consistently outperforming strong baselines while maintaining high efficiency in tokens and latency, establishing a new minimalist baseline for conversational memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that degradation in long-term conversational memory arises primarily from the Signal Sparsity Effect—specifically Decisive Evidence Sparsity (relevant signals becoming isolated) and Dual-Level Redundancy (inter- and intra-session non-informative content)—rather than from memory architecture complexity. Through controlled experiments the authors identify these issues and propose a minimalist framework relying solely on retrieval and generation: Turn Isolation Retrieval (TIR) replaces global aggregation with per-turn max-activation, while Query-Driven Pruning (QDP) removes redundant sessions and filler to produce a compact evidence set. The paper reports that this approach consistently outperforms strong baselines across multiple benchmarks while remaining efficient in token usage and latency.
Significance. If the empirical results hold, the work would be significant for establishing a simple, efficient baseline that questions the necessity of complex hierarchical summarization or RL-based memory systems. It provides concrete evidence that directly targeting sparsity and redundancy via retrieval can suffice, and the emphasis on efficiency metrics offers a practical contribution to the field.
major comments (2)
- [§4] §4 (TIR and QDP description): The central claim that TIR's max-activation strategy reliably isolates decisive evidence rests on the untested assumption that relevant turns produce the highest activation score for a given query. No ablation or case study examines query-mismatch scenarios in which critical facts exhibit low lexical or embedding overlap yet remain decisive; without such validation the outperformance results cannot be attributed to successful recovery of sparse signals rather than dataset-specific properties.
- [§3] §3 (controlled experiments identifying the phenomena): The experiments demonstrating Decisive Evidence Sparsity and Dual-Level Redundancy are presented as independent motivation, yet the manuscript provides no details on the activation metric used, the precise definition of 'decisive evidence,' or whether the experimental design was performed prior to and independently of the TIR/QDP proposal. This leaves open the possibility that the identified effects are partly artifacts of the measurement choices that later motivate the method.
minor comments (2)
- [Abstract] Abstract: The abstract states that the method 'consistently outperforming strong baselines' and maintains 'high efficiency' but supplies no numerical results, named baselines, or benchmark identifiers, reducing immediate readability.
- Notation: The shorthand 'method' appears before its expansion; spelling out the full name on first use would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will incorporate revisions to improve clarity and validation.
read point-by-point responses
-
Referee: [§4] §4 (TIR and QDP description): The central claim that TIR's max-activation strategy reliably isolates decisive evidence rests on the untested assumption that relevant turns produce the highest activation score for a given query. No ablation or case study examines query-mismatch scenarios in which critical facts exhibit low lexical or embedding overlap yet remain decisive; without such validation the outperformance results cannot be attributed to successful recovery of sparse signals rather than dataset-specific properties.
Authors: We acknowledge that the manuscript does not currently contain dedicated ablations or case studies for query-mismatch scenarios with low lexical or embedding overlap. The controlled experiments in §3 establish the sparsity effect and motivate the max-activation choice, while the consistent gains across multiple benchmarks provide supporting evidence for robustness. To directly address the concern and strengthen attribution to sparse-signal recovery, we will add a targeted ablation and qualitative case study in the revised version that explicitly tests low-overlap decisive facts. revision: yes
-
Referee: [§3] §3 (controlled experiments identifying the phenomena): The experiments demonstrating Decisive Evidence Sparsity and Dual-Level Redundancy are presented as independent motivation, yet the manuscript provides no details on the activation metric used, the precise definition of 'decisive evidence,' or whether the experimental design was performed prior to and independently of the TIR/QDP proposal. This leaves open the possibility that the identified effects are partly artifacts of the measurement choices that later motivate the method.
Authors: We agree that additional transparency is required. In the revised manuscript we will expand §3 to specify the activation metric (maximum cosine similarity using a fixed sentence-transformer embedding model), provide a precise definition of decisive evidence (turns containing information necessary for correct query resolution, cross-validated by human annotation on a sample), and explicitly state that the diagnostic experiments were designed and executed as an independent preliminary analysis prior to the development of TIR and QDP. These clarifications will eliminate ambiguity regarding potential measurement artifacts. revision: yes
Circularity Check
No circularity: derivation relies on independent experiments and benchmark validation
full rationale
The paper first runs controlled experiments to surface Signal Sparsity Effect, Decisive Evidence Sparsity, and Dual-Level Redundancy, then introduces TIR (max-activation per turn) and QDP (query-driven pruning) as a direct response. These steps are empirical motivation followed by a new retrieval-generation pipeline; the final performance claims rest on separate benchmark evaluations against external baselines rather than any self-definition, fitted-parameter renaming, or self-citation chain. No equations or definitions in the provided text reduce the claimed outperformance to the initial observations by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retrieval of isolated turns can capture decisive evidence better than global aggregation
invented entities (3)
-
Signal Sparsity Effect
no independent evidence
-
Decisive Evidence Sparsity
no independent evidence
-
Dual-Level Redundancy
no independent evidence
Forward citations
Cited by 1 Pith paper
-
HadAgent: Harness-Aware Decentralized Agentic AI Serving with Proof-of-Inference Blockchain Consensus
HadAgent uses Proof-of-Inference consensus, a three-lane block structure, and a harness layer to enable secure decentralized LLM agent serving.
Reference graph
Works this paper leans on
-
[1]
Vincent-Pierre Berges, Barlas O˘ guz, Daniel Haziza, Wen-tau Yih, Luke Zettlemoyer, and Gargi Ghosh. Memory layers at scale.arXiv preprint arXiv:2412.09764,
-
[2]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
URL https: //arxiv.org/abs/2504.19413. Lin Chin-Yew. Rouge: A package for automatic evaluation of summaries. InProceedings of the Workshop on Text Summarization Branches Out, 2004,
work page internal anchor Pith review arXiv 2004
-
[3]
Pan, Ruifeng Xu, and Kam-Fai Wong
Yiming Du, Bingbing Wang, Yang He, Bin Liang, Baojun Wang, Zhongyang Li, Lin Gui, Jeff Z Pan, Ruifeng Xu, and Kam-Fai Wong. Memguide: Intent-driven memory selection for goal-oriented multi-session llm agents.arXiv preprint arXiv:2505.20231,
-
[4]
Cartridges: Lightweight and general- purpose long context representations via self-study
Sabri Eyuboglu, Ryan Ehrlich, Simran Arora, Neel Guha, Dylan Zinsley, Emily Liu, Will Ten- nien, Atri Rudra, James Zou, Azalia Mirhoseini, et al. Cartridges: Lightweight and general- purpose long context representations via self-study.arXiv preprint arXiv:2506.06266,
-
[5]
URL https://arxiv. org/abs/2510.18866. Zafeirios Fountas, Martin Benfeghoul, Adnan Oomerjee, Fenia Christopoulou, Gerasimos Lampouras, Haitham Bou Ammar, and Jun Wang. Human-inspired episodic memory for infinite context llms. InThe Thirteenth International Conference on Learning Representations,
-
[6]
Manthan Gupta. I reverse engineered claude’s memory system, and here’s what i found! https://manthanguptaa.in/posts/claude_memory/, 2025a. Manthan Gupta. I reverse engineered chatgpt’s memory system, and here’s what i found! https://manthanguptaa.in/posts/chatgpt_memory/, 2025b. Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. From...
-
[7]
Rag meets temporal graphs: Time-sensitive modeling and retrieval for evolving knowledge
Jiale Han, Austin Cheung, Yubai Wei, Zheng Yu, Xusheng Wang, Bing Zhu, and Yi Yang. Rag meets temporal graphs: Time-sensitive modeling and retrieval for evolving knowledge. arXiv preprint arXiv:2510.13590,
-
[8]
Memory in the Age of AI Agents
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 32779–32798, 2025a. 11 Preprint. Under review. Yuy...
work page internal anchor Pith review arXiv
-
[9]
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
URLhttps://arxiv.org/abs/2601.03236. Cai Ke, Yiming Du, Bin Liang, Yifan Xiang, Lin Gui, Zhongyang Li, Baojun Wang, Yue Yu, Hui Wang, Kam-Fai Wong, et al. Flexibly utilize memory for long-term conversation via a fragment-then-compose framework. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 21130–21147,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Prompted llms as chatbot modules for long open-domain conversation
Gibbeum Lee, Volker Hartmann, Jongho Park, Dimitris Papailiopoulos, and Kangwook Lee. Prompted llms as chatbot modules for long open-domain conversation. InFindings of the association for computational linguistics: ACL 2023, pp. 4536–4554,
2023
-
[11]
Federated maddpg-based collaborative scheduling strategy in vehicular edge computing
Songxin Lei, Huijun Tang, Chuangyi Li, Xueying Zhang, Chenli Xu, and Huaming Wu. Federated maddpg-based collaborative scheduling strategy in vehicular edge computing. IEEE Transactions on Mobile Computing, 2025a. Songxin Lei, Qiongyan Wang, Yanchen Zhu, Hanyu Yao, Sijie Ruan, Weilin Ruan, Yuyu Luo, Huaming Wu, and Yuxuan Liang. A game-theoretic spatio-tem...
-
[12]
Hello again! llm-powered personalized agent for long-term dialogue
Hao Li, Chenghao Yang, An Zhang, Yang Deng, Xiang Wang, and Tat-Seng Chua. Hello again! llm-powered personalized agent for long-term dialogue. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 5259–5276,
2025
-
[13]
TiMem: Temporal-Hierarchical Memory Consolidation for Long-Horizon Conversational Agents
URL https://arxiv.org/ abs/2601.02845. Jun Liu, Zhenglun Kong, Changdi Yang, Fan Yang, Tianqi Li, Peiyan Dong, Joannah Nan- jekye, Hao Tang, Geng Yuan, Wei Niu, et al. Rcr-router: Efficient role-aware context rout- ing for multi-agent llm systems with structured memory.arXiv preprint arXiv:2508.04903,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Na Liu, Liangyu Chen, Xiaoyu Tian, Wei Zou, Kaijiang Chen, and Ming Cui. From llm to conversational agent: A memory enhanced architecture with fine-tuning of large language models.arXiv preprint arXiv:2401.02777,
-
[15]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[16]
12 Preprint. Under review. Junru Lu, Siyu An, Mingbao Lin, Gabriele Pergola, Yulan He, Di Yin, Xing Sun, and Yunsheng Wu. Memochat: Tuning llms to use memos for consistent long-range open- domain conversation.arXiv preprint arXiv:2308.08239,
-
[17]
MemGPT: Towards LLMs as Operating Systems
URL https: //arxiv.org/abs/2310.08560. Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, et al. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 963–981,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H Vicky Zhao, Lili Qiu, et al. On memory construction and retrieval for personalized conversational agents.arXiv preprint arXiv:2502.05589,
-
[19]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956,
work page internal anchor Pith review arXiv
-
[20]
arXiv preprint arXiv:2507.22925 , year=
Haoran Sun and Shaoning Zeng. Hierarchical memory for high-efficiency long-term reason- ing in llm agents.arXiv preprint arXiv:2507.22925,
-
[21]
Xingyu Tan, Xiaoyang Wang, Qing Liu, Xiwei Xu, Xin Yuan, Liming Zhu, and Wenjie Zhang. Memotime: Memory-augmented temporal knowledge graph enhanced large language model reasoning.arXiv preprint arXiv:2510.13614, 2025a. Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, et al. In prospect and...
-
[22]
https: //arxiv.org/abs/2002.10957
URLhttps://arxiv.org/abs/2002.10957. 13 Preprint. Under review. Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813,
-
[23]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Kai Mei, Hang Gao, Juntao Tan, Zujie Liang, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110,
work page internal anchor Pith review arXiv
-
[24]
Yilun Yao, Shan Huang, Elsie Dai, Zhewen Tan, Zhenyu Duan, Shousheng Jia, Yanbing Jiang, and Tong Yang. Arc: Active and reflection-driven context management for long-horizon information seeking agents.arXiv preprint arXiv:2601.12030,
-
[25]
arXiv preprint arXiv:2312.17257 , year=
URL https: //arxiv.org/abs/2312.17257. Yanwei Yue, Boci Peng, Xuanbo Fan, Jiaxin Guo, Qiankun Li, and Yan Zhang. Mem-t: Densifying rewards for long-horizon memory agents.arXiv preprint arXiv:2601.23014,
-
[26]
URLhttps://arxiv.org/abs/2512.18746
Guibin Zhang, Muxin Fu, Kun Wang, Guancheng Wan, Miao Yu, and Shuicheng YAN. G-memory: Tracing hierarchical memory for multi-agent systems. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025a. Guibin Zhang, Muxin Fu, and Shuicheng Yan. Memgen: Weaving generative latent memory for self-evolving agents.The Fourteenth Interna...
-
[27]
BERTScore: Evaluating Text Generation with BERT
URLhttps://arxiv.org/abs/1904.09675. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt- bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623,
work page internal anchor Pith review arXiv 1904
-
[28]
A simple yet strong baseline for long-term conversational memory of LLM agents, 2025
Sizhe Zhou and Jiawei Han. A simple yet strong baseline for long-term conversational memory of llm agents.arXiv preprint arXiv:2511.17208,
-
[29]
arXiv preprint arXiv:2602.16284 , year=
Adam Zweiger, Xinghong Fu, Han Guo, and Yoon Kim. Fast kv compaction via attention matching.arXiv preprint arXiv:2602.16284,
-
[30]
In this study, we employ its publicly available subset, which contains 10 high-quality, long conversations with 27.2 sessions and 20,756.2 tokens on average
is designed to evaluate long-term memory in long-context LLMs and RAG systems in multi-turn question-answering tasks. In this study, we employ its publicly available subset, which contains 10 high-quality, long conversations with 27.2 sessions and 20,756.2 tokens on average. The evaluation tasks consist of 1,986 queries 15 Preprint. Under review. Table 6:...
2025
-
[31]
It addresses scarce QA pairs and short dialogues by merging five consecutive sessions into a long-form conversation
is an enhanced long-dialogue benchmark reconstructed from MT-Bench+ (Lu et al., 2023). It addresses scarce QA pairs and short dialogues by merging five consecutive sessions into a long-form conversation. The dataset contains 11 conversations, averaging 4.9 sessions and approximately 19287.5 tokens. Unlike LoCoMo, it focuses exclusively on user-AI interact...
2023
-
[32]
and permuted language modeling from Xlnet (Yang et al., 2019), while addressing their key limitations. It captures dependencies among predicted tokens through permutation-based objectives and incorporates auxiliary position information to align pre-training more closely with downstream tasks, enabling better utilization of full sentence context. This meth...
2019
-
[33]
is a memory consolidation framework that organizes mem- ories into units of varying granularity and uses Gaussian Mixture Models to cluster 17 Preprint. Under review. Table 7: Retrieval Performance. Contriever is used as the default retriever for all methods except MPNet. Model Recall@3 NDCG@3 Recall@5 NDCG@5 Recall@10 NDCG@10 Time LoCoMo MPNet (2020) 45....
-
[34]
18 Preprint
Note that LongMTBench+ is excluded from this evaluation because it lacks retrieval ground truth. 18 Preprint. Under review. Table 8: QA Performance Comparison of Different Generators on LoCoMo with Contriever. Model 4o-J F1 BLEU4 Rouge1 Rouge2 RougeL BERTScore GPT-4o-mini-2024-07-18 Contriever (2021) 40.33 15.76 2.77 16.08 7.75 15.10 84.70 SeCom (2025) 43...
2024
-
[35]
Fused Historical Event
We observe similar analysis as in the main text. 20 Preprint. Under review. 25% 50% 75% 100% 0.25 0.37 0.50 0.62Recall@3 Turn Level Ours (a) LoCoMo, Contriever 25% 50% 75% 100% 0.25 0.35 0.45 0.56Recall@3 Turn Level Ours (b) LoCoMo,MPNet 25% 50% 75% 100% 0.25 0.34 0.44 0.53Recall@3 Turn Level Ours (c) LoCoMo,MiniLM 25% 50% 75% 100% 0.25 0.49 0.72 0.96Reca...
2024
-
[36]
GPT-4o-as-Judge I will give you a question, a reference answer, and a response from a model
to judge whether the model’s output matches the correct answer, as detailed below. GPT-4o-as-Judge I will give you a question, a reference answer, and a response from a model. Please answer <yes> if the response contains the reference answer. Otherwise, answer <no>. If the response is equivalent to the correct answer or contains all the intermediate steps...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.