Recognition: unknown
RPA-Check: A Multi-Stage Automated Framework for Evaluating Dynamic LLM-based Role-Playing Agents
Pith reviewed 2026-05-10 15:13 UTC · model grok-4.3
The pith
A four-step pipeline converts role-playing criteria into boolean checklists scored by an LLM judge to evaluate agent fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RPA-Check evaluates LLM role-playing agents by first defining high-level criteria, augmenting them into granular boolean indicators, applying semantic filtering to ensure no redundancy and full isolation, and then running an LLM-as-a-Judge step with chain-of-thought verification to score fidelity. When applied to several quantized models in a forensic training environment across five legal scenarios, the framework identifies an inverse relationship between parametric scale and consistency, with 8-9B models showing stronger performance than larger architectures affected by user-alignment bias.
What carries the argument
The RPA-Check pipeline that turns qualitative role requirements into non-redundant boolean indicators for automated LLM-based scoring.
If this is right
- The method can expose specific trade-offs between model size, reasoning depth, and long-term stability in agent behavior.
- Smaller instruction-tuned models can deliver higher procedural consistency than larger ones in constraints-heavy settings.
- It supplies a reproducible metric for comparing generative agents in specialized domains.
- Findings point to the value of targeted instruction tuning over raw parameter count for maintaining role fidelity.
Where Pith is reading between the lines
- Teams building interactive agents may achieve better reliability by selecting mid-sized tuned models rather than scaling up.
- The checklist approach could transfer to evaluating consistency in other long-horizon domains such as educational simulations.
- Combining the automated scores with occasional human review might further reduce judge bias in high-stakes uses.
Load-bearing premise
That an LLM judge using chain-of-thought reasoning can produce objective scores for role adherence without its own biases or missed failure modes.
What would settle it
A new set of role-playing tests in which larger models receive equal or higher consistency scores than smaller ones while avoiding sycophancy, or where the boolean indicators fail to flag a major observed breakdown in narrative stability.
Figures



read the original abstract
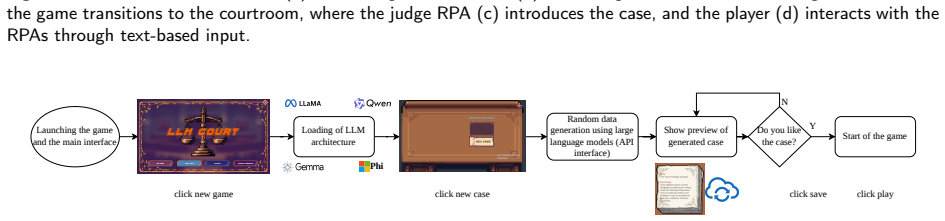
The rapid adoption of Large Language Models (LLMs) in interactive systems has enabled the creation of dynamic, open-ended Role-Playing Agents (RPAs). However, evaluating these agents remains a significant challenge, as standard NLP metrics fail to capture the nuances of role adherence, logical consistency, and long-term narrative stability. This paper introduces RPA-Check, a multi-stage automated evaluation framework designed to objectively assess the performance of LLM-based RPAs in complex, constraints-heavy environments. Our methodology is based on a four-step pipeline: (1) Dimension Definition, establishing high-level qualitative behavioral criteria; (2) Augmentation, where these requirements are expanded into granular boolean checklist indicators; (3) Semantic Filtering, to ensure indicator objectivity, no redundancy and agent isolation; and (4) LLM-as-a-Judge Evaluation, which employs chain-of-thought verification to score agent fidelity. We validate this framework by applying it to LLM Court, a serious game for forensic training involving several quantized local models. Experimental results across five distinct legal scenarios demonstrate the framework's ability to identify subtle trade-offs between model size, reasoning depth, and operational stability. Notably, the findings reveal an inverse relationship between parametric scale and procedural consistency, showing that smaller, adequately instruction-tuned models (8-9B) can outperform larger architectures prone to user-alignment bias or sycophancy. RPA-Check thus provides a standardized and reproducible metric for future research in generative agent evaluation within specialized domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RPA-Check, a four-stage automated evaluation framework for LLM-based role-playing agents consisting of (1) dimension definition, (2) augmentation to granular boolean checklist indicators, (3) semantic filtering for objectivity, non-redundancy and agent isolation, and (4) chain-of-thought LLM-as-a-Judge scoring of agent fidelity. The framework is validated by application to the LLM Court serious game across five legal scenarios with quantized local models, with the central empirical claim being an inverse relationship between parametric scale and procedural consistency, such that smaller instruction-tuned models (8-9B) outperform larger architectures due to reduced user-alignment bias or sycophancy.
Significance. If the reported trade-offs prove robust under independent validation, the framework could supply a reproducible, domain-specific metric for assessing role adherence and narrative stability in interactive agents, particularly in high-stakes settings such as forensic training. The scale-consistency observation, if not an artifact of the evaluation pipeline, would have practical implications for model selection in constrained role-play applications.
major comments (2)
- [Methodology, step 4] LLM-as-a-Judge Evaluation (step 4): The headline finding of an inverse relationship between model scale and consistency rests entirely on scores produced by an LLM judge with chain-of-thought. No details are supplied on the identity or size of the judge model, any ablation of alternative judges, or any correlation of the resulting scores against human expert ratings on the same boolean indicators. Without such grounding, systematic preferences in the judge could mechanically generate the reported sycophancy penalty on larger models.
- [Experiments and Results] Experimental results across five scenarios: The manuscript asserts that the results demonstrate subtle trade-offs and the inverse scale-consistency relationship, yet the provided text contains no tables of per-model scores, error bars, statistical significance tests, exclusion criteria, or raw indicator-level data. This absence prevents assessment of whether the 8-9B advantage is reliable or driven by a small number of scenarios.
minor comments (1)
- [Abstract] The abstract refers to 'quantized local models' without naming the specific model families, parameter counts, or quantization formats used; this information should be added to the experimental setup for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for improving the transparency and rigor of our work. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methodology, step 4] LLM-as-a-Judge Evaluation (step 4): The headline finding of an inverse relationship between model scale and consistency rests entirely on scores produced by an LLM judge with chain-of-thought. No details are supplied on the identity or size of the judge model, any ablation of alternative judges, or any correlation of the resulting scores against human expert ratings on the same boolean indicators. Without such grounding, systematic preferences in the judge could mechanically generate the reported sycophancy penalty on larger models.
Authors: We agree that additional details on the LLM judge are required for reproducibility and to mitigate concerns about bias. In the revised manuscript, we will explicitly specify the identity, size, and prompting configuration of the judge model (a distinct quantized model chosen for its balance of capability and consistency). We will also report any ablations on alternative judges conducted during development. The semantic filtering stage and boolean indicator design were intended to reduce subjectivity, and the chain-of-thought prompting was used to increase interpretability of scores. However, we did not perform a human correlation study in the original work. We will add a dedicated limitations subsection discussing potential judge biases and the observed scale-consistency pattern, while noting that results were consistent across all five scenarios. revision: partial
-
Referee: [Experiments and Results] Experimental results across five scenarios: The manuscript asserts that the results demonstrate subtle trade-offs and the inverse scale-consistency relationship, yet the provided text contains no tables of per-model scores, error bars, statistical significance tests, exclusion criteria, or raw indicator-level data. This absence prevents assessment of whether the 8-9B advantage is reliable or driven by a small number of scenarios.
Authors: We apologize for the insufficient detail in the results presentation. The revised manuscript will include new tables reporting per-model scores across all five legal scenarios, with error bars, statistical significance tests (e.g., paired t-tests or ANOVA for scale comparisons), and explicit exclusion criteria. Raw indicator-level data will be added to an appendix. These additions will allow independent assessment of whether the 8-9B advantage is robust or scenario-specific. revision: yes
- Providing a direct correlation between LLM judge scores and human expert ratings on the boolean indicators, as this would require a new human evaluation study not included in the original experiments.
Circularity Check
No circularity: framework and results are independently described
full rationale
The paper introduces RPA-Check as a novel four-stage pipeline (dimension definition, augmentation, semantic filtering, LLM-as-Judge) and reports experimental outcomes on five legal scenarios without any equations, fitted parameters renamed as predictions, or load-bearing self-citations. The inverse scale-consistency finding is presented as an empirical observation from applying the pipeline to quantized models, not derived by construction from prior author work or internal definitions. No self-definitional loops, ansatz smuggling, or renaming of known results appear in the abstract or described methodology. The derivation chain is self-contained as a methodological proposal validated by application.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-as-a-Judge equipped with chain-of-thought reasoning can produce objective fidelity scores for role-playing behavior
- ad hoc to paper Semantic filtering can eliminate redundancy and ensure agent isolation in the boolean checklist without losing coverage of role-adherence dimensions
invented entities (1)
-
RPA-Check four-stage pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL:https://arxiv.org/abs/2411.02714,arXiv:2411.02714
Game plot design with an llm-powered assistant: An empirical study with game designers. URL:https://arxiv.org/abs/2411.02714,arXiv:2411.02714. Ashby, T., Webb, B.K., Knapp, G., Searle, J., Fulda, N.,
-
[2]
Personalized quest and dialogue generation in role-playing games: A knowledge graph-andlanguagemodel-basedapproach,in:Proceedingsofthe2023CHIConferenceonHumanFactorsinComputingSystems,Association for Computing Machinery, New York, NY, USA. pp. 1–20. doi:10.1145/3544548.3581441. Bai, G., Chai, Z., Ling, C., Wang, S., Lu, J., Zhang, N., Shi, T., Yu, Z., Zhu...
-
[3]
URL:https://arxiv.org/abs/2401.00625, arXiv:2401.00625
Beyond efficiency: A systematic survey of resource-efficient large language models. URL:https://arxiv.org/abs/2401.00625, arXiv:2401.00625. Beattie,S.,Colbran,S.,2017. Fromphoenixwrighttoatticusfinch:Legalsimulationgamesasanaidtoself-representedlitigants,in:Proceedingsof the 26th International Conference on World Wide Web Companion, International World Wi...
-
[4]
Using llms to adapt serious games with educators in the loop, in: Schönbohm, A., Bellotti, F., Bucchiarone,A.,deRosa,F.,Ninaus,M.,Wang,A.,Wanick,V.,Dondio,P.(Eds.),GamesandLearningAlliance,SpringerNatureSwitzerland, Cham. pp. 68–77. doi:10.1007/978-3-031-78269-5_7. Chen,J.,Wang,X.,Xu,R.,Yuan,S.,Zhang,Y.,Shi,W.,Xie,J.,Li,S.,Yang,R.,Zhu,T.,Chen,A.,Li,N.,Che...
-
[5]
Chatbot arena: an open platform for evaluating llms by human preference, in: Proceedings of the 41st International Conference on Machine Learning, JMLR.org. pp. 8359–8388. doi:10.5555/3692070.3692401. Cox, S.R., Ooi, W.T.,
-
[6]
(Eds.), Chatbot Research and Design, Springer Nature Switzerland, Cham
Conversational interactions with npcs in llm-driven gaming: Guidelines from a content analysis of player feedback, in: Følstad, A., Araujo, T., Papadopoulos, S., Law, E.L.C., Luger, E., Goodwin, M., Hobert, S., Brandtzaeg, P.B. (Eds.), Chatbot Research and Design, Springer Nature Switzerland, Cham. pp. 167–184. doi:10.1007/978-3-031-54975-5_10. Fabbri,A.R...
-
[7]
Procedural content generation in games: A survey with insights on emerging llm integration, in: Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, pp. 167–178. doi:10.1609/aiide.v20i1.31877. Gopalakrishnan, K., Hedayatnia, B., Chen, Q., Gottardi, A., Kwatra, S., Venkatesh, A., Gabriel, R., Hakkani-Tur, D.,
-
[8]
URL:https://arxiv.org/abs/2308.11995,arXiv:2308.11995
Topical-chat: Towards knowledge-grounded open-domain conversations. URL:https://arxiv.org/abs/2308.11995,arXiv:2308.11995. R. Rosati et al.:Preprint submitted to ElsevierPage 32 of 34 RPA-Check: A Multi-Stage Automated Framework for Evaluating Dynamic LLM-based Role-Playing Agents Gu,J.,Jiang,X.,Shi,Z.,Tan,H.,Zhai,X.,Xu,C.,Li,W.,Shen,Y.,Ma,S.,Liu,H.,Wang,...
-
[9]
The Innovation , 101253doi:10.1016/j.xinn.2025.101253
A survey on llm-as-a-judge. The Innovation , 101253doi:10.1016/j.xinn.2025.101253. Gursesli, M.C., Taveekitworachai, P., Abdullah, F., Dewantoro, M.F., Lanata, A., Guazzini, A., Lê, V.K., Villars, A., Thawonmas, R.,
-
[10]
(Eds.), Interactive Storytelling, Springer Nature Switzerland, Cham
The chronicles of chatgpt: Generating and evaluating visual novel narratives on climate change through chatgpt, in: Holloway-Attaway, L., Murray, J.T. (Eds.), Interactive Storytelling, Springer Nature Switzerland, Cham. pp. 181–194. doi:10.1007/978-3-031-47658-7_16. Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.,
-
[11]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding. URL:https://arxiv.org/abs/2009.03300,arXiv:2009.03300. Hua, M., Raley, R.,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[12]
Scenecraft: Automating interactive narrative scene generation in digital games with large language models, in: Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, pp. 86–96. doi:10.1609/aiide.v19i1.27504. Lang, J., Guo, Z., Huang, S.,
-
[13]
A comprehensive study on quantization techniques for large language models, in: 2024 4th International Conference on Artificial Intelligence, Robotics, and Communication (ICAIRC), pp. 224–231. doi:10.1109/ICAIRC64177.2024.10899941. Lanzi, P.L.,Loiacono, D.,2023. Chatgpt andother largelanguage modelsas evolutionaryengines foronline interactivecollaborative...
-
[14]
Orak: A Foundational Benchmark for Training and Evaluating LLM Agents on Diverse Video Games
Orak: A foundational benchmark for training and evaluating llm agents on diverse video games. URL: https://arxiv.org/abs/2506.03610,arXiv:2506.03610. Pereira, J., Assumpcao, A., Lotufo, R.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh
Check-eval: A checklist-based approach for evaluating text quality. URL:https://arxiv.org/ abs/2407.14467,arXiv:2407.14467. Phan, L., Mazeika, M., Zou, A., Hendrycks, D.,
-
[16]
Textquests: How good are llms at text-based video games?, 2025
Textquests: How good are llms at text-based video games? URL:https://arxiv.org/ abs/2507.23701,arXiv:2507.23701. Salinas, A., Morstatter, F.,
-
[17]
The butterfly effect of altering prompts: How small changes and jailbreaks affect large language model performance,in:Ku,L.W.,Martins,A.,Srikumar,V.(Eds.),FindingsoftheAssociationforComputationalLinguistics:ACL2024,Association for Computational Linguistics, Bangkok, Thailand. pp. 4629–4651. doi:10.18653/v1/2024.findings-acl.275. SavannaDevelopments,2024.V...
-
[18]
Quantifying language models’ sensitivity to spurious features in prompt design or: how i learned to start worrying about prompt formatting, in: 12th International Conference on Learning Representations, ICLR 2024, pp. 1–29. R. Rosati et al.:Preprint submitted to ElsevierPage 33 of 34 RPA-Check: A Multi-Stage Automated Framework for Evaluating Dynamic LLM-...
-
[19]
Developing an immersive game-based learning platform with generative artificial intelligence and virtual reality technologies – “learningversevr”. Computers & Education: X Reality 4, 100069. doi:10.1016/j.cexr.2024.100069. Sweetser, P.,
-
[20]
Large language models and video games: A preliminary scoping review, in: Proceedings of the 6th ACM Conference on Conversational User Interfaces, Association for Computing Machinery, New York, NY, USA. pp. 1–8. doi:10.1145/3640794.3665582. Tódová,T.,2025. Aquestforinformation:Enhancinggame-basedlearningwithllm-drivennpcs,in:ProceedingsofCESCG2025:The29thC...
-
[21]
(Eds.), Interactive Storytelling, Springer Nature Switzerland, Cham
Llm-powered npcs, in: Reyes, M.C., Nack, F. (Eds.), Interactive Storytelling, Springer Nature Switzerland, Cham. pp. 171–189. doi:10.1007/978-3-032-12405-0_10. Wang, Y., Chen, J., Xiao, H.,
-
[22]
URL: https://arxiv.org/abs/2601.10122,arXiv:2601.10122
Role-playing agents driven by large language models: Current status, challenges, and future trends. URL: https://arxiv.org/abs/2601.10122,arXiv:2601.10122. Wei,J.,Wang,X.,Schuurmans,D.,Bosma,M.,Ichter,B.,Xia,F.,Chi,E.H.,Le,Q.V.,Zhou,D.,2022. Chain-of-thoughtpromptingelicitsreasoning in large language models, in: Proceedings of the 36th International Confe...
-
[23]
IEEE Transactions on Games , 1–15doi:10.1109/TG.2025.3564869
A systematic review of generative ai on game character creation: Applications, challenges, and future trends. IEEE Transactions on Games , 1–15doi:10.1109/TG.2025.3564869. Yang, T., Zhu, Y., Quan, X., Liu, C., Wang, Q.,
-
[24]
arXiv preprint arXiv:2502.03821 , year=
Psyplay: Personality-infused role-playing conversational agents. URL:https://arxiv. org/abs/2502.03821,arXiv:2502.03821. Zargham, N., Tonini, L., Alexandrovsky, D., Ruthven, E.G., Friehs, M.A., Dratzidis, L.T., Dänekas, B., Bikas, I., Nacke, L.E., Zebel, S., Malaka, R.,
-
[25]
International Journal of Human–Computer Interaction , 1–29doi:10.1080/10447318.2026.2620647
Dialogs with genai npcs: Exploring player interactions with speech agents in a vr game. International Journal of Human–Computer Interaction , 1–29doi:10.1080/10447318.2026.2620647. Zhao, Y., Pan, J., Dong, Y., Dong, T., Wang, G., Ying, F., Shen, Q., Cao, J.,
-
[26]
Language urban odyssey: A serious game for enhancing second language acquisition through large language models, in: Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, Association for Computing Machinery, New York, NY, USA. pp. 1–7. doi:10.1145/3613905.3651112. Zhu, Q., Zhao, R., Liang, B., Du, J., Gui, L., He, Y.,
-
[27]
Player*: Enhancing llm-based multi-agent communication and interaction in murder mystery games
Player*: Enhancing llm-based multi-agent communication and interaction in murder mystery games. URL:https://arxiv.org/abs/2404.17662,arXiv:2404.17662. Zhu, X., Chen, Y., Tian, H., Tao, C., Su, W., Yang, C., Huang, G., Li, B., Lu, L., Wang, X., Qiao, Y., Zhang, Z., Dai, J.,
-
[28]
Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory. URL: https://arxiv.org/abs/2305.17144,arXiv:2305.17144. Özkaya, S., Berrezueta-Guzman, S., Wagner, S.,
-
[29]
How llms are shaping the future of virtual reality. IEEE Access 13, 193335–193355. doi:10.1109/ACCESS.2025.3631594. R. Rosati et al.:Preprint submitted to ElsevierPage 34 of 34
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.