Recognition: 2 theorem links
· Lean TheoremSCORP: Scene-Consistent Multi-agent Diffusion Planning with Stable Online Reinforcement Post-Training for Cooperative Driving
Pith reviewed 2026-05-12 04:18 UTC · model grok-4.3
The pith
SCORP integrates a scene-conditioned diffusion architecture with a two-layer MDP and variance-gated policy optimization to enable stable closed-loop post-training for multi-agent cooperative driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SCORP shows that coupling inter-agent self-attention with dual-path scene conditioning produces more consistent joint trajectories, while the two-layer MDP formulation that merges the denoising chain with policy-environment interaction, together with co-designed dense rewards and VG-GRPO, yields stable online reinforcement post-training that improves closed-loop cooperative driving performance.
What carries the argument
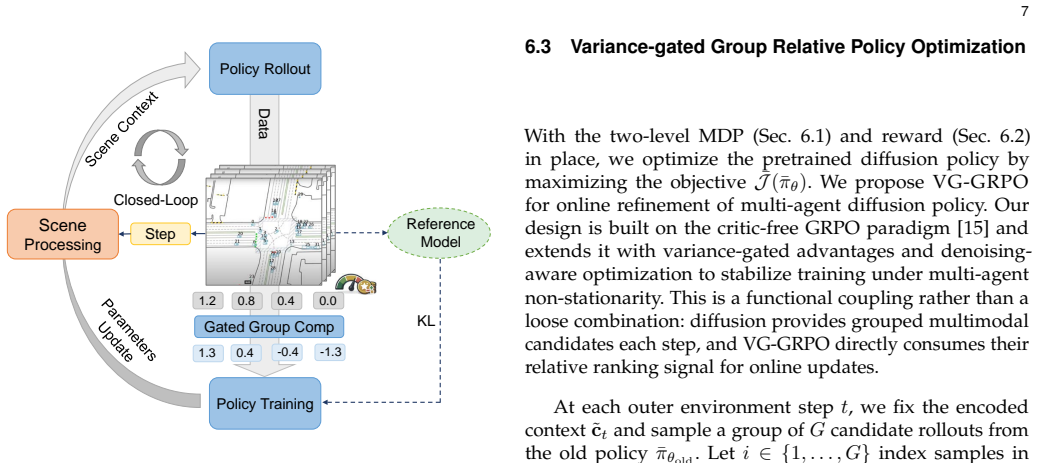
The two-layer Markov decision process (MDP) that integrates the reverse denoising chain with policy-environment interaction, paired with variance-gated group-relative policy optimization (VG-GRPO).
If this is right
- Joint trajectories gain improved scene consistency and road adherence through the dual-path conditioning mechanism.
- Closed-loop training proceeds without the advantage collapse and gradient instability typical in reactive multi-agent settings.
- Safety metrics improve by 10.47 to 28.26 percent and efficiency metrics by 1.70 to 7.22 percent over strong open-source baselines.
- The method produces larger and more consistent gains than alternative post-training approaches in both safety and traffic efficiency.
Where Pith is reading between the lines
- The two-layer MDP integration may transfer to other diffusion-based planners in robotics domains that require long-horizon consistency.
- Stable post-training of this form could narrow the gap between offline demonstration learning and online deployment in multi-agent systems.
- Similar variance-gating ideas might stabilize reinforcement fine-tuning for single-agent driving planners that currently suffer from distribution shift.
- The approach opens a path to parameter-efficient scaling of diffusion planners by reducing the need for separate offline and online stages.
Load-bearing premise
The two-layer MDP and VG-GRPO combination will maintain stable closed-loop training without advantage collapse or gradient instability in reactive multi-agent environments.
What would settle it
Training curves or final metrics on WOMD that show comparable advantage collapse, gradient instability, or lack of safety gains when using the two-layer MDP and VG-GRPO versus standard post-training methods would falsify the stability claim.
Figures




read the original abstract
Cooperative driving is a safety- and efficiency-critical task that requires the coordination of diverse, interaction-realistic multi-agent trajectories. Although existing diffusion-based methods can capture multimodal behaviors from demonstrations, they often exhibit weak scene consistency and poor alignment with closed-loop cooperative objectives. This makes post-training necessary for further improvement, yet achieving stable online post-training in reactive multi-agent environments remains challenging. In this paper, we propose SCORP, a scene-consistent multi-agent diffusion planner with stable online reinforcement learning (RL) post-training for cooperative driving. For pre-training, we develop a scene-conditioned multi-agent denoising architecture that couples inter-agent self-attention with a dual-path conditioning mechanism: cross-attention provides direct scene-information injection, while AdaLN-Zero enables additional flexible and stable conditional modulation, thereby improving the scene consistency and road adherence of joint trajectories. For post-training, we formulate a two-layer Markov decision process (MDP) that explicitly integrates the reverse denoising chain with policy-environment interaction. We further co-design dense, well-shaped planning rewards and variance-gated group-relative policy optimization (VG-GRPO) to mitigate advantage collapse and gradient instability during closed-loop training. Extensive experiments show that SCORP outperforms strong open-source baselines on WOMD, with 10.47%-28.26% and 1.70%-7.22% improvements in core safety and efficiency metrics, respectively. Moreover, compared with alternative post-training methods, SCORP delivers significant and consistent gains in both driving safety and traffic efficiency, highlighting stable and sustained advances in closed-loop cooperative driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SCORP, a scene-consistent multi-agent diffusion planner for cooperative driving. Pre-training uses a scene-conditioned denoising architecture with inter-agent self-attention and dual-path conditioning via cross-attention and AdaLN-Zero to improve joint trajectory consistency. Post-training formulates a two-layer MDP integrating the reverse denoising chain with policy-environment interaction, co-designed with dense shaped rewards and variance-gated group-relative policy optimization (VG-GRPO) to mitigate advantage collapse and instability. On WOMD, it reports 10.47%-28.26% gains in safety metrics and 1.70%-7.22% in efficiency metrics over baselines, plus consistent advantages over alternative post-training methods.
Significance. If the empirical results hold under rigorous scrutiny, this represents a useful engineering advance in combining diffusion-based trajectory generation with online RL for multi-agent driving. The dual conditioning mechanism and VG-GRPO co-design directly target known issues of scene inconsistency and training instability in closed-loop settings. The concrete quantitative comparisons on a standard benchmark provide a clear basis for assessing practical impact in cooperative autonomous driving.
major comments (2)
- Abstract: The reported performance improvements (10.47%-28.26% safety, 1.70%-7.22% efficiency) and claims of stable closed-loop gains are presented as high-level summaries without ablations, error bars, data-split details, or statistical significance tests. This is load-bearing for the central claim that the two-layer MDP, dense rewards, and VG-GRPO produce stable post-training gains, as it prevents verification of causal contributions from each component.
- Two-layer MDP formulation (post-training section): The integration of the reverse denoising chain with policy-environment interaction lacks an explicit mechanism or analysis for synchronizing discrete denoising steps with continuous state changes from other agents' simultaneous actions in reactive multi-agent environments. This risks inconsistent advantage signals or delayed feedback, directly bearing on the stability claim despite the introduction of variance gating.
minor comments (1)
- Abstract: The acronym VG-GRPO is introduced without an immediate parenthetical expansion, which could be clarified for readers encountering the work for the first time.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential engineering contribution of combining scene-consistent diffusion planning with stable online RL post-training. We address each major comment below and will incorporate revisions to improve clarity and verifiability.
read point-by-point responses
-
Referee: Abstract: The reported performance improvements (10.47%-28.26% safety, 1.70%-7.22% efficiency) and claims of stable closed-loop gains are presented as high-level summaries without ablations, error bars, data-split details, or statistical significance tests. This is load-bearing for the central claim that the two-layer MDP, dense rewards, and VG-GRPO produce stable post-training gains, as it prevents verification of causal contributions from each component.
Authors: We agree that the abstract provides only high-level numerical summaries and does not contain ablations, error bars, or statistical details. These elements appear in the experimental sections (with component-wise ablations on the two-layer MDP and VG-GRPO, tables reporting means and standard deviations on the WOMD validation split). To strengthen verifiability of causal contributions directly in the abstract, we will revise it to briefly reference the key ablation outcomes and the stability improvements from VG-GRPO while remaining within length limits. We will also ensure all main-result tables explicitly note the data split and include error bars or standard deviations. revision: yes
-
Referee: Two-layer MDP formulation (post-training section): The integration of the reverse denoising chain with policy-environment interaction lacks an explicit mechanism or analysis for synchronizing discrete denoising steps with continuous state changes from other agents' simultaneous actions in reactive multi-agent environments. This risks inconsistent advantage signals or delayed feedback, directly bearing on the stability claim despite the introduction of variance gating.
Authors: The two-layer MDP treats each denoising step as a discrete policy action that produces a trajectory increment, with the environment advancing all agents' states at the corresponding planning horizon; VG-GRPO then computes group-relative advantages to dampen variance from simultaneous multi-agent actions. We acknowledge that the current text does not provide an explicit timing diagram or pseudocode for the synchronization loop. We will add a dedicated paragraph plus a figure in the revised post-training section that details the alignment between discrete denoising timesteps and continuous environment updates, including how advantage signals are computed at each step to avoid delayed feedback. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper is an empirical engineering contribution describing a scene-conditioned diffusion architecture for pre-training and a two-layer MDP formulation integrating denoising with environment interaction for post-training, along with co-designed rewards and VG-GRPO. No load-bearing equations, predictions, or first-principles results are presented that reduce by construction to fitted inputs, self-definitions, or self-citation chains. Performance gains are reported from experiments on the WOMD dataset and are independently falsifiable, with the central claims resting on architectural novelty and empirical validation rather than tautological reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward shaping weights
axioms (2)
- ad hoc to paper The reverse denoising process can be directly integrated into a two-layer MDP for closed-loop policy interaction
- domain assumption Inter-agent self-attention combined with dual-path scene conditioning produces scene-consistent joint trajectories
invented entities (1)
-
VG-GRPO
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe formulate a two-level MDP that explicitly integrates the reverse denoising chain with policy-environment interaction... variance-gated group-relative policy optimization (VG-GRPO)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearAdaLN-Zero adaptive modulation mechanism in conjunction with cross-attention... dual-path scene conditioning
Reference graph
Works this paper leans on
-
[1]
Real-time cooperative vehicle coordination at unsignalized road intersections,
J. Luo, T. Zhang, R. Hao, D. Li, C. Chen, Z. Na, and Q. Zhang, “Real-time cooperative vehicle coordination at unsignalized road intersections,”IEEE Trans. Intell. Transp. Syst., vol. 24, no. 5, pp. 5390–5405, 2023
work page 2023
-
[2]
A robust cooperative vehicle coordination framework for intersection crossing,
H. Bai, J. Luo, H. Li, X. Zhao, and Y. Wang, “A robust cooperative vehicle coordination framework for intersection crossing,”IEEE Trans. Veh. Technol., 2025
work page 2025
-
[3]
N. Nayakanti, R. Al-Rfou, A. Zhou, K. Goel, K. S. Refaat, and B. Sapp, “Wayformer: Motion forecasting via simple and efficient attention networks,”arXiv preprint arXiv:2207.05844, 2022
-
[4]
Planning with diffusion for flexible behavior synthesis,
M. Janner, Y. Du, J. Tenenbaum, and S. Levine, “Planning with diffusion for flexible behavior synthesis,” inProc. Int. Conf. Mach. Learn. (ICML). PMLR, 2022, pp. 9902–9915. 12
work page 2022
-
[5]
arXiv preprint arXiv:2501.15564 , year =
Y. Zheng, R. Liang, K. Zheng, J. Zheng, L. Mao, J. Li, W. Gu, R. Ai, S. E. Li, X. Zhanet al., “Diffusion-based planning for autonomous driving with flexible guidance,”arXiv preprint arXiv:2501.15564, 2025
-
[6]
Ver- satile behavior diffusion for generalized traffic agent simulation,
Z. Huang, Z. Zhang, A. Vaidya, Y. Chen, C. Lv, and J. F. Fisac, “Ver- satile behavior diffusion for generalized traffic agent simulation,” arXiv preprint arXiv:2404.02524, 2024
-
[7]
MDG: Masked denoising generation for multi-agent behavior modeling in traffic environments,
Z. Huang, Z. Zhou, T. Cai, Y. Zhang, and J. Ma, “MDG: Masked denoising generation for multi-agent behavior modeling in traffic environments,”arXiv preprint arXiv:2511.17496, 2025
-
[8]
Y. Lu, J. Fu, G. Tucker, X. Pan, E. Bronstein, R. Roelofs, B. Sapp, B. White, A. Faust, S. Whitesonet al., “Imitation is not enough: Robustifying imitation with reinforcement learning for challenging driving scenarios,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS). IEEE, 2023, pp. 7553–7560
work page 2023
-
[9]
PlannerRFT: Reinforcing diffusion plan- ners through closed-loop and sample-efficient fine-tuning,
H. Li, T. Li, J. Yang, H. Tian, C. Wang, L. Shi, M. Shang, Z. Lin, G. Wu, Z. Haoet al., “PlannerRFT: Reinforcing diffusion plan- ners through closed-loop and sample-efficient fine-tuning,”arXiv preprint arXiv:2601.12901, 2026
-
[10]
H. Gao, S. Chen, B. Jiang, B. Liao, Y. Shi, X. Guo, Y. Pu, H. Yin, X. Li, X. Zhanget al., “RAD: Training an end-to-end driving policy via large-scale 3DGS-based reinforcement learning,”arXiv preprint arXiv:2502.13144, 2025
-
[11]
Z. Huang, X. Weng, M. Igl, Y. Chen, Y. Cao, B. Ivanovic, M. Pavone, and C. Lv, “Gen-drive: Enhancing diffusion generative driving policies with reward modeling and reinforcement learning fine- tuning,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA). IEEE, 2025, pp. 3445–3451
work page 2025
-
[12]
Improving agent behaviors with RL fine-tuning for autonomous driving,
Z. Peng, W. Luo, Y. Lu, T. Shen, C. Gulino, A. Seff, and J. Fu, “Improving agent behaviors with RL fine-tuning for autonomous driving,” inProc. Eur. Conf. Comput. Vis. (ECCV). Springer, 2024, pp. 165–181
work page 2024
-
[13]
Fine-tuning generative trajectory model with reinforcement learning from human feedback,
D. Li, J. Ren, Y. Wang, X. Wen, P . Li, L. Xu, K. Zhan, Z. Xia, P . Jia, X. Langet al., “Fine-tuning generative trajectory model with reinforcement learning from human feedback,”arXiv e-prints, 2025
work page 2025
-
[14]
Y. Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wanget al., “RecogDrive: A reinforced cognitive framework for end-to-end autonomous driving,”arXiv preprint arXiv:2506.08052, 2025
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, P . Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y. Yuan, X. Zuo, Y. Yue, W. Dai, T. Fan, G. Liu, L. Liuet al., “DAPO: An open-source LLM reinforcement learning system at scale,”arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
K. Zhang, Y. Zuo, B. He, Y. Sun, R. Liu, C. Jiang, Y. Fan, K. Tian, G. Jia, P . Liet al., “A survey of reinforcement learning for large reasoning models,”arXiv preprint arXiv:2509.08827, 2025
-
[18]
Scalable diffusion models with transform- ers,
W. Peebles and S. Xie, “Scalable diffusion models with transform- ers,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 4195–4205
work page 2023
-
[19]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
S. Chen, B. Jiang, H. Gao, B. Liao, Q. Xu, Q. Zhang, C. Huang, W. Liu, and X. Wang, “VADv2: End-to-end vectorized autonomous driving via probabilistic planning,”arXiv preprint arXiv:2402.13243, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
MTR++: Multi-agent motion prediction with symmetric scene modeling and guided intention querying,
S. Shi, L. Jiang, D. Dai, and B. Schiele, “MTR++: Multi-agent motion prediction with symmetric scene modeling and guided intention querying,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 5, pp. 3955–3971, 2024
work page 2024
-
[21]
Z. Zhou, Z. Wen, J. Wang, Y.-H. Li, and Y.-K. Huang, “QCNext: A next-generation framework for joint multi-agent trajectory prediction,”arXiv preprint arXiv:2306.10508, 2023
-
[22]
DenseTNT: End-to-end trajectory prediction from dense goal sets,
J. Gu, C. Sun, and H. Zhao, “DenseTNT: End-to-end trajectory prediction from dense goal sets,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 15 303–15 312
work page 2021
-
[23]
Multipath++: Efficient information fusion and trajectory aggregation for behavior prediction,
B. Varadarajan, A. Hefny, A. Srivastava, K. S. Refaat, N. Nayakanti, A. Cornman, K. Chen, B. Douillard, C. P . Lam, D. Anguelov et al., “Multipath++: Efficient information fusion and trajectory aggregation for behavior prediction,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA). IEEE, 2022, pp. 7814–7821
work page 2022
-
[24]
Smart: Scalable multi-agent real-time motion generation via next-token prediction,
W. Wu, X. Feng, Z. Gao, and Y. Kan, “Smart: Scalable multi-agent real-time motion generation via next-token prediction,”Adv. Neural Inf. Process. Syst., vol. 37, pp. 114 048–114 071, 2024
work page 2024
-
[25]
MotionLM: Multi-agent motion forecasting as language modeling,
A. Seff, B. Cera, D. Chen, M. Ng, A. Zhou, N. Nayakanti, K. S. Refaat, R. Al-Rfou, and B. Sapp, “MotionLM: Multi-agent motion forecasting as language modeling,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 8579–8590
work page 2023
-
[26]
BehaviorGPT: Smart agent simulation for autonomous driving with next-patch prediction,
Z. Zhou, H. Haibo, X. Chen, J. Wang, N. Guan, K. Wu, Y.-H. Li, Y.-K. Huang, and C. J. Xue, “BehaviorGPT: Smart agent simulation for autonomous driving with next-patch prediction,”Adv. Neural Inf. Process. Syst., vol. 37, pp. 79 597–79 617, 2024
work page 2024
-
[27]
Agentformer: Agent- aware transformers for socio-temporal multi-agent forecasting,
Y. Yuan, X. Weng, Y. Ou, and K. M. Kitani, “Agentformer: Agent- aware transformers for socio-temporal multi-agent forecasting,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 9813–9823
work page 2021
-
[28]
SceneDiffuser: Efficient and controllable driving simulation initialization and rollout,
M. Jiang, Y. Bai, A. Cornman, C. Davis, X. Huang, H. Jeon, S. Kulshrestha, J. Lambert, S. Li, X. Zhouet al., “SceneDiffuser: Efficient and controllable driving simulation initialization and rollout,”Adv. Neural Inf. Process. Syst., vol. 37, pp. 55 729–55 760, 2024
work page 2024
-
[29]
MotionDiffuser: Controllable multi-agent motion prediction using diffusion,
C. Jiang, A. Cornman, C. Park, B. Sapp, Y. Zhou, D. Anguelovet al., “MotionDiffuser: Controllable multi-agent motion prediction using diffusion,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 9644–9653
work page 2023
-
[30]
Guided conditional diffusion for controllable traffic simulation,
Z. Zhong, D. Rempe, D. Xu, Y. Chen, S. Veer, T. Che, B. Ray, and M. Pavone, “Guided conditional diffusion for controllable traffic simulation,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA). IEEE, 2023, pp. 3560–3566
work page 2023
-
[31]
Language-guided traffic simulation via scene-level diffusion,
Z. Zhong, D. Rempe, Y. Chen, B. Ivanovic, Y. Cao, D. Xu, M. Pavone, and B. Ray, “Language-guided traffic simulation via scene-level diffusion,” inProc. Conf. Robot Learn. (CoRL). PMLR, 2023, pp. 144–177
work page 2023
-
[32]
D. Zhang, J. Liang, K. Guo, S. Lu, Q. Wang, R. Xiong, Z. Miao, and Y. Wang, “Carplanner: Consistent auto-regressive trajectory planning for large-scale reinforcement learning in autonomous driving,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 17 239–17 248
work page 2025
-
[33]
B. Jiang, S. Chen, Q. Zhang, W. Liu, and X. Wang, “AlphaDrive: Unleashing the power of VLMs in autonomous driving via rein- forcement learning and reasoning,”arXiv preprint arXiv:2503.07608, 2025
-
[34]
Q. Li, X. Jia, S. Wang, and J. Yan, “Think2Drive: Efficient reinforce- ment learning by thinking with latent world model for autonomous driving (in CARLA-v2),” inProc. Eur. Conf. Comput. Vis. (ECCV). Springer, 2024, pp. 142–158
work page 2024
-
[35]
Plan-R1: Safe and feasible trajectory planning as language modeling,
X. Tang, M. Kan, S. Shan, and X. Chen, “Plan-R1: Safe and feasible trajectory planning as language modeling,”arXiv preprint arXiv:2505.17659, 2025
-
[36]
Improved denoising diffusion probabilistic models,
A. Q. Nichol and P . Dhariwal, “Improved denoising diffusion probabilistic models,” inProc. Int. Conf. Mach. Learn. (ICML). PMLR, 2021, pp. 8162–8171
work page 2021
-
[37]
Training diffusion models with reinforcement learning,
K. Black, M. Janner, Y. Du, I. Kostrikov, and S. Levine, “Training diffusion models with reinforcement learning,” inProc. ICML 2023 Workshop on Structured Probabilistic Inference and Generative Modeling, 2023
work page 2023
-
[38]
Diffusion policy policy optimization,
A. Z. Ren, J. Lidard, L. L. Ankile, A. Simeonov, P . Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz, “Diffusion policy policy optimization,” inProc. CoRL 2024 Workshop on Mastering Robot Manipulation in a World of Abundant Data, 2024
work page 2024
-
[39]
J. Schulman, “Approximating KL divergence,”http://joschu.net/blog/ kl-approx.html, 2020
work page 2020
-
[40]
Large scale interactive motion forecasting for autonomous driving: The Waymo Open Motion Dataset,
S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y. Chai, B. Sapp, C. R. Qi, Y. Zhouet al., “Large scale interactive motion forecasting for autonomous driving: The Waymo Open Motion Dataset,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 9710–9719
work page 2021
-
[41]
Signal-to-noise ratio analysis of policy gradient algorithms,
J. Roberts and R. Tedrake, “Signal-to-noise ratio analysis of policy gradient algorithms,”Advances in neural information processing systems, vol. 21, 2008
work page 2008
-
[42]
arXiv preprint arXiv:2602.03025 , year=
H. Zhong, J. Zhai, L. Song, J. Bian, Q. Liu, and T. Tan, “Rc-grpo: Reward-conditioned group relative policy optimization for multi- turn tool calling agents,”arXiv preprint arXiv:2602.03025, 2026
-
[43]
Z. Zhang, C. Sakaridis, and L. Van Gool, “TrafficBots V1.5: Traffic simulation via conditional VAEs and transformers with relative pose encoding,”arXiv preprint arXiv:2406.10898, 2024
-
[44]
Closed-loop supervised fine-tuning of tokenized traffic models,
Z. Zhang, P . Karkus, M. Igl, W. Ding, Y. Chen, B. Ivanovic, and M. Pavone, “Closed-loop supervised fine-tuning of tokenized traffic models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 5422–5432
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.