When Reasoning Models Hurt Behavioral Simulation: A Solver-Sampler Mismatch in Multi-Agent LLM Negotiation
Pith reviewed 2026-05-10 15:50 UTC · model grok-4.3
The pith
Reasoning-enhanced language models often default to authority-heavy outcomes in multi-agent negotiations instead of sampling diverse behaviors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
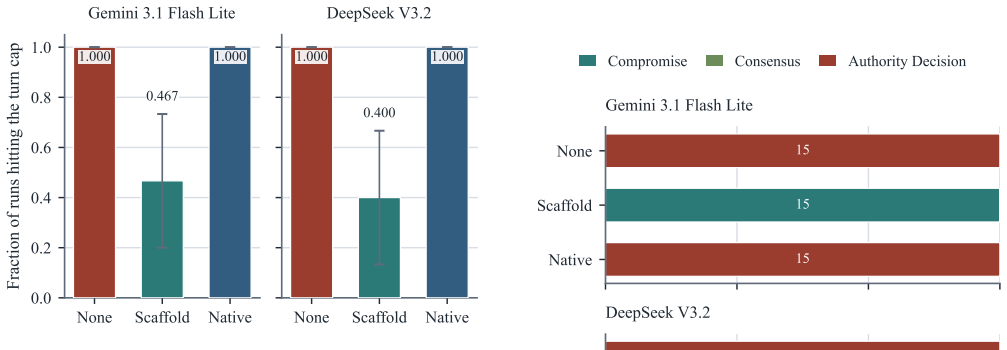
The paper establishes a solver-sampler mismatch: models whose reasoning strength improves strategic solving tend to collapse toward authority-dominated results in multi-agent negotiation rather than generating varied behavioral samples, with native reasoning versions reaching authority decisions in 15 of 15 or 45 of 45 runs across environments despite measurable concession and entropy, while only the negotiation-structured scaffold condition consistently produces negotiated outcomes.
What carries the argument
The solver-sampler mismatch, which distinguishes a model's capacity for strategic problem solving from its ability to sample representative agent behaviors within a fixed negotiation grammar.
If this is right
- Models selected for institutional behavioral simulation must be qualified separately for sampling ability rather than by reasoning benchmarks alone.
- Native reasoning increases the rate of authority decisions across different authority structures in trading and emergency management settings.
- Neither larger output space nor added generic private state overcomes the sampler failure in these negotiation tasks.
- A negotiation-structured scaffold is required to shift outcomes away from authority defaults toward more open agreements.
Where Pith is reading between the lines
- The same mismatch could appear in other multi-agent policy simulations, requiring role-specific evaluation instead of general capability tests.
- Model training or prompting for behavioral roles may need objectives distinct from those used to boost reasoning performance.
- Widespread use of reasoning-optimized models in institutional modeling could systematically tilt simulated outcomes toward centralized authority.
Load-bearing premise
The three chosen negotiation environments adequately proxy the behavioral simulation tasks relevant to institutional policy, and the observed outcomes primarily reflect sampler limitations rather than prompt or implementation artifacts.
What would settle it
A single run in one of the tested environments where a native-reasoning model produces a clear majority of negotiated, non-authority outcomes without a structured scaffold would directly challenge the mismatch claim.
Figures




read the original abstract
Behavioral simulation and strategic problem solving are different tasks. Large language models are increasingly explored as agents in policy-facing institutional simulations, but stronger reasoning need not improve behavioral sampling. We study this solver-sampler mismatch in three multi-agent negotiation environments: two trading-limits scenarios with different authority structures and a grid-curtailment case in emergency electricity management. Across two primary model families, native reasoning and often no reflection collapse toward authority-heavy outcomes. The sharpest case is DeepSeek native reasoning in the grid-curtailment transfer: it reaches action entropy 1.256 and a concession-arc rate of 0.933, yet still ends in authority decision in 15 of 15 runs. A direct OpenAI extension shows the same pressure at provider breadth: GPT-5.2 native reasoning ends in authority decisions in 45 of 45 runs across the three environments. Budget-matched no-reflection controls and orthogonal private-state controls remain rigid, while the negotiation-structured scaffold condition is the only condition that consistently opens negotiated outcomes. These diagnostics are failure screens within a fixed negotiation grammar, not evidence of external behavioral realism or policy-forecasting validity. The results show that neither more output space nor generic extra private state rescues solver-like sampler failure. For institutional simulation, solver strength and sampler qualification are different objectives: models should be evaluated for the behavioral role they are meant to play, not only for strategic capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit a solver-sampler mismatch in multi-agent negotiation simulations: stronger native reasoning (and often no reflection) collapses to authority-heavy terminal outcomes rather than diverse behavioral negotiations. This is shown across three fixed-grammar environments (two trading-limits variants differing in authority structure, plus grid-curtailment emergency management) using DeepSeek and GPT-5.2 families. Key evidence includes high concession-arc rates (e.g., 0.933) paired with 15/15 or 45/45 authority decisions under native reasoning, while a negotiation-structured scaffold opens negotiated outcomes; budget-matched no-reflection and orthogonal private-state controls remain rigid. The authors conclude that reasoning strength and behavioral sampling are distinct objectives, and that neither expanded output space nor generic private state mitigates sampler failure. All results are presented as diagnostics within the fixed grammar, without external validity claims.
Significance. If the central interpretation holds, the result is significant for the expanding use of LLMs as agents in institutional and policy-facing simulations. It supplies a concrete diagnostic distinction between solver capability and sampler fidelity, supported by controlled comparisons across model families, reflection conditions, and interventions (scaffold vs. private-state). The explicit framing as grammar-internal failure screens is a strength that avoids overclaiming behavioral realism. This could shift evaluation practices away from reasoning benchmarks alone when selecting models for multi-agent behavioral roles.
major comments (2)
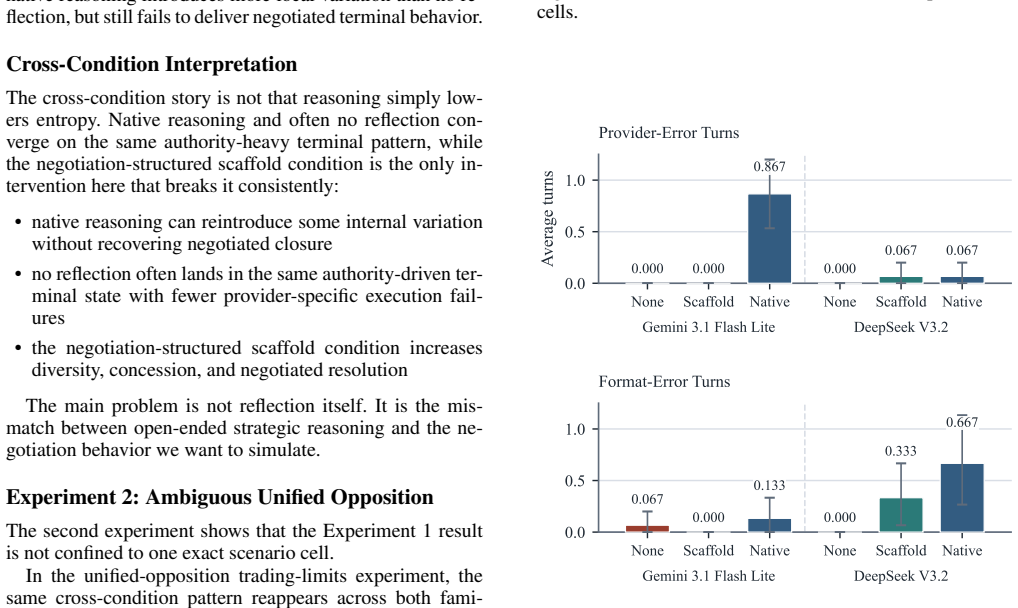
- [Grid-curtailment case and trading-limits variants] Grid-curtailment environment and trading-limits variants: the claim that authority decisions indicate sampler failure (rather than correct equilibrium sampling) is load-bearing for the mismatch thesis, yet the manuscript does not report whether authority-decision frequency tracks the presence or strength of authority options across the three environments. The skeptic concern applies directly: in emergency electricity management, unilateral authority may be the only stable terminal state permitted by the grammar, so 15/15 authority outcomes with high concession arcs could be rational rather than a collapse. The paper should add explicit enumeration of feasible terminal states and outcome frequencies per environment to isolate sampler limitations from grammar constraints.
- [Results (authority outcome counts)] Methods and results sections: counts such as 15/15 and 45/45 are reported without statistical tests (binomial or chi-squared against uniform/random baselines), variance across random seeds, or confidence intervals. This weakens the evidence that the observed rigidity is systematic rather than run-specific sampling variability, especially given the small number of runs. Adding these would make the central empirical pattern more robust.
minor comments (2)
- [Results] Action entropy is reported as 1.256 for one condition; clarify whether this is normalized Shannon entropy, absolute, or scaled to the action space size, and provide the formula or computation details.
- [Introduction] The manuscript would benefit from a short related-work paragraph situating the solver-sampler distinction against prior LLM-agent negotiation studies (e.g., those using game-theoretic or reinforcement-learning baselines).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. The suggestions to strengthen the presentation of grammar constraints and to add statistical support for the outcome counts are appreciated. We respond to each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: Grid-curtailment environment and trading-limits variants: the claim that authority decisions indicate sampler failure (rather than correct equilibrium sampling) is load-bearing for the mismatch thesis, yet the manuscript does not report whether authority-decision frequency tracks the presence or strength of authority options across the three environments. The skeptic concern applies directly: in emergency electricity management, unilateral authority may be the only stable terminal state permitted by the grammar, so 15/15 authority outcomes with high concession arcs could be rational rather than a collapse. The paper should add explicit enumeration of feasible terminal states and outcome frequencies per environment to isolate sampler limitations from grammar constraints.
Authors: We agree that explicitly enumerating feasible terminal states per environment will help isolate sampler behavior from grammar constraints. The manuscript already describes the three environments as having distinct authority structures (two trading-limits variants plus the grid-curtailment emergency case) and shows that the negotiation scaffold produces non-authority outcomes within the same fixed grammars. To address the concern directly, we will add a table in the methods or results section that lists all terminal states permitted by each environment's grammar and reports the observed frequencies under every experimental condition. This will demonstrate that negotiated outcomes remain feasible (as evidenced by the scaffold results) while native reasoning collapses to authority across environments that differ in authority strength. revision: yes
-
Referee: Methods and results sections: counts such as 15/15 and 45/45 are reported without statistical tests (binomial or chi-squared against uniform/random baselines), variance across random seeds, or confidence intervals. This weakens the evidence that the observed rigidity is systematic rather than run-specific sampling variability, especially given the small number of runs. Adding these would make the central empirical pattern more robust.
Authors: We acknowledge that statistical tests and variability measures would make the evidence more robust. The reported counts reflect consistent collapse across model families and environments, with the scaffold condition providing a clear contrast. In the revision we will add binomial tests against a uniform baseline over feasible terminals and report associated p-values. For variance and confidence intervals, we will include results from additional random seeds where they exist in our logs; however, not every condition was originally run with explicit multi-seed variation. The core pattern remains supported by the cross-condition and cross-model consistency, but we will incorporate the requested statistical elements to the extent feasible. revision: partial
Circularity Check
No circularity: empirical counts in fixed environments
full rationale
The paper reports direct experimental outcomes (authority-decision frequencies, concession-arc rates, action entropy) from runs in three fixed negotiation environments with controlled conditions (native reasoning, no-reflection, private-state, scaffold). No equations, fitted parameters, or derivations are presented as predictions. Central claims rest on observed frequencies rather than any self-definitional mapping, self-citation chain, or renaming of known results. The analysis is self-contained against the reported runs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The trading-limits and grid-curtailment negotiation environments serve as valid proxies for policy-facing institutional behavioral simulations.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Abdelnabi, S.; Gomaa, A.; Sivaprasad, S.; Sch \"o nherr, L.; and Fritz, M. 2024. LLM -Deliberation: Evaluating LLM s with Interactive Multi-Agent Negotiation Games. In The Twelfth International Conference on Learning Representations
work page 2024
-
[4]
Aher, G. V.; Arriaga, R. I.; and Kalai, A. T. 2023. Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, 337--371
work page 2023
-
[5]
Akata, E.; Coda-Forno, J.; Oh, S. J.; Bethge, M.; and Schulz, E. 2025. Playing Repeated Games with Large Language Models. Nature Human Behaviour, 9: 1380--1390
work page 2025
-
[6]
Bonabeau, E. 2002. Agent-Based Modeling: Methods and Techniques for Simulating Human Systems. Proceedings of the National Academy of Sciences, 99(suppl\_3): 7280--7287
work page 2002
- [7]
- [8]
-
[9]
Collins, A. J.; Koehler, M.; and Lynch, C. J. 2024. Methods That Support the Validation of Agent-Based Models: An Overview and Discussion. Journal of Artificial Societies and Social Simulation, 27(1): 11
work page 2024
-
[10]
Epstein, J. M.; and Axtell, R. 1996. Growing Artificial Societies: Social Science from the Bottom Up. Brookings Institution Press and MIT Press
work page 1996
-
[11]
Fan, C.; Chen, J.; Jin, Y.; and He, H. 2024. Can Large Language Models Serve as Rational Players in Game Theory? A Systematic Analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 17960--17967
work page 2024
-
[12]
Horton, J. J. 2023. Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus? Technical Report 31122, National Bureau of Economic Research
work page 2023
- [13]
-
[14]
Kahneman, D. 2003. Maps of Bounded Rationality: Psychology for Behavioral Economics. American Economic Review, 93(5): 1449--1475
work page 2003
-
[15]
Larooij, M.; and T \"o rnberg, P. 2026. Validation Is the Central Challenge for Generative Social Simulation: A Critical Review of LLMs in Agent-Based Modeling. Artificial Intelligence Review, 59: 15
work page 2026
- [16]
- [17]
- [18]
-
[19]
Manoranjan, V.; and Gaikwad, S. N. 2026. When Identity Overrides Incentives: Representational Choices as Governance Decisions in Multi-Agent LLM Systems. arXiv preprint arXiv:2601.10102
work page internal anchor Pith review arXiv 2026
-
[20]
Nath, A.; VanderHoeven, H.; and Krishnaswamy, N. 2026. CRAFT: Grounded Multi-Agent Coordination Under Partial Information. arXiv preprint arXiv:2603.25268
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Park, J. S.; O'Brien, J. C.; Cai, C. J.; Ringel Morris, M.; Liang, P.; and Bernstein, M. S. 2023. Generative Agents: Interactive Simulacra of Human Behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2:1--2:22
work page 2023
-
[22]
Pruitt, D. G. 1981. Negotiation Behavior. Academic Press
work page 1981
-
[23]
Raiffa, H. 1982. The Art and Science of Negotiation. Harvard University Press
work page 1982
-
[24]
Rubinstein, A. 1998. Modeling Bounded Rationality. MIT Press
work page 1998
-
[25]
Simon, H. A. 1955. A Behavioral Model of Rational Choice. Quarterly Journal of Economics, 69(1): 99--118
work page 1955
-
[26]
A.; Garcia-Gathright, J.; Olteanu, A.; Pangakis, N
Wallach, H.; Desai, M.; Cooper, A. A.; Garcia-Gathright, J.; Olteanu, A.; Pangakis, N. J.; Reed, S.; Sheng, E.; Vann, D.; Vaughan, J. W.; Vogel, M.; Washington, H.; and Jacobs, A. Z. 2025. Position: Evaluating Generative AI Systems Is a Social Science Measurement Challenge. In Proceedings of the 42nd International Conference on Machine Learning, volume 26...
work page 2025
-
[27]
Walton, R. E.; and McKersie, R. B. 1965. A Behavioral Theory of Labor Negotiations: An Analysis of a Social Interaction System. McGraw-Hill
work page 1965
-
[28]
Wang, C.; Kasenberg, D.; Stachenfeld, K.; and Castro, P. S. 2026. Discovering Differences in Strategic Behavior Between Humans and LLMs. arXiv preprint arXiv:2602.10324
work page internal anchor Pith review arXiv 2026
- [29]
-
[30]
Zhou, X.; Su, Z.; Eisape, T.; Kim, H.; and Sap, M. 2024. Is This the Real Life? Is This Just Fantasy? The Misleading Success of Simulating Social Interactions With LLM s. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 21692--21714. Association for Computational Linguistics
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.