Recognition: no theorem link
LLMs Struggle with Abstract Meaning Comprehension More Than Expected
Pith reviewed 2026-05-10 15:29 UTC · model grok-4.3
The pith
Large language models struggle with abstract meaning comprehension even in few-shot settings
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Most large language models, including GPT-4o, struggle with abstract meaning comprehension under zero-shot, one-shot, and few-shot settings on the ReCAM task, while fine-tuned models like BERT and RoBERTa perform better. A bidirectional attention classifier inspired by human cognitive strategies improves accuracy by 4.06 percent on Task 1 and 3.41 percent on Task 2.
What carries the argument
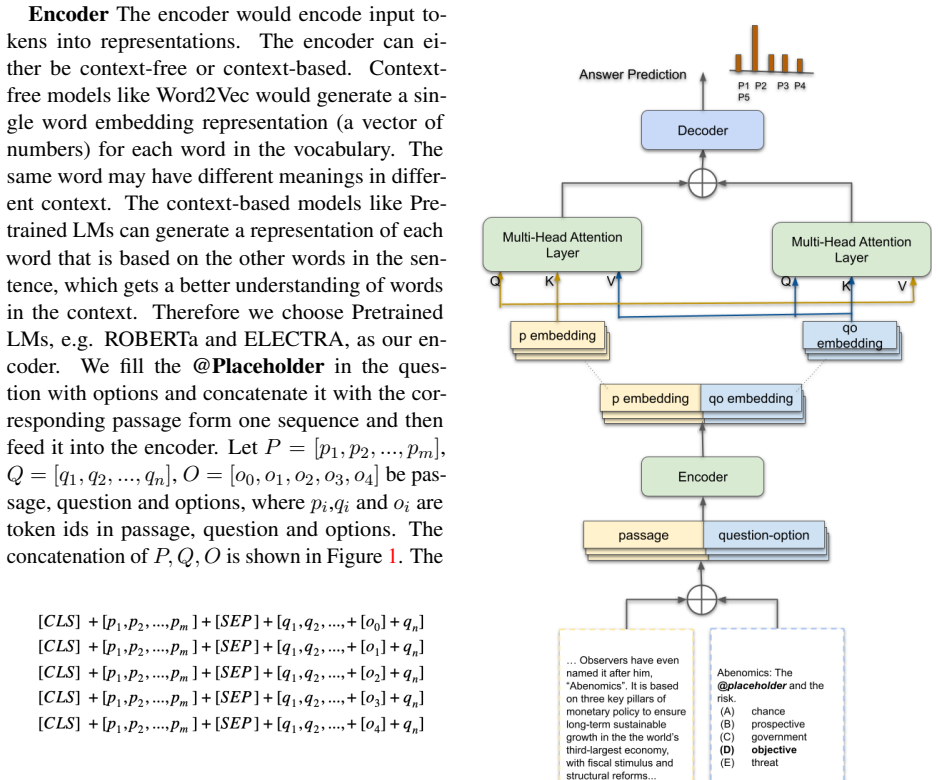
A bidirectional attention classifier that dynamically attends to both the input passage and the abstract answer options.
If this is right
- Fine-tuned models can achieve better results on abstract comprehension by incorporating bidirectional attention.
- LLMs may require fine-tuning rather than relying solely on prompting to handle abstract semantics.
- The ReCAM benchmark highlights a specific weakness in current LLM capabilities for high-level language understanding.
Where Pith is reading between the lines
- Models might need training data or objectives specifically targeting abstract concepts to close the gap with fine-tuned approaches.
- This limitation could extend to other areas like understanding metaphors or emotional language that rely on abstraction.
Load-bearing premise
That differences in performance between LLMs and fine-tuned models on the ReCAM task are caused by the abstract nature of the meanings rather than differences in model scale or training data.
What would settle it
If an LLM without fine-tuning matches or exceeds the accuracy of fine-tuned models on the ReCAM task with abstract options, or if the gap closes when all models are trained on the same data.
Figures

read the original abstract
Understanding abstract meanings is crucial for advanced language comprehension. Despite extensive research, abstract words remain challenging due to their non-concrete, high-level semantics. SemEval-2021 Task 4 (ReCAM) evaluates models' ability to interpret abstract concepts by presenting passages with questions and five abstract options in a cloze-style format. Key findings include: (1) Most large language models (LLMs), including GPT-4o, struggle with abstract meaning comprehension under zero-shot, one-shot, and few-shot settings, while fine-tuned models like BERT and RoBERTa perform better. (2) A proposed bidirectional attention classifier, inspired by human cognitive strategies, enhances fine-tuned models by dynamically attending to passages and options. This approach improves accuracy by 4.06 percent on Task 1 and 3.41 percent on Task 2, demonstrating its potential for abstract meaning comprehension.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates large language models (including GPT-4o) on the ReCAM cloze task (SemEval-2021 Task 4) for abstract meaning comprehension. It claims that LLMs perform poorly in zero-shot, one-shot, and few-shot settings while fine-tuned BERT and RoBERTa models achieve higher accuracy; a proposed bidirectional attention classifier is shown to improve the fine-tuned models by 4.06% on Task 1 and 3.41% on Task 2.
Significance. If the central empirical claims survive controls for adaptation method, the work would usefully document limitations of in-context learning on abstract semantics and introduce a cognitively motivated attention module for fine-tuned classifiers on public benchmarks. The absence of matched conditions currently prevents unambiguous attribution of performance gaps to abstract meaning rather than training regime.
major comments (2)
- [Results] The core claim that LLMs struggle more with abstract meaning than fine-tuned models rests on an asymmetric comparison: LLMs are tested only in zero/one/few-shot prompting while BERT/RoBERTa receive full supervised fine-tuning on the ReCAM training split. Without a matched condition (e.g., fine-tuned LLMs or few-shot BERT baselines on the same task), performance differences cannot be attributed to abstract semantics rather than adaptation method. This issue is load-bearing for the title and abstract conclusions.
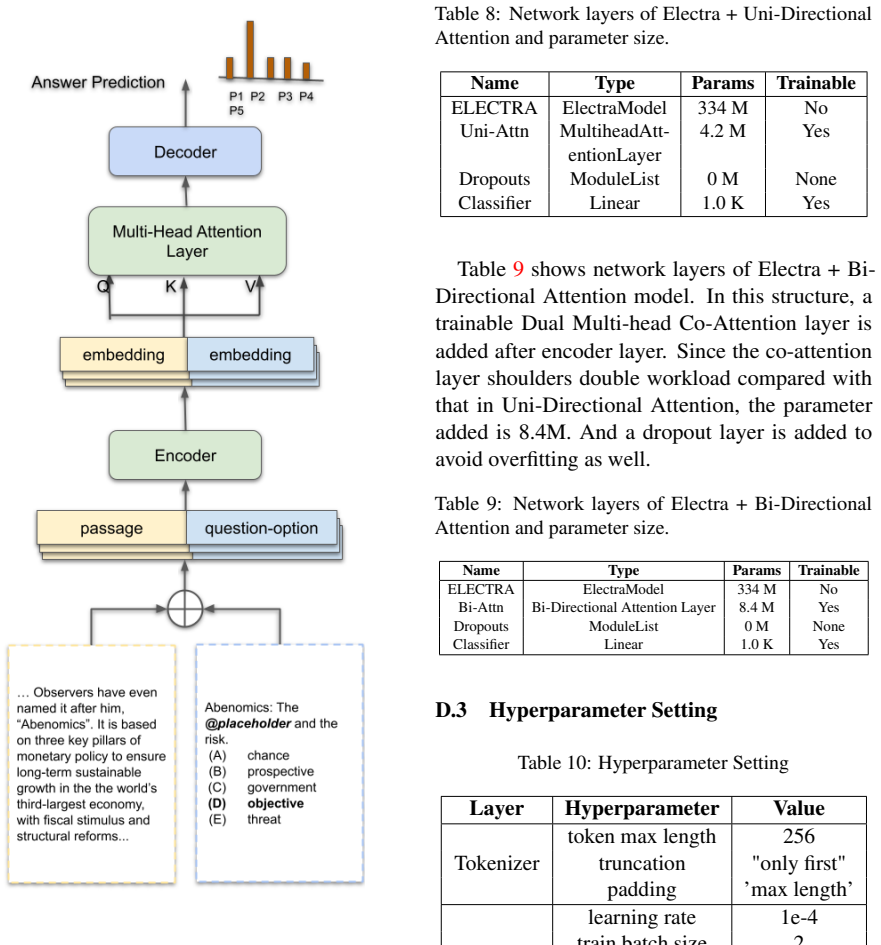
- [Proposed Method] The bidirectional attention classifier is reported to yield 4.06% and 3.41% gains on the two tasks, yet the manuscript provides no error bars, statistical significance tests, ablation studies, or comparison against stronger baselines (e.g., standard self-attention or other attention variants). It is also unclear whether the module was evaluated on LLMs or only on the fine-tuned encoder models.
minor comments (2)
- [Abstract] The abstract supplies no experimental details, model versions, prompt templates, hyperparameter settings, or statistical information, which is atypical for an empirical NLP paper and makes it difficult to assess the reported gains.
- [Method] Clarify the exact ReCAM subtasks (Task 1 and Task 2) and whether the bidirectional attention module replaces or augments the standard classifier head; include a diagram or pseudocode for the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. The feedback highlights important issues regarding experimental controls and methodological rigor. We address each major comment below, commit to revisions where feasible, and note limitations honestly.
read point-by-point responses
-
Referee: [Results] The core claim that LLMs struggle more with abstract meaning than fine-tuned models rests on an asymmetric comparison: LLMs are tested only in zero/one/few-shot prompting while BERT/RoBERTa receive full supervised fine-tuning on the ReCAM training split. Without a matched condition (e.g., fine-tuned LLMs or few-shot BERT baselines on the same task), performance differences cannot be attributed to abstract semantics rather than adaptation method. This issue is load-bearing for the title and abstract conclusions.
Authors: We agree the current comparison is asymmetric and that this limits causal attribution to abstract semantics alone. Our focus was on the practical limitations of in-context learning for LLMs, as full fine-tuning of models like GPT-4o is infeasible. In revision we will add few-shot BERT/RoBERTa baselines using the same number of examples as the LLM prompts, revise the title and abstract to explicitly qualify results as applying to zero- and few-shot regimes, and add a limitations paragraph discussing the adaptation-method confound. We cannot run fine-tuned GPT-4o experiments due to cost and access constraints. revision: partial
-
Referee: [Proposed Method] The bidirectional attention classifier is reported to yield 4.06% and 3.41% gains on the two tasks, yet the manuscript provides no error bars, statistical significance tests, ablation studies, or comparison against stronger baselines (e.g., standard self-attention or other attention variants). It is also unclear whether the module was evaluated on LLMs or only on the fine-tuned encoder models.
Authors: We will add error bars from five random seeds, report p-values from McNemar's test for significance, include ablation studies (removing bidirectional vs. unidirectional attention), and compare against standard self-attention and multi-head attention baselines. The module was applied only to the fine-tuned BERT/RoBERTa encoders; LLMs were evaluated exclusively via prompting. We will clarify this distinction and add the requested analyses in the revised manuscript. revision: yes
- Fine-tuning of GPT-4o (or equivalent closed models) on the ReCAM training set is not possible under current API and compute constraints, preventing a fully matched LLM fine-tuning baseline.
Circularity Check
No circularity: empirical measurements on public benchmark
full rationale
The paper reports direct accuracy numbers for LLMs (zero/one/few-shot) and fine-tuned BERT/RoBERTa on the public ReCAM cloze dataset, plus an empirical gain from a proposed bidirectional attention classifier. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear. All claims remain externally falsifiable against the fixed benchmark split and are not reduced to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report. arXiv preprint arXiv:2303.08774. Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation by jointly learning to align and translate.Preprint, arXiv:1409.0473. Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosse- lut, Emma Brunskill, et al
work page internal anchor Pith review arXiv
-
[3]
On the Opportunities and Risks of Foundation Models
On the opportuni- ties and risks of foundation models.arXiv preprint arXiv:2108.07258. Tom B Brown
work page internal anchor Pith review arXiv
-
[4]
Language Models are Few-Shot Learners
Language models are few-shot learners.arXiv preprint arXiv:2005.14165. Sébastien Bubeck, Varun Chandrasekaran, Ronen El- dan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lund- berg, et al
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[5]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sparks of artificial general intelli- gence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712. Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton
work page internal anchor Pith review arXiv
-
[6]
A simple framework for contrastive learning of visual representations.CoRR, abs/2002.05709. K Clark
work page internal anchor Pith review arXiv 2002
-
[7]
ELECTRA: Pre-training text encoders as discriminators rather than generators
Electra: Pre-training text encoders as discriminators rather than generators.arXiv preprint arXiv:2003.10555. Jacob Devlin
-
[8]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert: Pre-training of deep bidi- rectional transformers for language understanding. arXiv preprint arXiv:1810.04805. Bhuwan Dhingra, Hanxiao Liu, Zhilin Yang, William W Cohen, and Ruslan Salakhutdinov
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Gated- attention readers for text comprehension.arXiv preprint arXiv:1606.01549. Suchin Gururangan, Ana Marasovi ´c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A Smith
-
[10]
Don’t stop pretraining: Adapt language models to domains and tasks.arXiv preprint arXiv:2004.10964. Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen
-
[11]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Deberta: Decoding-enhanced bert with disentangled attention.arXiv preprint arXiv:2006.03654. Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson
work page internal anchor Pith review arXiv 2006
-
[12]
Averaging Weights Leads to Wider Optima and Better Generalization
Averaging weights leads to wider optima and better generalization.Preprint, arXiv:1803.05407. Yinhan Liu
-
[13]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly opti- mized bert pretraining approach.arXiv preprint arXiv:1907.11692. Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[14]
MS MARCO: A human gener- ated machine reading comprehension dataset.CoRR, abs/1611.09268. OpenAI
work page internal anchor Pith review arXiv
-
[15]
https://openai.com/ research/gpt-4
Gpt-3.5-turbo. https://openai.com/ research/gpt-4. Accessed: 2024-11-02. OpenAI
2024
-
[16]
Gpt-4 technical report. https:// openai.com/research/gpt-4. Accessed: 2024- 11-02. Joshua Robinson, Christopher Michael Rytting, and David Wingate. 2023a. Leveraging large language models for multiple choice question answering. Preprint, arXiv:2210.12353. Raquel B Robinson, Karin Johansson, James Collin Fey, Elena Márquez Segura, Jon Back, Annika Waern, S...
-
[17]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama: Open and effi- cient foundation language models.arXiv preprint arXiv:2307.09288. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Attention is all you need.Preprint, arXiv:1706.03762. Ye Wang, Yanmeng Wang, Haijun Zhu, Bo Zeng, Zhenghong Hao, Shaojun Wang, and Jing Xiao
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
InProceedings of the 15th International Workshop on Semantic Eval- uation (SemEval-2021), pages 820–826
Pingan omini-sinitic at semeval-2021 task 4: reading comprehension of abstract meaning. InProceedings of the 15th International Workshop on Semantic Eval- uation (SemEval-2021), pages 820–826. Yudong Xu, Wenhao Li, Pashootan Vaezipoor, Scott Sanner, and Elias B Khalil
2021
-
[20]
arXiv preprint arXiv:2305.18354
Llms and the abstraction and reasoning corpus: Successes, failures, and the importance of object-based representations. arXiv preprint arXiv:2305.18354. Jing Zhang, Yimeng Zhuang, and Yinpei Su
-
[21]
InProceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), pages 51–58
Ta- mamc at semeval-2021 task 4: Task-adaptive pre- training and multi-head attention for abstract mean- ing reading comprehension. InProceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), pages 51–58. Boyuan Zheng, Xiaoyu Yang, Yu-Ping Ruan, Zhenhua Ling, Quan Liu, Si Wei, and Xiaodan Zhu
2021
- [22]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.