Recognition: unknown
Empirical Evaluation of PDF Parsing and Chunking for Financial Question Answering with RAG
Pith reviewed 2026-05-10 15:13 UTC · model grok-4.3
The pith
PDF parsers and chunking strategies significantly affect the performance of RAG systems for financial question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that different combinations of PDF parsers and chunking strategies, including those with varied overlap, produce measurable differences in preserving the structure of financial documents and in the correctness of answers generated by RAG systems, with the evaluation across benchmarks yielding practical guidelines for building robust PDF-understanding pipelines.
What carries the argument
The key machinery is the systematic examination of PDF parsers and chunking strategies with different overlaps, assessed by their synergy in maintaining document structure and answer accuracy within RAG for question answering on financial benchmarks.
If this is right
- Optimal parser-chunker pairs improve handling of tables and mixed content in PDFs for better RAG results.
- Chunk overlap levels interact with parser choice to affect performance.
- The new TableQuest benchmark provides a targeted way to evaluate table understanding in financial QA.
- These empirical findings directly inform the selection of components when constructing RAG systems for PDF documents.
Where Pith is reading between the lines
- Similar evaluation methods could be applied to PDFs in legal or scientific domains to derive domain-specific guidelines.
- Future experiments might combine these parsing and chunking approaches with advanced layout analysis techniques for further gains.
- Results may vary with different base language models or RAG architectures, suggesting the need for model-specific tuning.
Load-bearing premise
The assumption that the selected financial benchmarks and metrics capture the essential real-world challenges of PDF understanding and that findings generalize beyond the tested configurations.
What would settle it
A demonstration that an untested PDF parser or chunking method achieves higher accuracy on the same benchmarks, or that the recommended strategies underperform on a new financial dataset with different table structures, would challenge the guidelines.
Figures




read the original abstract
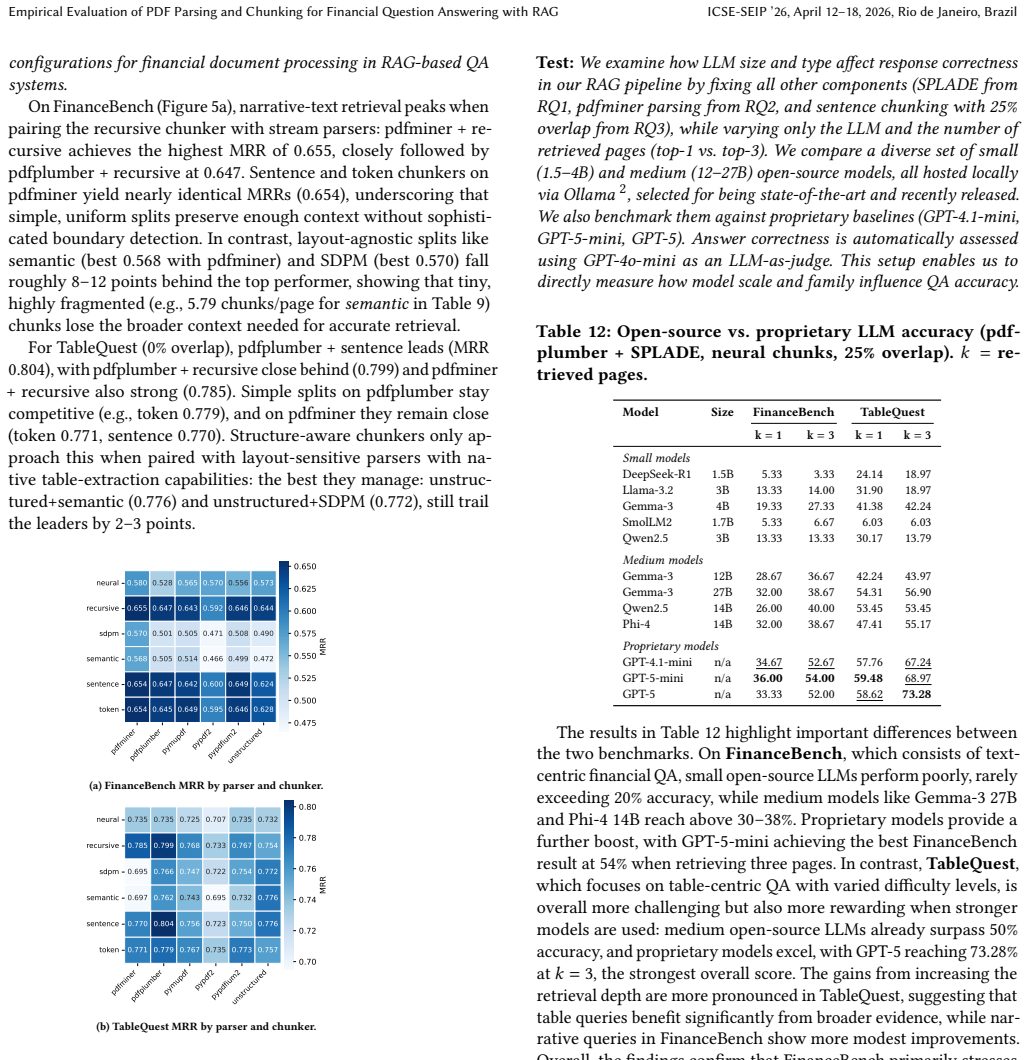
PDF files are primarily intended for human reading rather than automated processing. In addition, the heterogeneous content of PDFs, such as text, tables, and images, poses significant challenges for parsing and information extraction. To address these difficulties, both practitioners and researchers are increasingly developing new methods, including the promising Retrieval-Augmented Generation (RAG) systems to automated PDF processing. However, there is no comprehensive study investigating how different components and design choices affect the performance of a RAG system for understanding PDFs. In this paper, we propose such a study (1) by focusing on Question Answering, a specific language understanding task, and (2) by leveraging two benchmarks from the financial domain, including TableQuest, our newly generated, publicly available benchmark. We systematically examine multiple PDF parsers and chunking strategies (with varied overlap), along with their potential synergies in preserving document structure and ensuring answer correctness. Overall, our results offer practical guidelines for building robust RAG pipelines for PDF understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper performs an empirical study on the impact of PDF parsers and chunking strategies (including different overlap settings) on the performance of RAG-based question answering systems. It uses two financial domain benchmarks, including the newly proposed TableQuest dataset, to evaluate how these choices affect the preservation of document structure and the correctness of answers. The authors conclude that their results provide practical guidelines for developing robust RAG pipelines for PDF understanding.
Significance. If the experimental results are reliable, this study contributes empirical evidence on component interactions in RAG systems for handling complex PDF content like tables and text. The public release of TableQuest is a notable strength, as it provides a new resource for financial QA research. The work could inform practitioners in the financial sector on optimizing their PDF processing pipelines. However, the domain-specific nature of the benchmarks may constrain the generalizability of the proposed guidelines to broader PDF understanding tasks.
major comments (1)
- [Abstract] The central claim that the study offers 'practical guidelines for building robust RAG pipelines for PDF understanding' is not adequately supported by the experimental design. The evaluation is confined to financial-domain QA benchmarks, without testing on other document types (e.g., scientific papers with equations or multi-column layouts). This raises the risk that the identified synergies between parsers and chunking methods are artifacts of financial report formatting rather than general PDF properties, undermining the broader applicability asserted in the abstract and conclusions.
minor comments (1)
- Consider adding a summary table of the key parser-chunking combinations and their performance metrics across the benchmarks to improve the clarity of the results presentation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] The central claim that the study offers 'practical guidelines for building robust RAG pipelines for PDF understanding' is not adequately supported by the experimental design. The evaluation is confined to financial-domain QA benchmarks, without testing on other document types (e.g., scientific papers with equations or multi-column layouts). This raises the risk that the identified synergies between parsers and chunking methods are artifacts of financial report formatting rather than general PDF properties, undermining the broader applicability asserted in the abstract and conclusions.
Authors: We agree that the experimental scope is limited to financial-domain benchmarks and that this constrains claims of broad applicability across all PDF types. Financial reports feature dense tabular structures and specific layouts that may not generalize to scientific papers with equations or other multi-column formats, so the observed parser-chunking synergies could partly reflect domain-specific formatting. To correct this, we will revise the abstract to state that the guidelines apply to financial PDF understanding, update the conclusions accordingly, and add an explicit limitations paragraph discussing domain specificity and the need for future cross-domain validation. revision: yes
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper is a purely empirical evaluation of PDF parsers, chunking strategies, and their synergies on two financial-domain QA benchmarks (including a new TableQuest dataset). It reports experimental results to derive practical guidelines for RAG pipelines. No mathematical derivations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described methodology. The guidelines are presented as direct outcomes of the systematic comparisons performed, with no reduction of claims to their own inputs by construction. This is a standard empirical study whose central claims rest on observed performance metrics rather than any internal circular logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected financial benchmarks and metrics are representative proxies for PDF understanding performance in QA tasks.
Reference graph
Works this paper leans on
- [1]
-
[2]
Adobe. 2025. What Is a PDF? Portable Document Format. https://www.adobe. com/acrobat/about-adobe-pdf.html. https://www.adobe.com/acrobat/about- adobe-pdf.html Accessed: 14 May 2025
2025
- [3]
-
[4]
and contributors
Artifex Software, Inc. and contributors. 2016. PyMuPDF: High-performance Python PDF library. https://github.com/pymupdf/PyMuPDF. https://github.com/ pymupdf/PyMuPDF
2016
-
[5]
Hannah Bast and Claudius Korzen. 2017. A benchmark and evaluation for text extraction from PDF. In2017 ACM/IEEE joint conference on digital libraries (JCDL) . IEEE, 1–10
2017
-
[6]
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, et al
-
[7]
arXiv preprint arXiv:2109.00122 , year=
Finqa: A dataset of numerical reasoning over financial data. arXiv preprint arXiv:2109.00122 (2021)
-
[8]
Tobias Daudert, Paul Buitelaar, and Sapna Negi. 2018. Leveraging news senti- ment to improve microblog sentiment classification in the financial domain. In Proceedings of the first workshop on economics and natural language processing . 49–54
2018
- [9]
-
[10]
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. 2024. Ragas: Automated evaluation of retrieval augmented generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. 150–158
2024
-
[11]
Joao Filgueiras, Luís Barbosa, Gil Rocha, Henrique Lopes Cardoso, Luís Paulo Reis, Joao Pedro Machado, and Ana Maria Oliveira. 2019. Complaint analysis and classification for economic and food safety. InProceedings of the Second Workshop on Economics and Natural Language Processing . 51–60
2019
- [12]
- [13]
-
[14]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented gen- eration for large language models: A survey. arXiv preprint arXiv:2312.10997 2 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. 2021. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021)
work page internal anchor Pith review arXiv 2021
-
[16]
Daniel Gozman and Wendy Currie. 2014. The role of investment management systems in regulatory compliance: A post-financial crisis study of displacement mechanisms. Journal of Information Technology 29, 1 (2014), 44–58
2014
-
[17]
Jingguang Han, Utsab Barman, Jer Hayes, Jinhua Du, Edward Burgin, and Dadong Wan. 2018. Nextgen aml: Distributed deep learning based language technologies to augment anti money laundering investigation. Association for Computational Linguistics
2018
-
[18]
Paul Hopkin. 2018. Fundamentals of risk management: understanding, evaluating and implementing effective risk management . Kogan Page Publishers
2018
-
[19]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [20]
-
[21]
Gautier Izacard. 2021. PyLate: Python Library for ColBERT-Style Indexing. https: //github.com/lightonai/pylate
2021
-
[22]
Jeremy Singer-Vine and contributors. 2013. pdfplumber: Python PDF Parsing and Extraction Library. https://github.com/jsvine/pdfplumber. https://github. com/jsvine/pdfplumber
2013
-
[23]
Thorsten Joachims and Nick Craswell. 2021. ir-measures: A Library for Evaluating Information Retrieval. https://github.com/terrierteam/ir_measures
2021
-
[24]
Feyza Duman Keles, Pruthuvi Mahesakya Wijewardena, and Chinmay Hegde
-
[25]
In International Confer- ence on Algorithmic Learning Theory
On the computational complexity of self-attention. In International Confer- ence on Algorithmic Learning Theory . PMLR, 597–619
-
[26]
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 39–48
2020
- [27]
-
[28]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33 (2020), 9459–9474
2020
-
[29]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. Llms-as-judges: a comprehensive survey on llm-based evaluation methods. arXiv preprint arXiv:2412.05579 (2024)
work page internal anchor Pith review arXiv 2024
-
[30]
Macedo Maia, Siegfried Handschuh, André Freitas, Brian Davis, Ross McDermott, Manel Zarrouk, and Alexandra Balahur. 2018. Www’18 open challenge: financial opinion mining and question answering. In Companion proceedings of the the web conference 2018. 1941–1942
2018
-
[31]
Phillip Massa and Julian McAuley. 2020. rank_bm25: A Python Implementation of Okapi BM25. https://github.com/dorianbrown/rank_bm25
2020
-
[32]
Norman Meuschke, Apurva Jagdale, Timo Spinde, Jelena Mitrović, and Bela Gipp
-
[33]
In International Conference on Information
A benchmark of pdf information extraction tools using a multi-task and multi-domain evaluation framework for academic documents. In International Conference on Information. Springer, 383–405
-
[34]
Inc. Ollama. 2024. Ollama: Local LLM Inference Toolkit. https://ollama.com
2024
-
[35]
pdfminer.six contributors. 2018. pdfminer.six: Python PDF Parsing Library. https: //github.com/pdfminer/pdfminer.six. https://github.com/pdfminer/pdfminer.six
2018
-
[36]
and contributors
Phaseit, Inc. and contributors. 2012. PyPDF2: Pure-Python PDF toolkit. https: //github.com/py-pdf/PyPDF2. https://github.com/py-pdf/PyPDF2
2012
-
[37]
pypdfium2-team. 2023. pypdfium2: Python bindings for PDFium. https: //github.com/pypdfium2-team/pypdfium2. https://github.com/pypdfium2-team/ pypdfium2
2023
-
[38]
Stephen Robertson, Hugo Zaragoza, et al . 2009. The probabilistic relevance framework: BM25 and beyond. Foundations and Trends® in Information Retrieval 3, 4 (2009), 333–389
2009
-
[39]
Daniel Ruffinelli and Joshua Martel. 2022. sparsembed: SPLADE Dense+Sparse Embedding Library. https://github.com/naver/splade
2022
- [40]
-
[41]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Hugging Face Team. 2023. Transformers: State-of-the-Art Natural Language Processing. https://github.com/huggingface/transformers
2023
-
[43]
Unstructured Technologies and contributors. 2022. Unstructured: Python library for document preprocessing. https://github.com/Unstructured-IO/unstructured. https://github.com/Unstructured-IO/unstructured
2022
-
[44]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Multilingual e5 text embeddings: A technical report. arXiv preprint arXiv:2402.05672 (2024)
work page internal anchor Pith review arXiv 2024
-
[45]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824–24837
2022
-
[46]
Peng Xu, Wei Ping, Xianchao Wu, Lawrence McAfee, Chen Zhu, Zihan Liu, Sandeep Subramanian, Evelina Bakhturina, Mohammad Shoeybi, and Bryan Catanzaro. 2023. Retrieval meets long context large language models. In The Twelfth International Conference on Learning Representations
2023
- [47]
-
[48]
Antonio Jimeno Yepes, Yao You, Jan Milczek, Sebastian Laverde, and Renyu Li
-
[49]
Financial report chunking for effective retrieval augmented generation,
Financial report chunking for effective retrieval augmented generation. arXiv preprint arXiv:2402.05131 (2024)
-
[50]
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, and Zhaofeng Liu. 2024. Evaluation of retrieval-augmented generation: A survey. In CCF Conference on Big Data. Springer, 102–120. 728 ICSE-SEIP ’26, April 12–18, 2026, Rio de Janeiro, Brazil El Bachyr, et al
2024
- [51]
- [52]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.