Recognition: unknown
Why Your Tokenizer Fails in Information Fusion: A Timing-Aware Pre-Quantization Fusion for Video-Enhanced Audio Tokenization
Pith reviewed 2026-05-10 14:46 UTC · model grok-4.3
The pith
Timing-aware pre-quantization fusion integrates video into audio tokenizers while preserving reconstruction quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that fusing visual information along the temporal axis before quantization, guided by distinctive features, allows the first successful integration of video into audio tokenizer architectures without degrading reconstruction fidelity. This method outperforms both audio-only tokenizers and established multimodal fusion baselines on downstream understanding tasks. The result rests on three findings: fusion location within the architecture matters for quality preservation, contrastive learning is unsuitable for discrete tokenizers, and temporal fusion is superior to feature-dimension fusion.
What carries the argument
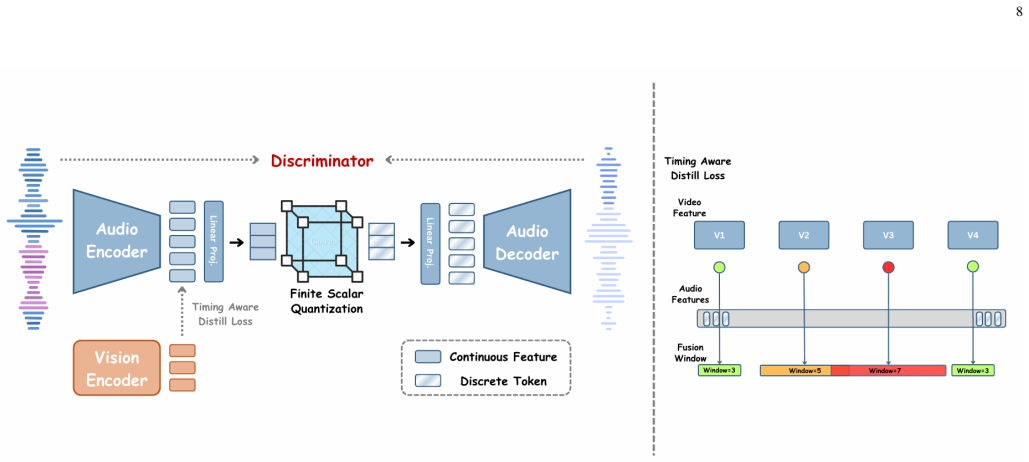
Timing-Aware Pre-Quantization Fusion, which aligns video and audio features along the temporal axis before the quantization step using guidance from distinctive features.
If this is right
- Video information can be added to audio tokenizers before quantization to improve understanding tasks without reconstruction loss.
- Contrastive learning approaches fail to enhance performance when applied to discrete audio tokenizers.
- Temporal-axis fusion guided by distinctive features outperforms feature-dimension fusion for preserving reconstruction quality.
- The resulting tokenizers achieve higher downstream-task accuracy than both audio-only and prior multimodal baselines.
Where Pith is reading between the lines
- The same pre-quantization temporal strategy could be tested with other modalities such as text or motion to further enrich audio tokenizers.
- Verification on larger or more varied video-audio corpora would indicate whether the reported superiority of temporal fusion generalizes.
- Audio language models that rely on these tokenizers may handle ambiguous inputs more robustly once video cues are reliably incorporated.
Load-bearing premise
That fusing along the temporal axis guided by distinctive features will avoid the reconstruction degradation seen in other multimodal approaches.
What would settle it
A reconstruction-quality evaluation on a held-out video-audio dataset in which the Timing-Aware Pre-Quantization Fusion method produces lower fidelity metrics than an audio-only baseline would falsify the central claim.
Figures



read the original abstract
Audio tokenization has emerged as a critical component in end-to-end audio language models, enabling efficient discrete representation learning for both audio understanding and generation tasks. However, existing audio tokenizers face fundamental limitations in understanding tasks due to single-modality constraints, particularly when audio signals contain ambiguous or incomplete information. While incorporating additional modality information can significantly enhance audio understanding, current multimodal fusion approaches invariably degrade reconstruction quality. This degradation is unacceptable for end-to-end audio systems that require high-fidelity audio generation capabilities. In this work, we investigate the root causes of reconstruction quality degradation in video-enhanced audio tokenization and present three key findings. First, the location of fusion within the tokenizer architecture is crucial for preserving reconstruction quality. Second, we show that contrastive learning, though effective in continuous representation fusion, is unsuitable for discrete tokenizers as it fails to enhance downstream task performance. Third, while feature-dimension fusion approaches achieve moderate success, we discover that fusing along the temporal axis -- guided by the concept of distinctive features -- yields significantly better results. Building on these insights, we introduce the Timing-Aware Pre-Quantization Fusion for Video-Enhanced Audio Tokenization, the first approach to successfully integrate visual information into audio tokenizer architectures while preserving reconstruction fidelity. Our approach not only maintains high-fidelity reconstruction but also achieves superior performance on downstream understanding tasks compared with audio-only tokenizers and established multimodal fusion baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines limitations of single-modality audio tokenizers in understanding tasks and investigates why multimodal (video-enhanced) fusion degrades reconstruction quality. It reports three findings: fusion location within the architecture is critical for fidelity; contrastive learning fails to improve downstream performance in discrete tokenizers; and temporal-axis fusion guided by distinctive features outperforms feature-dimension fusion. Building on these, it proposes Timing-Aware Pre-Quantization Fusion as the first method to integrate visual information into audio tokenizers while preserving high-fidelity reconstruction and achieving superior downstream task performance versus audio-only and multimodal baselines.
Significance. If the empirical results and method hold, this would represent a meaningful advance in multimodal audio tokenization by resolving the reconstruction-understanding trade-off, with direct relevance to end-to-end audio language models that require both generation fidelity and enhanced understanding from visual cues.
major comments (1)
- Abstract: The abstract asserts three key findings plus superior performance on downstream tasks relative to audio-only tokenizers and multimodal baselines, yet supplies no quantitative metrics, datasets, ablation studies, or error analysis. Without these, the central claim that the proposed timing-aware fusion preserves fidelity while improving tasks cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment on the abstract. We address the concern point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [—] Abstract: The abstract asserts three key findings plus superior performance on downstream tasks relative to audio-only tokenizers and multimodal baselines, yet supplies no quantitative metrics, datasets, ablation studies, or error analysis. Without these, the central claim that the proposed timing-aware fusion preserves fidelity while improving tasks cannot be evaluated.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript, we will add specific metrics supporting the three findings (e.g., reconstruction fidelity measured by Mel-spectrogram MSE or STFT loss, and downstream task gains such as accuracy or mAP improvements on datasets like AudioSet or VGGSound). We will also briefly reference the main ablation outcomes and the primary evaluation datasets. This revision will make the central claims directly evaluable from the abstract while preserving its concise nature. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an empirical study of multimodal fusion strategies for audio tokenizers, reporting three findings on fusion location, the unsuitability of contrastive learning for discrete tokens, and the superiority of temporal-axis fusion guided by distinctive features. These observations are used to motivate the Timing-Aware Pre-Quantization Fusion method. No equations, derivations, or parameter-fitting steps appear in the abstract or described approach; the claims rest on experimental comparisons rather than any self-definitional reduction, fitted-input prediction, or load-bearing self-citation chain. The central result is therefore not equivalent to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Moshi: a speech-text foundation model for real-time dialogue
A. D´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
Step-audio: Unified understanding and generation in intelligent speech interaction, 2025
A. Huang, B. Wu, B. Wang, C. Yan, C. Hu, C. Feng, F. Tian, F. Shen, J. Li, M. Chenet al., “Step-audio: Unified understanding and generation in intelligent speech interaction,”arXiv preprint arXiv:2502.11946, 2025
-
[3]
Step-audio 2 technical report, 2025
B. Wu, C. Yan, C. Hu, C. Yi, C. Feng, F. Tian, F. Shen, G. Yu, H. Zhang, J. Liet al., “Step-audio 2 technical report,”arXiv preprint arXiv:2507.16632, 2025
-
[4]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Speaking in wavelet domain: A simple and efficient approach to speed up speech diffusion model,
X. Zhang, D. Liu, H. Liu, Q. Zhang, H. Meng, L. P. G. Perera, E. Chng, and L. Yao, “Speaking in wavelet domain: A simple and efficient approach to speed up speech diffusion model,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 159–171
2024
-
[6]
Selective state space model for monaural speech enhancement,
M. Chen, Q. Zhang, M. Wang, X. Zhang, H. Liu, E. Ambikairaiah, and D. Chen, “Selective state space model for monaural speech enhancement,” IEEE Transactions on Consumer Electronics, 2025
2025
-
[7]
Step-audio-r1 technical report, 2025
F. Tian, X. T. Zhang, Y . Zhang, H. Zhang, Y . Li, D. Liu, Y . Deng, D. Wu, J. Chen, L. Zhaoet al., “Step-audio-r1 technical report,”arXiv preprint arXiv:2511.15848, 2025
-
[8]
Mind-paced speaking: A dual-brain approach to real-time reasoning in spoken language models,
D. Wu, H. Zhang, J. Chen, H. Liu, E. S. Chng, F. Tian, X. Yang, X. Zhang, D. Jiang, G. Yuet al., “Mind-paced speaking: A dual-brain approach to real-time reasoning in spoken language models,”arXiv preprint arXiv:2510.09592, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2021
2021
-
[10]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”Transactions on Machine Learning Research, 2022
2022
-
[11]
High- fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High- fidelity audio compression with improved rvqgan,”Advances in Neural Information Processing Systems, vol. 36, pp. 27 980–27 993, 2023
2023
-
[12]
Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,
S. Ji, Z. Jiang, W. Wang, Y . Chen, M. Fang, J. Zuo, Q. Yang, X. Cheng, Z. Wang, R. Liet al., “Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,” inThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[13]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
The llama 3 herd of models,
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
2024
-
[15]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Danget al., “Qwen2. 5-omni technical report,”arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review arXiv 2025
-
[16]
Reinforcement Learning Outperforms Supervised Fine-Tuning: A Case Study on Audio Question Answering,
G. Li, J. Liu, H. Dinkel, Y . Niu, J. Zhang, and J. Luan, “Reinforcement learning outperforms supervised fine-tuning: A case study on audio question answering,”arXiv preprint arXiv:2503.11197, 2025
-
[17]
Omni-r1: Do you really need audio to fine-tune your audio llm?arXiv preprint arXiv:2505.09439, 2025
A. Rouditchenko, S. Bhati, E. Araujo, S. Thomas, H. Kuehne, R. Feris, and J. Glass, “Omni-r1: Do you really need audio to fine-tune your audio llm?”arXiv preprint arXiv:2505.09439, 2025
-
[18]
Unified audio-visual saliency model for omnidirectional videos with spatial audio,
D. Zhu, K. Zhang, N. Zhang, Q. Zhou, X. Min, G. Zhai, and X. Yang, “Unified audio-visual saliency model for omnidirectional videos with spatial audio,”IEEE Transactions on Multimedia, vol. 26, pp. 764–775, 2024
2024
-
[19]
Audio-visual event recognition in surveillance video sequences,
M. Cristani, M. Bicego, and V . Murino, “Audio-visual event recognition in surveillance video sequences,”IEEE Transactions on Multimedia, vol. 9, no. 2, pp. 257–267, 2007
2007
-
[20]
Synchronization of multiple camera videos using audio-visual features,
P. Shrestha, M. Barbieri, H. Weda, and D. Sekulovski, “Synchronization of multiple camera videos using audio-visual features,”IEEE Transactions on Multimedia, vol. 12, no. 1, pp. 79–92, 2010
2010
-
[21]
Cross- lingual adaptation for vision-language model via multimodal semantic distillation,
Y . Weng, W. He, J. Dong, Chaomurilige, X. Liu, and Z. Liu, “Cross- lingual adaptation for vision-language model via multimodal semantic distillation,”IEEE Transactions on Multimedia, vol. 27, pp. 3184–3196, 2025
2025
-
[22]
Unleash the power of vision-language models by visual attention prompt and multimodal interaction,
W. Zhang, L. Wu, Z. Zhang, T. Yu, C. Ma, X. Jin, X. Yang, and W. Zeng, “Unleash the power of vision-language models by visual attention prompt and multimodal interaction,”IEEE Transactions on Multimedia, vol. 27, pp. 2399–2411, 2025
2025
-
[23]
Visual, auditory, and somatosensory convergence on cells in superior colliculus results in multisensory integration,
M. A. Meredith and B. E. Stein, “Visual, auditory, and somatosensory convergence on cells in superior colliculus results in multisensory integration,”Journal of neurophysiology, vol. 56, no. 3, pp. 640–662, 1986
1986
-
[24]
Audio-visual experience strengthens multi- sensory assemblies in adult mouse visual cortex,
T. Kn ¨opfel, Y . Sweeney, C. I. Radulescu, N. Zabouri, N. Doostdar, C. Clopath, and S. J. Barnes, “Audio-visual experience strengthens multi- sensory assemblies in adult mouse visual cortex,”Nature communications, vol. 10, no. 1, p. 5684, 2019
2019
-
[25]
Sequential contrastive audio- visual learning,
I. Tsiamas, S. Pascual, C. Yeh, and J. Serr`a, “Sequential contrastive audio- visual learning,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[26]
V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foundation models,
H. Wang, J. Ma, S. Pascual, R. Cartwright, and W. Cai, “V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foundation models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 14, 2024, pp. 15 492–15 501
2024
-
[27]
Speechtokenizer: Unified speech tokenizer for speech language models,
X. Zhang, D. Zhang, S. Li, Y . Zhou, and X. Qiu, “Speechtokenizer: Unified speech tokenizer for speech language models,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=AF9Q8Vip84
2024
-
[28]
Distinctive feature codec: Adaptive segmentation for efficient speech representation,
X. Zhang, F. Fang, P. Gao, B. Qin, B. Ahmed, and J. Epps, “Distinctive feature codec: Adaptive segmentation for efficient speech representation,” arXiv preprint arXiv:2505.18516, 2025
-
[29]
Xy-tokenizer: Mitigating the semantic-acoustic conflict in low-bitrate speech codecs,
Y . Gong, L. Jin, R. Deng, D. Zhang, X. Zhang, Q. Cheng, Z. Fei, S. Li, and X. Qiu, “Xy-tokenizer: Mitigating the semantic-acoustic conflict in low-bitrate speech codecs,”arXiv preprint arXiv:2506.23325, 2025
-
[30]
UniCodec: Unified audio codec with single domain-adaptive codebook.arXiv preprint arXiv:2502.20067,
Y . Jiang, Q. Chen, S. Ji, Y . Xi, W. Wang, C. Zhang, X. Yue, S. Zhang, and H. Li, “Unicodec: Unified audio codec with single domain-adaptive codebook,”arXiv preprint arXiv:2502.20067, 2025
-
[31]
Straightening out the straight-through estimator: Overcoming optimization challenges in vector quantized networks,
M. Huh, B. Cheung, P. Agrawal, and P. Isola, “Straightening out the straight-through estimator: Overcoming optimization challenges in vector quantized networks,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 14 096–14 113
2023
-
[32]
Learning representations for neural network-based classification using the information bottleneck principle,
R. A. Amjad and B. C. Geiger, “Learning representations for neural network-based classification using the information bottleneck principle,” IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 9, pp. 2225–2239, 2019
2019
-
[33]
Tiva: Time-aligned video-to-audio generation,
X. Wang, Y . Wang, Y . Wu, R. Song, X. Tan, Z. Chen, H. Xu, and G. Sui, “Tiva: Time-aligned video-to-audio generation,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 573–582
2024
-
[34]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12 888–12 900. 11
2022
-
[35]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
-
[36]
Lee,Automatic speech recognition: the development of the SPHINX system
K.-F. Lee,Automatic speech recognition: the development of the SPHINX system. Springer Science & Business Media, 1988, vol. 62
1988
-
[37]
Landmark detection for distinctive feature-based speech recognition,
S. A. Liu, “Landmark detection for distinctive feature-based speech recognition,”The Journal of the Acoustical Society of America, vol. 100, no. 5, pp. 3417–3430, 1996
1996
-
[38]
Auto-Landmark: Acoustic Landmark Dataset and Open-Source Toolkit for Landmark Extraction,
Xiangyu Zhang and Daijiao Liu and Tianyi Xiao and Cihan Xiao and T¨unde Szalay and Mostafa Shahin and Beena Ahmed and Julien Epps, “Auto-Landmark: Acoustic Landmark Dataset and Open-Source Toolkit for Landmark Extraction,” inInterspeech 2025, 2025, pp. 4263–4267
2025
-
[39]
X. Zhang, H. Liu, Q. Zhang, B. Ahmed, and J. Epps, “Speecht-rag: Reliable depression detection in llms with retrieval-augmented generation using speech timing information,”arXiv preprint arXiv:2502.10950, 2025
-
[40]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tanget al., “Qwen2. 5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review arXiv 2024
-
[42]
Speechgpt: Empowering large language models with intrinsic cross- modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “Speechgpt: Empowering large language models with intrinsic cross- modal conversational abilities,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 15 757–15 773
2023
-
[43]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[44]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[45]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[46]
Neural machine translation of rare words with subword units,
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” inProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016, pp. 1715–1725
2016
-
[47]
Do all languages cost the same? tokenization in the era of commercial language models,
O. Ahia, S. Kumar, H. Gonen, J. Kasai, D. R. Mortensen, N. A. Smith, and Y . Tsvetkov, “Do all languages cost the same? tokenization in the era of commercial language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 9904– 9923
2023
-
[48]
Unicode: Learning a unified codebook for multimodal large language models,
S. Zheng, B. Zhou, Y . Feng, Y . Wang, and Z. Lu, “Unicode: Learning a unified codebook for multimodal large language models,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 426–443
2024
-
[49]
arXiv preprint arXiv:2502.20321 (2025) 9
C. Ma, Y . Jiang, J. Wu, J. Yang, X. Yu, Z. Yuan, B. Peng, and X. Qi, “Unitok: A unified tokenizer for visual generation and understanding,” arXiv preprint arXiv:2502.20321, 2025
-
[50]
A new approach to extract fetal electrocardiogram using affine combination of adaptive filters,
Y . Xuan, X. Zhang, S. S. Li, Z. Shen, X. Xie, L. P. Garcia, and R. Togneri, “A new approach to extract fetal electrocardiogram using affine combination of adaptive filters,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[51]
Autoregressive image generation using residual quantization,
D. Lee, C. Kim, S. Kim, M. Cho, and W.-S. Han, “Autoregressive image generation using residual quantization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 523–11 532
2022
-
[52]
Seanet: A multi- modal speech enhancement network,
M. Tagliasacchi, Y . Li, K. Misiunas, and D. Roblek, “Seanet: A multi- modal speech enhancement network,” inInterspeech 2020, 2020, pp. 1126–1130
2020
-
[53]
Perception Encoder: The best visual embeddings are not at the output of the network
D. Bolya, P.-Y . Huang, P. Sun, J. H. Cho, A. Madotto, C. Wei, T. Ma, J. Zhi, J. Rajasegaran, H. Rasheedet al., “Perception encoder: The best visual embeddings are not at the output of the network,”arXiv preprint arXiv:2504.13181, 2025
work page internal anchor Pith review arXiv 2025
-
[54]
Pengi: An audio language model for audio tasks,
S. Deshmukh, B. Elizalde, R. Singh, and H. Wang, “Pengi: An audio language model for audio tasks,”Advances in Neural Information Processing Systems, vol. 36, pp. 18 090–18 108, 2023
2023
-
[55]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
S. Sakshi, U. Tyagi, S. Kumar, A. Seth, R. Selvakumar, O. Nieto, R. Duraiswami, S. Ghosh, and D. Manocha, “Mmau: A massive multi- task audio understanding and reasoning benchmark,”arXiv preprint arXiv:2410.19168, 2024
work page internal anchor Pith review arXiv 2024
-
[56]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 776–780
2017
-
[57]
Visqol: an objective speech quality model,
A. Hines, J. Skoglund, A. C. Kokaram, and N. Harte, “Visqol: an objective speech quality model,”EURASIP Journal on Audio, Speech, and Music Processing, vol. 2015, no. 1, p. 13, 2015
2015
-
[58]
Avqa: A dataset for audio-visual question answering on videos,
P. Yang, X. Wang, X. Duan, H. Chen, R. Hou, C. Jin, and W. Zhu, “Avqa: A dataset for audio-visual question answering on videos,” in Proceedings of the 30th ACM international conference on multimedia, 2022, pp. 3480–3491
2022
-
[59]
Gradient surgery for multi-task learning,
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn, “Gradient surgery for multi-task learning,”Advances in neural information processing systems, vol. 33, pp. 5824–5836, 2020
2020
-
[60]
F. Faghri, D. Duvenaud, D. J. Fleet, and J. Ba, “A study of gradient variance in deep learning,”arXiv preprint arXiv:2007.04532, 2020
-
[61]
On large-batch training for deep learning: Generalization gap and sharp minima,
N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang, “On large-batch training for deep learning: Generalization gap and sharp minima,” inInternational Conference on Learning Representations, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.