Recognition: unknown
Evaluating Plan Compliance in Autonomous Programming Agents
Pith reviewed 2026-05-10 14:48 UTC · model grok-4.3
The pith
Programming agents often ignore given plans but resolve more issues when periodically reminded to follow them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Without an explicit plan, agents fall back on workflows internalized during training, which are often incomplete, overfit, or inconsistently applied. Providing the standard plan improves issue resolution, and periodic plan reminders can mitigate plan violations and improve task success. A subpar plan hurts performance even more than no plan at all. Augmenting a plan with additional task-relevant phases in the early stage can degrade performance, particularly when these phases do not align with the model's internal problem-solving strategy.
What carries the argument
Systematic tracking of plan compliance across 16,991 agent trajectories under eight different plan variations.
If this is right
- Providing a standard plan improves issue resolution compared to running without any plan.
- Periodic reminders reduce plan violations and raise overall task success.
- A poorly aligned plan lowers performance below the level achieved with no plan at all.
- Adding extra phases early in a plan can decrease success when those phases conflict with the agent's internal strategy.
Where Pith is reading between the lines
- Benchmark results may overstate agent reasoning ability when plan adherence is not separately verified.
- Training methods could be designed to reward adaptive plan use instead of workflow memorization.
- Agent evaluation suites might add compliance checks as a standard reporting requirement to separate strategic execution from other factors.
Load-bearing premise
Plan compliance can be measured reliably and objectively from the sequence of actions in agent trajectories alone.
What would settle it
A set of human-annotated trajectories that shows compliance rates differing substantially from the automated measurement used in the study.
Figures





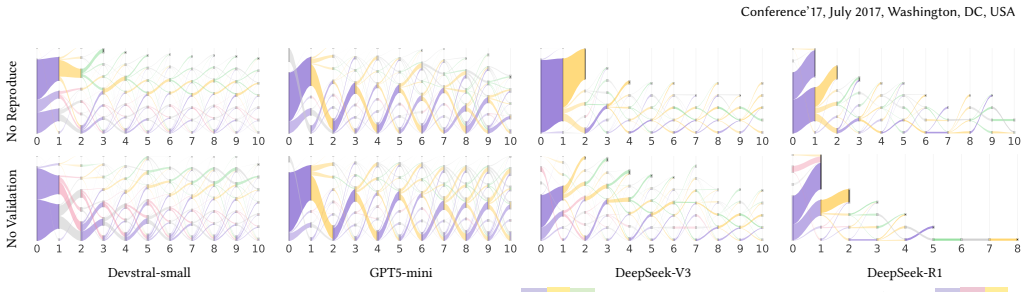
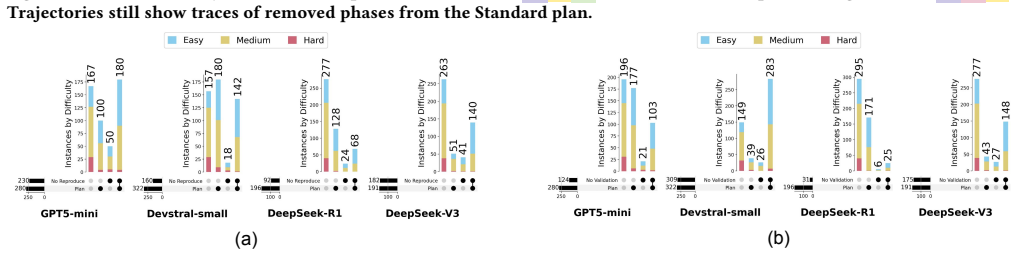











read the original abstract
Agents aspire to eliminate the need for task-specific prompt crafting through autonomous reason-act-observe loops. Still, they are commonly instructed to follow a task-specific plan for guidance, e.g., to resolve software issues following phases for navigation, reproduction, patch, and validation. Unfortunately, it is unknown to what extent agents actually follow such instructed plans. Without such an analysis, determining the extent agents comply with a given plan, it is impossible to assess whether a solution was reached through correct strategic reasoning or through other means, e.g., data contamination or overfitting to a benchmark. This paper presents the first extensive, systematic analysis of plan compliance in programming agents, examining 16,991 trajectories from SWE-agent across four LLMs on SWE-bench Verified and SWE-bench Pro under eight plan variations. Without an explicit plan, agents fall back on workflows internalized during training, which are often incomplete, overfit, or inconsistently applied. Providing the standard plan improves issue resolution, and we observe that periodic plan reminders can mitigate plan violations and improve task success. A subpar plan hurts performance even more than no plan at all. Surprisingly, augmenting a plan with additional task-relevant phases in the early stage can degrade performance, particularly when these phases do not align with the model's internal problem-solving strategy. These findings highlight a research gap: fine-tuning paradigms that teach models to follow instructed plans, rather than encoding task-specific plans in them. This requires teaching models to reason and act adaptively, rather than memorizing workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first large-scale empirical analysis of plan compliance in autonomous programming agents. Using 16,991 trajectories generated by SWE-agent across four LLMs on SWE-bench Verified and SWE-bench Pro under eight plan variations, it finds that agents without an explicit plan default to incomplete or overfit internalized workflows; a standard plan improves issue resolution; periodic reminders reduce violations and increase success; a subpar plan degrades performance more than no plan; and augmenting plans with misaligned early phases can further harm results. The work concludes by identifying a gap in fine-tuning paradigms that would teach adaptive plan following rather than workflow memorization.
Significance. If the directional findings on plan effects and compliance hold after methodological strengthening, the study would provide concrete evidence that explicit plans are not merely optional scaffolding but can be performance-critical (or detrimental) in agentic software engineering. It would also motivate new training objectives focused on instructed-plan adherence, with potential implications for benchmark design and agent reliability on tasks like issue resolution.
major comments (2)
- [Methods / Evaluation of plan compliance] The central claims rest on quantifying plan compliance and violations from trajectories alone. The manuscript does not report how agent actions (commands, edits, observations) are mapped to discrete phases (navigation, reproduction, patch, validation), whether this mapping uses heuristics, LLM classifiers, or other rules, or any cross-validation against human judgments or model internals. Without such validation, correlations between compliance rates and success rates could reflect benchmark-specific patterns or inconsistent phase boundaries rather than genuine strategic adherence.
- [Results] The claim that a subpar plan hurts performance more than no plan at all, and that adding misaligned early phases degrades results, is load-bearing for the practical takeaway. The results section should include per-condition success rates with confidence intervals, statistical tests for the eight plan variations, and controls for multiple comparisons; the current directional statements would be strengthened by these details.
minor comments (1)
- [Abstract] The abstract contains a slightly awkward sentence ('Without such an analysis, determining the extent agents comply with a given plan, it is impossible...') that could be rephrased for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us strengthen the methodological transparency and statistical rigor of our work. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods / Evaluation of plan compliance] The central claims rest on quantifying plan compliance and violations from trajectories alone. The manuscript does not report how agent actions (commands, edits, observations) are mapped to discrete phases (navigation, reproduction, patch, validation), whether this mapping uses heuristics, LLM classifiers, or other rules, or any cross-validation against human judgments or model internals. Without such validation, correlations between compliance rates and success rates could reflect benchmark-specific patterns or inconsistent phase boundaries rather than genuine strategic adherence.
Authors: We agree that a more detailed account of the phase-mapping procedure is necessary for reproducibility and to address potential concerns about consistency. In the revised manuscript we have expanded Section 3.2 with a dedicated subsection (3.2.1) that fully specifies the mapping pipeline: a deterministic rule-based classifier that inspects command strings, file paths, and observation patterns, supplemented by an LLM judge (GPT-4o) for ambiguous cases. We now report the complete set of rules, the exact LLM prompt, and the results of a post-hoc human validation study on a stratified sample of 400 trajectories (Cohen’s κ = 0.79 with two independent annotators). We also discuss the limitations of this hybrid approach and the steps taken to mitigate benchmark-specific artifacts. These additions directly respond to the referee’s concern. revision: yes
-
Referee: [Results] The claim that a subpar plan hurts performance more than no plan at all, and that adding misaligned early phases degrades results, is load-bearing for the practical takeaway. The results section should include per-condition success rates with confidence intervals, statistical tests for the eight plan variations, and controls for multiple comparisons; the current directional statements would be strengthened by these details.
Authors: We concur that the load-bearing claims benefit from explicit statistical support. We have added a new table (Table 3) that reports success rates for all eight plan conditions on both SWE-bench Verified and SWE-bench Pro, together with 95 % bootstrap confidence intervals. Pairwise χ² tests with Bonferroni correction for the eight conditions were performed; the key contrasts (subpar plan vs. no-plan; misaligned early phases vs. standard plan) remain significant after correction (p < 0.01). These results are now presented in Section 4.2, and the discussion has been updated to reference the corrected p-values. The directional findings are unchanged, but the quantitative backing is now substantially stronger. revision: yes
Circularity Check
No circularity: purely empirical trajectory analysis
full rationale
The paper reports direct measurements of plan compliance and task success across 16,991 agent trajectories on SWE-bench benchmarks under controlled plan variations. All central claims (e.g., performance differences with/without plans, effects of reminders or subpar plans) are grounded in observed action sequences mapped to phases, with no equations, fitted parameters renamed as predictions, self-referential definitions, or load-bearing self-citations that reduce the results to their own inputs. The study is self-contained as an empirical comparison and does not derive any result by construction from its own measurements or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Trae Agent. 2026. Trae Agent System Prompt with Default Plan. https://github. com/bytedance/trae-agent/blob/main/trae_agent/prompt/agent_prompt.py
2026
- [2]
-
[3]
Yang Chen, Toufique Ahmed, Reyhaneh Jabbarvand, and Martin Hirzel. 2026. Can Old Tests do New Tricks for Resolving SWE Issues?. InSymposium on the Foundations of Software Engineering (FSE)
2026
-
[4]
Jimenez, John Yang, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Kevin Liu, and Aleksander Madry. 2024. Introducing SWE- bench Verified. https://openai.com/index/introducing-swe-bench-verified/
2024
-
[5]
DeepSeek-AI. 2025. DeepSeek-R1-0528. https://huggingface.co/deepseek-ai/ DeepSeek-R1-0528
2025
-
[6]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. 2025. SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?arXiv preprint arXiv:2509.16941(2025)
work page internal anchor Pith review arXiv 2025
-
[7]
Lutfi Eren Erdogan, Hiroki Furuta, Sehoon Kim, Nicholas Lee, Suhong Moon, Gopala Anumanchipalli, Kurt Keutzer, and Amir Gholami. 2025. Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks. InForty-second Inter- national Conference on Machine Learning. https://openreview.net/forum?id= ybA4EcMmUZ
2025
-
[8]
Sebastian Farquhar, Vikrant Varma, David Lindner, David Elson, Caleb Bid- dulph, Ian Goodfellow, and Rohin Shah. 2025. Mona: Myopic optimization with non-myopic approval can mitigate multi-step reward hacking.arXiv preprint arXiv:2501.13011(2025). Conference’17, July 2017, Washington, DC, USA Shuyang Liu, Saman Dehghan, Jatin Ganhotra, Martin Hirzel, and ...
-
[9]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1: Incen- tivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
-
[11]
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. 2024. Understanding the planning of LLM agents: A survey.arXiv preprint arXiv:2402.02716(2024)
work page internal anchor Pith review arXiv 2024
- [12]
-
[13]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues?. InInternational Conference on Learning Representations (ICLR). https://openreview.net/forum?id=VTF8yNQM66
2024
-
[14]
Ao Li, Yuexiang Xie, Songze Li, Fugee Tsung, Bolin Ding, and Yaliang Li. 2025. Agent-Oriented Planning in Multi-Agent Systems. InThe Thirteenth Interna- tional Conference on Learning Representations. https://openreview.net/forum?id= EqcLAU6gyU
2025
- [15]
-
[16]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics12 (2024), 157–173
2024
-
[18]
Shuyang Liu, Yang Chen, Rahul Krishna, Saurabh Sinha, Jatin Ganhotra, and Reyhan Jabbarvand. 2025. Process-Centric Analysis of Agentic Software Systems. arXiv preprint arXiv:2512.02393(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
From Plan to Action: How Well Do Agents Follow the Plan?
Shuyang Liu, Saman Dehghan, Jatin Ganhotra, Martin Hirzel, and Reyhaneh Jabbarvand. 2026. "From Plan to Action: How Well Do Agents Follow the Plan?" artifact website. https://github.com/Intelligent-CAT-Lab/Planning-Analysis
2026
-
[20]
Henry B Mann and Donald R Whitney. 1947. On a test of whether one of two random variables is stochastically larger than the other.The annals of mathematical statistics(1947), 50–60
1947
-
[21]
Quinn McNemar. 1947. Note on the Sampling Error of the Difference Between Correlated Proportions or Percentages.Psychometrika12, 2 (1947), 153–157. https://doi.org/10.1007/BF02295996
-
[22]
Mistral AI. 2025. Devstral-Small-2512. https://openrouter.ai/mistralai/devstral- 2512
2025
-
[23]
OpenAI. 2025. GPT5-Mini. https://developers.openai.com/api/docs/models/gpt- 5-mini
2025
-
[24]
OpenAI. 2026. Why SWE-bench Verified no longer measures frontier coding capabilities. https://openai.com/index/why-we-no-longer-evaluate-swe-bench- verified
2026
-
[25]
OpenHands. 2025. OpenHands System Prompt with De- fault Plan. https://github.com/OpenHands/OpenHands/blob/ 08118d742b564add3e970921ac8910c265ece975/evaluation/benchmarks/swe_ bench/prompts/swe_default.j2
2025
-
[26]
Karl Pearson. 1895. VII. Note on regression and inheritance in the case of two parents.Proceedings of the Royal Society of London58, 347-352 (12 1895), 240–242. https://doi.org/10.1098/rspl.1895.0041 arXiv:https://royalsocietypublishing.org/rspl/article-pdf/58/347- 352/240/263745/rspl.1895.0041.pdf
- [27]
-
[28]
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani- Tür, Gokhan Tur, and Heng Ji. 2025. ToolRL: Reward is all tool learning needs. arXiv preprint arXiv:2504.13958(2025)
work page internal anchor Pith review arXiv 2025
-
[29]
IBM Research. 2026. From 73% to 11%: Revealing True SWE-Agent Capabilities with Discriminative Subsets. https://jatinganhotra.dev/blog/swe-agents/2025/06/ 05/swe-bench-verified-discriminative-subsets.html
2026
-
[30]
Shuzheng Si, Haozhe Zhao, Kangyang Luo, Gang Chen, Fanchao Qi, Minjia Zhang, Baobao Chang, and Maosong Sun. 2025. A Goal Without a Plan Is Just a Wish: Efficient and Effective Global Planner Training for Long-Horizon Agent Tasks. https://arxiv.org/abs/2510.05608
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
SWE-Agent. 2026. SWE-agent System Prompt with Default Plan. https://github. com/SWE-agent/SWE-agent/blob/main/config/default.yaml
2026
-
[32]
Scott Wu. 2024. Introducing Devin, the first AI software engineer.Cognition Labs Blog(2024)
2024
-
[33]
Binfeng Xu, Zhiyuan Peng, Bowen Lei, Subhabrata Mukherjee, and Dongkuan Xu
-
[34]
ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models. https://arxiv.org/abs/2305.18323
-
[35]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: agent-computer interfaces enable automated software engineering. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada) (NIPS ’24). Curran Associates Inc., Red Hook, NY,...
2024
-
[36]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR). https: //openreview.net/forum?id=WE_vluYUL-X
2023
-
[37]
Cong Zhang, Xin Deik Goh, Dexun Li, Hao Zhang, and Yong Liu. 2025. Planning with multi-constraints via collaborative language agents. InProceedings of the 31st International Conference on Computational Linguistics. 10054–10082
2025
-
[38]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- toCodeRover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1592–1604
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.