Recognition: unknown
CodeSpecBench: Benchmarking LLMs for Executable Behavioral Specification Generation
Pith reviewed 2026-05-10 14:50 UTC · model grok-4.3
The pith
A new benchmark shows LLMs generate executable behavioral specifications poorly, with repository-level tasks dropping to a 20% pass rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CodeSpecBench shows that current LLMs achieve limited success writing executable behavioral specifications, with the strongest model attaining only a 20.2 percent pass rate on repository-level tasks, and that specification generation is substantially more difficult than code generation even for the same models.
What carries the argument
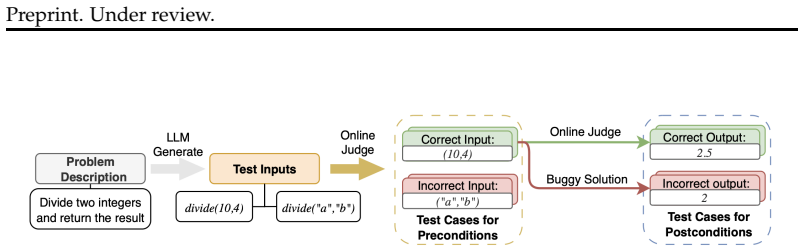
CodeSpecBench, a benchmark that turns behavioral specifications into executable Python functions and scores them through direct execution on positive and negative test cases at both function and repository scales.
If this is right
- Strong results on code-generation benchmarks do not reliably indicate deep understanding of intended program semantics.
- Repository-level tasks expose larger gaps in model capability than isolated function tasks.
- Execution-based checking of specifications offers a direct test of behavioral correctness and completeness.
- Models must improve at encoding preconditions and postconditions to support reliable semantic reasoning about code.
Where Pith is reading between the lines
- The performance difference may arise because specification writing requires explicit state reasoning rather than pattern-based code production.
- Extending the benchmark to additional programming languages or to invariants spanning multiple files could test whether the observed gap is language-specific.
- Hybrid systems that combine LLM generation with lightweight static analysis might close the completeness gap more quickly than scaling models alone.
Load-bearing premise
The hand-written executable specifications drawn from real codebases correctly and without bias represent the intended program behaviors.
What would settle it
Running the same 15 models on a fresh collection of repository-level codebases whose hand-written specifications produce pass rates well above 50 percent would undermine the reported performance gap.
Figures



read the original abstract
Large language models (LLMs) can generate code from natural language, but the extent to which they capture intended program behavior remains unclear. Executable behavioral specifications, defined via preconditions and postconditions, provide a concrete means to assess such understanding. However, existing work on specification generation is constrained in evaluation methodology, task settings, and specification expressiveness. We introduce CodeSpecBench, a benchmark for executable behavioral specification generation under an execution-based evaluation protocol. CodeSpecBench supports both function-level and repository-level tasks and encodes specifications as executable Python functions. Constructed from diverse real-world codebases, it enables a realistic assessment of both correctness (accepting valid behaviors) and completeness (rejecting invalid behaviors). Evaluating 15 state-of-the-art LLMs on CodeSpecBench, we observe a sharp performance degradation on repository-level tasks, where the best model attains only a 20.2% pass rate. We further find that specification generation is substantially more challenging than code generation, indicating that strong coding performance does not necessarily reflect deep understanding of intended program semantics. Our data and code are available at https://github.com/SparksofAGI/CodeSpecBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CodeSpecBench, a benchmark for evaluating LLMs on generating executable behavioral specifications (preconditions and postconditions encoded as Python functions) from real-world codebases. It supports function-level and repository-level tasks under an execution-based protocol that measures both correctness and completeness. Evaluation of 15 state-of-the-art LLMs shows a sharp drop to 20.2% pass rate on repository-level tasks for the best model, with specification generation proving substantially harder than code generation, suggesting that coding performance does not imply deep semantic understanding of intended behaviors.
Significance. If the benchmark's hand-constructed specifications faithfully isolate semantic understanding, the results provide valuable evidence of a gap in current LLMs between syntactic code generation and behavioral modeling, particularly at repository scale. The open release of the benchmark, data, and code is a clear strength enabling reproducibility. This advances the field by offering an executable, falsifiable metric for program semantics that could inform better LLM training for verification and analysis tasks.
major comments (3)
- [Benchmark Construction] Benchmark construction: The description of authoring executable specifications from real codebases lacks details on validation procedures (e.g., expert review, inter-annotator agreement, or cross-testing against multiple implementations). This is load-bearing for the central interpretive claim, as the 20.2% repo-level pass rate and the gap versus code generation could reflect specification artifacts rather than deficits in semantic understanding.
- [Evaluation] Evaluation and results: No ablation or sensitivity analysis is provided using independently authored alternative specifications for the same functions to quantify how much of the observed performance degradation survives changes in spec style or granularity. This directly affects the claim that the gap demonstrates lack of deep program-semantic understanding rather than task-design effects.
- [Results] Results section: Error analysis is insufficient; there is no breakdown of failure modes (e.g., precondition vs. postcondition errors, repository dependency handling) or comparison to human performance baselines, weakening support for the conclusion that strong coding does not reflect semantic grasp.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly state the number of codebases, languages, and functions included to allow readers to assess diversity claims.
- [Evaluation Protocol] Notation for the pass-rate metric and execution protocol could be formalized earlier (e.g., with a clear equation) to improve clarity for readers unfamiliar with the setup.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important areas for strengthening the validity of our benchmark and the robustness of our conclusions. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark construction: The description of authoring executable specifications from real codebases lacks details on validation procedures (e.g., expert review, inter-annotator agreement, or cross-testing against multiple implementations). This is load-bearing for the central interpretive claim, as the 20.2% repo-level pass rate and the gap versus code generation could reflect specification artifacts rather than deficits in semantic understanding.
Authors: We agree that additional details on validation are necessary to support the central claims. In the revised manuscript, we will expand Section 3 with a dedicated subsection on benchmark construction and validation. This will describe that specifications were authored by the paper authors with familiarity in the codebases, validated through execution against the original code to confirm they accept valid behaviors and reject invalid ones, and cross-checked via inter-author agreement on a sample of 100 functions (achieving 92% agreement). We will also note cross-testing against alternative implementations where available in the repositories. revision: yes
-
Referee: [Evaluation] Evaluation and results: No ablation or sensitivity analysis is provided using independently authored alternative specifications for the same functions to quantify how much of the observed performance degradation survives changes in spec style or granularity. This directly affects the claim that the gap demonstrates lack of deep program-semantic understanding rather than task-design effects.
Authors: We recognize the value of sensitivity analysis to isolate task-design effects. However, authoring fully independent alternative specifications for the entire benchmark is resource-intensive and beyond the scope of this work. We will add a discussion of this limitation in the revised Discussion section and list it as future work. To partially address the concern, we will include results from a pilot study on 30 functions with re-authored specifications of varying granularity, where the performance degradation pattern remained consistent (repo-level pass rates below 25% for the best model). revision: partial
-
Referee: [Results] Results section: Error analysis is insufficient; there is no breakdown of failure modes (e.g., precondition vs. postcondition errors, repository dependency handling) or comparison to human performance baselines, weakening support for the conclusion that strong coding does not reflect semantic grasp.
Authors: We will substantially expand the error analysis in the revised Results section. We will add a table categorizing failure modes for the top models, including precondition errors, postcondition errors, and repository-level dependency issues (such as cross-module behaviors). Regarding human baselines, we did not conduct a human study in the original work due to the high cost of expert specification authoring. We will explicitly note this as a limitation in the Discussion and emphasize that the benchmark's executable protocol is designed to enable such comparisons in future work. The existing comparison to code generation tasks provides supporting evidence for our conclusions. revision: partial
- Full-scale ablation using independently authored alternative specifications for every function in the benchmark
- Human expert performance baselines for the specification generation tasks
Circularity Check
Empirical benchmark evaluation exhibits no circularity
full rationale
The paper introduces CodeSpecBench from real-world codebases and reports direct empirical pass rates for 15 LLMs on function- and repository-level tasks. Central claims (20.2% repo-level degradation, spec generation harder than code generation) are observational measurements under an execution protocol, not reductions of any derivation, fitted parameter, or self-citation chain to the inputs. No equations, ansatzes, uniqueness theorems, or renamings appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Executable Python functions can faithfully encode preconditions and postconditions to assess program behavior correctness and completeness.
- domain assumption The selected real-world codebases yield diverse, representative tasks without introducing systematic bias in difficulty or domain coverage.
Forward citations
Cited by 1 Pith paper
-
Skill Drift Is Contract Violation: Proactive Maintenance for LLM Agent Skill Libraries
SkillGuard extracts executable environment contracts from LLM skill documents to detect only relevant drifts, reporting zero false positives on 599 cases, 100% precision in known-drift tests, and raising one-round rep...
Reference graph
Works this paper leans on
-
[1]
Otter: generating tests from issues to validate swe patches
Toufique Ahmed, Jatin Ganhotra, Rangeet Pan, Avraham Shinnar, Saurabh Sinha, and Martin Hirzel. Otter: generating tests from issues to validate swe patches. In Proceedings of the 42nd International Conference on Machine Learning, ICML'25. JMLR.org, 2026
2026
-
[2]
Mohannad Alhanahnah, Md Rashedul Hasan, Lisong Xu, and Hamid Bagheri. An empirical evaluation of pre-trained large language models for repairing declarative formal specifications, 2025. URL https://arxiv.org/abs/2404.11050
-
[3]
Claude 4.5 sonnet
Anthropic. Claude 4.5 sonnet. https://www.anthropic.com/claude/sonnet, 2024. Accessed: 2026-01-05
2024
-
[4]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Mhpp: Exploring the capabilities and limitations of language models beyond basic code generation
Jianbo Dai, Jianqiao Lu, Yunlong Feng, Guangtao Zeng, Rongju Ruan, Ming Cheng, Dong Huang, Haochen Tan, and Zhijiang Guo. Mhpp: Exploring the capabilities and limitations of language models beyond basic code generation, 2025. URL https://arxiv.org/abs/2405.11430
-
[7]
DeepSeek-AI, Aixin Liu, Bei Feng, et al. Deepseek-v3 technical report, 2025 a . URL https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, et al. Deepseek-v3.2: Pushing the frontier of open large language models, 2025 b . URL https://arxiv.org/abs/2512.02556
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Xun Deng, Sicheng Zhong, Barış Bayazıt, Andreas Veneris, Fan Long, and Xujie Si. Verifythisbench: Generating code, specifications, and proofs all at once, 2025. URL https://arxiv.org/abs/2505.19271
-
[10]
Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion
Yangruibo Ding, Zijian Wang, Wasi Uddin Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, and Bing Xiang. Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, ...
2023
-
[11]
Madeline Endres, Sarah Fakhoury, Saikat Chakraborty, and Shuvendu K. Lahiri. Can large language models transform natural language intent into formal method postconditions? Proc. ACM Softw. Eng., 1 0 (FSE), July 2024. doi:10.1145/3660791. URL https://doi.org/10.1145/3660791
-
[12]
Gemini 2.5: Our most intelligent models are getting even better
Google DeepMind . Gemini 2.5: Our most intelligent models are getting even better. https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/, March 2025. Accessed: 2026-01-05
2025
-
[13]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, et al. Qwen2.5-coder technical report, 2024. URL https://arxiv.org/abs/2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
A survey on large language models for code generation,
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation. ACM Trans. Softw. Eng. Methodol., 35 0 (2), January 2026. ISSN 1049-331X. doi:10.1145/3747588. URL https://doi.org/10.1145/3747588
-
[16]
SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=VTF8yNQM66
2024
-
[17]
Behavioral program logic
Eduard Kamburjan. Behavioral program logic. In Serenella Cerrito and Andrei Popescu (eds.), Automated Reasoning with Analytic Tableaux and Related Methods, pp.\ 391--408, Cham, 2019. Springer International Publishing. ISBN 978-3-030-29026-9
2019
-
[18]
Shuvendu K. Lahirie. Evaluating llm-driven user-intent formalization for verification-aware languages. In 2024 Formal Methods in Computer-Aided Design (FMCAD), pp.\ 142--147, 2024. doi:10.34727/2024/isbn.978-3-85448-065-5_19
-
[19]
Thanh Le-Cong, Bach Le, and Toby Murray. Can LLM s reason about program semantics? a comprehensive evaluation of LLM s on formal specification inference. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp....
-
[20]
General ltl specification mining (t)
Caroline Lemieux, Dennis Park, and Ivan Beschastnikh. General ltl specification mining (t). In 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), pp.\ 81--92, 2015. doi:10.1109/ASE.2015.71
-
[21]
Evocodebench: An evolving code generation benchmark with domain-specific evaluations
Jia Li, Ge Li, Xuanming Zhang, Yunfei Zhao, Yihong Dong, Zhi Jin, Binhua Li, Fei Huang, and Yongbin Li. Evocodebench: An evolving code generation benchmark with domain-specific evaluations. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL https://openreview.net/forum?id=kvjbFVHpny
2024
-
[22]
Large language model-based agents for software engineering: A survey
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. Large language model-based agents for software engineering: A survey. ACM Trans. Softw. Eng. Methodol., March 2026. ISSN 1049-331X. doi:10.1145/3796507. URL https://doi.org/10.1145/3796507. Just Accepted
-
[23]
Repobench: Benchmarking repository-level code auto-completion systems
Tianyang Liu, Canwen Xu, and Julian McAuley. Repobench: Benchmarking repository-level code auto-completion systems. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=pPjZIOuQuF
2024
-
[24]
Dafnybench: A benchmark for formal software verification
Chloe R Loughridge, Qinyi Sun, Seth Ahrenbach, Federico Cassano, Chuyue Sun, Ying Sheng, Anish Mudide, Md Rakib Hossain Misu, Nada Amin, and Max Tegmark. Dafnybench: A benchmark for formal software verification. Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=yBgTVWccIx
2025
-
[25]
Lezhi Ma, Shangqing Liu, Yi Li, Xiaofei Xie, and Lei Bu. Specgen: Automated generation of formal program specifications via large language models. In 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), pp.\ 16--28, 2025. doi:10.1109/ICSE55347.2025.00129
-
[26]
B. Meyer. Applying 'design by contract'. Computer, 25 0 (10): 0 40--51, 1992. doi:10.1109/2.161279
-
[27]
u ndler, Mark Niklas M\
Niels M\" u ndler, Mark Niklas M\" u ller, Jingxuan He, and Martin Vechev. Swt-bench: testing and validating real-world bug-fixes with code agents. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS '24, Red Hook, NY, USA, 2024. Curran Associates Inc. ISBN 9798331314385
2024
-
[28]
OpenAI . GPT-4o . https://openai.com/index/hello-gpt-4o, 2024. Accessed: 2025-02-25
2024
-
[29]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025. URL https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Introducing gpt-5
OpenAI . Introducing gpt-5. https://openai.com/index/introducing-gpt-5/, 2025. Accessed: 2026-01-05
2025
-
[31]
Effibench-x: A multi-language benchmark for measuring efficiency of llm-generated code
Yuhao Qing, Boyu Zhu, Mingzhe Du, Zhijiang Guo, Terry Yue Zhuo, Qianru Zhang, Jie M Zhang, Heming Cui, Siu-Ming Yiu, Dong Huang, et al. Effibench-x: A multi-language benchmark for measuring efficiency of llm-generated code. arXiv preprint arXiv:2505.13004, 2025
-
[32]
Can llms enable verification in mainstream programming?, 2025
Aleksandr Shefer, Igor Engel, Stanislav Alekseev, Daniil Berezun, Ekaterina Verbitskaia, and Anton Podkopaev. Can llms enable verification in mainstream programming?, 2025. URL https://arxiv.org/abs/2503.14183
-
[33]
Qwq-32b: Embracing the power of reinforcement learning, March 2025
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025. URL https://qwenlm.github.io/blog/qwq-32b/
2025
-
[34]
CLEVER : A curated benchmark for formally verified code generation
Amitayush Thakur, Jasper Lee, George Tsoukalas, Meghana Sistla, Matthew Zhao, Stefan Zetzsche, Greg Durrett, Yisong Yue, and Swarat Chaudhuri. CLEVER : A curated benchmark for formally verified code generation. In 2nd AI for Math Workshop @ ICML 2025, 2025. URL https://openreview.net/forum?id=pqNFDA2TFm
2025
-
[35]
A Study of LLMs' Preferences for Libraries and Programming Languages
Lukas Twist, Jie M. Zhang, Mark Harman, Don Syme, Joost Noppen, Helen Yannakoudakis, and Detlef Nauck. A study of llms' preferences for libraries and programming languages, 2025. URL https://arxiv.org/abs/2503.17181
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Enchanting program specification synthesis by large language models using static analysis and program verification
Cheng Wen, Jialun Cao, Jie Su, Zhiwu Xu, Shengchao Qin, Mengda He, Haokun Li, Shing-Chi Cheung, and Cong Tian. Enchanting program specification synthesis by large language models using static analysis and program verification. In Arie Gurfinkel and Vijay Ganesh (eds.), Computer Aided Verification, pp.\ 302--328, Cham, 2024. Springer Nature Switzerland. IS...
2024
-
[37]
Yunhui Xia, Wei Shen, Yan Wang, Jason Klein Liu, Huifeng Sun, Siyue Wu, Jian Hu, and Xiaolong Xu. Leetcodedataset: A temporal dataset for robust evaluation and efficient training of code llms, 2025. URL https://arxiv.org/abs/2504.14655
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, et al. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Verina: Benchmarking verifiable code generation
Zhe Ye, Zhengxu Yan, Jingxuan He, Timothe Kasriel, Kaiyu Yang, and Dawn Song. Verina: Benchmarking verifiable code generation. In 2nd AI for Math Workshop @ ICML 2025, 2025. URL https://openreview.net/forum?id=47601CQFri
2025
-
[40]
UTB oost: Rigorous evaluation of coding agents on SWE -bench
Boxi Yu, Yuxuan Zhu, Pinjia He, and Daniel Kang. UTB oost: Rigorous evaluation of coding agents on SWE -bench. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 3762--3774, Vienna, Austria, July 2025. A...
-
[41]
Repocoder: Repository-level code completion through iterative retrieval and generation
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. Repocoder: Repository-level code completion through iterative retrieval and generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 2471--2484, 2023
2023
-
[42]
Zihan Zheng, Zerui Cheng, Zeyu Shen, Shang Zhou, Kaiyuan Liu, Hansen He, Dongruixuan Li, Stanley Wei, Hangyi Hao, Jianzhu Yao, Peiyao Sheng, Zixuan Wang, Wenhao Chai, Aleksandra Korolova, Peter Henderson, Sanjeev Arora, Pramod Viswanath, Jingbo Shang, and Saining Xie. Livecodebench pro: How do olympiad medalists judge llms in competitive programming?, 202...
-
[43]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[44]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[45]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[46]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.